一个都不能用?62个AI算法被指存在重大问题,剑桥团队:都不具有新冠临床诊断价值

新智元报道
新智元报道
来源:学术头条
2020 年,新冠肺炎肆虐全球。为了能协助医生快速而精确地筛查潜在患者,各国的计算机科学家们发布了上千种机器学习算法,并声称这些算法能根据胸部 X 光片、CT 图像诊断或预测新冠肺炎。
然而,近日由剑桥大学领衔的一项最新研究却发现,这些算法存在着算法偏见和不可重复性等重大问题,并不具有临床价值。
当地时间 3 月 15 日,这篇名为 “Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans” 的论文发表于自然子刊《自然机器智能》(Nature Machine Intelligence)上。

(来源:Nature Machine Intelligence)
这项由剑桥大学科学家们领导完成的研究,涵盖了从 2020 年 1 月 1 日到同年 10 月 3 日内所有科学论文和预印本提到的相关机器学习算法。同一时间段内,在 BioRxiv、medRxiv 和 arxiv 上刊登的所有手稿以及 EMBASE 和 MEDLINE 的所有条目也被纳入了研究范围。
在 2212 篇用机器算法诊断新冠肺炎的论文中,研究人员最终确定了 62 篇质量相对较高的论文进行讨论,其中 37 篇论文为深度学习算法,23 篇论文为传统的机器学习算法,2 篇为混合算法。
但遗憾的是,由于算法偏见和不可重复性等问题,没有一个具有潜在的临床应用价值。
论文第一作者、剑桥大学应用数学和理论物理系博士迈克尔(Michael Roberts)在接受采访时表示:“任何机器学习算法(的应用价值)都取决于训练它所使用的数据,特别是对于像新冠肺炎这样的新流行病来说,数据的多样性是至关重要的。”
算法偏见和不可重复性
一般来说,算法偏见是指算法在数据集构建、目标制定与特征选取、数据标注等环节中产生的信息偏差,导致算法失去公平和准确性。在这项研究中,剑桥大学人员使用 “预测性算法的偏见风险评估工具”(PROBAST),从参与者、预测因素、结论和分析等四个方面系统性地评估了 62 个算法的偏见性风险。结果发现,有 55 个算法在至少一个方面有较高的算法偏见。
拿参与者举例,研究人员认为从公共数据集里获得的胸部 X 光片和 CT 影像具有选择性偏见,因为无法确认患者是否真的新冠肺炎呈阳性。又比如,相当一部分算法采用了儿童的相关影像作为 “非新冠肺炎” 对照组。事实上相比于成人,儿童感染新冠肺炎的几率要小得多。因此这种设计上的偏差会让算法产生很大的偏见。
除了算法偏见以外,算法的性能,也就是预测结果的可重复性,也是剑桥大学在这项研究中关注的重点之一。一般来说有两种方法来验证算法的性能,即内部验证和外部验证。内部验证是指测试数据与开发数据属于相同来源;外部验证是指测试数据属于不同来源。研究人员发现,在 62 篇论文中,有 48 篇只考虑了内部验证,有 13 篇使用了外部测试数据集(其中 12 篇使用了真正的外部测试数据集,1 篇使用了与训练算法完全相同的数据来进行测试)。
对此,论文作者剑桥大学医学院博士路德(James Rudd)指出:“在新冠疫情初期,人们对信息的渴求是如此强烈,以至于一些论文无疑是仓促出版的。但是,如果你的算法只是基于一家医院的数据之上的话,那么它很可能不适用于另一个城市的某家医院。这些数据需要多样性,最好是国际化的。否则,当你的机器学习算法被更广泛地测试时肯定是要失败的。”
在这篇论文中,研究人员特别指出了 “科学怪人数据集”(Frankenstein datasets)的问题。“科学怪人数据集” 是指从不同的数据集合并而成并重新命名分布的数据集,这样的数据集涉及到复杂的数据来源重复问题。例如,训练某算法的数据集集合了 N 个子集而成,但算法开发人员没有意识到其中一个子集还包含了其他子集的成分。这种对数据集的重新打包虽然实用,但会不可避免地导致算法在相同或重叠的数据集上进行训练,进而出现问题。
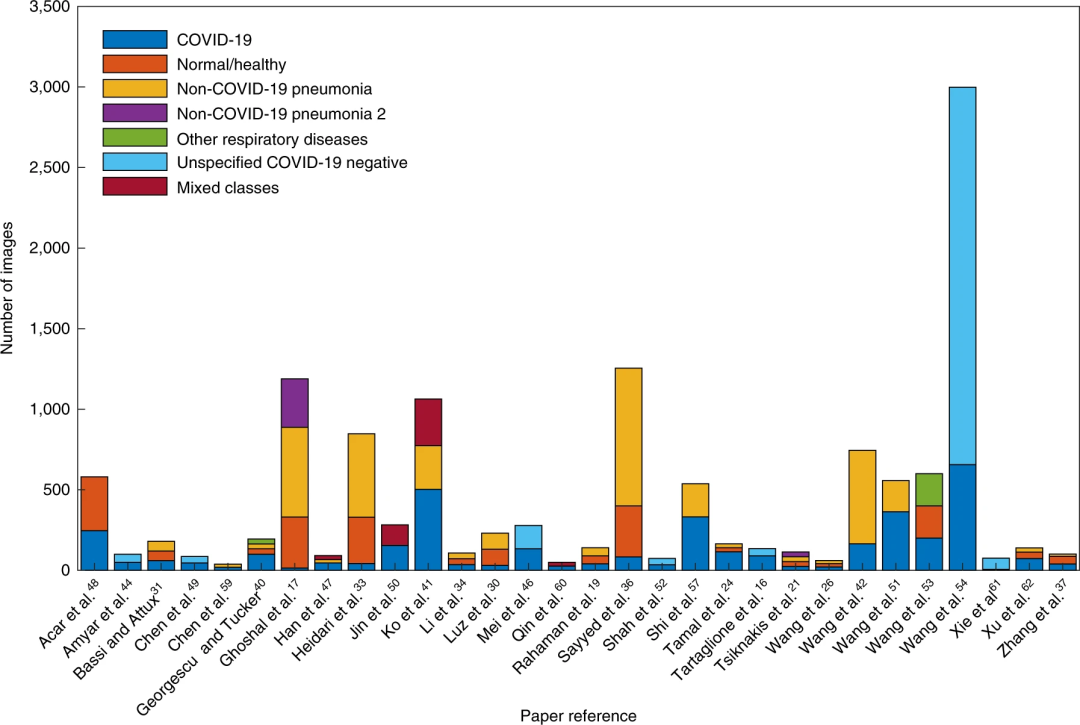
图 | 用于模型测试的图像数量
除了算法偏见和预测结果的不可重复性之外,这些论文的另一个普遍问题是缺乏放射科医生和临床医生的参与。罗伯茨认为:“不论你是使用机器学习来预测天气或研究疾病如何发展,确保不同领域的专家一起参与并保持沟通是非常重要的,这样才能专注于研究正确的问题。”
5 点建议
毫无疑问,机器学习算法在医疗方面有着巨大潜力和广阔的市场前景。在过去的一年间,全球范围内的算法开发人员也为抗击新冠肺炎做出了巨大的努力。
出于严谨的治学态度,剑桥大学研究人员对 2020 年相关机器算法文献的系统性问题给出了 5 点建议:
(1)用于算法开发的数据使用和常见陷阱;
(2)评估被训练算法;
(3)预测模型的可重复性;
(4)手稿中的文献;
(5)同行评议过程。
其中,他们尤其强调需要谨慎使用公共数据库。由于数据来源和 “科学怪人数据集” 的原因,公共数据库会导致高风险的算法偏见。他们认为,算法开发人员应该着眼于广泛采用不同人群的统计数据,这是一个经常被忽视但却非常重要的偏见性来源。除此之外,外部数据的检验也必不可少,任何用于诊断或预测的模型都必须足够稳健,以便为目标人群的任意样本得出可靠结果。
论文还指出,清楚地认识到新冠肺炎检测相关的人工智能算法与明确的临床需求之间需求关系是技术转化的关键。因此,开发人工智能算法需要临床专业知识和计算机知识的互补,同时也需要高质量的医疗数据。
尽管研究人员在新冠肺炎 AI 模型中发现了缺陷,但研究人员表示,通过一些关键的修改,机器学习可以成为抗击这种流行病的强大工具 。在未来的临床场景中,被改进的算法可以更好地被验证。
参考资料:
https://www.nature.com/articles/s42256-021-00307-0



