朱俊彦团队提出GAN压缩算法:计算量减少20倍,生成效果不变,GPU、CPU统统能加速
边策 鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
现如今,GAN的效果已经越来越出神入化。
比如英伟达的GauGAN,就如神笔马良,能够凭空造物:

不过,从无化有背后,计算量也相当惊人。
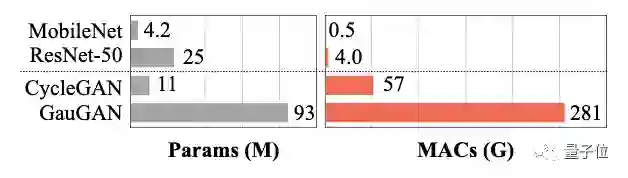
以GauGAN为例,与MobileNet-v3这样的识别CNN相比,参数只相差1个数量级(4.2 : 93)计算强度却高出了2个数量级(0.5 : 281)。
如此一来,交互式部署就变得很困难。
更直白来说,想要把模型部署到手机、平板这样的终端,换装变脸转性别,这些边缘设备——吃不太消。
为了解决这一问题,来自MIT、Adobe研究院和上海交通大学的团队琢磨出了一个通用压缩框架。
有多强?
一举将CycleGAN的计算量减少了20倍以上,将GauGAN的计算量减少了9倍,简笔画到实物图的pix2pix也能驾驭,效果却未差分毫。

值得一提的是。论文已入选CVPR 2020,代码也已开源。
作者团队也星光璀璨,一作是来自上海交通大学ACM班的本科生李沐阳,CycleGAN的作者朱俊彦则亲身参与、指导。
GAN压缩算法
压缩GAN,并不像压缩其他CNN模型那样容易。
主要原因:GAN的训练动力学高度不稳定,生成器与鉴别器之间存在巨大的结构差异,让我们很难使用现有的CNN压缩算法。
为了解决这个问题,作者提出了针对有效生成模型量身定制的训练方案,并通过神经架构搜索(NAS)进一步提高压缩率。
GAN压缩的框架如下图所示,主要分为3个部分:
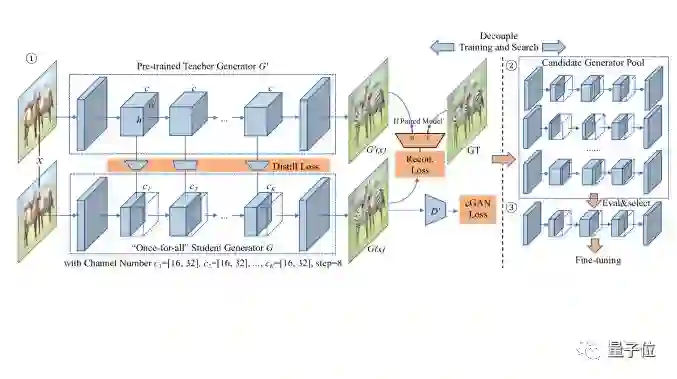
1、给定一个预训练的teacher生成器G’,通过蒸馏的方法获取一个较小的“once-for-all”的student生成器G,其中包括通过权重共享的所有可能通道数。在每个训练步骤中选择不同的通道数ck。
2、从“once-for-all”生成器中提取许多子生成器,并评估其性能,无需重新训练,这也是被叫做once-for-all(一劳永逸)的原因。
3、最后,根据给定的压缩率目标和性能目标,选择最佳子生成器,进行微调,并获得最终的压缩模型。
构造合适的损失函数
因为GAN压缩算法要面对CycleGAN、pix2pix还有GauGAN,这些模型的损失函数都不尽相同,所以需要构造一个新的损失函数。
统一未配对和配对学习
有些GAN是通过配对数据集学习的,有些则是非配对数据集。因此要在损失函数中加入第二项,统一非配对和配对学习的损失:
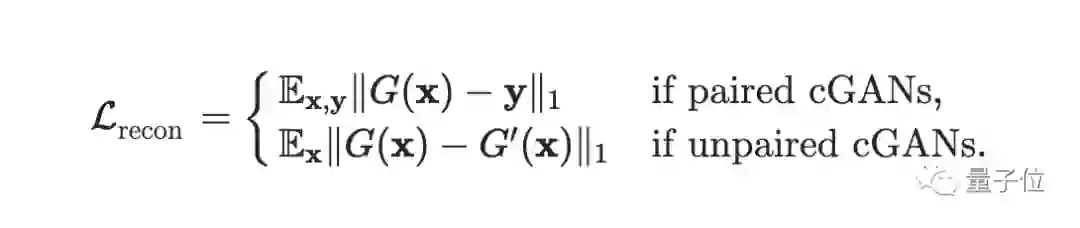
继承teacher鉴别器
尽管目标是压缩生成器,但是鉴别器会存储学习到GAN知识,因为它会发现当前生成器的缺点。
因此,我们采用相同的鉴别器架构,使用teacher预训练的权重,并与我们的压缩生成器一起对鉴别器进行微调。预训练的鉴别器可以指导student生成器的训练。
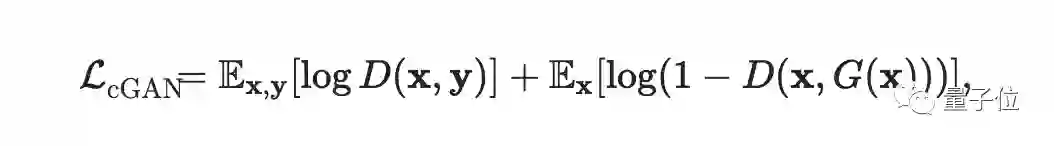
初始化的student鉴别器D使用来自teacher鉴别器D’的权重。
中间特征蒸馏
蒸馏是CNN中广泛使用的模型压缩方法。
CNN模型压缩的一种广泛使用的方法是知识蒸馏。通过匹配输出层的logits,可以将知识从teacher模型转移到student模型,从而提高后者的表现。
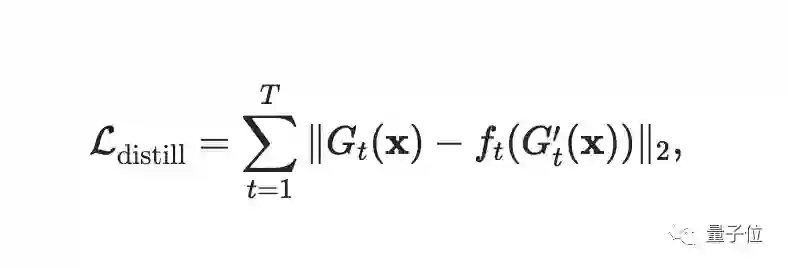
最后完整的损失函数为:
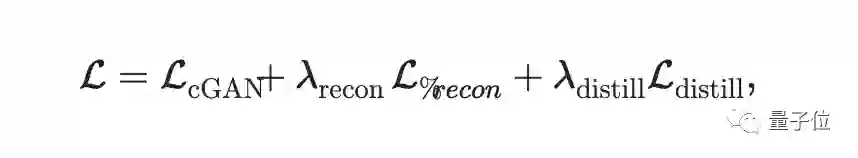
其中超参数λrecon和λdistill控制后两项的权重。
高效的生成器设计空间
选择设计良好的student体系结构对于最终进行知识蒸馏至关重要。
简单地缩小teacher模型的通道数并不能产生紧凑的student模型,一旦计算量的压缩比超过4倍,性能就会开始显著下降。
预测可能的原因之一是,现有的生成器采用的图像识别模型,可能不是图像合成任务的最佳选择。
下面,作者展示了如何从现有的cGAN生成器中获得更好的架构设计空间,并在该空间内执行神经架构搜索(NAS)。
卷积分解和层敏感性
近来高效的CNN设计,广泛采用了卷积分解的方法,证明了在性能与计算之间的权衡取舍。作者发现使用分解的卷积,也有利于cGAN中的生成器设计。
然而实验表明,将分解直接应用于所有卷积层,将大大降低图像质量。但是可以只有某些层分解会降低性能,而某些层则更鲁棒。
在ResNet生成器中,resBlock层消耗了大部分模型参数和计算成本,而几乎不受分解的影响。相反,上采样层的参数要少得多,但是对模型压缩相当敏感,适度的压缩也会导致FID大幅下降。
NAS自动裁剪通道
现在的生成器在所有层上都使用手动设计,因此通道数会有冗余。为了进一步压缩模型,作者使用通道修剪自动选择生成器的通道宽度减少冗余,可以二次减少计算量。
对于每个卷积层,可以从8的倍数中选择通道数,可以平衡MAC和硬件并行性。
解耦训练和结构搜索
为了解决该问题,作者遵循one-shot神经体系结构搜索方法的最新工作,将模型训练与体系结构搜索分离 。
先训练一个支持所有通道的“once-for-all”网络,具有不同数量通道的每个子网络都经过同等训练,可以独立运行,子网络与“once-for-all”网络共享权重。
在训练了“once-for-all”网络后,通过直接在验证集上评估每个候选子网络的性能来找到最佳子网。由于“once-for-all”网络经过权重共享的全面训练,因此无需进行微调。
通过这种方式,我们可以将训练和搜索生成器体系结构分离开来:只需要训练一次,在无需进一步训练的情况下评估所有可能的通道配置,并选择最佳的作为搜索结果。
实验结果
最终实验结果如下:
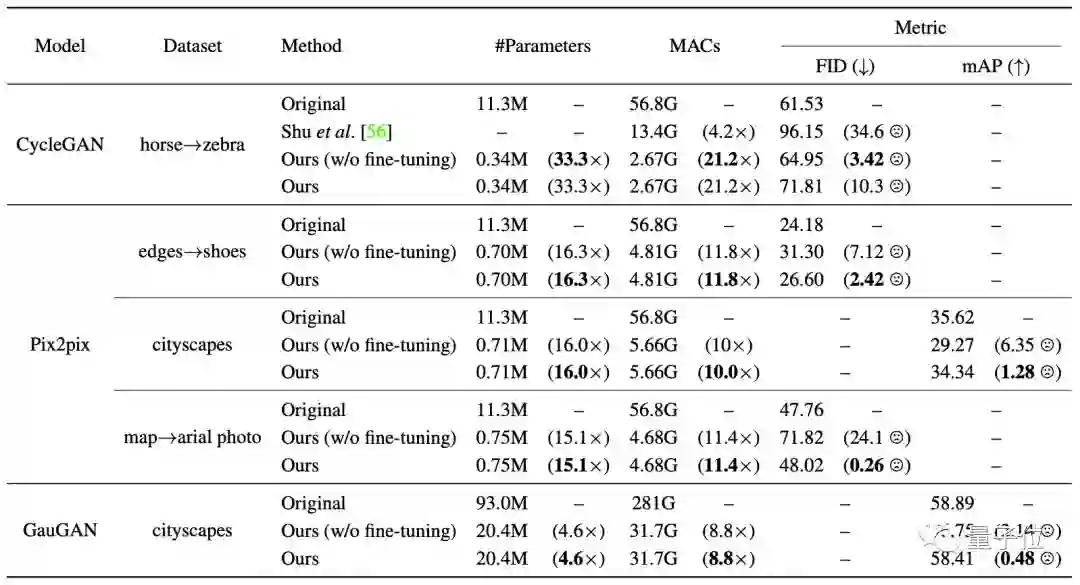
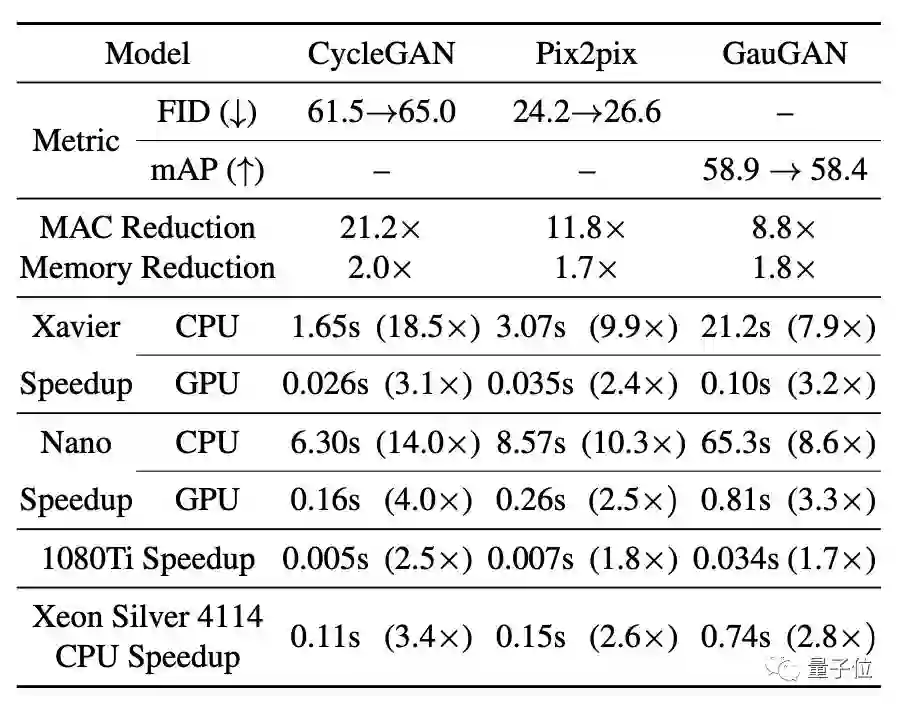
GAN压缩将乘法累加运算(MAC)的数量减了9~21倍。
这种方法将CycleGAN的计算量减少了20倍以上,将pix2pix的计算量减少了9倍,将GauGAN的计算量减少了9倍。
而且不仅能在GPU上加速,在各种各种各样的CPU上也可以实现加速,而且加速效果在CPU上更明显。
代码开源
现在,这一GAN压缩框架已经开源,数据集和预训练模型均可下载。
如果想要上手亲测,需要的环境是:
Linux
Python 3
CPU or NVIDIA GPU + CUDA CuDNN
同时,研究团队也准备了CycleGAN和pix2pix两个版本的PyTorch Colab,在线即可体验。
试试用CycleGAN把普通马变斑马的效果。
首先把GAN Compression这个项目克隆下来:
!git clone https://github.com/mit-han-lab/gan-compression.git
下载测试数据集:
!bash datasets/download_cyclegan_dataset.sh horse2zebra
下载预训练模型:
python scripts/download_model.py —model pix2pix —task edges2shoes-r —stage full
python scripts/download_model.py —model pix2pix —task edges2shoes-r —stage compressed
下面,就是见证换皮的时刻:

效果差距大不大,肉眼看了不算,还是要计算一下FID(用于评估GAN生成图像的质量,分数越低代表与真实图像越相似)。
该项目提供了几个数据集的真实统计信息:
bash ./datasets/download_real_stat.sh horse2zebra A
bash ./datasets/download_real_stat.sh horse2zebra B
测试的结果显示,原始CycleGAN的FID是65.687,压缩后,模型的FID是65.312,两者差距不大。
但在MAC、参数规模和延迟方面,压缩模型都要远远小于原始模型。

上海交大本科生一作,朱俊彦&韩松加持
论文一作,是上海交通大学ACM班大四本科生李沐阳。

2019年7月-今年1月,李沐阳师从MIT韩松教授和朱俊彦教授,在MIT Han Lab担任研究助理,这篇CVPR 2020论文就是在此期间产出。
目前,李沐阳的研究兴趣在于机器学习、系统以及计算机图形学等领域,他计划在今年毕业之后继续读博深造。
科研之余,李沐阳同学的一大爱好是唱歌。在他的个人主页上,他还分享了自己的唱吧链接,以及个人MV。

论文的另外几位作者,分别是:
Ji Lin,本科毕业于清华大学,现于MIT就读博士。
丁尧尧,同样是来自上海交大ACM班的本科生,和李沐阳同在MIT Han Lab担任研究助理,受韩松教授指导。
Zhijian Liu,本科毕业于上海交大,现于韩松教授门下就读博士。
朱俊彦,李沐阳的指导者之一。这位青年大牛无需多介绍,CycleGAN作者,国际顶会ACM SIGGRAPH 2018最佳博士论文奖获得者。现为Adobe研究科学家,今年秋天将回归母校CMU担任助理教授。
韩松,MIT EECS助理教授,同样是AI业界大牛。博士毕业于斯坦福大学,曾斩获ICLR 2016最佳论文、FPGA 2017最佳论文。
传送门
论文地址:
https://arxiv.org/abs/2003.08936
GitHub:
https://github.com/mit-han-lab/gan-compression
李沐阳个人主页:
https://lmxyy.me
Colab:
https://colab.research.google.com/github/mit-han-lab/gan-compression/blob/master/cycle_gan.ipynb
https://colab.research.google.com/github/mit-han-lab/gan-compression/blob/master/pix2pix.ipynb
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
今晚直播 | 地平线BPU重新定义极致效能


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !


