从CVPR2019看计算机视觉的最新趋势
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:AI公园
作者:Priya Dwived 译者:ronghuaiyang
我从CVPR中选取已被录用的论文进行分析,了解研究的主要领域和论文题目中的常见关键词。这可以提供研究进展的一个迹象。
用数据做一些很酷的事情!
2019年IEEE计算机视觉与模式识别大会(CVPR)于今年6月16日至20日举行。CVPR是计算机视觉领域世界三大学术会议之一(与ICCV和ECCV并列)。今年共收到5165篇论文,录取率达到创纪录的1300篇(25.2%)。
CVPR带来了计算机视觉领域的顶尖人才,每年都有许多令人印象深刻的论文。
我从CVPR中选取已被录用的论文进行分析,了解研究的主要领域和论文题目中的常见关键词。这可以提供研究进展的一个迹象。
底层数据和代码可以在我的Github:https://github.com/priya-dwivedi/Deep-Learning/blob/master/cvpr2019/CVPR2019_stats.ipynb上找到。
CVPR为每篇论文指定一个主要的主题区域。按学科类别划分的获接纳论文的细目如下:
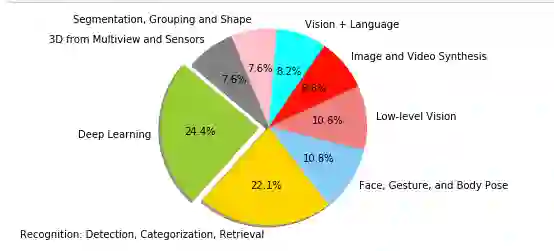
不出所料,大多数研究都集中在深度学习(现在还不是所有的都是深度学习!)、检测和分类以及面部/手势/姿势。这种分解是非常普遍的,并不能提供很好的见解。所以接下来我从被接受的论文中提取出所有的单词,并使用计数器来计算它们的频率。最常见的25个关键词如下:
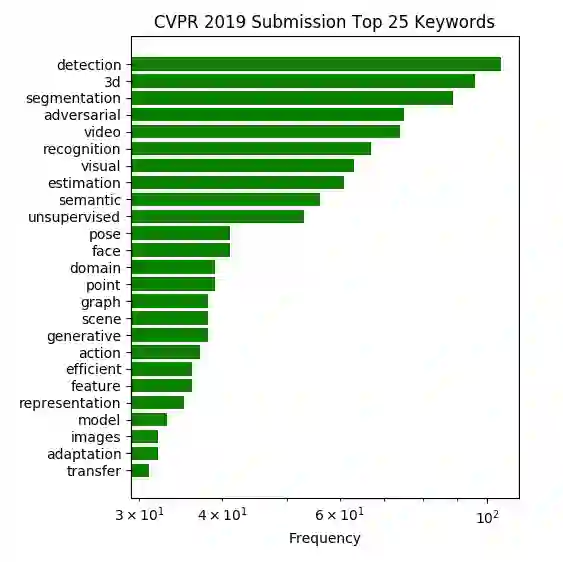
现在这个更有趣了。最流行的研究领域是检测、分割、3D和对抗性训练。这也表明了对无监督学习方法的研究越来越多。
最后,我还绘制了单词云图。

你可以使用我的Github按主题提取排在前面的论文,如下所示:

在接下来的博客中,我从研究的关键领域中选择了5篇有趣的论文。请注意,我挑选了一些最吸引我的论文。
Learning the Depths of Moving People by Watching Frozen People:https://arxiv.org/abs/1904.11111
人类的视觉系统有一种非凡的能力,从它的二维投影来理解我们的三维世界。即使在有多个运动物体的复杂环境中,人们也能够对物体的几何形状和深度顺序保持一个可行的解释。在过去的几年里,利用相机图像进行深度估计已经做了很多工作,但是在许多情况下,鲁棒重建仍然是困难的。当摄像机和场景中的物体都在自由移动时,就会出现一个特别具有挑战性的情况。这混淆了基于三角划分的传统3D重建算法。
本文通过在摄像机和被摄对象自由移动的场景中建立深度学习模型来解决这一问题。
为了创建这样一个模型,我们需要通过移动摄像机捕捉到的自然场景的视频序列,以及每个图像的精确深度图。创建这样一个数据集将是一个挑战。为了克服这个问题,这篇论文非常创新地使用了一个现有的数据集——YouTube视频,其中人们通过冻结在各种各样的自然姿势来模仿人体模型,同时手持摄像机在场景中漫游。由于场景是静止的,只有相机在移动,因此可以使用三角测量技术构建精确的深度图。这篇论文读起来很有趣。它解决了一个复杂的问题,并且在为它创建数据集方面非常有创意。
经过训练的模型在带有移动摄像头和人的互联网视频剪辑上的表现比以往任何研究都要好得多。见下图:

BubbleNets: Learning to Select the Guidance Frame in Video Object Segmentation by Deep Sorting Frames:https://arxiv.org/abs/1903.11779
我看了几篇关于视频物体分割(VOS)的论文。这是在视频中分割物体的任务,在第一帧中提供一个注释。这在视频理解中得到了应用,并在过去的一年里进行了大量的研究。
视频中物体的位置和外观会随着帧与帧之间的变化而发生显著的变化,本文发现使用不同的帧进行标注会显著改变性能。
BubbleNets迭代地比较和交换相邻的视频帧,直到预测性能最大的帧排名最高,然后选择该帧供用户注释并用于视频物体分割。
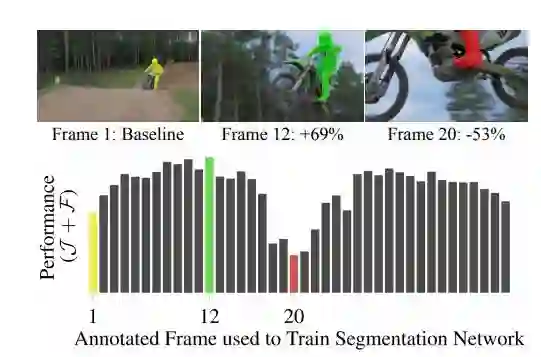
模型的视频描述在youtube上共享,源代码在Github上开源。
使用BubbleNets模型预测两帧之间的相对性能差异。相对性能是通过结合区域相似性和轮廓精度来衡量的。
输入2帧比较,3帧参考。然后它通过ResNet50和完全连接的层来输出一个数字f,表示两帧的比较。为了执行冒泡排序,我们从前两帧开始比较它们。如果BubbleNet预测第1帧的性能优于第2帧,则交换帧的顺序,并将下一帧与目前最好的帧进行比较。在处理完整个视频序列后,最佳帧仍然存在。下图显示了冒泡排序的BubbleNets体系结构和流程。
总的来说,作者表明,在不改变底层分割算法的情况下,改变注释帧的选择方式会使DAVIS benchmark data set的性能提高11%。
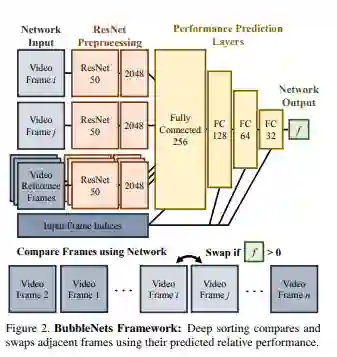
Bubblenets architecture
3D Hand Shape and Pose Estimation from a Single RGB Image:https://arxiv.org/pdf/1903.00812.pdf
手的三维形状和姿态估计是近年来一个非常活跃的研究领域。这在VR和机器人领域都有应用。本文使用单目RGB图像创建一个三维手部姿态和环绕手部的三维网格,如下图所示。

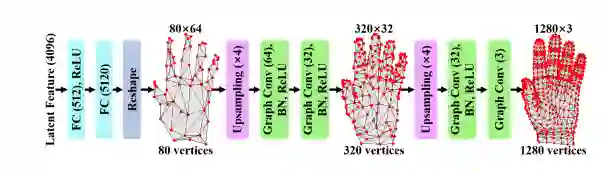
本文利用CNNs图重建手部三维网格。为了训练网络,作者创建了一个包含ground truth三维网格和三维姿态的大规模合成数据集。在真实的RGB图像上手工标注ground truth 3D手网格是非常费力和耗时的。然而,基于合成数据集的模型与实际数据集之间的区域差距导致模型的估计结果往往不尽人意。为了解决这一问题,作者提出了一种新的弱监督方法,利用深度图作为三维网格生成的弱监督,因为在采集真实世界的训练数据时,深度图可以很容易地被RGB-D摄像机捕获。本文在数据集、训练过程等方面做了详细的阐述。如果这是你感兴趣的领域,请通读一遍。
对我来说,一个有趣的学习是CNN用于网格生成的图的架构。这个网络的输入是来自RGB图像的一个潜在向量。它通过两个完全连接的层,以粗略图的形式输出80x64个特征。然后,它通过层层向上采样和CNNs图来输出更丰富的细节,最终输出1280个顶点。
Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection:http://openaccess.thecvf.com/content_CVPR_2019/papers/Xu_Reasoning-RCNN_Unifying_Adaptive_Global_Reasoning_Into_Large-Scale_Object_Detection_CVPR_2019_paper.pdf

随着计算机视觉的广泛应用,目标检测得到了广泛的应用。Faster RCNN是一种常用的物体检测模型。然而,当检测类的数量小于100时,物体检测是最成功的。这篇文章针对具有数千个类别的大规模物体检测问题,提出了一种基于长尾数据分布、重遮挡和类模糊的目标检测方法。
Reasoning-RCNN通过构建一个知识图谱来实现这一点,该图对人类常识进行编码。什么是知识图谱?知识图编码物体之间的信息,如空间关系(on、near)、主谓宾关系(如Drive、run)以及属性相似性(如颜色、大小、材质)。如下图所示,具有视觉关系的类别彼此之间距离更近。
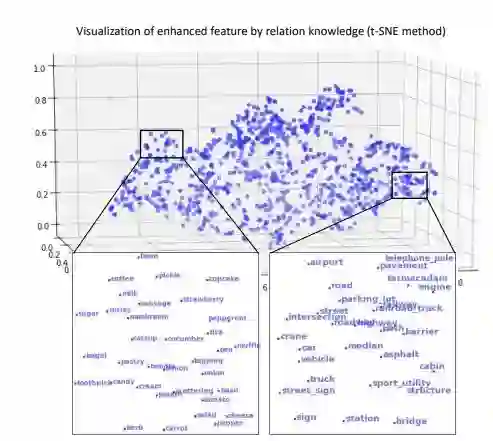
知识图谱
在架构方面,它在标准的物体检测器(如Faster RCNN)之上堆叠了一个推理框架。通过收集分类器的权值,生成所有类别的全局语义池,并将其输入自适应全局推理模块。增强的类别上下文(即,推理模块的输出)通过软映射机制映射回区域proposal。最后,利用每个区域的增强特征以端到端方式提高分类和定位的性能。下图显示了模型体系结构。
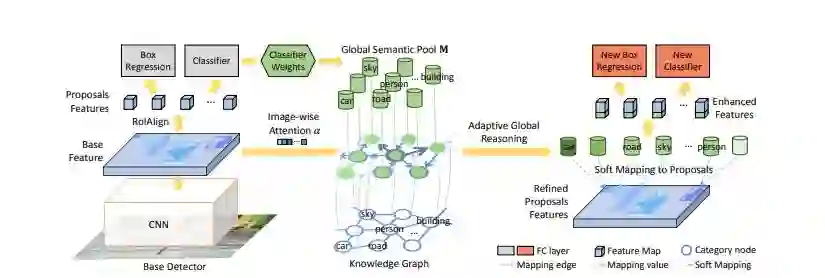
该模型在3个主要数据集上进行训练和评估——Visual Gnome(3000个类别)、ADE(445个类别)和COCO(80个类别)。该模型能够在Visual Gnome上获得16%的提升,在ADE上获得37%的提升,在COCO上获得15%的提升。
Deep Learning for Zero Shot Face Anti-Spoofing:http://arxiv.org/abs/1904.02860
近年来,人脸检测技术取得了很大的进步,人脸检测与识别系统在许多领域得到了广泛的应用。事实上,我们可以用8行代码建立一个系统来检测人脸、识别人脸并理解他们的情绪。
然而,也有风险,人脸检测被欺骗,以获得非法访问。人脸反欺诈是为了防止人脸识别系统将假人脸识别为真实用户而设计的。在开发先进的人脸反欺诈方法的同时,新型的欺诈攻击也在不断产生,并对现有的系统构成威胁。文章介绍了一种检测未知欺诈攻击的概念,即零样本人脸反欺诈。以前的人脸反欺诈只研究了1- 2种类型的欺诈攻击,比如打印/重放,这限制了对这个问题的理解。该工作在13种类型的欺骗攻击(包括打印、重放、3D蒙版等)中广泛地研究了人脸反欺诈问题。下图显示了不同类型的欺诈攻击。
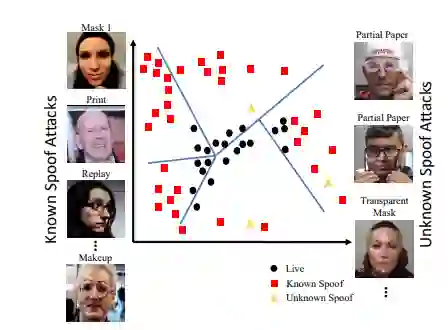
人脸欺骗可以包括打印(打印人脸照片)、重放视频、3D蒙版、眼睛裁剪人脸照片、化妆、透明蒙版等多种形式。本文提出了一种利用深度树网络从无监督的欺诈图片中学习语义嵌入的方法。嵌入在这里可以模拟像人类凝视这样的东西。它创建一组欺诈图像的数据集来学习这些嵌入。在测试过程中,将未知攻击投射到嵌入中,寻找最接近的属性进行欺诈检测。
阅读论文了解更多关于深树网络模型体系结构和训练过程的细节。本文能够创建嵌入,用各种类型的欺骗分离出活的人脸(真实的脸)。参见下面的t-SNE图:
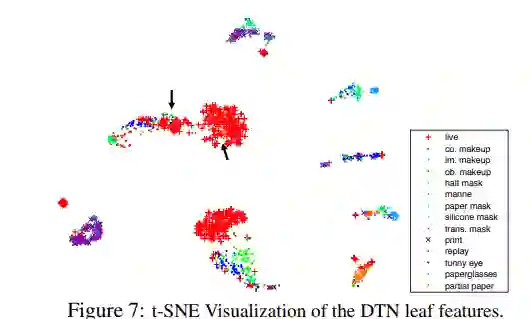
这篇论文很棒。是有希望解决实际问题的的研究。
总结
看到计算机视觉方面的所有最新研究是非常有趣的。这里分享的5篇论文只是冰山一角。我希望你能使用我的Github对论文进行分类,并选择你感兴趣的论文。

英文原文:https://towardsdatascience.com/latest-computer-vision-trends-from-cvpr-2019-c07806dd570b
重磅!CVer学术交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



