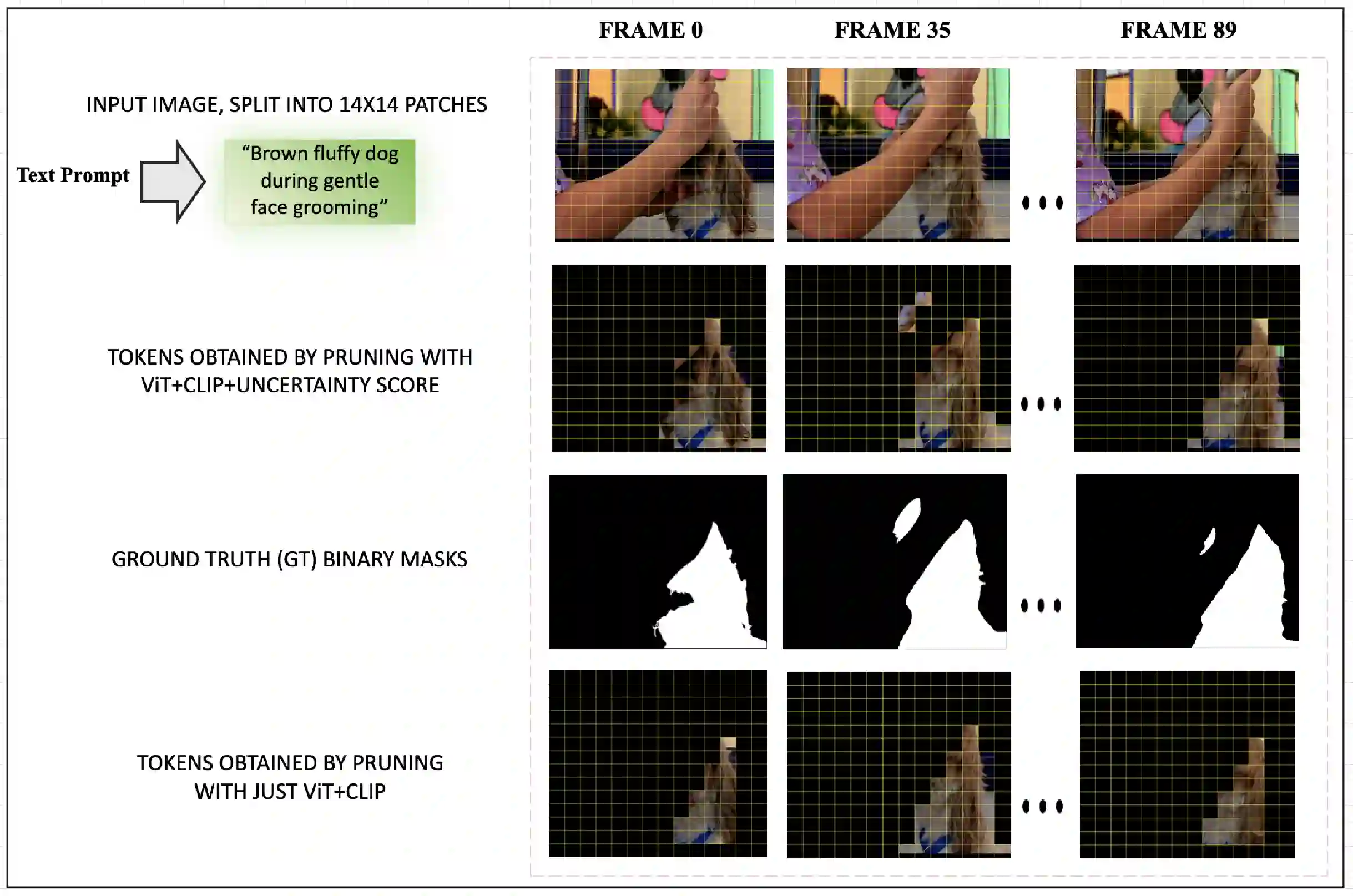
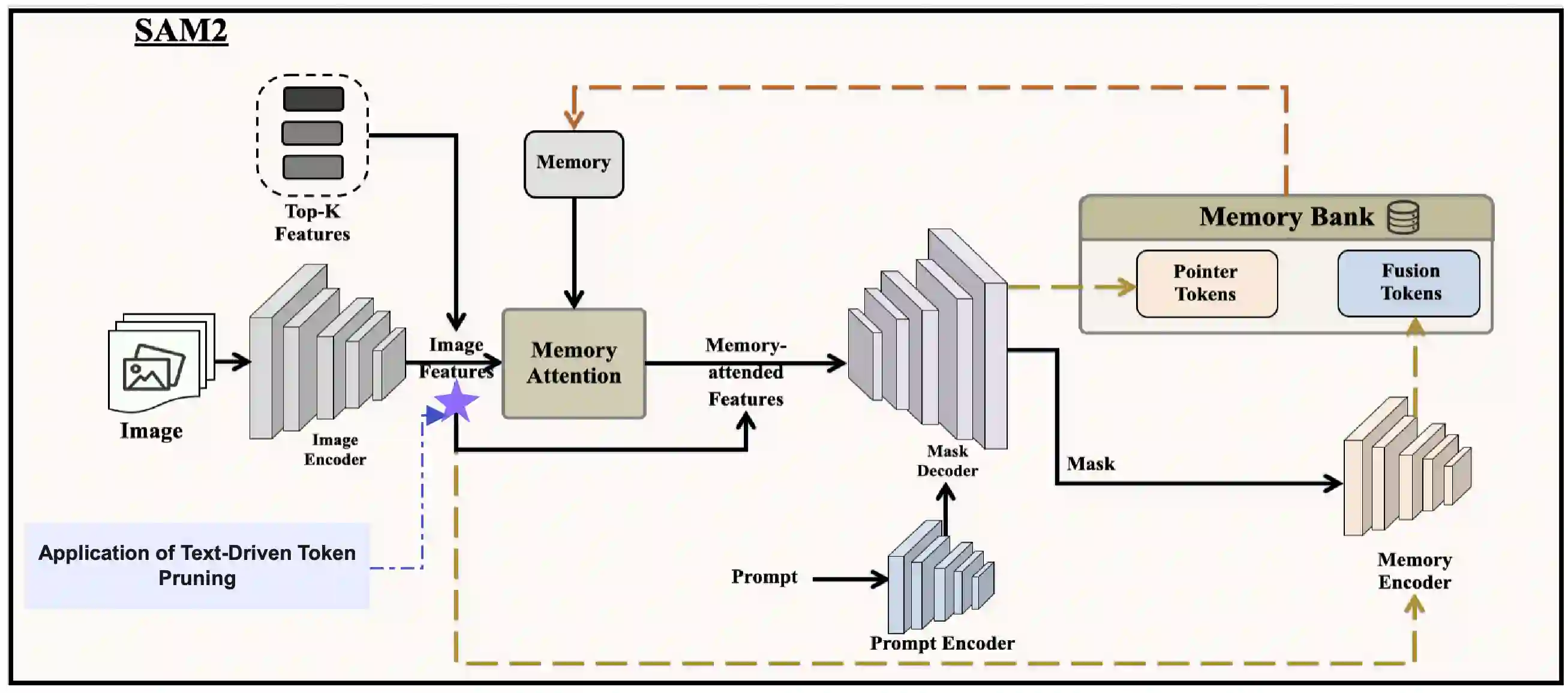
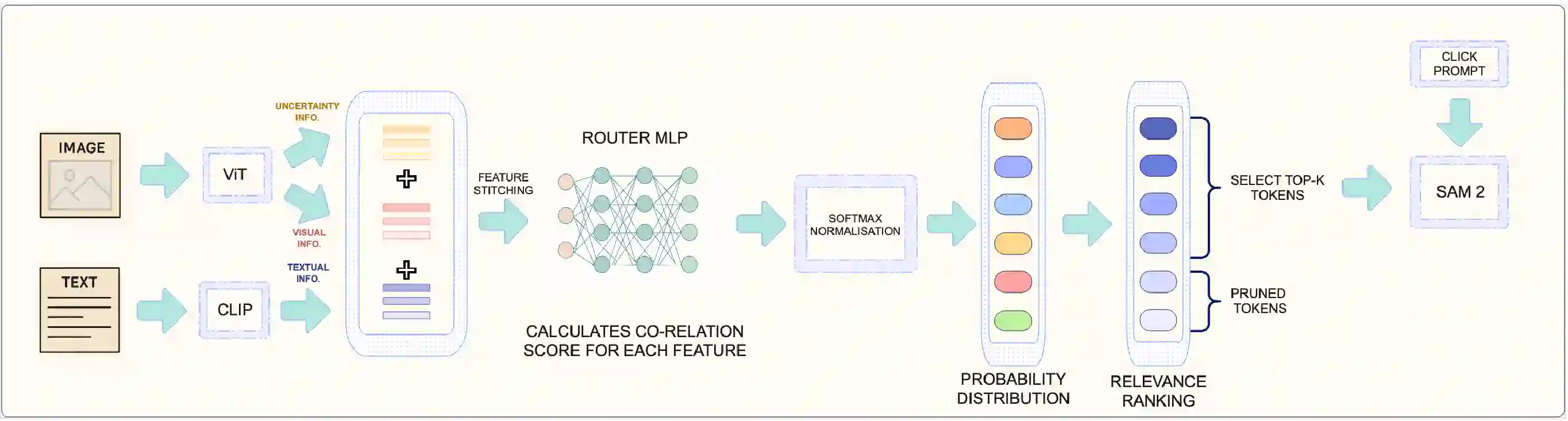
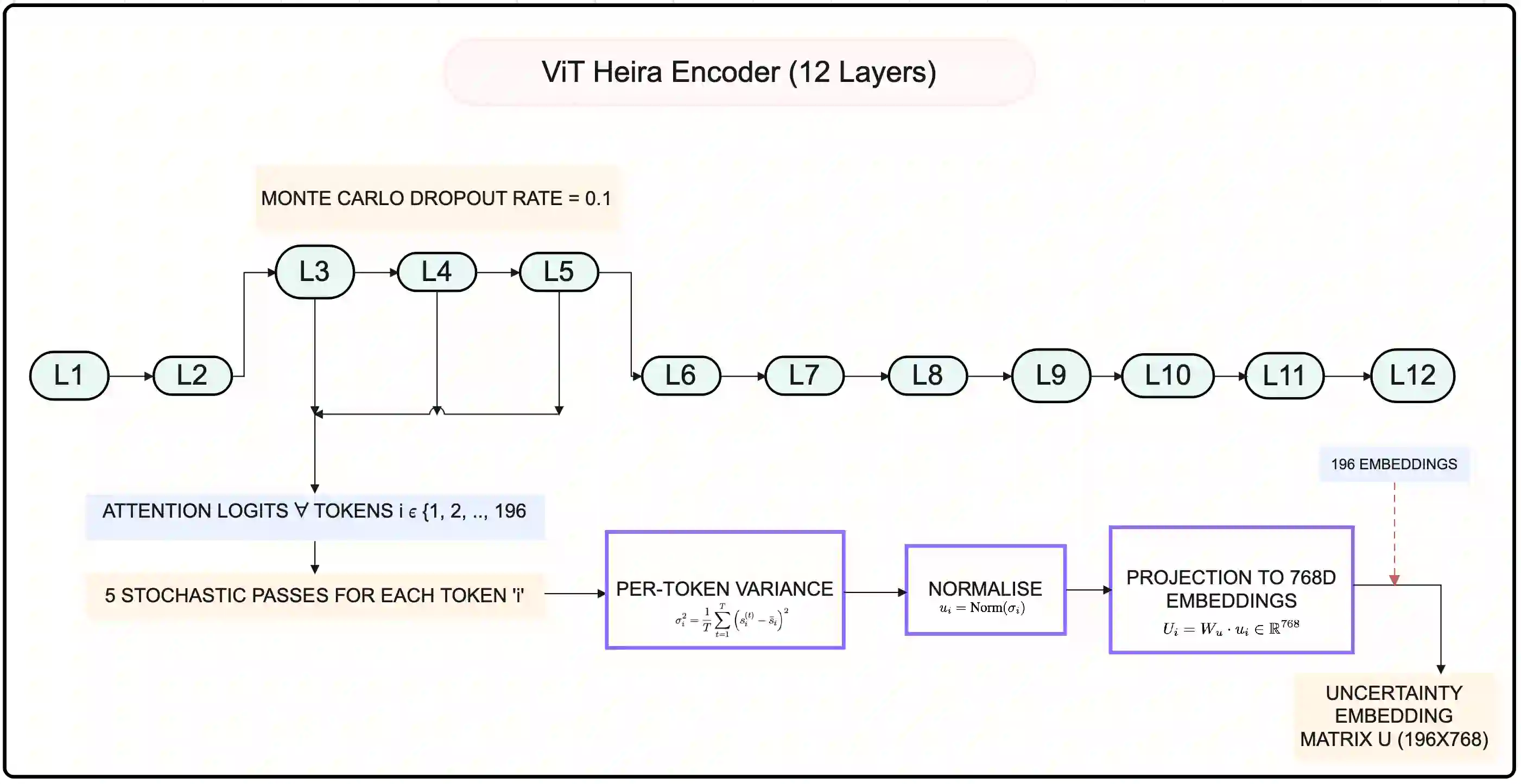
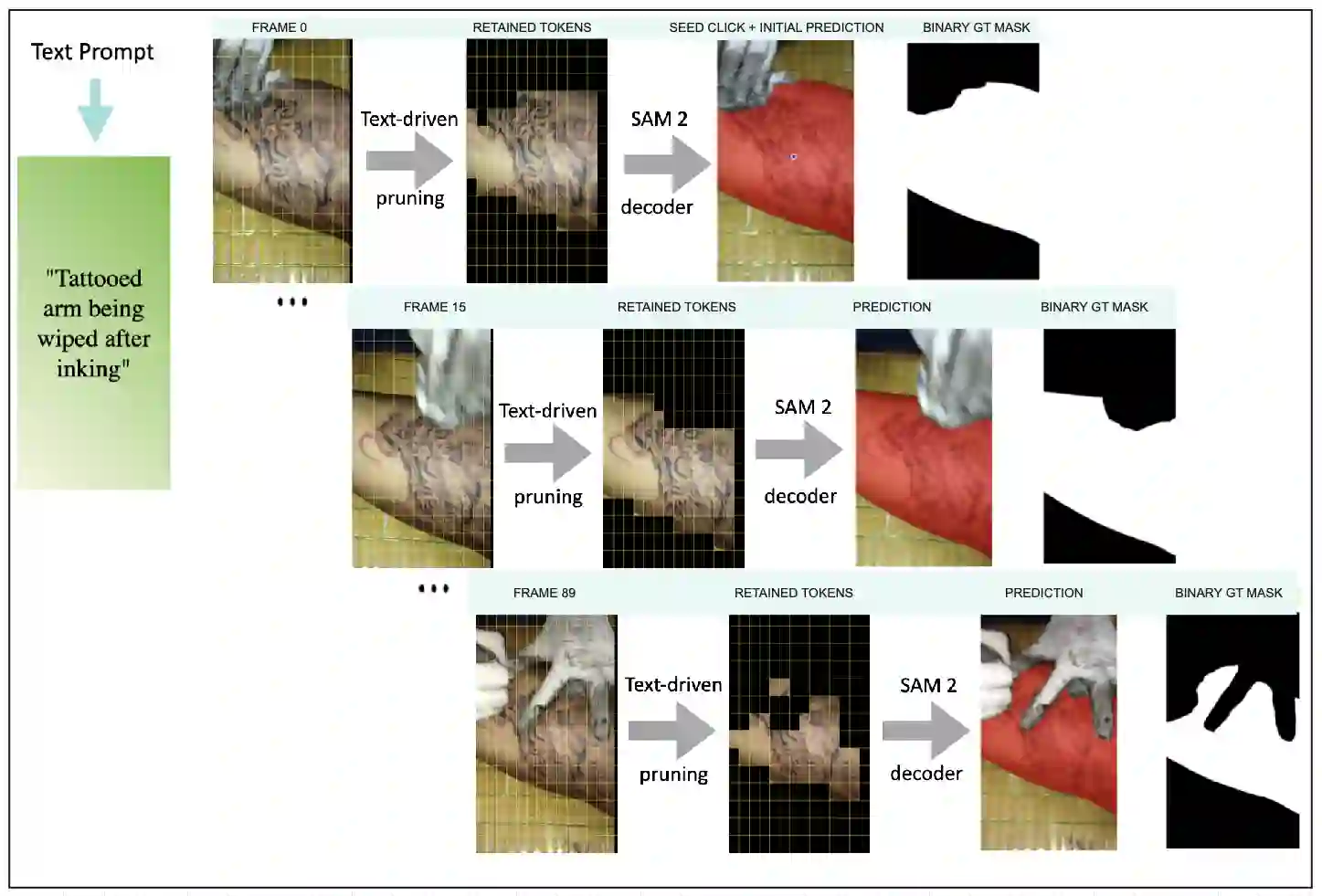
Segment Anything Model 2 (SAM2), a vision foundation model has significantly advanced in prompt-driven video object segmentation, yet their practical deployment remains limited by the high computational and memory cost of processing dense visual tokens across time. The SAM2 pipelines typically propagate all visual tokens produced by the image encoder through downstream temporal reasoning modules, regardless of their relevance to the target object, resulting in reduced scalability due to quadratic memory attention overhead. In this work, we introduce a text-guided token pruning framework that improves inference efficiency by selectively reducing token density prior to temporal propagation, without modifying the underlying segmentation architecture. Operating after visual encoding and before memory based propagation, our method ranks tokens using a lightweight routing mechanism that integrates local visual context, semantic relevance derived from object-centric textual descriptions (either user-provided or automatically generated), and uncertainty cues that help preserve ambiguous or boundary critical regions. By retaining only the most informative tokens for downstream processing, the proposed approach reduces redundant computation while maintaining segmentation fidelity. Extensive experiments across multiple challenging video segmentation benchmarks demonstrate that post-encoder token pruning provides a practical and effective pathway to efficient, prompt-aware video segmentation, achieving up to 42.50 percent faster inference and 37.41 percent lower GPU memory usage compared to the unpruned baseline SAM2, while preserving competitive J and F performance. These results highlight the potential of early token selection to improve the scalability of transformer-based video segmentation systems for real-time and resource-constrained applications.
翻译:Segment Anything Model 2 (SAM2)作为一种视觉基础模型,在提示驱动的视频对象分割方面取得了显著进展,但其实际部署仍受限于处理跨时间密集视觉令牌的高计算和内存成本。SAM2流程通常将图像编码器生成的所有视觉令牌传播至下游时间推理模块,无论其与目标对象的相关性如何,这导致二次内存注意力开销,从而降低了可扩展性。在本工作中,我们提出了一种文本引导的令牌剪枝框架,通过在时间传播之前有选择地降低令牌密度来提高推理效率,而无需修改底层分割架构。该方法在视觉编码之后、基于记忆的传播之前运行,通过一个轻量级路由机制对令牌进行排序,该机制整合了局部视觉上下文、源自以对象为中心的文本描述(用户提供或自动生成)的语义相关性,以及有助于保留模糊或边界关键区域的不确定性线索。通过仅保留最具信息量的令牌进行下游处理,所提方法在保持分割保真度的同时减少了冗余计算。在多个具有挑战性的视频分割基准上进行的大量实验表明,编码器后令牌剪枝为高效、提示感知的视频分割提供了一条实用且有效的途径,与未剪枝的基线SAM2相比,推理速度最高提升42.50%,GPU内存使用降低37.41%,同时保持了具有竞争力的J和F性能。这些结果突显了早期令牌选择在提升基于Transformer的视频分割系统在实时和资源受限应用中的可扩展性方面的潜力。