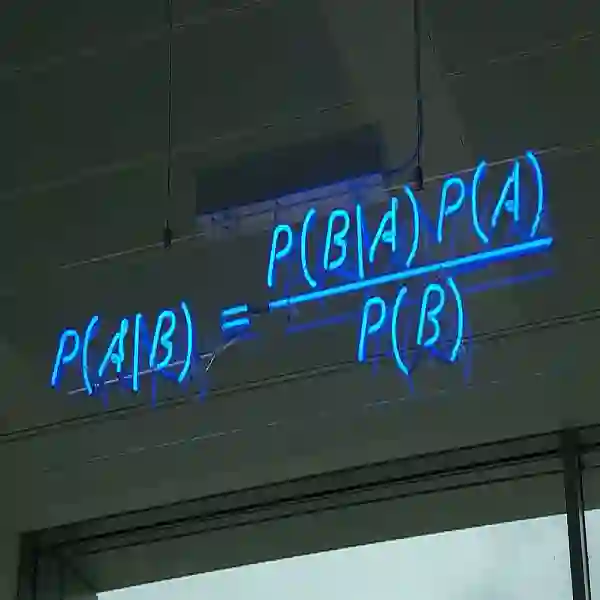概率论——总结
概率论
概率基础
学习机器学习经常会涉及概率论的知识,可以说概率论在机器学习中扮演着一个核心角色,因为机器学习算法的设计通常依赖于对数据的概率假设。因此,本章对机器学习中涉及的概率论常用的知识进行归纳总结,便于大家学习和查阅。
1. 样本空间
假设进行1000次抛硬币实验,每次实验的结果要么是正面,要么是反面,那么就会有1000个结果,这1000个实验结果就称为样本点, 而抛硬币实验中所有可能结果的集合{正面,反面}是该实验的样本空间。样本空间通常用符号$\Omega$ 表示,如果是投掷一个骰子,那么样本空间就是{1, 2, 3, 4, 5, 6}。

有些实验有两个或多个可能的样本空间。例如,从52张扑克牌中随机抽出一张,一个可能的样本空间是数字( A到 K),另外一个可能的样本空间是花色(黑桃,红桃,梅花,方块)。如果要完整地描述一张牌,就需要同时给出数字和花色,这时的样本空间可以通过构建上述两个样本空间的笛卡儿积来得到。
2. 随机事件及其概率
事件的概念:每次实验的一个结果成为基本事件,也就是上文提到的样本点,基本事件是不可再分解的、最基本的事件,其他事件都是由它们复合而成。
随机事件:由基本事件复合而成的事件成为随机事件或简称事件,它是样本空间的一个子集。如在投掷骰子的试验中,如果随机事件$A$表示为:$A = \left\{ {出现的点数为偶数} \right\}=\left\{{2, 4, 6}\right\}$,则是样本空间{1, 2, 3, 4, 5, 6}的一个子集,同时也是由基本事件复合而成的。
概率:概率表示一个随机事件发生的可能性大小,为$\left[ {0,1} \right]$之间的一个非负实数。一般随机事件$A$的概率可用符号$P\left( A \right)$表示。如,在抛掷硬币的试验中,如果硬币是均匀的,那么$P\left( 正面 \right)=P\left( 反面 \right)=0.5$。
3. 随机变量及其分布
随机变量:我们用一个变量来表示随机试验的结果,在每次试验之前无法确定会出现何种结果,因此也无法确定变量会取什么值,我们称这样的变量为随机变量。随机变量一般用大写字母表示随机变量,用小写字母表示其取值,例如用$X$表示一次抛硬币的随机变量,随机变量可能的取值为$x_1=\left\{ {正面} \right\}$和$x_2=\left\{ {反面} \right\}$。
随机变量因其取值方式不同,通常分为离散型随机变量和连续型随机变量两类。离散型随机变量拥有有限或者无限多状态;连续随机变量用实数值刻画,将在下文中分别介绍。
概率分布:概率分布用来描述随机变量或一簇随机变量在每一个可能渠道的状态的可能性大小。针对离散随机变量和连续随机变量,其概率分布也是有差异。
3.1 离散随机变量及其概率分布
如果随机变量$X$只取有限个或可列无限多个可能值,而且用确定的概率来取这些不同的值,则称$X$为离散随机变量。我们要了解离散随机变量$X$的统计规律,就必须知道它取每种可能值$x_i$的概率,即
$$P\left(X=x_i\right)=p\left(x_i\right), i=1,...,n \tag{3.1} $$
则$p\left(x_i\right), i=1,...,n$成为离散随机变量$X$的概率分布,且满足:
$$\sum\limits_{i = 1}n {P\left( {{x_i}} \right)} = 1 \tag{3.2} $$
$$P\left( {{x_i}} \right) \ge 0,i = 1, \ldots ,n \tag{3.3} $$
常见的离散随机变量及其概率分布:
- 伯努利分布
伯努利分布也称为两点分布或0-1分布。在一次试验中,用随机变量$X$表示事件$A$出现或不出现的情况($X=1$表示事件$A$出现,$X=0$表示事件$A$不出现),且事件$A$出现的概率为$p$,不出现的概率为$1-p$,此时随机变量$X$的取值只可能取0或1两个值,其分布律如下表:
| A | 0 | 1 | | :---: | :---: | :---: | | p_k | 1-p | p |
则称$X$服从参数为$p$的伯努利分布,记为$X\sim B\left(1, p\right)$。
生活中有很多服从伯努利分布的例子,如一次投掷硬币实验硬币是“正面”还是“反面”,射手某次射击是否“中靶”,产品是否“合格”等。
- 二项分布
在 n次伯努利分布中,若以变量 X 表示事件 A出现的次数,则$X$ 的取值为 $\left\{ {0, · · · , n} \right\}$,其相应的分布为二项分布:
$$P\left( {X = k} \right) = C_nk{pk}{q{n - k}},k = 1, \ldots ,n \tag{3.4} $$
其中$C_nk$为二项式系数,表示从$n$个元素中取出$k$个元素而不考虑其顺序的组合的总数。
- 泊松分布
当二项分布中的$n$很大而$p$很小时,就可将二项分布近似看作泊松分布。公式为:
$$P\left( {X = k} \right) = \frac{{{\lambda k}}}{{k!}}{e{ - \lambda }},k = 0,1,2, \ldots \tag{3.5} $$
其中$\lambda>0$为常数,则称随机变量$X$服从参数为$\lambda$的泊松分布。记为$X\sim P(\lambda)$。
生活中有很多近似服从泊松分布的例子:某医院每天来就诊的病人数,某地区一年内发生自然灾害的次数等。
3.2 连续随机变量及其概率分布
与离散随机变量不同,一些随机变量$X$的取值是不可列举的,由全部实数或者由一部分区间组成,比如:
$$X={x|a \le x \le b}, -\infty <a<b< \infty \tag{3.6} $$
则称$X$为连续随机变量,连续随机变量的取值是不可数的。当我们研究的对象是连续型随机变量时,我们一般用密度函数$p\left(x\right)$来描述随机变量$X$的概率分布。其中$p\left(x\right)$是可积函数,并满足:
$$\int_{ - \infty }{ + \infty } {p\left( x \right)dx} = 1\tag{3.7} $$
概率密度函数具有以下两个重要性质:
- 在其样本空间内积分值为1:
- 对于连续随机变量$X$和任意实数$a$,总有$P\left\{{X=a}\right\}=0$ .
常见的连续随机变量及其概率分布:
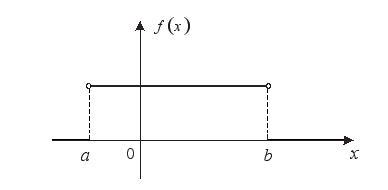
- 均匀分布
如果随机变量$X$的概率密度函数如下:
$$P{a<X\le b }=\int_{ - \infty }{ + \infty } {f\left( x \right)dx} \tag{3.8} $$
则称$X$服从$[a,b]$区间上的均匀分布,记作$X\sim U[a,b]$,其中$a$, $b$$(a<b)$为常数。
- 正态分布
正态分布又称为高斯分布,是概率论中最重要的连续型分布,在机器学习中也有重要应用。正态分布自然界最常见的一种分布,并且具有很多良好的性质,在很多领域都有非常重要的影响,其概率密度函数为:
$$p(x)=\frac{1}{{\sqrt {2\pi } \sigma }}{e{ - \frac{{{{\left( {x - \mu } \right)}2}}}{{2{\sigma 2}}}}} \tag{3.9} $$
其中$\mu $和$\sigma$均为常数,且$\sigma >0$,可记为:
$$X\sim N(\mu,\sigma2) \tag{3.10}$$
当$\mu=0, \sigma=0$时,称为标准正态分布。
由图可知,正态分布的概率密度$f(x)$有如下性质:
关于直线$x=\mu$对称;
在$x=\mu$处取得最大值$\frac{1}{{\sqrt {2\pi } \sigma }}$;
在$x=\mu \pm \sigma$处有拐点;
当$\left| x \right| \to \infty $时,曲线无限趋近$x$轴。
4. 随机向量
随机向量:指一组随机变量组成的向量。如果$X_1, X_2,..., X_n$为$n$个随机变量,那么称$(X_1, X_2,..., X_n)$为一个$n$维随机向量。一维随机向量也就是随机变量。随机向量也分为离散随机向量和连续随机向量。
离散随机向量:
一般地,离散随机向量的联合概率分布为:
$$P(X_1=x_{i_2},X_2=x_{i_1},...,X_n=x_{i_n})=p(x_{i_1},x_{i_2},...,x_{i_n}), x_{i_1},x_{i_2},...,x_{i_n}=1,2,... \tag{4.1} $$
与离散随机变量类似,离散随机向量的概率分布满足:
$$p(x_{i_1},x_{i_2},...,x_{i_n}) \ge 0, x_{i_1},x_{i_2},...,x_{i_n} = 1,2,... \tag{4.2} $$
$$\sum\limits_{{i_1}} {\sum\limits_{{i_2}} {...\sum\limits_{{i_3}} {p\left( {{x_{{i_1}}},{x_{{i_2}}},...,{x_{{i_n}}}} \right)} } } = 1 \tag{4.3} $$
连续随机向量:
一般地,连续随机向量的联合密度函数满足:
$$p(x_{i_1},x_{i_2},...,x_{i_n}) \ge 0 \tag{4.4} $$
$$\int_{ - \infty }{ + \infty } { \cdots \int_{ - \infty }{ + \infty } {p\left( {{x_1}, \cdots ,{x_n}} \right)d{x_1} \cdots d{x_n}} } = 1 \tag{4.5} $$
常见的随机向量及其概率分布:
- 多项分布
我们已经知道,二项分布是描述在$n$次伯努利分布中,事件$A$出现的次数的概率分布。那么,将二项分布推广到随机向量,就得到了多项分布。投掷骰子的试验就是典型的多项分布:骰子一般有六个面,假设骰子是均匀的,每次投掷其任一面出现的概率都是1/6,。推广到一般情况,假设骰子有$k$个不同的面,我们总共投掷$n$次。我们定义一个$k$维随机向量$X$,$X_i$定义为进行$n$次投掷中点数$i$出现的次数$(i=1,...,k)$。$\theta_i$定义为点数为$i$的概率。则$X$服从多项分布,其概率分布为:
$$p\left( {{x_1},...,{x_k}|\theta } \right) = P\left( {{X_1} = {x_1}, \cdots {X_k} = {x_k}|{\theta _1}, \cdots ,{\theta _k}} \right) = \frac{{n!}}{{{x_1}! \cdots {x_k}!}}p_1{{x_1}} \cdots p_k{{x_k}} \tag{4.6} $$
其中,$x_1,...,x_k$为非负整数,并且满足$\sum\nolimits_{i = 1}k {{x_i} = n} $。
多项分布的概率分布也可以用$\Gamma$函数表示:
$$p\left( {{x_1},...,{x_k}|\theta } \right) = \frac{{\Gamma \left( {\sum\nolimits_i {{x_i}} } \right)}}{{\prod\nolimits_i {\Gamma \left( {{x_i} + 1} \right)} }}\prod\limits_{i = 1}k {\theta _i{{x_i}}} \tag{4.7} $$
这种表示形式和Dirichlet分布类似,因此Dirichlet分布可以作为多项分布的共轭先验。关于共轭先验的知识我们后续会推出相应的章节。
- 多元正态分布
我们通常研究的问题不是二维的,因此将正态分布升级到混合正态分布(multivariate normal distribution)也称为混合高斯分布,其分布的期望和协方差是多元的:期望$\mu \in Rn$,协方差(二维称为标准差)$\Sigma \in R{n \times n}$,协方差具有对称性和正定性。记为:$X\sim N(\mu, \Sigma)$,其概率密度函数为:
的
其中$\mu$为混合高斯分布的期望$E(X)$,$\Sigma$是其协方差$Cov(X)$,$|\Sigma|$表示其协方差行列式,$\Sigma {-1}$是其协方差的逆。
我们用下图可以更直观的看到混合高斯分布的性质:

以上三个图的期望都是:$\mu = [0,0]T$,最左端的协方差$\Sigma = I$,中间的协方差$\Sigma = 0.6I$,最右端的协方差$\Sigma = 2I$。可以看出,当协方差$\Sigma$变小时,图像变得更加“瘦长”,当协方差$\Sigma$增大时,图像变得更加“扁平”。
5. 边际分布
如果我们知道一组变量的联合概率分布,想要研究其中一个变量的概率分布,这种一个变量的概率分布就称为边际分布。
我们以二维离散随机向量$(X,Y)$为例进行介绍,假设$X$取值为$x_1,x_2,...$;$Y$取值为$y_1,y_2,...$。联合概率分布满足:
$$p\left( {{x_i},{y_j}} \right) \ge 0 \tag{5.1} $$
$$\sum\limits_{i,j} {p\left( {{x_i},{y_j}} \right)} = 1 \tag{5.2} $$
对于联合概率分布$p (x_i,y_j)$,分别对$i$和$j$利用求和法则:
(1)固定$i$:
$$\sum\limits_j {p\left( {{x_i},{y_j}} \right)} = P\left( {X = {x_i}} \right) = p\left( {{x_i}} \right) \tag{5.3} $$
(2)固定$j$:
$$\sum\limits_i {p\left( {{x_i},{y_j}} \right)} = P\left( {Y = {y_j}} \right) = p\left( {{y_j}} \right) \tag{5.4} $$
这里$p(x_i)$和$p(y_j)$就称为$p(x_i,y_j)$的边际分布。
对于二维连续随机向量$(X,Y)$,其边际分布为:
$$p\left( x \right) = \int_{ - \infty }{ + \infty } {p\left( {x,y} \right)dy} \tag{5.5} $$
$$p\left( y \right) = \int_{ - \infty }{ + \infty } {p\left( {x,y} \right)dy} \tag{5.6} $$
6. 条件分布
在很多情况下,我们想要研究“事件在其他事件发生时出现的概率”这种概率就叫做条件概率。具体地,对于离散随机向量$(X,Y)$,已知$X=x_i$的条件下,随机变量$Y=y_i$的条件概率为:
$$P\left( {Y = {y_j}|X = {x_i}} \right) = \frac{{P\left( {X = {x_i},Y = {y_j}} \right)}}{{P\left( {X = {x_i}} \right)}} = \frac{{p\left( {{x_i},{y_j}} \right)}}{{p\left( {{x_i}} \right)}} \tag{6.1} $$
上述公式定义了随机变量$Y$关于随机变量$X$的条件分布。
对于二维连续随机向量$(X,Y)$,已知$X=x$的条件下,随机变量$Y=y$的条件密度函数为:
$$p(y|x)=\frac{{p(x,y)}} {{p(x)}} \tag{6.2} $$
同理,已知$Y=y$的条件下,随机变量$X=x$的条件概率密度为:
$$p(x|y)=\frac{{p(x,y)}} {{p(y)}} \tag{6.3} $$
贝叶斯公式:探索上述两个条件概率$p(y|x)$和$p(x|y)$之间的关系,可以得到:
$$p(y|x)=\frac{{p(x|y)p(y)}}{p(y)} \tag{6.4} $$
这个公式成为贝叶斯公式,利用贝叶斯公式,我们用条件概率通过$p(x|y)$计算出$p(y|x)$。关于贝叶斯网络的知识我们后续会推出相应的章节。
链式法则:对于公式$(7.1)$可写成如下形式:
$$P(X,Y)=P(X)P(Y|X) \tag{6.5} $$
继续将公式$(7.5)$扩展到一般形式,获得下述形式的公式:
$$P(X_1,X_2,...,X_n)=P(X_1)P(X_2|X_1)...P(X_n|X_1,X_2,...,X{n-1}) \tag{6.6} $$
这个公式被称为链式法则,链式法则通常用于计算多个随机变量的联合概率,特别是在变量之间相互为(条件)独立时会非常有用。注意,在使用链式法则时,我们可以选择展开随机变量的顺序;选择正确的顺序通常可以让概率的计算变得更加简单。
7. 独立性和条件独立
在概率论中,独立性是指随机变量的分布不受其他随机变量的影响。在机器学习中,我们通常假设数据之间具有独立性。例如,我们会假设训练样本是从某一底层空间独立提取,而不互相影响。设随机变量$X$和$Y$其独立性可表示为:
$$P(X,Y)=P(X)P(Y) \tag{7.1} $$
如果我们讨论:在给定一个随机变量的条件下,讨论其他随机变量之间的独立性。这种独立性被称为条件独立,简单地表述为,“给定$Z$,$X$和$Y$条件独立”,则:
$$P(X,Y|Z)=P(X|Z)P(Y|Z) \tag{7.2} $$
条件独立并不是普遍存在的,它是一个假设:假设随机变量之间相互独立。然而就是这个假设,常常能发挥强大的作用,可以说这是一个很强的假设。例如,在用贝叶斯作垃圾邮件检测时,假设两个单词是独立的,可能你认为这两个单词经常一起出现是明显不独立的,然而就是这个看似漏洞很大的假设,不仅能大大减小贝叶斯模型的复杂度,而且能很好地判别垃圾邮件。
8. 期望、方差、协方差
随机变量的数字特征,是由随机变量的分布确定、能描述随机变量某些特征的确定的数值。常见的随机变量的数字特征包括:期望、方差、协方差。
期望:期望可以简单地理解为随机变量的平均值。
离散随机变量的期望:
设$x_i$为随机变量$X$的取值,$p_i$为对应的概率,则期望可通过求和获得:
$$E(X)=\sum\limits_{i = 1}{{\rm{ + }}\infty } {{x_i}{p_i}} \tag{8.1} $$
连续随机变量的期望:
设$X$是一个连续型随机变量,其概率密度函数为$f(x)$,则期望可通过积分获得:
$$E(X)=\int_{ - \infty }{ + \infty } {xf\left( x \right)dx} \tag{8.2} $$
期望具有一些常用的性质(线性性质):
- $E(c)=c$
- $E(X+c)=E(X)+c$
- $E(kX)=kE(X)$
- $E(kX+c)=kE(X)+c$
- $E(X+Y)=E(X)+E(Y)$
方差:方差可以简单理解为随机变量取值的分散程度。当我们根据随机变量$X$的概率分布对其进行采样时,随机变量取值会呈现多大的差异性。方差的公式如下:
$$D(X)=E[X-E(X)]2 \tag{8.3} $$
将方差的平方根$\sqrt {D\left( X \right)} $称为标准差。
协方差:方差是计算单一维度的统计特性,为统计多维数据,需要引入协方差。协方差反映数据之间的线性相关性。如果协方差为正,表明两个维度的数据同时增加或减少;如果为负,表明一个维度的增加,另一个维度减少,反之亦然;如果为零,说明两个维度之间没有线性相关性。协方差公式如下:
$$Cov(X,Y)=E[(X-E(X))(Y-E(Y))] \tag{8.4} $$
协方差矩阵:协方差矩阵中的每一个元素表示随机向量不同分量之间的协方差,而不是不同样本之间的协方差。协方差矩阵具有以下性质:
- 协方差矩阵是对阵矩阵;
- 协方差矩阵是半正定(非负定)阵;
- 协方差矩阵的对角元是方差。
9. 随机过程
随机过程( Stochastic Process)是随机变量的集合。若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是 一个随机过程。随机过程是随机变量的集合, 你赋予了 t 时间上的涵义,所以你感觉符合“过程”这个理解,但是实际上随机过程和时间不见得有啥关系。比如给你一张二维的图片,图片上每个像素依某分布产生,那这些像素就组成了一个随机过程,你看到的自变量是个二维平面的坐标。(摘自:邱锡鹏)
10. 马尔科夫随机场
马尔科夫性质是指,当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定现在状态时,它与过去状态(即该过程的历史路径)是条件独立的,那么此随机过程即具有马尔可夫性质。 进一步理解:马尔科夫性质就是一个变量的条件分布(条件是所有其他变量)只与它相邻的一些变量有关系,相邻可以是时域上的或者是空域上的或者其他关系。通常利用这样的假设来简化计算,简化全概率公式,从而让问题可解。
马尔科夫链:具有马尔科夫性质的离散时间随机过程称为马尔科夫链。设有随机过程${X_n,n \in T}$,若对于任意的整数$n \in T$和任意的$i_0,i_1,...,i_{n+1}$,其中$T={0,1,2...}$为离散的时间序列,$I={i_0,i_1,...,i_{n+1}}$为$X_n$所有可能取值的全体组成的状态变量,如果条件概率满足:
$$P{X_{n+1}=i_{n+1}|X_0=i_0,X_1=i_1,...,X_n=i_n}=P{X_{n+1}=i_{n+1}|X_n=i_n} \tag{10.1} $$
则称该随机过程为马尔科夫链,简称马氏链。所以马尔科夫链的统计特性完全由条件概率$P{X_{n+1}=i_{n+1}|X_n=i_n}$决定,所以如何确定和利用条件概率是研究马尔科夫链的关键。
贝叶斯理论
贝叶斯方法是机器学习的一个重要方法,贝叶斯方法的名称是以其发现者Thomas Bayes命名的。贝叶斯思想试图描述的是观察者知识状态(概率分布)在新的观测发生后如何更新。

1. 贝叶斯公式
$$P\left( {A|B} \right) = P\left( A \right)\frac{{P\left( {B|A} \right)}}{{P\left( B \right)}} \tag{1}$$
这个公式即为后验概率=(似然*先验概率)/标准化常量,也就是说,后验概率与先验概率和似然函数的乘积成正比。那么什么是先验概率、后验概率、似然函数呢?
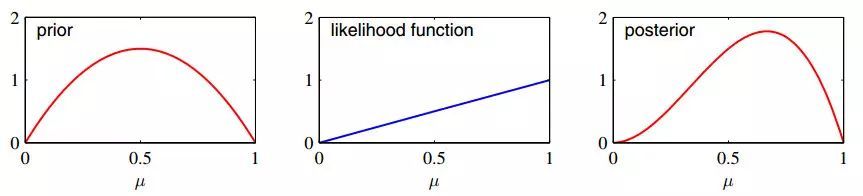
- 先验概率(Prior probability):在贝叶斯统计中,先验概率是关于某个随机变量的概率分布,是在确定该随机变量最终服从的概率分布之前,对其服从的分布进行的最初的猜测。
- 似然函数(Likelihood function):似然函数也是一个函数,是描述观测结果分布的参数的函数。例如在抛掷100次硬币后,有80次是正面,20次反面,似然函数就是要模拟这堆观测数据的概率分布。同时有理由相信,在接下来的投掷硬币的结果概率也服从这个分布。最大化似然函数就是要根据观测结果来获得更逼近观测数据的分布。
- 后验概率(Posterior probability):后验概率分布即在已知给定的数据后,对不确定性的条件分布。“后验”的意思是:考虑不确定性条件概率和已经获得的观测结果,得到重新修正的概率分布。
举个例子,比如抛硬币试验,如果硬币是均匀的,并且不考虑硬币立起来的情况。按照概率学派的思想,认为硬币的正面/反面的出现概率是固定的,经过很多次的试验后,可得到硬币正面/反面的概率都是0.5。那么如果硬币不是均匀的呢?贝叶斯思想认为,硬币正面/反面出现的概率是可变的,需要经过很多次试验才能近似确定这个概率。首先,先设定先验概率;然后进行试验将观测结果作为似然;最后先验获得修正后的后验概率分布。通过不断的抛硬币实验,不断更新分布使之逼近真实分布。
2. 常用的贝叶斯网络模型
2.1 朴素贝叶斯
朴素贝叶斯,是“朴素”和“贝叶斯”组成的,前面我们已经介绍了贝叶斯公式,这里的朴素贝叶斯就是给贝叶斯增加了一个条件:特征属性条件独立。就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。但是,基于朴素贝叶斯的垃圾邮件过滤器却在实践中取得了令人惊讶的效果。
利用朴素贝叶斯进行分类,给定一个有$d$维特征的样本$x$和类别$y$,类别的后验概率为:
$$p\left( {y|x} \right) = p\left( {y|{x_1}, \cdots ,{x_d}} \right) = \frac{{p\left( {{x_1}, \cdots ,{x_d}|y} \right)p\left( y \right)}}{{p\left( {{x_1}, \cdots ,{x_d}} \right)}} \propto p\left( {{x_1}, \cdots ,{x_d}|y} \right)p\left( y \right) \tag{2}$$
假设在给定$y$的情况下,$x_i$之间是条件独立的,那么,上式可简化为:
$$p\left( {y|x} \right) \propto p\left( y \right)\prod\limits_{i = 1}d {p\left( {{x_i}|y} \right)} \tag{3}$$
这个条件独立性的要求非常严格,在实际场景中往往难以满足。但是贝叶斯分类器之所以在垃圾邮件过滤中取得良好的效果,有人对此提出了一个理论解释,并且建立了什么时候朴素贝叶斯的效果能够等价于非朴素贝叶斯的充要条件,这个解释的核心就是:有些独立假设在各个分类之间的分布都是均匀的所以对于似然的相对大小不产生影响;即便不是如此,也有很大的可能性各个独立假设所产生的消极影响或积极影响互相抵消,最终导致结果受到的影响不大。
2.2 分层贝叶斯
层次贝叶斯模型是一个统计模型,用来为具有不同水平的问题进行建模,通过贝叶斯方法估计后验分布的参数。层级贝叶斯模型是现代贝叶斯方法的标志性建筑之一,前面讲的贝叶斯,都是在同一个事物层次上的各个因素之间进行统计推理,然而层次贝叶斯模型更深入了一层,将这些因素背后的因素)囊括进来。
隐马尔科夫模型(HMM):引用吴军对隐马尔科夫的介绍:利用隐马尔科夫模型解决“怎么根据接收到的信息来推测说话者想表达的意思呢?”。以语音识别为例,当我们观测到语音信号 $o_1,o_2,o_3$ 时,我们要根据这组信号推测出发送的句子$s_1,s_2,s_3$ 。显然,我们应该在所有可能的句子中找最有可能性的一个。用数学语言来描述,就是在已知 $o_1,o_2,o_3$的情况下,求使得条件概率$P(s_1,s_2,s_3,...|o_1,o_2,o_3)$ 达到最大值的那个句子 。
3. 参数估计
机器学习中的问题最终都是转化为参数求解问题,贝叶斯网络的参数估计一般是利用最大似然估计的方法求出一个最有可能接近实际观测的估计值。
贝叶斯网络中,所有变量的联合概率分布可以分解为每个随机变量的局部条件概率的练成形式。假设每个局部条件概率$p(x_k|x_{\pi_k})$的参数为$\theta_k$,则其对数似然函数为(一般用最大似然估计前一般要取对数,以方便计算):
$$\log p\left( {x,\Theta } \right) = \sum\limits_{k = 1}K {\log p\left( {{x_k}|{x_{{\pi _k}}},{\theta _k}} \right)} \tag{4}$$
根据邱锡鹏老师描述:最大化$x$的对数似然,只需要分别地最大化每个条件似然$logp(x_k|x_{\pi_k},\theta_k)$。如果$ x$ 中所有变量都是可观测的并且是离散的,只需要在训练集上统计每个变量的条件概率表即可。但是条件概率表需要的参数比较多。假设条件概率$p(x_k|x_{\pi_k})$的父节点数量为$M$,所有变量为二值变量,其条件概率表需要$2M$ 个参数。有时为了减少参数数量,我们可以使用参数化的模型,比如 logistic sigmoid函数。如果所有变量是连续的,我们可以使用高斯函数来表示条件概率分布。前者就是 sigmoid信念网络,后者就是高斯信念网络。在此基础上,我们可以所有的条件概率分布共享使用同一组参数来进一步减少参数数量。
如果x中所有变量都是可观测的,对于每个对数条件似然函数$logp(x_k|x_{\pi_k},\theta_k)$,我们可以将$x_{\pi_k}$作为输入变量,$x_k$作为输出变量,并使用监督学习的方法来需要每个参数 $\theta_k$。如果变量中有一部分变量为隐变量,就需要使用 EM算法来进行参数估计。
4. 贝叶斯网络
在第10节我们介绍了马尔科夫链,与之类似,贝叶斯网络中每个状态值取决于前面有限个状态。贝叶斯网又称为“信念网”,与马尔科夫链不同的是,贝叶斯网络比马尔可夫链灵活,它不受马尔可夫链的链状结构的约束,因此可以更准确地描述事件之间的相关性。可以讲,马尔可夫链是贝叶斯网络的特例,而贝叶斯网络是马尔可夫链的推广。使用贝叶斯网络必须知道各个状态之间相关的概率。贝叶斯网络的拓扑结构是一个有向无环图。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“(children)”,两节点就会产生一个条件概率值。下面是一个简单的贝叶斯网络:
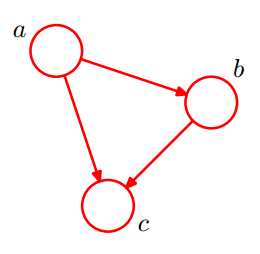
其全概率公式如下:
$$p(a,b,c)=p(c|a,b)p(b|a)p(a) \tag{5}$$
参考文献
- 数学之美番外篇:平凡而又神奇的贝叶斯方法
- 数学之美 - 吴军
- 概率论与数理统计-同济大学
- 神经网络与深度学习-数学基础
- 神经网络与深度学习-概率图模型
- 深度学习- 伊恩古德费罗
- 机器学习-周志华
- 从贝叶斯方法谈到贝叶斯网络- (http://blog.csdn.net/zdy0_2004/article/details/41096141)
- 你对贝叶斯统计都有怎样的理解 - 知乎话题
展开全文