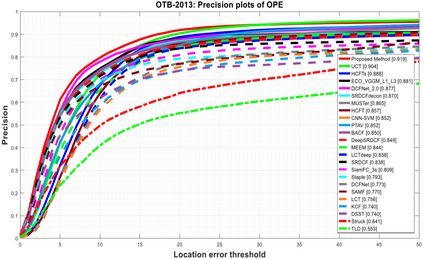
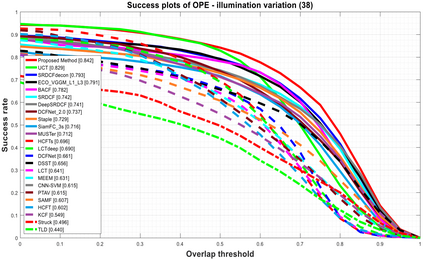
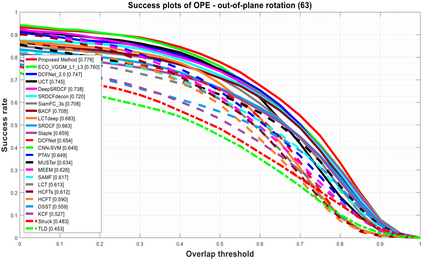
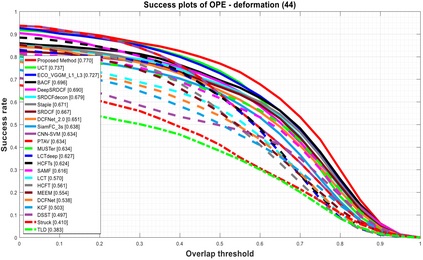
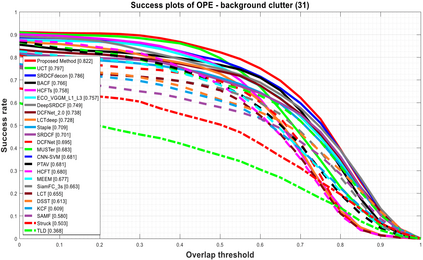
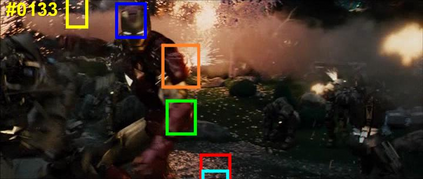
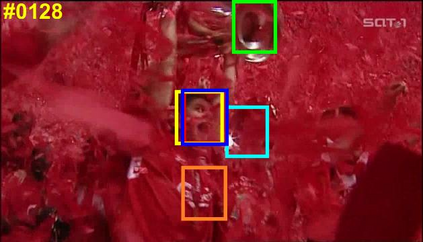
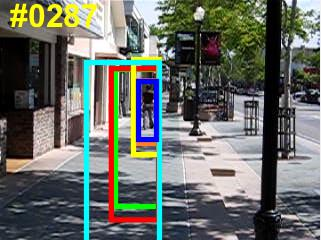
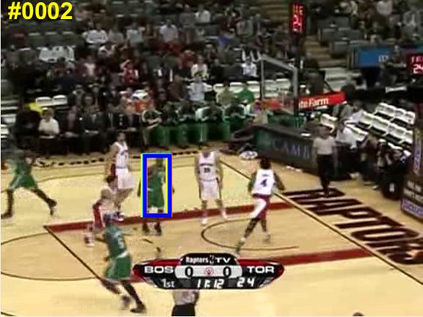
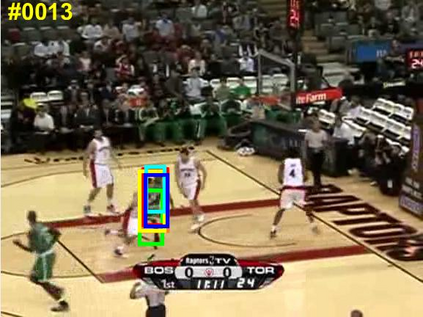
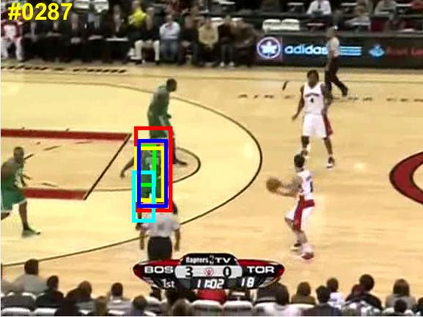
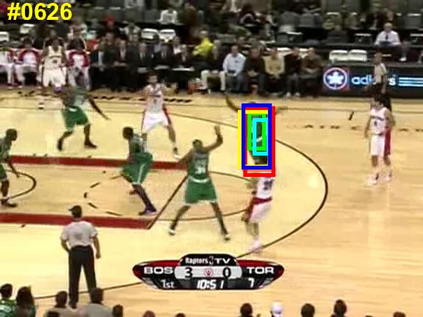
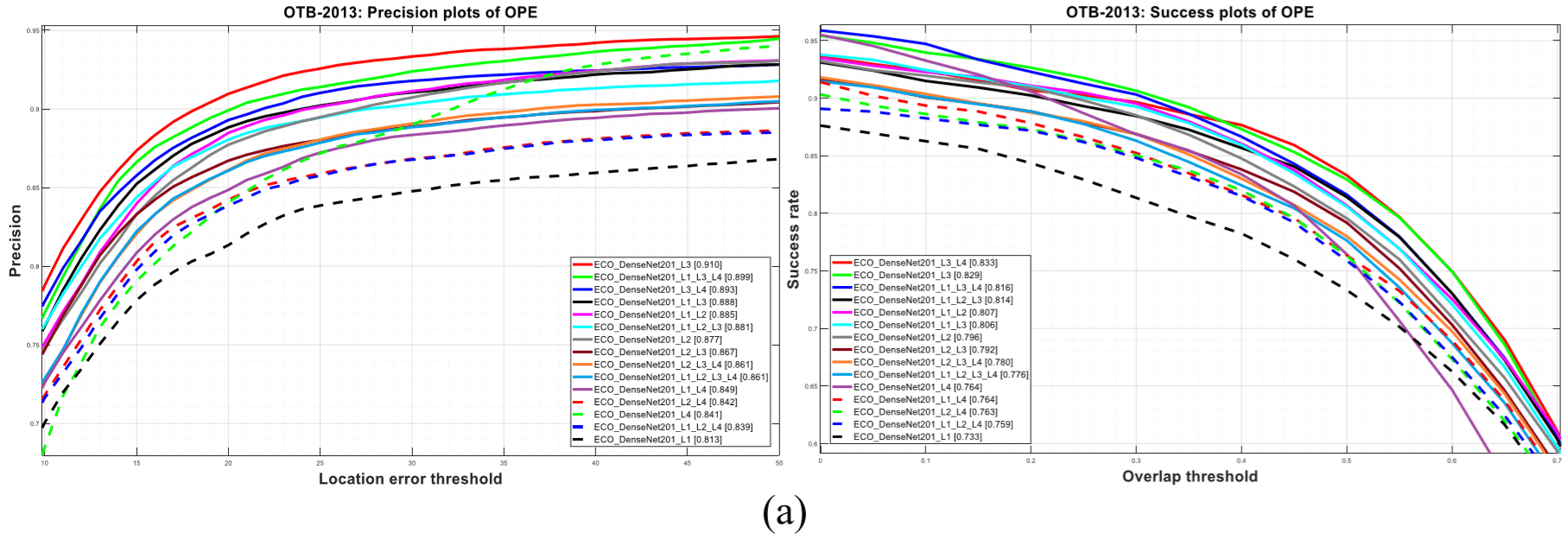
Visual object tracking remains an active research field in computer vision due to persisting challenges with various problem-specific factors in real-world scenes. Many existing tracking methods based on discriminative correlation filters (DCFs) employ feature extraction networks (FENs) to model the target appearance during the learning process. However, using deep feature maps extracted from FENs based on different residual neural networks (ResNets) has not previously been investigated. This paper aims to evaluate the performance of twelve state-of-the-art ResNet-based FENs in a DCF-based framework to determine the best for visual tracking purposes. First, it ranks their best feature maps and explores the generalized adoption of the best ResNet-based FEN into another DCF-based method. Then, the proposed method extracts deep semantic information from a fully convolutional FEN and fuses it with the best ResNet-based feature maps to strengthen the target representation in the learning process of continuous convolution filters. Finally, it introduces a new and efficient semantic weighting method (using semantic segmentation feature maps on each video frame) to reduce the drift problem. Extensive experimental results on the well-known OTB-2013, OTB-2015, TC-128 and VOT-2018 visual tracking datasets demonstrate that the proposed method effectively outperforms state-of-the-art methods in terms of precision and robustness of visual tracking.
翻译:由于在现实世界场景中存在各种特定问题的因素,在现实世界中,基于不同关联过滤器(DCFs)的许多现有跟踪方法都采用特征提取网络(FENs)来模拟学习过程中的目标外观,然而,利用基于不同残余神经网络(ResNets)的从FENs提取的深度特征图,此前尚未调查过,本文件旨在评估基于12个最新水平的ResNetFENs在基于DCF的框架中的表现,以确定最佳的视觉跟踪功能。首先,它排列了最佳特征图,并探索了普遍采用基于最佳ResNet的FEN(FENs)作为另一个基于DCFCF的方法。随后,拟议方法从完全动态FENs中提取了深度语义信息,并将其与基于ResNet的最佳特征图相结合,以加强持续变动过滤器学习过程中的目标代表性。最后,它引入了一种新的高效语义加权方法(使用每个视频框架中的语义分割图),并探索普遍采用基于最佳ResNet-20的FENEFENS-T(O-Tal-TL)精确性跟踪方法,以有效减少已了解的O-TBR-Tal-Tal-Tal-Tal-taild-taild-S-T-s-taild-taildroleg-tal-tal-tal-tal-S-tag-S-tag-st-s 和O-s-s-S-s-s-s-s-smmmal-tal-tal-tal-tal-smmmol-tal-tal-tal-trogrogal-s-s-s-s-s-tal-s-s-s-s-s-s-s-s-s-s-smal-smal-s-s-s-s-s-smmal-smal-smal-smoldal-smol-smold-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s