【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
点击上方“专知”关注获取更多AI知识!
【导读】主题荟萃知识是专知的核心功能之一,为用户提供AI领域系统性的知识学习服务。主题荟萃为用户提供全网关于该主题的精华(Awesome)知识资料收录整理,使得AI从业者便捷学习和解决工作问题!在专知人工智能主题知识树基础上,主题荟萃由专业人工编辑和算法工具辅助协作完成,并保持动态更新!另外欢迎对此创作主题荟萃感兴趣的同学,请加入我们专知AI创作者计划,共创共赢! 今天专知为大家呈送第六篇专知主题荟萃计算机视觉Computer Vison知识资料大全集荟萃 (入门/进阶/论文/课程/会议/专家等等),请大家查看!专知访问www.zhuanzhi.ai, 或关注微信公众号后台回复" 专知"进入专知,搜索主题“计算机视觉”查看。此外,我们也提供该文pdf下载链接,请文章末尾查看!此为初始版本,请大家指正补充,欢迎在后台留言!欢迎大家分享转发~
了解专知,专知,一个新的认知方式!
计算机视觉(computer vision)荟萃
入门学习
进阶论文
Image Classification
Object Detection
Video Classification
Object Tracking
Segmentation
Object Recognition
Image Captioning
Video Captioning
Visual Question Answering
Edge Detection
Human Pose Estimation
Image Generation
课程
综述
Turorial
图书
相关期刊与会议
国际会议
期刊
领域专家
华人机构和学者
North America
Europe
Australia
Asia and Middle East
Software
Datasets
Challenge
创业公司
公众号
入门学习
计算机视觉:让冰冷的机器看懂这个多彩的世界 by 孙剑
[http://www.msra.cn/zh-cn/news/features/computer-vision-20150210]
UCLA朱松纯: 正本清源·初探计算机视觉的三个源头、兼谈人工智能
深度学习与视觉计算 by 王亮 中科院自动化所
[http://www.caai.cn/index.php?s=/Home/Article/qikandetail/year/2017/month/04.html]
如何做好计算机视觉的研究? by 微软 华刚博士
[http://www.msra.cn/zh-cn/news/features/do-research-in-computer-vision-20161205]
计算机视觉 微软亚洲研究院系列文章
通俗介绍计算机视觉在生活中的各种应用。
[http://www.msra.cn/zh-cn/research/computer-vision]
计算机视觉随谈
[http://blog.csdn.net/zouxy09/article/details/38639349]
计算机视觉:就在你我身边 微软
什么是计算机视觉?什么是机器视觉?
卷积神经网络如何进行图像识别
[http://www.infoq.com/cn/articles/convolutional-neural-networks-image-recognition]
相似图片搜索的原理 阮一峰
[http://www.ruanyifeng.com/blog/2011/07/principle_of_similar_image_search.html\]
如何识别图像边缘? 阮一峰
[http://www.ruanyifeng.com/blog/2016/07/edge-recognition.html]
图像目标检测(Object Detection)原理与实现 (1-6)
[http://www.voidcn.com/article/p-xnjyqlkj-ua.html]
运动目标跟踪系列(1-17)
[http://blog.csdn.net/App_12062011/article/category/6269524/1]
看图说话的AI小朋友——图像标注趣谈(上,下)
[https://zhuanlan.zhihu.com/p/22408033]
[https://zhuanlan.zhihu.com/p/22520434]
Video Analysis 相关领域介绍之Video Captioning(视频to文字描述)
[https://zhuanlan.zhihu.com/p/26730181]
从特斯拉到计算机视觉之「图像语义分割」
[https://zhuanlan.zhihu.com/p/21824299]
计算机视觉识别简史:从 AlexNet、ResNet 到 Mask RCNN
[https://github.com/Nikasa1889/HistoryObjectRecognition]
[https://github.com/Nikasa1889/HistoryObjectRecognition/blob/master/HistoryOfObjectRecognition%20-%20A0.pdf]
深度学习在计算机视觉领域的前沿进展
[https://zhuanlan.zhihu.com/p/24699780]
深度学习时代的计算机视觉 [https://mp.weixin.qq.com/s/gExfzCxjHrSb7afn33f-lA]
视觉求索 公众号相关文章系列,
浅谈人工智能:现状、任务、构架与统一 | 正本清源 [http://mp.weixin.qq.com/s/-wSYLu-XvOrsST8_KEUa-Q]
人生若只如初见 | 学术人生 [https://mp.weixin.qq.com/s/kFA7bI_FFjZQkBNDvcn01g]
初探计算机视觉的三个源头、兼谈人工智能|正本清源 [https://mp.weixin.qq.com/s/2ytV5Bt50yhYOFYXYQe6ZQ]
深度学习大讲堂 公众号相关文章系列
深度学习在目标跟踪中的应用 [https://zhuanlan.zhihu.com/p/22334661]
深度学习在图像取证中的进展与趋势 [https://zhuanlan.zhihu.com/p/23341157]
行人检测、跟踪与检索领域年度进展报告 [https://zhuanlan.zhihu.com/p/26807041]
基于深度学习的目标检测研究进展 [https://zhuanlan.zhihu.com/p/21412911]
基于深度学习的视觉实例搜索研究进展 [https://zhuanlan.zhihu.com/p/22265265]
基于深度学习的VQA(视觉问答)技术 [https://zhuanlan.zhihu.com/p/22530291]
人脸识别简史与近期进展 [https://zhuanlan.zhihu.com/p/21465605]
边缘检测领域年度进展报告 [https://zhuanlan.zhihu.com/p/26848831]
目标跟踪领域进展报告 [https://zhuanlan.zhihu.com/p/27293523]
进阶论文
Image Classification
Microsoft Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition [http://arxiv.org/pdf/1512.03385v1.pdf] [[http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf]]
Microsoft Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, [http://arxiv.org/pdf/1502.01852]
Batch Normalization Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[http://arxiv.org/pdf/1502.03167]
GoogLeNet Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, CVPR, 2015. [http://arxiv.org/pdf/1409.4842]
VGG-Net Karen Simonyan and Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Visual Recognition, ICLR, 2015. [http://www.robots.ox.ac.uk/~vgg/research/very_deep/] [http://arxiv.org/pdf/1409.1556]
AlexNet Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks, NIPS, 2012. [http://papers.nips.cc/book/advances-in-neural-information-processing-systems-25-2012]
Object Detection
Deep Neural Networks for Object Detection (基于DNN的对象检测)NIPS2013:
[https://cis.temple.edu/~yuhong/teach/2014_spring/papers/NIPS2013_DNN_OD.pdf]
R-CNN Rich feature hierarchies for accurate object detection and semantic segmentation:
[https://arxiv.org/abs/1311.2524]
Fast R-CNN :
[http://arxiv.org/abs/1504.08083]
Faster R-CNN Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks:
[http://arxiv.org/abs/1506.01497]
Scalable Object Detection using Deep Neural Networks
[http://arxiv.org/abs/1312.2249]
Scalable, High-Quality Object Detection
[http://arxiv.org/abs/1412.1441]
SPP-Net Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[http://arxiv.org/abs/1406.4729]
DeepID-Net DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection
[http://www.ee.cuhk.edu.hk/%CB%9Cwlouyang/projects/imagenetDeepId/index.html]
Object Detectors Emerge in Deep Scene CNNs
[http://arxiv.org/abs/1412.6856]
segDeepM: Exploiting Segmentation and Context in Deep Neural Networks for Object Detection
[https://arxiv.org/abs/1502.04275]
Object Detection Networks on Convolutional Feature Maps
[http://arxiv.org/abs/1504.06066]
Improving Object Detection with Deep Convolutional Networks via Bayesian Optimization and Structured Prediction
[http://arxiv.org/abs/1504.03293]
DeepBox: Learning Objectness with Convolutional Networks
[http://arxiv.org/abs/1504.03293]
Object detection via a multi-region & semantic segmentation-aware CNN model
[http://arxiv.org/abs/1505.01749]
You Only Look Once: Unified, Real-Time Object Detection
[http://arxiv.org/abs/1506.02640]
YOLOv2 YOLO9000: Better, Faster, Stronger
[https://arxiv.org/abs/1612.08242]
AttentionNet: Aggregating Weak Directions for Accurate Object Detection
[http://arxiv.org/abs/1506.07704]
DenseBox: Unifying Landmark Localization with End to End Object Detection
[http://arxiv.org/abs/1509.04874]
SSD: Single Shot MultiBox Detector
[http://arxiv.org/abs/1512.02325]
DSSD : Deconvolutional Single Shot Detector
[https://arxiv.org/abs/1701.06659]
G-CNN: an Iterative Grid Based Object Detector
[http://arxiv.org/abs/1512.07729]
HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection
[http://arxiv.org/abs/1604.00600]
A MultiPath Network for Object Detection
[http://arxiv.org/abs/1604.02135]
R-FCN: Object Detection via Region-based Fully Convolutional Networks
[http://arxiv.org/abs/1605.06409]
A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
[http://arxiv.org/abs/1607.07155]
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
[http://arxiv.org/abs/1608.08021]
Feature Pyramid Networks for Object Detection
[https://arxiv.org/abs/1612.03144]
Learning Chained Deep Features and Classifiers for Cascade in Object Detection
[https://arxiv.org/abs/1702.07054]
DSOD: Learning Deeply Supervised Object Detectors from Scratch
[https://arxiv.org/abs/1708.01241]
Focal Loss for Dense Object Detection ICCV 2017 Best student paper award. Facebook AI Research
[https://arxiv.org/abs/1708.02002]
Mask-RCNN 2017 ICCV 2017 Best paper award. Facebook AI Research - [https://arxiv.org/pdf/1703.06870.pdf]
Video Classification
Nicolas Ballas, Li Yao, Pal Chris, Aaron Courville, "Delving Deeper into Convolutional Networks for Learning Video Representations", ICLR 2016. [http://arxiv.org/pdf/1511.06432v4.pdf]
Michael Mathieu, camille couprie, Yann Lecun, "Deep Multi Scale Video Prediction Beyond Mean Square Error", ICLR 2016. Paper [http://arxiv.org/pdf/1511.05440v6.pdf]
Donahue, Jeffrey, et al. Long-term recurrent convolutional networks for visual recognition and description CVPR 2015 [https://arxiv.org/abs/1411.4389]
Karpathy, Andrej, et al. Large-scale Video Classification with Convolutional Neural Networks. CVPR 2014 [http://cs.stanford.edu/people/karpathy/deepvideo/]
Yue-Hei Ng, Joe, et al. Beyond short snippets: Deep networks for video classification. CVPR 2015 [https://arxiv.org/abs/1503.08909]
Tran, Du, et al. Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV 2015 [https://arxiv.org/abs/1412.0767]
Object Tracking
NIPS2013
DLT: Naiyan Wang and Dit-Yan Yeung. "Learning A Deep Compact Image Representation for Visual Tracking." NIPS (2013).
paper [http://winsty.net/papers/dlt.pdf)]
project [http://winsty.net/dlt.html)]
code [http://winsty.net/dlt/DLTcode.zip)]
CVPR2014
CN: Martin Danelljan, Fahad Shahbaz Khan, Michael Felsberg and Joost van de Weijer. "Adaptive Color Attributes for Real-Time Visual Tracking." CVPR (2014).
paper [http://www.cvl.isy.liu.se/research/objrec/visualtracking/colvistrack/CN_Tracking_CVPR14.pdf]
project [http://www.cvl.isy.liu.se/research/objrec/visualtracking/colvistrack/index.html]
ECCV2014
MEEM: Jianming Zhang, Shugao Ma, and Stan Sclaroff. "MEEM: Robust Tracking via Multiple Experts using Entropy Minimization." ECCV (2014).
paper [http://cs-people.bu.edu/jmzhang/MEEM/MEEM-eccv-preprint.pdf]
project [http://cs-people.bu.edu/jmzhang/MEEM/MEEM.html]
TGPR: Jin Gao, Haibin Ling, Weiming Hu, Junliang Xing. "Transfer Learning Based Visual Tracking with Gaussian Process Regression." ECCV (2014).
paper [http://www.dabi.temple.edu/~hbling/publication/tgpr-eccv14.pdf]
project [http://www.dabi.temple.edu/~hbling/code/TGPR.htm]
STC: Kaihua Zhang, Lei Zhang, Ming-Hsuan Yang, David Zhang. "Fast Tracking via Spatio-Temporal Context Learning." ECCV (2014).
paper [http://arxiv.org/pdf/1311.1939v1.pdf]
project [http://www4.comp.polyu.edu.hk/~cslzhang/STC/STC.htm]
SAMF: Yang Li, Jianke Zhu. "A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration." ECCV workshop (2014).
paper [http://link.springer.com/content/pdf/10.1007%2F978-3-319-16181-5_18.pdf]
github [https://github.com/ihpdep/samf]
BMVC2014
DSST: Martin Danelljan, Gustav Häger, Fahad Shahbaz Khan and Michael Felsberg. "Accurate Scale Estimation for Robust Visual Tracking." BMVC (2014).
paper [http://www.cvl.isy.liu.se/research/objrec/visualtracking/scalvistrack/ScaleTracking_BMVC14.pdf]
PAMI [http://www.cvl.isy.liu.se/en/research/objrec/visualtracking/scalvistrack/DSST_TPAMI.pdf]
project [http://www.cvl.isy.liu.se/en/research/objrec/visualtracking/scalvistrack/index.html]
SAMF: Yang Li, Jianke Zhu. "A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration." ECCV workshop (2014).
paper [https://github.com/ihpdep/ihpdep.github.io/raw/master/papers/eccvw14_samf.pdf]
github [https://github.com/ihpdep/samf]
ICML2015
CNN-SVM: Seunghoon Hong, Tackgeun You, Suha Kwak and Bohyung Han. "Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network ." ICML (2015)
paper [http://120.52.73.80/arxiv.org/pdf/1502.06796.pdf]
project [http://cvlab.postech.ac.kr/research/CNN_SVM/]
CVPR2015
MUSTer: Zhibin Hong, Zhe Chen, Chaohui Wang, Xue Mei, Danil Prokhorov, Dacheng Tao. "MUlti-Store Tracker (MUSTer): A Cognitive Psychology Inspired Approach to Object Tracking." CVPR (2015).
paper [http://openaccess.thecvf.com/content_cvpr_2015/papers/Hong_MUlti-Store_Tracker_MUSTer_2015_CVPR_paper.pdf]
project [https://sites.google.com/site/multistoretrackermuster/]
LCT: Chao Ma, Xiaokang Yang, Chongyang Zhang, Ming-Hsuan Yang. "Long-term Correlation Tracking." CVPR (2015).
paper [http://openaccess.thecvf.com/content_cvpr_2015/papers/Ma_Long-Term_Correlation_Tracking_2015_CVPR_paper.pdf]
project [https://sites.google.com/site/chaoma99/cvpr15_tracking]
github [https://github.com/chaoma99/lct-tracker]
DAT: Horst Possegger, Thomas Mauthner, and Horst Bischof. "In Defense of Color-based Model-free Tracking." CVPR (2015).
paper [https://lrs.icg.tugraz.at/pubs/possegger_cvpr15.pdf]
project [https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/dat]
code [https://lrs.icg.tugraz.at/downloads/dat-v1.0.zip]
RPT: Yang Li, Jianke Zhu and Steven C.H. Hoi. "Reliable Patch Trackers: Robust Visual Tracking by Exploiting Reliable Patches." CVPR (2015).
paper [https://github.com/ihpdep/ihpdep.github.io/raw/master/papers/cvpr15_rpt.pdf]
github [https://github.com/ihpdep/rpt]
ICCV2015
FCNT: Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." ICCV (2015).
paper [http://202.118.75.4/lu/Paper/ICCV2015/iccv15_lijun.pdf]
project [http://scott89.github.io/FCNT/]
github [https://github.com/scott89/FCNT]
SRDCF: Martin Danelljan, Gustav Häger, Fahad Khan, Michael Felsberg. "Learning Spatially Regularized Correlation Filters for Visual Tracking." ICCV (2015).
paper [https://www.cvl.isy.liu.se/research/objrec/visualtracking/regvistrack/SRDCF_ICCV15.pdf]
project [https://www.cvl.isy.liu.se/research/objrec/visualtracking/regvistrack/]
CF2: Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang. "Hierarchical Convolutional Features for Visual Tracking." ICCV (2015)
paper [http://faculty.ucmerced.edu/mhyang/papers/iccv15_tracking.pdf]
project [https://sites.google.com/site/jbhuang0604/publications/cf2]
github [https://github.com/jbhuang0604/CF2]
Naiyan Wang, Jianping Shi, Dit-Yan Yeung and Jiaya Jia. "Understanding and Diagnosing Visual Tracking Systems." ICCV (2015).
paper [http://winsty.net/papers/diagnose.pdf]
project [http://winsty.net/tracker_diagnose.html]
code [http://winsty.net/diagnose/diagnose_code.zip]
Segmentation
Alexander Kolesnikov, Christoph Lampert, Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation, ECCV, 2016. [http://pub.ist.ac.at/~akolesnikov/files/ECCV2016/main.pdf] [https://github.com/kolesman/SEC]
Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel, Efficient piecewise training of deep structured models for semantic segmentation, arXiv:1504.01013. [http://arxiv.org/pdf/1504.01013]
Guosheng Lin, Chunhua Shen, Ian Reid, Anton van den Hengel, Deeply Learning the Messages in Message Passing Inference, arXiv:1508.02108. [http://arxiv.org/pdf/1506.02108]
Object Recognition
DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, Trevor Darrell [http://arxiv.org/abs/1310.1531]
CNN Features off-the-shelf: an Astounding Baseline for Recognition CVPR 2014 [http://arxiv.org/abs/1403.6382]
HD-CNN: Hierarchical Deep Convolutional Neural Network for Image Classification intro: ICCV 2015 [https://arxiv.org/abs/1410.0736]
Image Captioning
m-RNN模型《 Explain Images with Multimodal Recurrent Neural Networks》 2014 [https://arxiv.org/pdf/1410.1090.pdf]
NIC模型 《Show and Tell: A Neural Image Caption Generator》2014
MS Captivator From captions to visual concepts and back 2014
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 2015
What Value Do Explicit High Level Concepts Have in Vision to Language Problems? 2016 [https://arxiv.org/pdf/1506.01144.pdf]
Guiding Long-Short Term Memory for Image Caption Generation 2015https://arxiv.org/pdf/1509.04942.pdf
Watch What You Just Said: Image Captioning with Text-Conditional Attention 2016 [https://arxiv.org/pdf/1606.04621.pdf] [https://github.com/LuoweiZhou/e2e-gLSTM-sc]
Generating Natural-Language Video Descriptions Using Text-Mined Knowledge,2014 [https://www.aaai.org/ocs/index.php/AAAI/AAAI13/paper/view/6454/7204]
Self-critical Sequence Training for Image Captioning 2017 CVPR [https://arxiv.org/pdf/1612.00563.pdf]
Video Captioning
Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, Trevor Darrell, Long-term Recurrent Convolutional Networks for Visual Recognition and Description, CVPR, 2015. [http://jeffdonahue.com/lrcn/] [http://arxiv.org/pdf/1411.4389.pdf]
Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko, Translating Videos to Natural Language Using Deep Recurrent Neural Networks, arXiv:1412.4729. UT / UML / Berkeley [http://arxiv.org/pdf/1412.4729]
Yingwei Pan, Tao Mei, Ting Yao, Houqiang Li, Yong Rui, Joint Modeling Embedding and Translation to Bridge Video and Language, arXiv:1505.01861. Microsoft [http://arxiv.org/pdf/1505.01861]
Subhashini Venugopalan, Marcus Rohrbach, Jeff Donahue, Raymond Mooney, Trevor Darrell, Kate Saenko, Sequence to Sequence--Video to Text, arXiv:1505.00487. UT / Berkeley / UML [http://arxiv.org/pdf/1505.00487]
Li Yao, Atousa Torabi, Kyunghyun Cho, Nicolas Ballas, Christopher Pal, Hugo Larochelle, Aaron Courville, Describing Videos by Exploiting Temporal Structure, arXiv:1502.08029 Univ. Montreal / Univ. Sherbrooke [http://arxiv.org/pdf/1502.08029.pdf]]
Anna Rohrbach, Marcus Rohrbach, Bernt Schiele, The Long-Short Story of Movie Description, arXiv:1506.01698 MPI / Berkeley [http://arxiv.org/pdf/1506.01698.pdf]]
Yukun Zhu, Ryan Kiros, Richard Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, Sanja Fidler, Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books, arXiv:1506.06724 Univ. Toronto / MIT [[http://arxiv.org/pdf/1506.06724.pdf]]
Kyunghyun Cho, Aaron Courville, Yoshua Bengio, Describing Multimedia Content using Attention-based Encoder-Decoder Networks, arXiv:1507.01053 Univ. Montreal [http://arxiv.org/pdf/1507.01053.pdf]
Dotan Kaufman, Gil Levi, Tal Hassner, Lior Wolf, Temporal Tessellation for Video Annotation and Summarization, arXiv:1612.06950. TAU / USC [[https://arxiv.org/pdf/1612.06950.pdf]]
Chiori Hori, Takaaki Hori, Teng-Yok Lee, Kazuhiro Sumi, John R. Hershey, Tim K. Marks Attention-Based Multimodal Fusion for Video Description [https://arxiv.org/abs/1701.03126]
Describing Videos using Multi-modal Fusion [https://dl.acm.org/citation.cfm?id=2984065]
Andrew Shin , Katsunori Ohnishi , Tatsuya Harada Beyond caption to narrative: Video captioning with multiple sentences [http://ieeexplore.ieee.org/abstract/document/7532983/]
Jianfeng Dong, Xirong Li, Cees G. M. Snoek Word2VisualVec: Image and Video to Sentence Matching by Visual Feature Prediction [https://pdfs.semanticscholar.org/de22/8875bc33e9db85123469ef80fc0071a92386.pdf]
Multimodal Video Description [https://dl.acm.org/citation.cfm?id=2984066]
Xiaodan Liang, Zhiting Hu, Hao Zhang, Chuang Gan, Eric P. Xing Recurrent Topic-Transition GAN for Visual Paragraph Generation [https://arxiv.org/abs/1703.07022]
Weakly Supervised Dense Video Captioning(CVPR2017)
Multi-Task Video Captioning with Video and Entailment Generation(ACL2017)
Visual Question Answering
Kushal Kafle, and Christopher Kanan. An Analysis of Visual Question Answering Algorithms. arXiv:1703.09684, 2017. [https://arxiv.org/abs/1703.09684]
Hyeonseob Nam, Jung-Woo Ha, Jeonghee Kim, Dual Attention Networks for Multimodal Reasoning and Matching, arXiv:1611.00471, 2016. [https://arxiv.org/abs/1611.00471]
Jin-Hwa Kim, Kyoung Woon On, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhang, Hadamard Product for Low-rank Bilinear Pooling, arXiv:1610.04325, 2016. [https://arxiv.org/abs/1610.04325]
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, Marcus Rohrbach, Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding, arXiv:1606.01847, 2016. [https://arxiv.org/abs/1606.01847] [[code]][https://github.com/akirafukui/vqa-mcb]
Kuniaki Saito, Andrew Shin, Yoshitaka Ushiku, Tatsuya Harada, DualNet: Domain-Invariant Network for Visual Question Answering. arXiv:1606.06108v1, 2016. [https://arxiv.org/pdf/1606.06108.pdf]
Arijit Ray, Gordon Christie, Mohit Bansal, Dhruv Batra, Devi Parikh, Question Relevance in VQA: Identifying Non-Visual And False-Premise Questions, arXiv:1606.06622, 2016. [https://arxiv.org/pdf/1606.06622v1.pdf]
Hyeonwoo Noh, Bohyung Han, Training Recurrent Answering Units with Joint Loss Minimization for VQA, arXiv:1606.03647, 2016. [http://arxiv.org/abs/1606.03647v1]
Edge Detection
Saining Xie, Zhuowen Tu, Holistically-Nested Edge Detection Holistically-Nested Edge Detection [http://arxiv.org/pdf/1504.06375] [https://github.com/s9xie/hed]
Gedas Bertasius, Jianbo Shi, Lorenzo Torresani, DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection, CVPR, 2015. [http://arxiv.org/pdf/1412.1123]
Wei Shen, Xinggang Wang, Yan Wang, Xiang Bai, Zhijiang Zhang, DeepContour: A Deep Convolutional Feature Learned by Positive-Sharing Loss for Contour Detection, CVPR, 2015. [http://mc.eistar.net/UpLoadFiles/Papers/DeepContour_cvpr15.pdf]
Human Pose Estimation
Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh, Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, CVPR, 2017.
Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter Gehler, and Bernt Schiele, Deepcut: Joint subset partition and labeling for multi person pose estimation, CVPR, 2016.
Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and Yaser Sheikh, Convolutional pose machines, CVPR, 2016.
Alejandro Newell, Kaiyu Yang, and Jia Deng, Stacked hourglass networks for human pose estimation, ECCV, 2016.
Tomas Pfister, James Charles, and Andrew Zisserman, Flowing convnets for human pose estimation in videos, ICCV, 2015.
Jonathan J. Tompson, Arjun Jain, Yann LeCun, Christoph Bregler, Joint training of a convolutional network and a graphical model for human pose estimation, NIPS, 2014.
Image Generation
Aäron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu. "Conditional Image Generation with PixelCNN Decoders"[https://arxiv.org/pdf/1606.05328v2.pdfhttps://github.com/kundan2510/pixelCNN][]
Alexey Dosovitskiy, Jost Tobias Springenberg, Thomas Brox, "Learning to Generate Chairs with Convolutional Neural Networks", CVPR, 2015. [http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Dosovitskiy_Learning_to_Generate_2015_CVPR_paper.pdf]
Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, Daan Wierstra, "DRAW: A Recurrent Neural Network For Image Generation", ICML, 2015. [https://arxiv.org/pdf/1502.04623v2.pdf]
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Networks, NIPS, 2014. [http://arxiv.org/abs/1406.2661]
Emily Denton, Soumith Chintala, Arthur Szlam, Rob Fergus, Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks, NIPS, 2015. [http://arxiv.org/abs/1506.05751]
课程
斯坦福视觉实验室主页:http://vision.stanford.edu/ 李飞飞组CS131, CS231A, CS231n 三个课程,可是说是最好的计算机视觉课程。
CS 131 Computer Vision: Foundations and Applications: 基础知识:主要讲传统的边缘检测,特征点描述,相机标定,全景图拼接等知识 [http://vision.stanford.edu/teaching/cs131_fall1415/schedule.html]
CS231A Computer Vision: from 3D reconstruction to recognition: [http://cvgl.stanford.edu/teaching/cs231a_winter1415/schedule.html]
CS231n 2017: Convolutional Neural Networks for Visual Recognition 主要讲卷积神经网络的具体结构,各组成部分的原理优化以及各种应用。 [http://vision.stanford.edu/teaching/cs231n/] 国内地址:[http://www.bilibili.com/video/av13260183/]
Stanford CS231n 2016 : Convolutional Neural Networks for Visual Recognition
homepage: [http://cs231n.stanford.edu/]
homepage: [http://vision.stanford.edu/teaching/cs231n/index.html]
syllabus: [http://vision.stanford.edu/teaching/cs231n/syllabus.html]
course notes: [http://cs231n.github.io/]
youtube: [https://www.youtube.com/watch?v=NfnWJUyUJYU&feature=youtu.be]
mirror: [http://pan.baidu.com/s/1pKsTivp]
mirror: [http://pan.baidu.com/s/1c2wR8dy]
网易中文字幕:[http://study.163.com/course/introduction/1003223001.htm]
assignment 1: [http://cs231n.github.io/assignments2016/assignment1/]
assignment 2: [http://cs231n.github.io/assignments2016/assignment2/]
assignment 3: [http://cs231n.github.io/assignments2016/assignment3/]
1st Summer School on Deep Learning for Computer Vision Barcelona: (July 4-8, 2016)
youtube: [https://www.youtube.com/user/imatgeupc/videos?shelf_id=0&sort=dd&view=0]
深度学习计算机视觉夏季学校课程, 包含基础知识以及许多深度学习在计算机视觉中的应用,比如分类,检测,captioning等等
homepage(slides+videos): [http://imatge-upc.github.io/telecombcn-2016-dlcv/]
homepage: [https://imatge.upc.edu/web/teaching/deep-learning-computer-vision]
2nd Summer School on Deep Learning for Computer VisionBarcelona (June 21-27, 2017) [https://telecombcn-dl.github.io/2017-dlcv/]
综述
Annotated Computer Vision Bibliography: Table of Contents. Since 1994 Keith Price从1994年开始做了这个索引,涵盖了所有计算机视觉里面所有topic,所有subtopic的著作,包括论文,教材,还对各类主题的关键词。这个网站频繁更新(最近一次是2017年8月28号),收录每个方向重要期刊,会议文献和书籍,并且保证了所有链接不失效。
What Sparked Video Research in 1877? The Overlooked Role of the Siemens Artificial Eye by Mark Schubin 2017 [http://ieeexplore.ieee.org/document/7857854/]
Giving machines humanlike eyes. by Posch, C., Benosman, R., Etienne-Cummings, R. 2015 [http://ieeexplore.ieee.org/document/7335800/]
Seeing is not enough by Tom GellerOberlin, OH [https://dl.acm.org/citation.cfm?id=2001276]
Visual Tracking: An Experimental Survey [https://dl.acm.org/citation.cfm?id=2693387]
A survey on object recognition and segmentation techniques [http://ieeexplore.ieee.org/document/7724975/]
A Review of Image Recognition with Deep Convolutional Neural Network [https://link.springer.com/chapter/10.1007/978-3-319-63309-1_7\]
Recent Advance in Content-based Image Retrieval: A Literature Survey. Wengang Zhou, Houqiang Li, and Qi Tian 2017 [https://arxiv.org/pdf/1706.06064.pdf]
Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures 2016 [https://www.jair.org/media/4900/live-4900-9139-jair.pdf]
Turorial
Intro to Deep Learning for Computer Vision 2016 [http://chaosmail.github.io/deeplearning/2016/10/22/intro-to-deep-learning-for-computer-vision/]
CVPR 2014 Tutorial on Deep Learning in Computer Vision [https://sites.google.com/site/deeplearningcvpr2014/]
CVPR 2015 Applied Deep Learning for Computer Vision with Torch [https://github.com/soumith/cvpr2015]
Deep Learning for Computer Vision – Introduction to Convolution Neural Networks [http://www.analyticsvidhya.com/blog/2016/04/deep-learning-computer-vision-introduction-convolution-neural-networks/]
A Beginner's Guide To Understanding Convolutional Neural Networks [https://adeshpande3.github.io/adeshpande3.github.io/A-Beginners-Guide-To-Understanding-Convolutional-Neural-Networks/']
CVPR'17 Tutorial Deep Learning for Objects and Scenes by Kaiming He Ross Girshick [http://deeplearning.csail.mit.edu/]
CVPR tutorial : Large-Scale Visual Recognition [http://www.europe.naverlabs.com/Research/Computer-Vision/Highlights/CVPR-tutorial-Large-Scale-Visual-Recognition]
CVPR’16 Tutorial on Image Tag Assignment, Refinement and Retrieval [http://www.lambertoballan.net/2016/06/cvpr16-tutorial-image-tag-assignment-refinement-and-retrieval/]
Tutorial on Answering Questions about Images with Deep Learning The tutorial was presented at '2nd Summer School on Integrating Vision and Language: Deep Learning' in Malta, 2016 [https://arxiv.org/abs/1610.01076]
“Semantic Segmentation for Scene Understanding: Algorithms and Implementations" tutorial [ https://www.youtube.com/watch?v=pQ318oCGJGY]
A tutorial on training recurrent neural networks, covering BPPT, RTRL, EKF and the "echo state network" approach [http://minds.jacobs-university.de/sites/default/files/uploads/papers/ESNTutorialRev.pdf] [http://deeplearning.cs.cmu.edu/notes/shaoweiwang.pdf]
Towards Good Practices for Recognition & Detection by Hikvision Research Institute. Supervised Data Augmentation (SDA) [http://image-net.org/challenges/talks/2016/Hikvision_at_ImageNet_2016.pdf]
Generative Adversarial Networks by Ian Goodfellow, NIPS 2016 tutorial [ https://arxiv.org/abs/1701.00160] [http://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf]
Deep Learning for Computer Vision – Introduction to Convolution Neural Networks [http://www.analyticsvidhya.com/blog/2016/04/deep-learning-computer-vision-introduction-convolution-neural-networks/]
图书
两本经典教材《Computer Vision: A Modern Approach》和《Computer Vision: Algorithms and Applications》,可以先读完第一本再读第二本。
Computer Vision: A Modern Approach by David A. Forsyth, Jean Ponce 英文:[http://cmuems.com/excap/readings/forsyth-ponce-computer-vision-a-modern-approach.pdf] 中文:[https://pan.baidu.com/s/1min99eK]
Computer Vision: Algorithms and Applications by Richard Szeliski 英文:[http://szeliski.org/Book/drafts/SzeliskiBook_20100903_draft.pdf\] 中文:[https://pan.baidu.com/s/1mhYGtio]
Computer Vision: Models, Learning, and Inference by Simon J.D. Prince 书的主页上还有配套的Slider, 代码,tutorial,演示等各种资源。 [http://www.computervisionmodels.com/]
相关期刊与会议
国际会议
CVPR, Computer Vision and Pattern Recognition CVPR 2017:[http://cvpr2017.thecvf.com/]
ICCV, International Conference on Computer Vision ICCV2017:[http://iccv2017.thecvf.com/]
ECCV, European Conference on Computer Vision
SIGGRAPH, Special Interest Group on Computer Graphics and Interactive techniques SIGGRAPH2017 [http://s2017.siggraph.org/]
ACM International Conference on Multimedia ACMMM2017: [http://www.acmmm.org/2017/]
ICIP, International Conference on Image Processing [http://2017.ieeeicip.org/]
期刊
ACM Transactions on Graphics, TOG
International Journal of Computer Vision, IJCV
IEEE Trans on Pattern Analysis and Machine Intelligence, TPAMI
IEEE Transactions on Image Processing, TIP
IEEE Transactions on Visualization and Computer Graphics, TVCG
IEEE Communications Surveys and Tutorials
IEEE Signal Processing Magazine
IEEE Transactions on EVOLUTIONARY COMPUTATION
IEEE Transactions on GEOSCIENCE and REMOTE SENSING 2区
IEEE Transactions on Pattern Analysis and Machine Intelligence
NEUROCOMPUTING 2区
Pattern Recognition Letters 2区
Proceedings of the IEEE
Signal image and Video Processing 4区
IEEE journal on Selected areas in Communications 2区
IEEE Transactions on image Processing 2区
journal of Visual Communication and image Representation 3区
Machine Vision and Application 3区
Pattern Recognition 2区
Signal Processing-image Communication 3区
COMPUTER Vision and image UNDERSTANDING 3区
IEEE Communications Surveys and Tutorials
IET image Processing 4区
Artificial Intelligence 2区
Machine Learning 3区
Medical image Analysis 2区
领域专家
(水平有限,漏了很多大牛,欢迎大家提建议和补充,会一直保持更新)
华人机构和学者
旷视首席科学家, 前MSRA首席研究员 孙剑 [http://www.jiansun.org/]
微软微软全球执行副总裁 沈向阳 [https://news.microsoft.com/exec/harry-shum/]
微软亚洲研究院 华刚 [https://www.microsoft.com/en-us/research/people/ganghua/]
上海科技大学的 虞晶怡 [http://www.yu-jingyi.com/]
微软亚洲研究院 梅涛 [https://www.microsoft.com/en-us/research/people/tmei/]
微软亚洲研究院 张正友 [https://www.microsoft.com/en-us/research/people/zhang/]
微软研究院 刘自成[http://people.ucas.ac.cn/~xlchen\]
微软亚洲研究院 王井东 [https://www.microsoft.com/en-us/research/people/jingdw/]
原百度研究院院长 林元庆 [https://www.linkedin.com/in/yuanqing-lin-8666789/]
澳大利亚国立大学 李宏东 [http://users.cecs.anu.edu.au/~hongdong/\]
加州大学伯克利分校 马毅 [http://yima.csl.illinois.edu/]
密苏里科技大学 尹朝征 [http://web.mst.edu/~yinz/\]
美国西北大学 吴郢 [http://www.mccormick.northwestern.edu/research-faculty/directory/profiles/wu-ying.html]
新加坡国立大学 360 颜水成团队 [https://www.ece.nus.edu.sg/stfpage/eleyans/]
新加坡国立大学 冯佳时 [https://sites.google.com/site/jshfeng/home]
香港中文大学教授贾佳亚:http://www.cse.cuhk.edu.hk/~leojia/index.html
香港中文大学多媒体实验室&商汤(汤晓鸥团队); http://mmlab.ie.cuhk.edu.hk/, [https://www.ie.cuhk.edu.hk/people/xotang.shtml]
香港中文大学教授王晓刚; http://www.ee.cuhk.edu.hk/~xgwang/
图森首席科学家,香港科技大学王乃岩博士以及其团队 http://www.winsty.net/
美国伊利诺斯大学黄煦涛 [https://ece.illinois.edu/directory/profile/t-huang1]
奥尔巴尼大学陈梅 [http://www.albany.edu/meichen/]
宾夕法尼亚州立大学 刘燕西 [http://www.cse.psu.edu/~yul11/\]
亮风台联合创始人、首席科学家 凌海滨及其团队 [http://www.dabi.temple.edu/~hbling/\]
UCLA教授朱松纯; http://www.stat.ucla.edu/~sczhu/
肯塔基大学计算机系 杨睿刚 [http://www.vis.uky.edu/~ryang/\]
南洋理工大学 袁浚菘
中科院自动化所; http://www.ia.cas.cn/
视觉信息处理研究组
生物识别与安全研究组(生物识别与安全技术研究中心):http://www.cbsr.ia.ac.cn
模式识别基础理论与方法研究组(Pattern Analysis and Learning Group):http://www.nlpr.ia.ac.cn/pal/
计算医学研究组(脑网络组研究中心):http://www.brainnetome.org
空天信息研究中心
多媒体计算研究组:http://nlpr-web.ia.ac.cn/mmc/index.html
机器视觉课题组:http://vision.ia.ac.cn
图像视频组:http://www.nlpr.ia.ac.cn/iva
智能感知与计算研究中心:http://www.cripac.ia.ac.cn
Li-Group(李子青组):[http://www.cbsr.ia.ac.cn/Li%20Group/index%20CH.asp], 中科奥森科技有限公司:[http://www.authenmetric.com],“中科奥森”
胡卫明组
中科院自动化所模式识别国家重点实验室;http://www.nlpr.ia.ac.cn/CN/model/index.shtml
中科院计算所;http://www.ict.ac.cn/
跨媒体计算课题组(http://mcg.ict.ac.cn)
视觉信息处理与学习研究组(http://vipl.ict.ac.cnhttp://seetatech.com),下设人脸组、手语组、视频组、视觉建模组、情感计算组、视觉场景理解组、多模态生物特征组、多媒体计算与多模态智能组,中科视拓(北京)科技有限公司:
中科院计算所智能信息处理重点实验室;http://iip.ict.ac.cn/
前瞻研究实验室
信息工程研究所(http://www.cskaoyan.com/thread-205594-1-1.html)
刘偲组:http://liusi-group.com
多媒体安全与智能分析研究组
美国罗彻斯特大学教授罗杰波:http://www.cs.rochester.edu/u/jluo/
北京大学高文教授及其团队:http://www.jdl.ac.cn/htm-gaowen/
清华大学章毓晋教授及其团队:http://www.tsinghua.edu.cn/publish/ee/4157/2010/20101217173552339241557/20101217173552339241557.html
清华大学朱军,艾海舟,朱文武,鲁继文教授等
[http://ml.cs.tsinghua.edu.cn/~jun/index.shtml]
[http://media.cs.tsinghua.edu.cn/~ahz/\]
[https://baike.baidu.com/item/%E6%9C%B1%E6%96%87%E6%AD%A6/10181070?fr=aladdin]
[http://www.au.tsinghua.edu.cn/publish/au/1714/2016/20160229104943061296929/20160229104943061296929_.html]
西安交通大学人工智能与机器人研究所 (郑南宁 龚怡宏):http://www.aiar.xjtu.edu.cn/[http://gr.xjtu.edu.cn/web/ygong/home]
天津大学计算机图形图像与可视计算实验室
上海交通大学计算机视觉实验室刘允才教授:http://www.visionlab.sjtu.edu.cn/
https://cvsjtu.wordpress.com/
浙江大学:何晓飞,蔡登,宋明黎,李玺,朱建科,潘纲等老师团队
浙江大学图像技术研究与应用(ITRA)团队:http://www.dvzju.com/
中国科学技术大学 查正军 [http://auto.ustc.edu.cn/teacher_details.php?i=362\]
南京大学 吴建鑫 [https://cs.nju.edu.cn/wujx/]
中山大学:郑伟诗,林倞教授团队
南开:程明明教授团队
南京审计大学:吴毅教授(tracking)
大连理工大学:卢湖川教授(tracking)
厦门大学:纪荣嵘和王菡子教授等
华中科技大学:白翔教授团队(text detection)
北京邮电大学郭军老师组
哈工大: 左旺孟老师团队
Software
Caffe[http://caffe.berkeleyvision.org/]
PyTorch - Tensors and Dynamic neural networks in Python with strong GPU acceleration[https://github.com/pytorch/pytorch]
CNTK - Microsoft Cognitive Toolkit[https://github.com/Microsoft/CNTK]
Theano[http://deeplearning.net/software/theano/]
cuda-convnet[https://code.google.com/p/cuda-convnet2/]
DeepLearnToolbox[https://github.com/rasmusbergpalm/DeepLearnToolbox]
Deepnet[https://github.com/nitishsrivastava/deepnet]
Deeppy[https://github.com/andersbll/deeppy]
JavaNN[https://github.com/ivan-vasilev/neuralnetworks]
hebel[https://github.com/hannes-brt/hebel]
Mocha.jl[https://github.com/pluskid/Mocha.jl]
OpenDL[https://github.com/guoding83128/OpenDL]
cuDNN[https://developer.nvidia.com/cuDNN]
MGL[http://melisgl.github.io/mgl-pax-world/mgl-manual.html]
Knet.jl[https://github.com/denizyuret/Knet.jl]
Nvidia DIGITS - a web app based on Caffe[https://github.com/NVIDIA/DIGITS]
Neon - Python based Deep Learning Framework[https://github.com/NervanaSystems/neon]
. Keras - Theano based Deep Learning Library[http://keras.io]
. Chainer - A flexible framework of neural networks for deep learning[http://chainer.org/]
RNNLIB - A recurrent neural network library[http://sourceforge.net/p/rnnl/wiki/Home/]
Brainstorm - Fast, flexible and fun neural networks.[https://github.com/IDSIA/brainstorm]
Tensorflow - Open source software library for numerical computation using data flow graphs[https://github.com/tensorflow/tensorflow]
DMTK - Microsoft Distributed Machine Learning Tookit[https://github.com/Microsoft/DMTK]
Scikit Flow - Simplified interface for TensorFlow [mimicking Scikit Learn][https://github.com/google/skflow]
MXnet - Lightweight, Portable, Flexible Distributed/Mobile Deep Learning framework[https://github.com/dmlc/mxnet/]
Apache SINGA - A General Distributed Deep Learning Platform[http://singa.incubator.apache.org/]
DSSTNE - Amazon's library for building Deep Learning models[https://github.com/amznlabs/amazon-dsstne]
SyntaxNet - Google's syntactic parser - A TensorFlow dependency library[https://github.com/tensorflow/models/tree/master/syntaxnet]
mlpack - A scalable Machine Learning library[http://mlpack.org/]
Paddle - PArallel Distributed Deep LEarning by Baidu[https://github.com/baidu/paddle]
NeuPy - Theano based Python library for ANN and Deep Learning[http://neupy.com]
Sonnet - a library for constructing neural networks by Google's DeepMind[https://github.com/deepmind/sonnet]
Datasets
Detection
PASCAL VOC 2009 dataset Classification/Detection Competitions, Segmentation Competition, Person Layout Taster Competition datasets
LabelMe dataset LabelMe is a web-based image annotation tool that allows researchers to label images and share the annotations with the rest of the community. If you use the database, we only ask that you contribute to it, from time to time, by using the labeling tool.
BioID Face Detection Database
1521 images with human faces, recorded under natural conditions, i.e. varying illumination and complex background. The eye positions have been set manually.
CMU/VASC & PIE Face dataset
Yale Face dataset
Caltech Cars, Motorcycles, Airplanes, Faces, Leaves, Backgrounds
Caltech 101 Pictures of objects belonging to 101 categories
Caltech 256 Pictures of objects belonging to 256 categories
Daimler Pedestrian Detection Benchmark 15,560 pedestrian and non-pedestrian samples (image cut-outs) and 6744 additional full images not containing pedestrians for bootstrapping. The test set contains more than 21,790 images with 56,492 pedestrian labels (fully visible or partially occluded), captured from a vehicle in urban traffic.
MIT Pedestrian dataset CVC Pedestrian Datasets
CVC Pedestrian Datasets CBCL Pedestrian Database
MIT Face dataset CBCL Face Database
MIT Car dataset CBCL Car Database
MIT Street dataset CBCL Street Database
INRIA Person Data Set A large set of marked up images of standing or walking people
INRIA car dataset A set of car and non-car images taken in a parking lot nearby INRIA
INRIA horse dataset A set of horse and non-horse images
H3D Dataset 3D skeletons and segmented regions for 1000 people in images
HRI RoadTraffic dataset A large-scale vehicle detection dataset
BelgaLogos 10000 images of natural scenes, with 37 different logos, and 2695 logos instances, annotated with a bounding box.
FlickrBelgaLogos 10000 images of natural scenes grabbed on Flickr, with 2695 logos instances cut and pasted from the BelgaLogos dataset.
FlickrLogos-32 The dataset FlickrLogos-32 contains photos depicting logos and is meant for the evaluation of multi-class logo detection/recognition as well as logo retrieval methods on real-world images. It consists of 8240 images downloaded from Flickr.
TME Motorway Dataset 30000+ frames with vehicle rear annotation and classification (car and trucks) on motorway/highway sequences. Annotation semi-automatically generated using laser-scanner data. Distance estimation and consistent target ID over time available.
PHOS (Color Image Database for illumination invariant feature selection) Phos is a color image database of 15 scenes captured under different illumination conditions. More particularly, every scene of the database contains 15 different images: 9 images captured under various strengths of uniform illumination, and 6 images under different degrees of non-uniform illumination. The images contain objects of different shape, color and texture and can be used for illumination invariant feature detection and selection.
Classification
PASCAL VOC 2009 dataset Classification/Detection Competitions, Segmentation Competition, Person Layout Taster Competition datasets
Caltech Cars, Motorcycles, Airplanes, Faces, Leaves, Backgrounds
Caltech 101 Pictures of objects belonging to 101 categories
Caltech 256 Pictures of objects belonging to 256 categories
ETHZ Shape Classes A dataset for testing object class detection algorithms. It contains 255 test images and features five diverse shape-based classes (apple logos, bottles, giraffes, mugs, and swans).
Flower classification data sets 17 Flower Category Dataset
Animals with attributes A dataset for Attribute Based Classification. It consists of 30475 images of 50 animals classes with six pre-extracted feature representations for each image.
Stanford Dogs Dataset Dataset of 20,580 images of 120 dog breeds with bounding-box annotation, for fine-grained image categorization.
Video classification USAA dataset The USAA dataset includes 8 different semantic class videos which are home videos of social occassions which feature activities of group of people. It contains around 100 videos for training and testing respectively. Each video is labeled by 69 attributes. The 69 attributes can be broken down into five broad classes: actions, objects, scenes, sounds, and camera movement.
McGill Real-World Face Video Database This database contains 18000 video frames of 640x480 resolution from 60 video sequences, each of which recorded from a different subject (31 female and 29 male).
e-Lab Video Data Set Video data sets to train machines to recognise objects in our environment. e-VDS35 has 35 classes and a total of 2050 videos of roughly 10 seconds each.
Tracking
Dataset-AMP: Luka Čehovin Zajc; Alan Lukežič; Aleš Leonardis; Matej Kristan. "Beyond Standard Benchmarks: Parameterizing Performance Evaluation in Visual Object Tracking." ICCV (2017). [paper]
Dataset-Nfs: Hamed Kiani Galoogahi, Ashton Fagg, Chen Huang, Deva Ramanan and Simon Lucey. "Need for Speed: A Benchmark for Higher Frame Rate Object Tracking." ICCV (2017) [paper] [supp] [project]
Dataset-DTB70: Siyi Li, Dit-Yan Yeung. "Visual Object Tracking for Unmanned Aerial Vehicles: A Benchmark and New Motion Models." AAAI (2017) [paper] [project] [dataset]
Dataset-UAV123: Matthias Mueller, Neil Smith and Bernard Ghanem. "A Benchmark and Simulator for UAV Tracking." ECCV (2016) [paper] [project] [dataset]
Dataset-TColor-128: Pengpeng Liang, Erik Blasch, Haibin Ling. "Encoding color information for visual tracking: Algorithms and benchmark." TIP (2015) [paper] [project] [dataset]
Dataset-NUS-PRO: Annan Li, Min Lin, Yi Wu, Ming-Hsuan Yang, and Shuicheng Yan. "NUS-PRO: A New Visual Tracking Challenge." PAMI (2015) [paper] [project] [Data_360(code:bf28)] [Data_baidu]] [View_360(code:515a)] [View_baidu]]
Dataset-PTB: Shuran Song and Jianxiong Xiao. "Tracking Revisited using RGBD Camera: Unified Benchmark and Baselines." ICCV (2013) [paper] [project] [5 validation] [95 evaluation]
Dataset-ALOV300+: Arnold W. M. Smeulders, Dung M. Chu, Rita Cucchiara, Simone Calderara, Afshin Dehghan, Mubarak Shah. "Visual Tracking: An Experimental Survey." PAMI (2014) [paper] [project] Mirror Link:ALOV300++ Dataset Mirror Link:ALOV300++ Groundtruth
OTB2013: Wu, Yi, Jongwoo Lim, and Minghsuan Yang. "Online Object Tracking: A Benchmark." CVPR (2013). [paper]
OTB2015: Wu, Yi, Jongwoo Lim, and Minghsuan Yang. "Object Tracking Benchmark." TPAMI (2015). [paper] [project]
Dataset-VOT: [project]
[VOT13_paper_ICCV(http://www.votchallenge.net/vot2013/Download/vot_2013_paper.pdfThe)] Visual Object Tracking VOT2013 challenge results
[VOT14_paper_ECCV]The Visual Object Tracking VOT2014 challenge results
[VOT15_paper_ICCV]The Visual Object Tracking VOT2015 challenge results
[VOT16_paper_ECCV]The Visual Object Tracking VOT2016 challenge results
[VOT17_paper_ECCV]The Visual Object Tracking VOT2017 challenge results
Challenge
Microsoft COCO Image Captioning Challenge [https://competitions.codalab.org/competitions/3221]
ImageNet Large Scale Visual Recognition Challenge [http://www.image-net.org/]
COCO 2017 Detection Challenge [http://cocodataset.org/#detections-challenge2017]
Visual Domain Adaptation (VisDA2017) Segmentation Challenge [https://competitions.codalab.org/competitions/17054]
The PASCAL Visual Object Classes Homepage [http://host.robots.ox.ac.uk/pascal/VOC/]
YouTube-8M Large-Scale Video Understanding [https://research.google.com/youtube8m/workshop.html]
joint COCO and Places Challenge [https://places-coco2017.github.io/]
Places Challenge 2017: Deep Scene Understanding is held jointly with COCO Challenge at ICCV'17 [http://placeschallenge.csail.mit.edu/]
COCO Challenges. [http://cocodataset.org/#home]
VQA Challenge 2017 [http://visualqa.org/]
The Joint Video and Language Understanding Workshop: MovieQA and The Large Scale Movie Description Challenge (LSMDC), at ICCV 2017 [https://sites.google.com/site/describingmovies/challenge]
Microsoft Multimedia Challenge (2017) [http://ms-multimedia-challenge.com/2017/challenge]
MOTChallenge: The Multiple Object Tracking Benchmark [https://motchallenge.net/]
Visual Domain Adaptation Challenge [http://ai.bu.edu/visda-2017/]
MegaFace and MF2: Million-Scale Face Recognition [http://megaface.cs.washington.edu/]
Facial Keypoints Detection [https://www.kaggle.com/c/facial-keypoints-detection]
The VOT challenges Visual Object Tracking [http://www.votchallenge.net/]
Large-scale Scene Understanding Challenge. SCENE CLASSIFICATION, SEGMENTATION, SALIENCY PREDICTION [http://lsun.cs.princeton.edu/2017/]
AI Challenger·全球AI挑战赛 图像中文描述,人体骨骼关键点,场景分类 [https://challenger.ai/]
2016上海BOT大数据应用大赛 [http://www.zhishu51.com/Activity/bot]
创业公司
旷视科技:让机器看懂世界 [https://megvii.com/]
云从科技:源自计算机视觉之父的人脸识别技术 [http://www.cloudwalk.cn/]
格林深瞳:让计算机看懂世界 [http://www.deepglint.com/]
北京陌上花科技有限公司:人工智能计算机视觉引擎 [http://www.dressplus.cn/]
依图科技:与您一起构建计算机视觉的未来 [http://www.yitutech.com/]
码隆科技:最时尚的人工智能 [https://www.malong.com/]
Linkface脸云科技:全球领先的人脸识别技术服务 [https://www.linkface.cn/]
速感科技:让机器人认识世界,用机器人改变世界 [http://www.qfeeltech.com/]
图森: 中国自动驾驶商业化领跑者 [http://www.tusimple.com/]
Sense TIme商汤科技:教会计算机看懂这个世界 [https://www.sensetime.com/]
图普科技:专注于图像识别 [https://us.tuputech.com/?from=gz]
亮风台: 专注增强现实,引领人机交互 [https://www.hiscene.com/]
中科视拓 : 知人识面辨万物,开源赋能共发展 [http://www.seetatech.com/]
中科奥森:双目深度学习: 让生活和社会更安 [http://www.authenmetric.com/]
银河水滴:全球领先的步态识别技术 [http://www.watrix.cc/y1.html]
公众号
视觉求索 thevisionseeker
深度学习大讲堂 deeplearningclass
VALSE valse_wechat_
初步版本,水平有限,有错误或者不完善的地方,欢迎大家提建议和补充,会一直保持更新,敬请关注http://www.zhuanzhi.ai 和关注专知公众号,获取最新AI相关知识
特别提示-专知计算机视觉主题:
获取最新更新计算机视觉知识,请PC登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“ 计算机视觉” 主题,查看获得计算机视觉专知荟萃全集知识等资料!如下图所示~
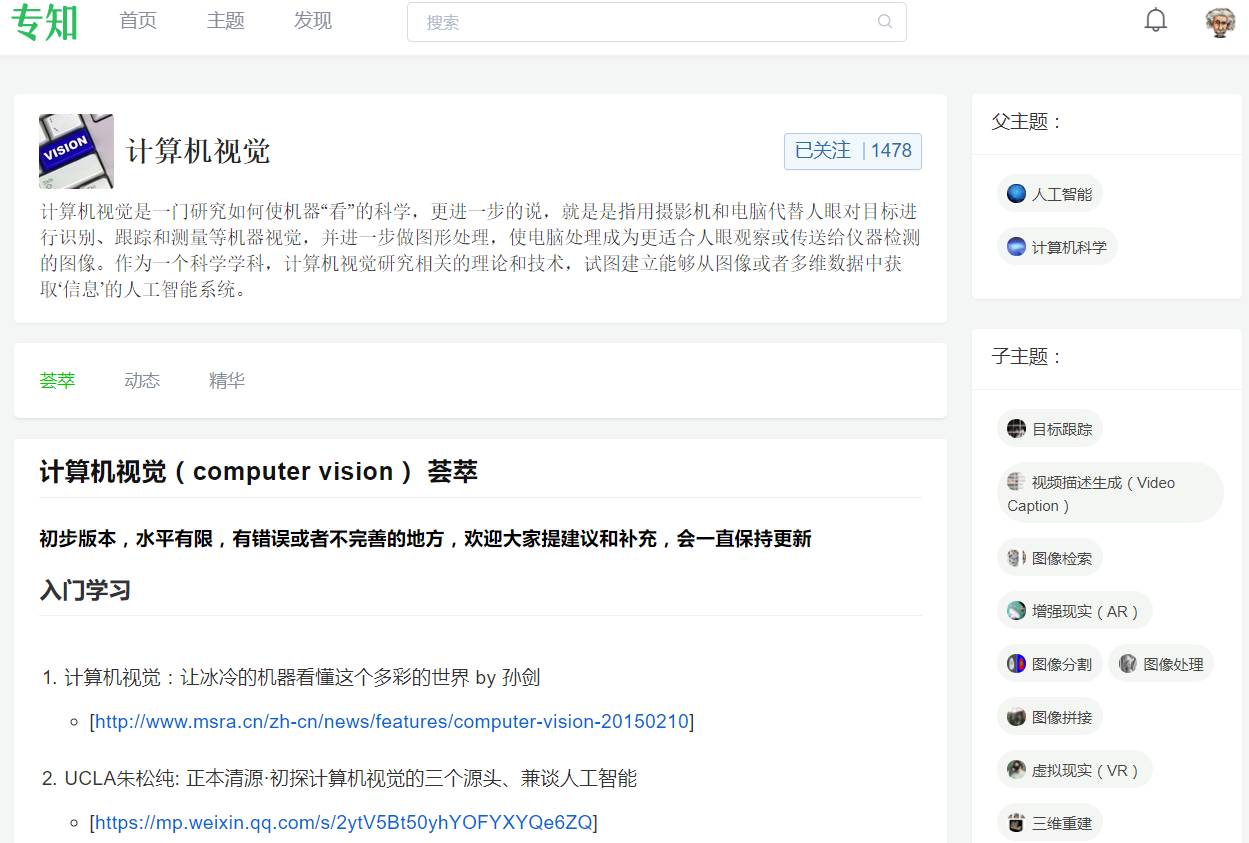
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“CV” 或者“计算机视觉”就可以获取专知计算机视觉荟萃知识资料pdf下载链接~~
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
更多专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【教程实战】Google DeepMind David Silver《深度强化学习》公开课教程学习笔记以及实战代码完整版
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!




