使用以 Tensorflow 为后端的 Keras 构建生成对抗网络的代码示例

本文为 AI 研习社编译的技术博客,原标题 :
GAN by Example using Keras on Tensorflow Backend
作者 | Rowel Atienza
翻译 | GuardSkill、鲁昂 编辑 | 王立鱼
原文链接:
https://towardsdatascience.com/gan-by-example-using-keras-on-tensorflow-backend-1a6d515a60d0
注:本文的相关链接请访问文末【阅读原文】
生成式对抗网络(GAN)是近期深度学习领域中最有前景的发展之一。 GAN由Ian Goodfellow于2014年推出,它通过分别训练两个相互竞争和合作的深度网络(称为生成器[Generator]和鉴别器[Discriminator])来进军无监督学习的问题。 在训练过程中,两个网络最终都会学习到如何执行各自任务。
GAN就像是假币伪造者(Generative)和警察(Discriminator)之间的故事。最开始时假币团伙的假钱将被警方发现,警方发现假币后,将向广大人民群众张贴假币实例和辨伪方法。这相当于警察向伪造者提供了反馈,告诉了为什么钱是假的。 假币团伙试图根据收到的反馈制作新的假钱。警方表示,这些钱仍然是假的,并向人民群众提供了一套新的辨伪方法。 假币团伙试图根据最新反馈制作新的假钱。这个循环无限期地持续下去,直到警察被假币愚弄,因为它现在看起来真的很真实。
虽然GAN的理念在理论上很简单,但构建一个可以工作的模型却非常困难。在GAN中,有两个深度网络耦合在一起,使得梯度的反向传播具有挑战性,因为反向传播需要进行两次。 深度卷积生成式对抗网络(DCGAN)展示了如何构建实用GAN的模型,该GAN能够自己学习如何合成新图像。
在本文中,我们将讨论如何在少于200行代码中使用以Tensorflow 1.0为后端的Keras 2.0构建能够工作的DCGAN。我们将使用MNIST训练DCGAN学习如何生成手写数图片。
鉴别器
鉴别器用了辨别一个图像的真实性,通常使用图一所示的深度卷积神经网络。对于Mnist数据集,输入是28*28*1的一帧图像。输出时一个标量,其大小用来表示图像的真实性(0是假的,1是真的,其他值无法缺人)。和常规的CNN相比,它通过跨距卷积(strided convolution)替代了之前的层间最大池化操作用来降采样。每个CNN层之间使用弱relu作为激活函数。使用0.4-0.7的dropout操作来避免过拟合和记忆化(memorization)。下面给出了keras中的实现。
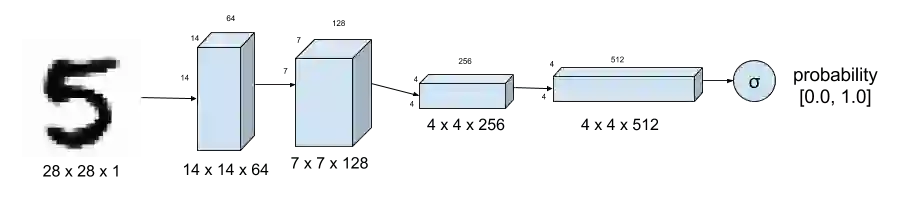
图1. DCGAN的鉴别器告诉我们数字的输入图像是多么真实。 MNIST数据集用作真实图像的基础事实。 跨步卷积而不是最大化下采样图像。
self.D = Sequential()depth = 64dropout = 0.4# In: 28 x 28 x 1, depth = 1# Out: 14 x 14 x 1, depth=64input_shape = (self.img_rows, self.img_cols, self.channel)self.D.add(Conv2D(depth*1, 5, strides=2, input_shape=input_shape,\padding='same', activation=LeakyReLU(alpha=0.2)))self.D.add(Dropout(dropout))self.D.add(Conv2D(depth*2, 5, strides=2, padding='same',\activation=LeakyReLU(alpha=0.2)))self.D.add(Dropout(dropout))self.D.add(Conv2D(depth*4, 5, strides=2, padding='same',\activation=LeakyReLU(alpha=0.2)))self.D.add(Dropout(dropout))self.D.add(Conv2D(depth*8, 5, strides=1, padding='same',\activation=LeakyReLU(alpha=0.2)))self.D.add(Dropout(dropout))# Out: 1-dim probabilityself.D.add(Flatten())self.D.add(Dense(1))self.D.add(Activation('sigmoid'))self.D.summary()
代码1.图1中的Discriminator的Keras代码
生成器
生成器用来合成加图片。图二中展示了从100维的噪声(-1.0到1.0的均匀分布)中利用反向卷积(卷积的转置)生成假图片的过程。除了DCGAN中建议使用的反卷积fractionally-strided,对前三层的上采样也被用来合成更加接近真实的手写图像。层与层之间的批量正则化(batch normalization)也被用来稳定学习过程。各层的激活函数使用relu。最后一层的输出是假图像。采用0.3-0.5 的dropout避免第一层的过拟合。下面给出了对应的keras实现:
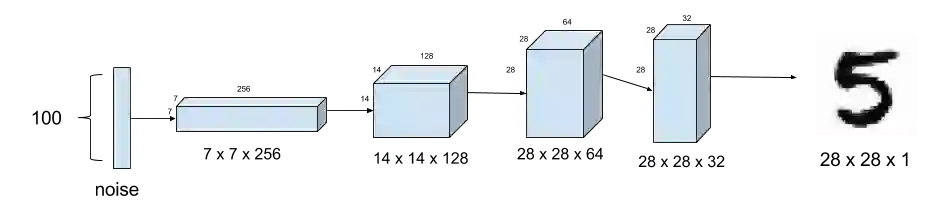
图2. Generator模型从噪声中合成伪造的MNIST图像。 使用上采样而不是分数跨越的转置卷积。
self.G = Sequential()dropout = 0.4depth = 64+64+64+64dim = 7# In: 100# Out: dim x dim x depthself.G.add(Dense(dim*dim*depth, input_dim=100))self.G.add(BatchNormalization(momentum=0.9))self.G.add(Activation('relu'))self.G.add(Reshape((dim, dim, depth)))self.G.add(Dropout(dropout))# In: dim x dim x depth# Out: 2*dim x 2*dim x depth/2self.G.add(UpSampling2D())self.G.add(Conv2DTranspose(int(depth/2), 5, padding='same'))self.G.add(BatchNormalization(momentum=0.9))self.G.add(Activation('relu'))self.G.add(UpSampling2D())self.G.add(Conv2DTranspose(int(depth/4), 5, padding='same'))self.G.add(BatchNormalization(momentum=0.9))self.G.add(Activation('relu'))self.G.add(Conv2DTranspose(int(depth/8), 5, padding='same'))self.G.add(BatchNormalization(momentum=0.9))self.G.add(Activation('relu'))# Out: 28 x 28 x 1 grayscale image [0.0,1.0] per pixself.G.add(Conv2DTranspose(1, 5, padding='same'))self.G.add(Activation('sigmoid'))self.G.summary()return self.G
代码2.图2中生成器的Keras代码
GAN 模型
到目前为止,还没有对应的机器学习模型。已经是时间用来构建训练用的模型了。我们使用两个模型:1. 鉴别模型(警察)2. 反模型或生成器模型(从警察那边学习知识的伪造者)。
鉴别器模型
下面的代码3展示了利用keras实现鉴别器模型的代码。他用来描述上面鉴别器用于训练的损失函数。因为鉴别器的输出是sigmoid,所以使用二元交叉熵来计算损失。对比Adam,这里使用RMSProp(均方根反向传播)来做为优化器生成更加接近真实的假图片。学习率为0.0008。为了稳定后续的学习,这里还添了权重衰减和输出值的clip。如果需要调整学习率,也需要对衰减作出响应的调整。
optimizer = RMSprop(lr=0.0008, clipvalue=1.0, decay=6e-8)self.DM = Sequential()self.DM.add(self.discriminator())self.DM.compile(loss='binary_crossentropy', optimizer=optimizer,\metrics=['accuracy'])
代码3. 鉴别模型的keras代码
反模型
图三中展示了生成-鉴别模型,生成器部分尝试骗过鉴别器并同时读取鉴别器的反馈。代码4给出了keras的代码实现。训练参数除了减小的学习率和对应的权重衰减其他训练参数都和鉴别模型一致。

图3. 反模型是简单的降他的输出连接到鉴别模型上。尝试去愚弄鉴别器使得输出的结果是1
optimizer = RMSprop(lr=0.0004, clipvalue=1.0, decay=3e-8)self.AM = Sequential()self.AM.add(self.generator())self.AM.add(self.discriminator())self.AM.compile(loss='binary_crossentropy', optimizer=optimizer,\metrics=['accuracy'])
代码4. 图3所示的keras实现的反模型
训练
训练是最难的一部分。首先需要保证鉴别器能够独自正确地区分真假图像。然后,鉴别器和反模型能够依次被训练。图4展示了当图3所示的反模型在训练阶段的鉴别模型。
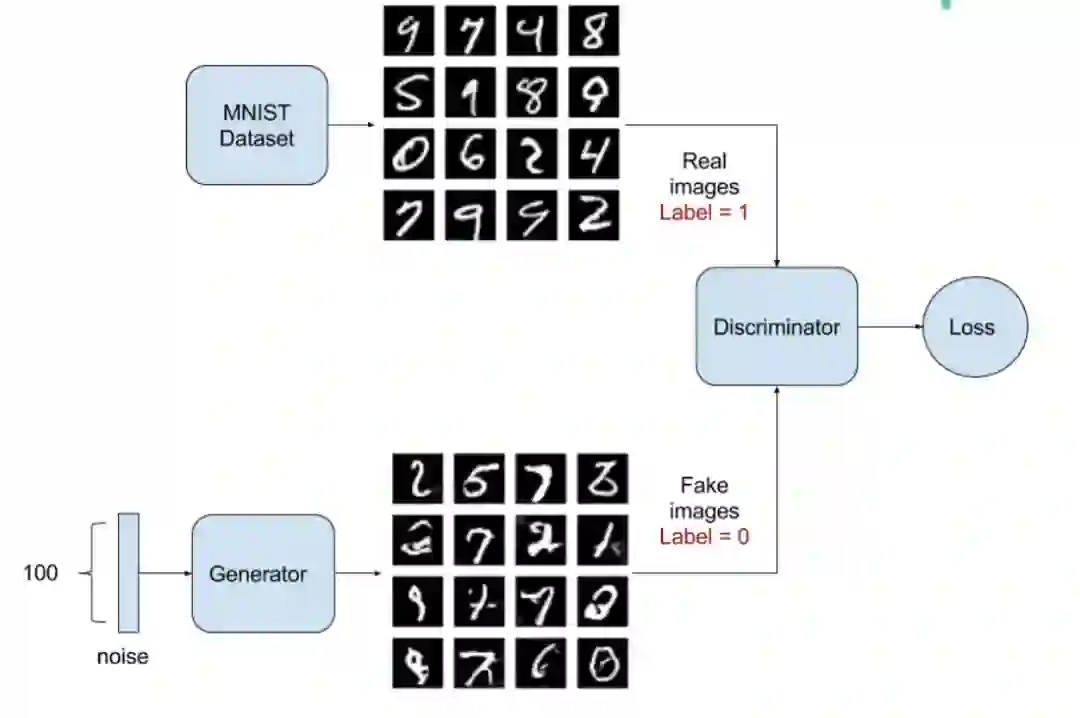
图4. 鉴别器被训练区分真假手写体图片
images_train = self.x_train[np.random.randint(0,self.x_train.shape[0], size=batch_size), :, :, :]noise = np.random.uniform(-1.0, 1.0, size=[batch_size, 100])images_fake = self.generator.predict(noise)x = np.concatenate((images_train, images_fake))y = np.ones([2*batch_size, 1])y[batch_size:, :] = 0d_loss = self.discriminator.train_on_batch(x, y)y = np.ones([batch_size, 1])noise = np.random.uniform(-1.0, 1.0, size=[batch_size, 100])a_loss = self.adversarial.train_on_batch(noise, y)
代码5. 序列的训练鉴别器模型和反模型。训练步骤超过1000次用以乘胜响应的输出。
训练GAN模型由于其深度需要极强的耐心,下面罗列了几点:
产生的图片看起来像噪声:对鉴别器和生成器的网络层之间添加dropout。较低的dropout值(0.3-0.6)将产生更加真实的图片
鉴别器的损失很快就收敛到0了,导致生成器无法学习:不要预先训练鉴别器。而是对于鉴别器使用稍大的学习率。对于生成器使用另一种训练噪声样本。
生成器的结果仍然像噪声:检查激活与否,batch normalization 和 dropout都被正确地应用在层序列上。
搞清楚正确的训练/模型参数:采用一些已知的参数,如论文或源代码,一次仅仅调整一个参数。在2000步或更多步的训练之前,观察参数值的效应并在500或1000步及时作出调整。
样本输出
图5显示了训练期间输出图像的演化过程,你可以看得出图5是十分的迷人,并且GAN在自己学习手写数字。
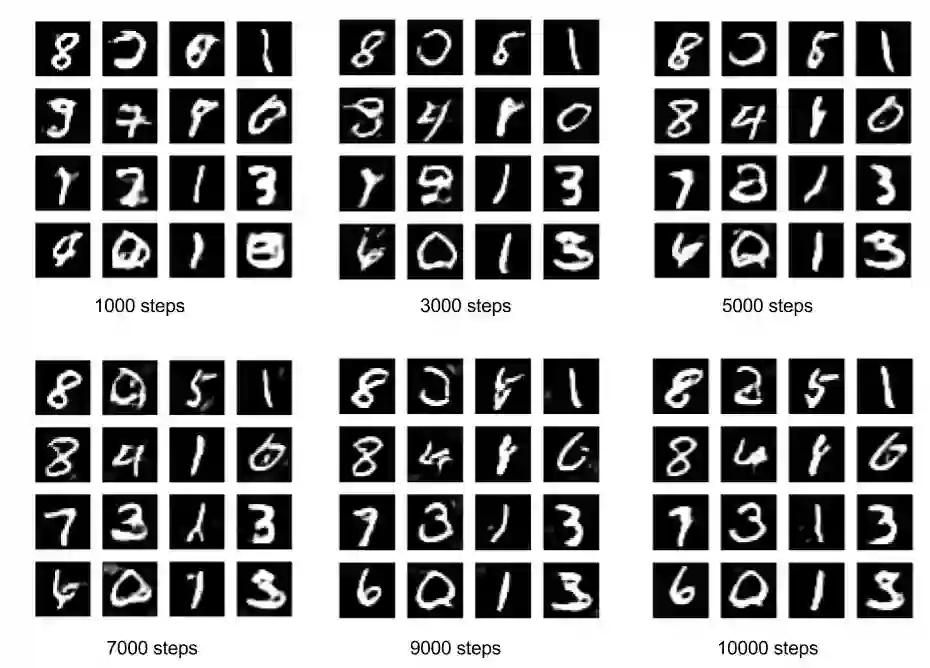
图5. DCGAN输出的图像
Keras 的完整代码请点击阅读原文查看.
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1548
滑动查看更多内容

<< 滑动查看更多栏目 >>




