©作者|YukiRain
研究方向|强化学习泛化和鲁棒性
当今RL的问题很多,诸如收敛看运气效果看天命之类的,之前有很多大佬也有吐槽过,本渣也在某个回答
[1]
里吐槽过。
根据个人经验来讲,目前大部分 RL paper 使用的主要 benchmark,比如 MuJoCo 或者 Atari,实际上都是偏弱的(更不用说前两年 MARL 用的 multiagent-particle-envs [2]),在偏弱的实验环境里,模型训练出来在那边跑一跑,看起来结果尚可,实际很多模型的本质问题暴露的不明显,暴露得不明显就不会引起 community 的广泛关注,相关的研究也就会比较少,难成体系。
很不幸,本文要讨论的 RL 泛化能力问题,就是这样的一个问题。
![]()
注:本文讨论的 generalization,有些文章里叫做 robustness,有些文章里叫 generalization,一般来说 robustness 设定中环境的 transition 还是固定的,只不过测试时模型会遇到训练时没见过的场景;而 generalization 一般是指训练环境与测试环境的 transition 有微小差异的时候,希望模型仍可以 cover 测试场景,以下统一使用 generalization 来讨论这两个概念,可能有点混淆。
绝大多数 RL 的基础都是 MDP,MDP 和 supervised learning 最本质的区别,就是前者解决的是一个满足 Markov 性质的环境上的 reward 最大化问题,所以一开始问题的前提假设中就只有一个固定的环境,听起来,泛化能力问题似乎应该是一个独属于 supervised learning 的问题,至少在 RL 的理论层面,是不存在测试环境与训练环境不同的问题的。
但实际上,只要你尝试在真正的应用场景中尝试过 RL,就会发现这是一个无法回避的问题,我去年在公司实习期间,很多实际做过 RL 应用的同事都会讲到的一个重要经验就是:RL 真的很容易过拟合。由于学术界相对研究比较少,应用中就会出现五花八门的问题,随之而来五花八门的解决方案:
案例一,众所周知 DeepMind 和 OpenAI 都做游戏 AI,一个做星际一个做 Dota,为了训练出一个超过人类水平的 AI,两家共同的思路就是 self-play,但是实际上 self-play 会遇到训练时过拟合于对手策略的问题,因为实际部署时会遇到各种各样奇葩的对手策略,训练时从来没有见过奇葩对手的模型会严重翻车。
DeepMind 早早地就预见到了这个问题,在 17 年 A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning [3] 这篇文章里面就指出,即使是在非常简单的环境,self-play 训练出的模型也会严重过拟合于对手策略。
所以做星际的时候他们压根就没想过要用一个模型解决所有问题,而是要引入 game theory 去做一个 zero-sum Markov game 中找 Nash equilibrium 的优化,后续这个思路在另一篇 ICML 的文章 Open-ended Learning in Symmetric Zero-sum Games [4] 又进一步得到了补全。
所以后来 AlphaStar 的训练中,他们用了数量惊人的算力资源,搞了一个 AlphaLeague,用类似 population-based training [5] 的方式分阶段训练——考虑目前绝大多数公司的算力情况,暂时,这套方法对其他公司的实践不具有太大的指导意义。
在这篇 OpenAI Five 的博客 [6] 中,OpenAI 表示 2017 年,他们在模型训练的过程中加入了环境参数的随机化后,模型开始在 1v1 场景下超越人类水平,后续这种随机化技巧广泛使用在他们的 5v5 模型,甚至是机器人模型的训练中。
案例二,robotics 训练,因为机器人机械臂有使用寿命的限制,目前常用的一种方式是在物理仿真模拟环境中训练,模型收敛后部署到现实世界中,然而模拟器不大可能建模出现实世界中所有的变量,实际上模拟器中表现良好的模型,在现实世界的表现会有所下降。
目前主要考虑两种解决方案:一是在训练期在模拟器中加入随机化,二是认为从模拟器到现实是一个迁移学习的问题,以 sim2real 为关键词搜索,这方面的研究非常多,这里简单列举两篇:
Tzeng E, Devin C, Hoffman J, et al. Towards adapting deep visuomotor representations from simulated to real environments[DB/OL]. arXiv:1511.07111.
Peng X B, Andrychowicz M, Zaremba W, et al. Sim-to-real transfer of robotic control with dynamics randomization[C]. IEEE International Conference on Robotics and Automation, 2018: 1-8.
Gupta A, Devin C, Liu Y X, et al. Learning invariant feature spaces to transfer skills with reinforcement learning[DB/OL]. arXiv:1703.02949.
案例三,环境动态表现出高度 non-stationary 特性的任务,如推荐系统、定价系统、交易系统等(应该是没有哪个公司真的在交易系统里上 RL 的吧),这些任务的一个共同特点是业务敏感,绝对不会真的让模型在训练时与环境交互。
一般的做法是线上开一个子进程去收集样本回来做完全意义上的 off-policy 训练(就此延伸出去的一个研究方向叫 batch reinforcement learning,不过这已经不在本文讨论范围内了)。由于环境动态高度非平稳,三个月前训练的模型可能现在已经不 work 了,据我了解到的一点点情况,目前工业界没啥太好的办法,唯不停地重新训练而已。
基本上大多数研究 RL generalization 或 robustness 的文章里都会涉及到,举一些代表性的例子:
Observational Overfitting in Reinforcement Learning
https://arxiv.org/abs/1912.02975
Action Robust Reinforcement Learning and Applications in Continuous Control
https://arxiv.org/abs/1901.09184
A Dissection of Overfitting and Generalization in Continuous Reinforcement Learning
https://arxiv.org/abs/1806.07937
A Study on Overfitting in Deep Reinforcement Learning
https://arxiv.org/abs/1804.06893
Quantifying Generalization in Reinforcement Learning
https://openai.com/blog/quantifying-generalization-in-reinforcement-learning/
Planning with Information-Processing Constraints and Model Uncertainty in Markov Decision Processes
https://arxiv.org/abs/1604.02080
DRL的过拟合是一个属于RL的问题还是一个属于DL的问题?
就目前的一些研究结果来看,答案可能是 both。有关 RL 的过拟合,上面列举的一些文献已经能够一定程度上说明问题,这里主要说说 DL。
传统 machine learning 中人们就常用各种正则项来抑制过拟合,最典型的应该是 L2 正则,而近些年 RL 领域中也有若干 paper 研究正则项的影响,比如今年 ICLR Regularization Matters in Policy Optimization [7] 作者称 L2 可以起到比 entropy regularization 更好的效果,DL 里常用的 dropout 可以为 off-policy 训练带来一些正面的效果(虽然最后被 reject 掉了)。
而 Generalization and Regularization in DQN [8] 一文中作者称,模型训练到后期,训练环境上模型能力的上升同时也意味着泛化能力的下降,而 L2 正则可以找到一个较好的平衡点,类似于 supervised learning 里面 L2 与 early stop 的等价关系。
Does robust optimization work for RL generalization?
学术界中,robust optimization(以下简称 RO)是一个比较容易想到的解决方案,在早期 RL 研究者们还聚焦于各种 MDP 数学意义上的 tractability 的时候,就已经有一些工作研究在不完美、或者包含 uncertainty 的环境动态的基础上进行优化,这种优化一般被称作 robust MDP:
Bart van den Broek, Wim Wiegerinck, and Hilbert J. Kappen. Risk sensitive path integral control. In UAI, 2010.
Arnab Nilim and Laurent El Ghaoui. Robust control of markov decision processes with uncertain transition matrices.Operations Research, 53(5):780–798, 2005
Wolfram Wiesemann, Daniel Kuhn, and Berc Rustem. Robust markov decision processes. Mathematics of Operations Research, 38(1):153–183, 2013.
Lars Peter Hansen and Thomas J Sargent.Robustness. Princeton university press, 2008
Yun Shen, Michael J Tobia, Tobias Sommer, and Klaus Obermayer. Risk-sensitive reinforcement learning. Neural computation, 26(7):1298–1328, 2014.
Yinlam Chow, Aviv Tamar, Shie Mannor, and Marco Pavone. Risk-sensitive and robust decision-making: a cvar optimization approach. In Advances in Neural Information Pro-cessing Systems, pages 1522–1530, 2015.
进入深度学习时代以后,最早的代表性工作应该是 RARL,其优化目标是 total reward 的 CVaR,最终在训练中引入了 zero-sum Markov game 来提升 robustness,总体来说是比较漂亮的一个方法,后来的很多文章都沿用了 RARL 的框架:
Robust Adversarial Reinforcement Learning
https://arxiv.org/abs/1703.02702
如果想让模型对环境动态具有一定的 robustness,那么就应该针对环境动态设计 uncertainty set 来做 RO,比如(第一篇被 reject 过):
Wasserstein Robust Reinforcement Learning
https://arxiv.org/abs/1907.13196
Robust Reinforcement Learning for Continuous Control with Model Misspecification
https://openreview.net/forum?id=HJgC60EtwB
有从 RO 角度做的,就一定会有从 Distributionally Robust Optimization 的角度做的(这篇技术上是用 DRO 做的,但最终做的任务是 safe exploration,个人认为也可以算到 RO 的工作类别中,此外这篇是 workshop)。
Distributionally Robust Reinforcement Learning
https://openreview.net/pdf?id=r1xfz_93oN
sim2real、环境随机化与 CVaR 大杂烩的思路:
EPOpt: Learning Robust Neural Network Policies Using Model Ensembles
https://arxiv.org/abs/1610.01283
以及今年 ICLR 一篇在 RARL 基础上做改进的文章,最终惨遭 reject:
Robust Reinforcement Learning via Adversarial Training with Langevin Dynamics
https://openreview.net/forum?id=BJl7mxBYvB
说到 RO,大概会有些人动 supervised learning 里面 adversarial examples 的主意,但是将 adversarial examples 的思路直接引入 RL 并不一定是 trivially correct 的,目前有数量较少的几篇文章在这个思路上做了简单尝试,个人对这个思路的尝试报怀疑态度。
Sinha A, Namkoong H, Duchi J. Certifying some distributional robustness with principled adversarial training [DB/OL]. arXiv:1710.10571.
DRO 优化的文章,思路可以看看,但只在最后一小节提到可以用于 robust MDP,个人做实验发现对复杂任务完全不 work。
Pattanaik A, Tang Z, Liu S, et al. Robust deep reinforcement learning with adversarial attacks[C]. International Joint Conference on Autonomous Agents and Multi-agent Systems, 2018: 2040-2042.
提出了一种将对抗样本引入 DDPG 训练的思路,相当于采用经对抗扰动后最差的 policy 做 off-policy 训练,导致收敛速度非常慢。
Huang S, Papernot N, Goodfellow I, et al. Adversarial attacks on neural network policies[J]. arXiv preprint arXiv:1702.02284, 2017.
虽然作者列表大神云集,但个人认为这篇没有带来什么新的 insight,不推荐。
Ilahi I, Usama M, Qadir J, et al. Challenges and Countermeasures for Adversarial Attacks on Deep Reinforcement Learning[J]. arXiv preprint arXiv:2001.09684, 2020.
目前学术界对 RL 泛化问题的研究实际上很难完全分类,因为目前鲜有能构成体系的研究工作,提出的各种解决方案颇有东一榔头西一棒槌之感,下面列两篇无法分类到以上任何类别的工作:
Improving Generalization in Meta Reinforcement Learning using Neural Objectives
https://openreview.net/forum?id=S1evHerYPr
On the Generalization Gap in Reparameterizable Reinforcement Learning
https://arxiv.org/abs/1905.12654
第二篇是 RL 泛化问题上为数不多的理论文章之一,用 finite sample analysis 做分析的,值得一读,缺点是只能用于 on-policy 和 reparameterizable state 的情况。
目前的工业应用中,环境加随机化可能是使用最广泛的解决方案,在 18 年 Assessing Generalization in Deep Reinforcement Learning [9] 一文中,作者基于若干组 MuJoCo 的实验,声称环境加随机化是目前为止提升泛化能力最有效的方法。
但 A Study on Overfitting in Deep Reinforcement Learning [10] 在迷宫环境上的实验则得出了完全相反的结论,作者称 RL 训练出的模型会死记硬背,随机化技巧无法避免 RL 模型的过拟合。
首先一个比较容易想到的问题,环境复杂度的问题:加入随机化后环境的数量会随随机变量数量的上升而指数上升,今年 ICLR 就有审稿人提出了这一质疑:
If there are, e.g., 20 parameters, and one picks 3 values for each, there are 3^20 variations of the environment. This exponential growth seems problematic, which is also mentioned by R3.
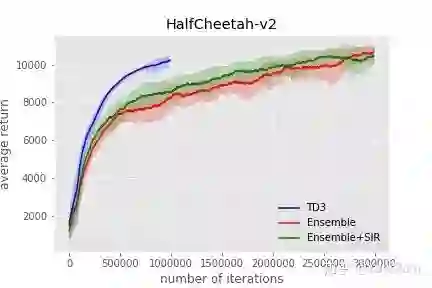
环境复杂度的问题会进一步提升训练的复杂度:加入环境随机化后,模型训练达到收敛所需的样本量实际上也显著上升了,由于其他论文里都不怎么提,这里以 TD3 为 baseline 放一点点自己的实验图作为证据(忽略绿色曲线),这里可以看到 HalfCheetah-v2 环境上,加入了环境随机的模型用了大约三倍的 iteration 才达到了原始版本 TD3 的水平。
![]()
从上面的图中还可以看出一个新的问题:方差问题。加入环境随机化以后,模型表现无论是在训练环境中,还是测试环境中,表现出的方差要大于在单一环境上训练,这也与本渣渣去年在公司实习期间的一些实验结论一致,当时的结论是随机化训练的方差会比只在一个固定环境上训练高出若干个数量级。
对于加入随机化以后过度探索的问题,OpenAI 提出过一个不错的解决思路:
https://openai.com/blog/solving-rubiks-cube/
Difficulties
理论层面,由于 RL 本身的理论建模中不存在泛化问题,目前学术界的研究大部分都是 empirical 的工作,理论性文章很少,上面列举的唯一一篇理论 paper 的假设条件还离实践比较远。
实践层面,最大的困难来自于当前 model-free RL 高方差的尿性,开篇已经提到过,MuJoCo 和 Atari 一类的环境对于 RL 泛化问题是比较弱的,如果你有机会在企业级别的场景下做 RL 实验,那么一定会在泛化方面有更深刻的体会。
因此,在 MuJoCo、Atari、或者是之前有作者用过的随机迷宫之类的环境中,如果你做出了某种提升,可能提升的幅度还不如代码层面优化换 random seed 或者 reward scaling 来的明显,今年 ICLR 就有一篇讲 RL 的 code-level optimization 的文章工作被 accept,足以说明现在的 R L研究者对 reproducibility 的殷切期盼。
Implementation Matters in Deep RL: A Case Study on PPO and TRPO
https://openreview.net/forum?id=r1etN1rtPB
众所周知 model-free RL 换个 seed 或者做个 reward scaling 就可能让模型的表现从地下到天上,那么除非你的方法表现可以全方位碾压各种 baseline,否则如何说明这种影响不是来源于 seed 之类的无关影响因素呢?
[1] https://www.zhihu.com/question/369263409/answer/995669697
[2] https://github.com/openai/multiagent-particle-envs
[3] https://arxiv.org/pdf/1711.00832.pdf
[4] http://proceedings.mlr.press/v97/balduzzi19a/balduzzi19a.pdf
[5] https://arxiv.org/pdf/1711.09846.pdf
[6] https://openai.com/blog/openai-five/
[7] https://openreview.net/forum?id=B1lqDertwr
[8] https://arxiv.org/pdf/1810.00123.pdf
[9] https://arxiv.org/pdf/1810.12282.pdf
[10] https://arxiv.org/pdf/1804.06893.pdf
![]()
点击以下标题查看更多往期内容:
![]() #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
▽ 点击 | 阅读原文 | 查看作者专栏