Python 机器学习教程: 预测Airbnb 价格(2)

创建一个多变量KNN模型
我们可以对前面的函数进行扩展,来使用两个特性和整个数据集。代替distance.euclidean(),我们准备使用distance.cdist(),因为它允许我们一次性传入多个行。
( cdist()方法可以被用来以多种方法来计算距离,但它默认的是欧氏距离。)
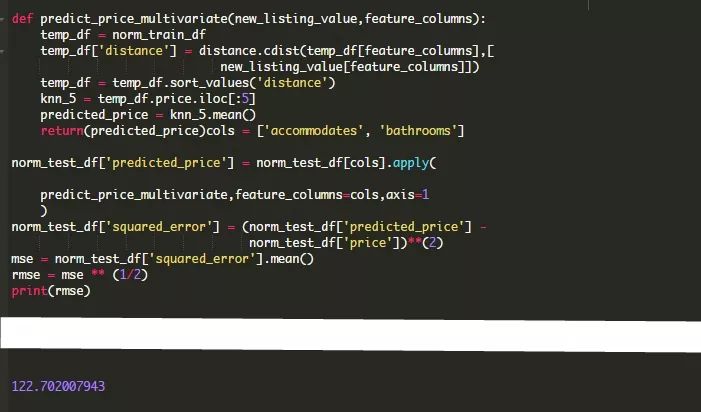
你可以看到,我们的RMSE在使用两个特性而不是仅仅使用accommodates时从212提高到了122。这是一个巨大的改进,尽管它仍然没有我们想要的那么精确。
scikit-learn简介
我们已经从零开始编写了函数来训练我们的k最近邻模型。这有助于我们理解这些机制是如何允许的,但是现在我们已经了解了基本原理,我们就可以使用Python的scikit-learn库更快更有效地工作。
Scikit-learn是Python中最流行的机器学习库。它为所有主要的机器学习算法提供了内置的函数,并提供了一个简单、统一的工作流。这些特性都允许数据科学家在对一个新数据集进行不同模型的训练和测试时变得非常高效。
scikit-learn工作流包括四个主要步骤:
实例化你要使用的特定机器学习模型。
将模型与训练数据相匹配。
使用该模型进行预测。
评估预测的准确性。
scikit-learn中的每个模型都被实现为一个单独的类,第一步是识别我们想要创建实例的类。
任何帮助我们预测数值的模型,比如我们模型中的房屋出租价格,都被称为一个回归模型。机器学习模型的另一个主要类别称为分类。当我们试图从一组固定的标签(例如血型或性别)来预测一个标签时,就会使用到分类模型。
在本例中,我们希望使用 KNeighborsRegressor 类。来自类名KNeighborsRegressor中的单词regressor是指我们刚刚讨论过的回归模型类,而“KNeighbors”则来自我们正在构建的k最近邻模型。
scikit-learn使用类似于Matplotlib的面向对象风格。在调用构造函数执行任何其他操作之前,我们需要先实例化一个空模型。

如果我们参考其文档,我们会注意到这些默认设置:
n_neighbors:邻居的数量,设置为5
算法:计算最近的邻居,设置为auto
p:设置为2,对应欧氏距离
我们将algorithm参数设置为brute,并将n_neighbors值保留为5,这与我们构建的手动实现相匹配。

拟合模型并做出预测
现在,我们可以使用fit方法将模型与数据进行拟合。对于所有模型,fit方法都需要两个参数:
一个类矩阵对象,包含我们希望从训练集中使用的特征列。
一个类列表对象,包含正确的目标值。
“类矩阵对象”意味着该方法是灵活的,可以接受一个pandas 的DataFrame或一个NumPy 的二维数组。这意味着我们可以从DataFrame中选择要使用的列,并将其用作fit方法的第一个参数。
对于第二个参数,回想一下前面的内容,以下所有这些都是可接受的类列表对象:
NumPy数组
Python列表
pandas 的Series对象(例如列)
让我们从DataFrame中选择目标列,并将其作为fit方法的第二个参数:

当调用fit()方法时,scikit-learn会存储我们在KNearestNeighbors实例(knn)中指定的训练数据。如果我们试图将包含缺失值或非数值的数据传入到fit方法中,scikit-learn将返回一个错误。这就是这个库的优点之一——它包含了许多这样的特性,可以防止我们犯错误。
现在我们已经指定了我们想要用来进行预测的训练数据,我们可以使用predict方法来对测试集进行预测。predict方法只有一个必需的参数:
一个类似矩阵的对象,其中包含我们想要对其进行预测的数据集中的特征列
我们在训练和测试期间使用的特征列的数量需要相匹配,否则scikit-learn将返回一个错误。

predict()方法会返回一个NumPy数组,其中包含针对测试集的预测的price值。
我们现在已经有了实践整个scikit-learn工作流所需的一切东西:

当然,仅仅因为我们使用的是scikit-learn而不是手工编写函数,并不意味着我们可以跳过评估步骤,看看我们模型的预测到底有多准确!
使用scikit-learn计算MSE
到目前为止,我们一直是使用NumPy和SciPy函数来帮助我们手动计算RMSE值。或者,我们也可以使用sklearn.metrics.mean_squared_error function() 函数来代替。
mean_squared_error()函数接受两个输入 :
一个类列表对象,表示测试集中的真实值。
第二个类列表对象,表示模型生成的预测值。
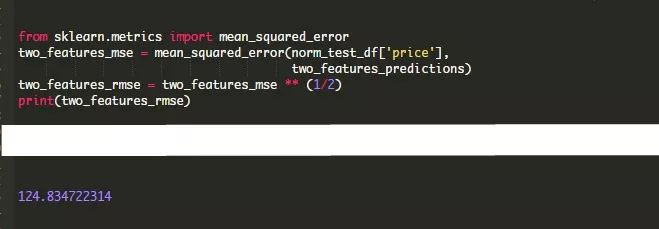
从语法的角度来看,这不仅简单得多,而且由于scikit-learn已经对速度进行了大量优化,因此模型运行所需的时间也更少。
请注意,我们的RMSE与我们手工实现的算法有一点不同——这可能是由于我们的“手工”KNN算法和scikit-learn版本在随机化方面的差异和实现上的细微差异造成的。
请注意,对scikit-learn库本身的更改也会在一定程度上影响这些值。如果你正在学习本教程,并且得到了一个稍微不同的结果,这可能是因为你正在使用一个更新版本的scikit-learn。
使用更多的特征
scikit-learn最棒的一点是它允许我们更快地进行迭代。让我们通过创建一个使用四个而不是两个特征的模型来尝试一下,看看这个优点是否可以改进我们的结果。
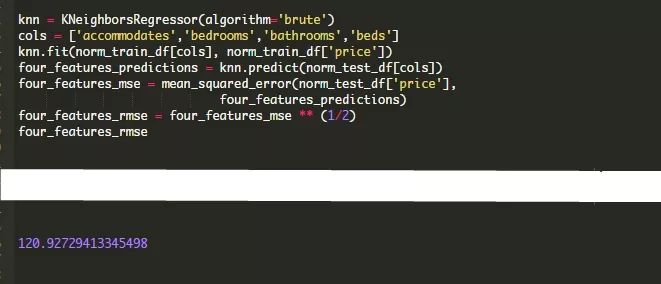
在这种情况下,我们的错误会略有下降。不过,当你添加特征时,它可能并不总是这样做。需要注意的一件重要的事情是:添加更多的特征并不一定会产生一个更精确的模型。
这是因为添加一个不能准确预测你的目标变量的特征会给你的模型增加“噪音”。
总结
让我们来看看我们学习了什么:
我们学习了什么是机器学习,并通过一个非常基本的手工“模型”来预测一个房子的售价。
我们学习了k最近邻算法,并在Python中从头开始构建了一个单变量模型(只有一个特征),并使用它进行预测。
我们了解到RMSE可以用来计算我们的模型的误差,然后我们可以用它来进行迭代,并尝试改进我们的预测。
然后,我们从零开始创建一个多变量(不止一个特征)模型,并使用它做出更好的预测。
最后,我们学习了scikit-learn库,并使用KNeighborsRegressor类进行预测。
接下来的步骤
果你想继续自己研究这个模型,你可以做以下几件事来提高其准确性:
试着用不同的值替换k。
回到原始数据集,将我们删除的一些列转换为numeric(我们的《机器学习数据准备和清理》一文将会帮到你),并尝试添加不同的特征组合进行实验。
尝试一些特性工程,在其中基于现有数据创建新列:我们从Kaggle:房价竞争文章开始:有一个简单的例子。
本文更新于2019年7月。
英文原文: https://www.dataquest.io/blog/machine-learning-tutorial/
译者: 好酒不上头