为什么你学了 N 遍 Spring Boot,至今还是学生项目?你的问题在这里 | 原力计划


为什么你学了n遍《1天精通Spring Boot》,至今还是不精通Spring Boot,甚至还是停留在学生项目?真正要做项目就应该一步到位,半吊子半桶水是不行的。一个实战项目需要充分考虑状态码、异常处理、日志处理、性能监控、数据安全、部署等等因素,而不是急于求成,为了达到1天精通的目标而糊弄过去。
笔者在大学时也经历过学了很多Spring Boot的教材,但是比起外包(哪怕是个小程序),总觉得比真实项目缺了点什么,项目跑起来也是分分钟解体。本篇适合有一定后端开发基础(不涉及中间件,会在Spring Cloud讲),但是又停留于学生项目的读者(不同语言均有借鉴意义)。
问题分析:

项目监控
项目能跑就行!管他什么项目监控,项目问题通通等用户反馈,挂了就重启!SQL慢用户就等着,我怎么知道哪里执行慢?项目访问不了就是用户网络问题!用户遇到问题就是一清缓存、二换浏览器、三重启大法好!你怕是没经过社会的毒打,KPI分分钟垫底,再过2个月就可以实现家里蹲的愿望了。
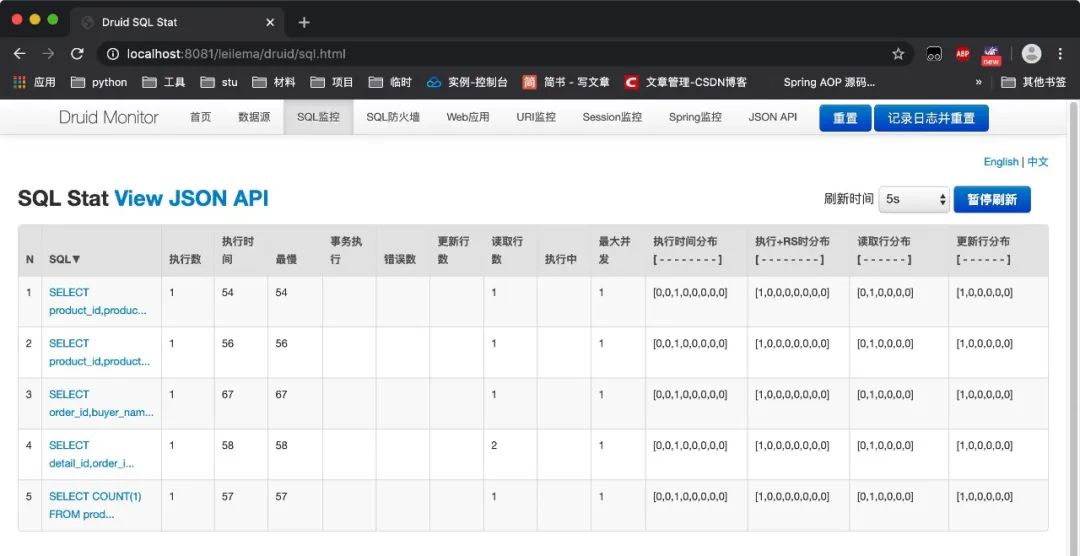
这里拿alibaba的druid做个例子,druid可以监控以下几个部分:
数据源:显示当前项目下所有数据源,多数据源的项目才会用到。当然了,肯定不会显示密码。
SQL监控:监控所有执行的SQL语句,包括耗时,参数等等。
SQL防火墙:druid提供了黑白名单的访问,可以清楚的看到SQL防护情况。
Web应用:可以看到目前运行的Web程序的并发数,事务书等等详细信息。
URI监控:可以监控到所有的请求路径的请求次数、请求时间等参数。
Session监控:监控session状况,创建时间、最后活跃时间、请求次数、请求时间等参数。
集成完druid,项目马上提高一个档次,可以在boss面前打开页面吹嘘一把。最最关键的是,集成druid是分分钟的事情,几乎没有代码的侵入性,要改造也只需添加个bean,改下配置文件。详细可参考springboot集成druid,绝对是排查慢SQL、优化性能、监控项目居家必备良药!

日志
日志记录操作轨迹、监控系统运行状态、回溯系统故障,保留系统故障现场,方便程序员快定位问题。生产环境不同于学生项目,随时有问题就重启debug,在公司里,开发人员你碰服务器的资格都没有,所以保留日志成了排查Bug唯一的方法。这里就谈谈容易被忽视的几点:
等级:DEBUG<INFO<WARN<ERROR<FATAL,程序员应该预先判断好日志等级。不是所有日志一打就是log.error(),比方说业务异常往往只需要通过引导用户正确操作就可以解决,那么应该将他归为log.warn()级别。如果一股脑全部日志都打成log.error(),error日志几万行(里面99%都只是校验输入出错),看到就头疼,谁去排查error日志上的问题?
定期巡检:初级项目往往是用户反馈了故障才进行问题排查。而标准的项目应该定期巡检error日志,因为②中已经做好的分类,error一定是需要人为介入的,将这些error日志逐条排查便可以提前发现项目潜在风险。
日志完整性:初学者往往会打出log.error(e.getMessage)或log.error("错误信息:" + e)的日志,这种写法将吃掉所有的堆栈信息!这是非常非常严重的事情,正确的写法应该是logger.error("第x部分出错 " + e)。
日志配置:初学者往往并不关心日志文件存放在哪里,日志文件保留多久,日志文件按等级生成等配置细节,而作为一名架构师,你需要充分评估项目的需求,对这些进行自定义的配置。笔者也曾因为不关心这些配置,导致日志爆满撑死服务器!
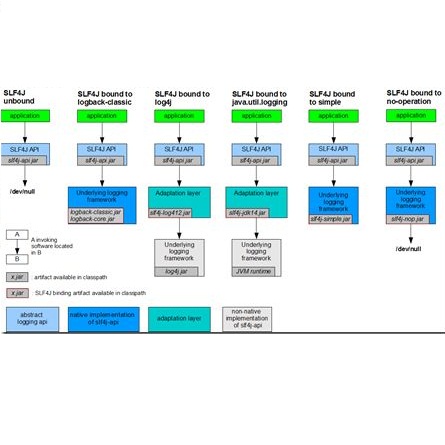
日志框架分为日志门面、日志实现库、日志适配器三类。JCL、SLF4j、Jboss-logging这些框架都是日志门面;而真实干活的人则是日志实现库,常见的Log4j、Log4j2、Logback、JUL;当门面与实现库不匹配时则需要日志适配器。当然现在百分之90的项目使用的都是slf4j + logback,可以不太关心日志框架的选型。但是如果你立志成为一名架构师,那框架的选型就是一门必修课,还是得去了解。

状态码

对比一下上图有什么区别?很简单,就是多了个状态码。有没有这个状态码似乎对前端请求的数据也没什么影响,不加状态码前端还是可以正常显示。确实,在核心数据上是不会有任何影响的,但是一旦出现一些业务异常,返回的数据就会如下图所示:
{
"timestamp":
"2020-04-25T03:55:26.179+0000",
"status": 500,
"error":
"Internal Server Error",
"message":
"\n### Error querying database. Cause: java.sql.SQLException: sql injection violation, syntax error: syntax error, error in :\u0027 asd from product_info where produc\u0027, expect IDENTIFIER, actual IDENTIFIER pos 12, line 1, column 13, token IDENTIFIER null : select * asd from ...
}
如果能与前端妹子好好商量一下状态码的规则,那么前端就可以通过不同的状态码,判断不同的请求响应等级,例如:
当接受到200时,说明正常,直接取data数据,进行正常的展示;
如果遇到1000~2000的,说明只是普通的警告,调用⚠️的弹窗,显示一下msg就可以了;
如果遇到2000+的说明时是重大问题,需要获取msg作为弹窗title,并从data中获取异常信息……
不然你就随心所欲抛异常,想怎么返回就怎么返回,前端妹子提刀就来找你了。想想自己为什么还是单身?或许就是因为没跟前端妹子在大明湖畔约定好状态码吧。

学生项目往往就是不到IDE报无法编译,不到万不得已坚决不进行异常处理!而异常处理又至关重要!那就大致来了解一下吧。
所有异常都是Throwable的子类,分为Error致命异常和Exception非致命异常。
Error异常往往是StackOverflowError、OutOfMemoryError这类根本无能为力的异常,既然无能为力了,我们也不需要太关心了,只需要记录日志,也只能到时候排查了。
Exception这类异常又分为checked和RuntimeException、checked是需要显示处理的异常,比如io异常等,你不处理就编译不了,也就是上面说的不到万不得已坚决不进行异常处理的异常,这类因为每次Idea都会提醒。
而我们关心的是RuntimeException,这类,这类异常往往是业务异常,正常的做法是封装一个AppException继承自RuntimeException,在发现业务异常时,配合状态码抛出对应异常:
@Getter
public
class APIException extends RuntimeException {
private
int code;
private String msg;
// 手动设置异常
public APIException(StatusCode statusCode, String message) {
// message用于用户设置抛出错误详情,例如:当前价格-5,小于0
super(message);
// 状态码
this.code = statusCode.getCode();
// 状态码配套的msg
this.msg = statusCode.getMsg();
}
// 默认异常使用APP_ERROR状态码
public APIException(String message) {
super(message);
this.code = AppCode.APP_ERROR.getCode();
this.msg = AppCode.APP_ERROR.getMsg();
}
}
通常来说,一般抛出业务异常的是在service层或者相关的逻辑业务层进行,并且配合状态码进行抛出:
throw
new APIException(AppCode.PRODUCT_NOT_EXIST,
"上架商品中无法查询到:" + orderDetail.getProductId());
@RestControllerAdvice
@Slf4j
public
class ControllerExceptionAdvice {
@ExceptionHandler({BindException.class})
public ResultVo MethodArgumentNotValidExceptionHandler(BindException e) {
// 从异常对象中拿到ObjectError对象
ObjectError objectError = e.getBindingResult().getAllErrors().
get(
0);
return new ResultVo(ResultCode.VALIDATE_ERROR, objectError.getDefaultMessage());
}
@ExceptionHandler(APIException.class)
public ResultVo APIExceptionHandler(APIException e) {
log.error(e.getMessage(), e);
return new ResultVo(e.getCode(), e.getMsg(), e.getMessage());
}
}

单元测试的意义并不仅仅在于发现现有代码Bug。一个好的单元测试可以作为测试用例固化在项目中,方便程序员进行重构和修改。如上图,自己都可能出现不敢删掉冗余代码的情况,更何况是重构代码?修改代码?甚至是接手别人的代码?在公司中,正常一套代码会有AB角之分,保证其中一方跑路跳槽,项目也不会出现人员断层,确保项目能正常进行:
A角经历开发的完整周期,对功能潜在bug往往比B角清楚的多。当A角能写好单元测试,B角只需重构修改好代码,再重新运行一遍单元测试便可以安心上线
而当A角完全不写单元测试,B角接手后大概就是。“卧靠,这段tm能不能改啊?”,“这不会有特殊情况吧?”,“这其他地方不会用到吧?”,“这tm该不会是业务需求讨论,为后续模块预留的吧?”……
如果说,公司某个A角邀请你签他的AB角生死状,请先看一下他的单元测试覆盖率等指标,如果一个单元测试都不写的,打死都不签!不然改完代码一上线很可能又是解体操作!

服务器
这点笔者深有体会,在大学期间,总是听人说服务器就是一台电脑。但是你说任你说,我还是觉得服务器是一个高端大气又特别神秘的东西!自己的代码永远都运行在IDEA上,哪怕我知道部署项目的所有步骤,却一直止步不前,总觉得少了点什么。直到第一次接触到服务器,才发现原本以为这货真的是个电脑!这货真的就是个Linux!而且通过公网IP、域名真的可以访问到自己的项目!
如果你也有这方面的困惑,请花一笔几十块钱的巨资去买阿里云或者腾讯云买个服务器,然后亲手实操一遍,服务器、公网IP、域名(几块钱)这些都是本机虚拟机无法模拟的东西!最好学习一下docker部署springboot项目,详见docker部署MySQL、SpringBoot。纸上读来终觉浅!去实际操作一把,相信对你会有实质上的提升!这里笔者提供给大家学习的《一步到位SpringBoot系列》数据库也是部署在服务器上的。
《一天精通SpringBoot》是不现实的,如果真是这样,那Java后端程序员也就太没有含金量了。麻雀谁小五胀俱全,一个哪怕再小的小程序项目,只要要上线,就都得经历一个项目的完整过程,少的可能只是中间件的优化。
如果说要学习SpringBoot,目标已经明确就是Java后端,那为什么不一步到位呢?又想学习SpringBoot后端的同学可以参考《一步到位SpringBoot》,保证搭建出一套健壮的,不会解体操作的后端框架。
《一步到位SpringBoot》链接:
https://blog.csdn.net/chaitoudaren/article/details/105624082
版权声明:本文为CSDN博主「bugpool」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/chaitoudaren/article/details/105745335


更多精彩推荐
☞顺丰正式杀入外卖领域;中国移动推出 5G 消息 App;GCC 10.1 发布 | 极客头条
☞你现在从事的程序员还有多久会消失?牛津大学研究员帮你算了算
![]()
你点的每个“在看”,我都认真当成了喜欢