NLP的12种后BERT预训练方法
作者:朝九晚九
学校:北京航空航天大学
研究方向:自然语言处理
论文:A Robustly Optimized BERT Pretraining Approach.
在更长的句子上训练,动态更改mask的模式。
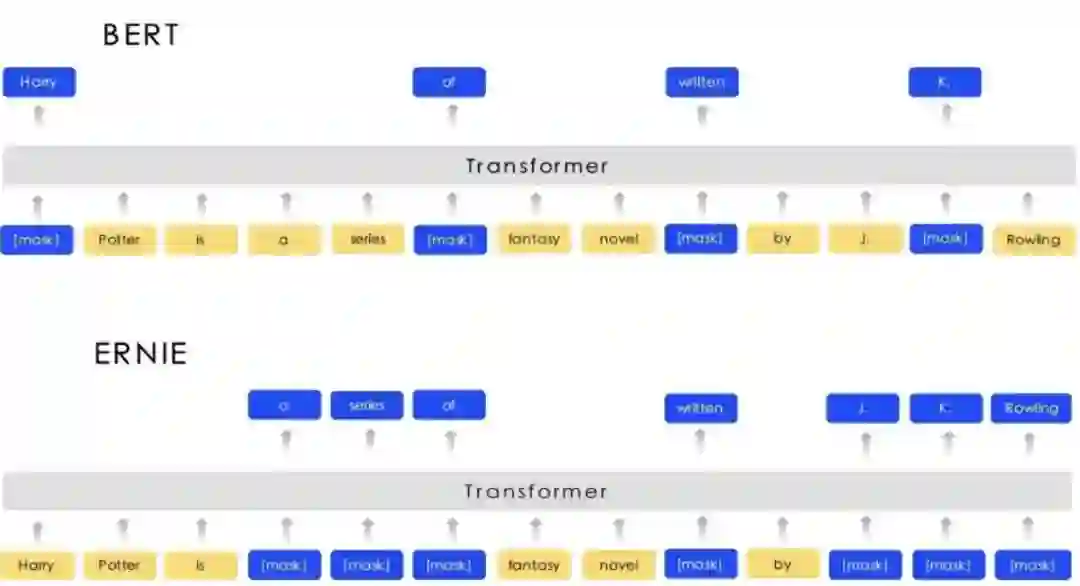
论文:Enhanced Representation through Knowledge Integration.
使用NLP的工具来识别短语和实体,包括3种层级的Masking:基本、phrase和entity。依次对基于基本级别、短语级别、实体级别分别进行mask训练。对于对话数据,还训练了Dialogue LM。使用Q和R标记query和response。
论文:A Continual Pre-training Framework for Language
Understanding.
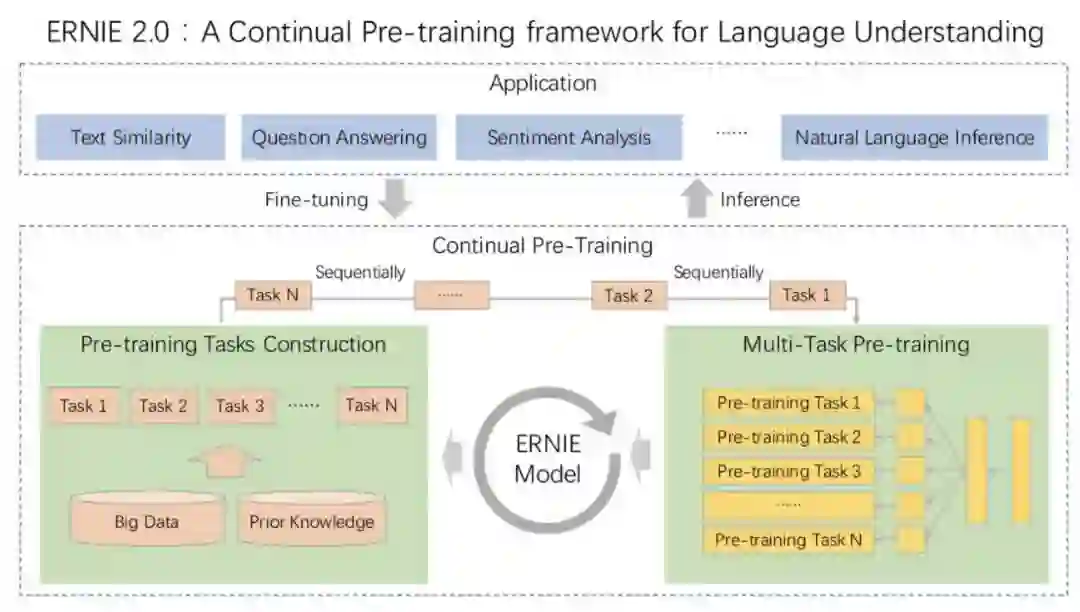
词法任务:Word、phrase、entity级别的mask;预测一个词是否首字母大小的任务;预测当前词是否出现在其他文档里
句法任务:把一个段落切分成1到m个段,随机打散,让模型来恢复;两个句子距离的任务,对于两个句子有三种关系:前后相邻,不相邻但是属于同一个文档,属于不同的文档
语义任务:预测两个句子的语义和修辞关系;利用搜索引擎的数据,给定query和搜索结果,预测两个句子是强相关,弱相关和完全不相关
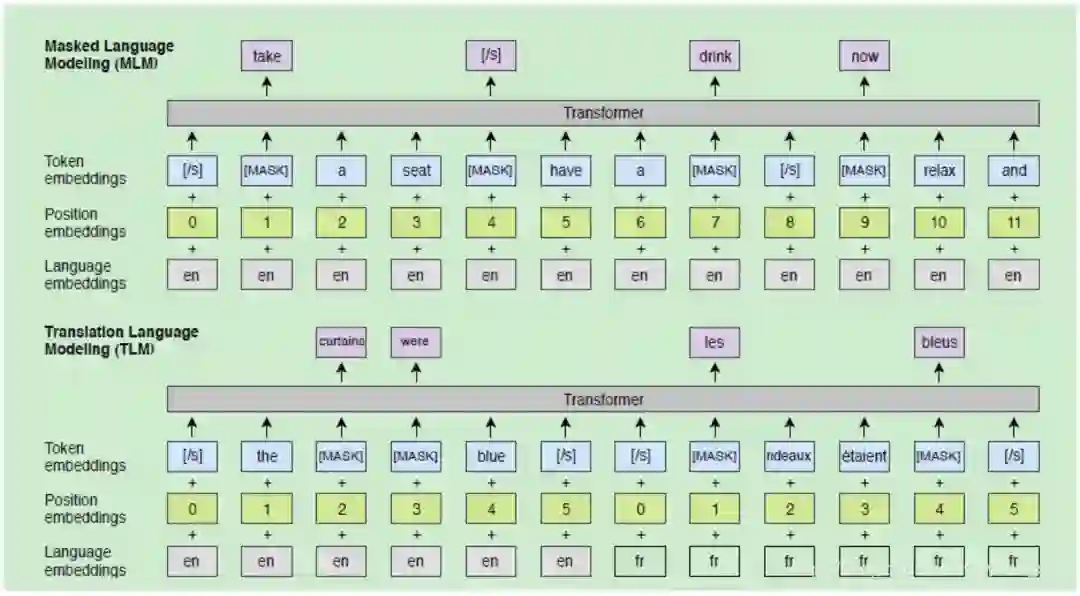
论文:Cross-lingual Language Model Pretraining.
跨语言版的bert,使用两种预训练方法:
基于单语种语料的无监督学习
基于跨语言的平行语料的有监督学习
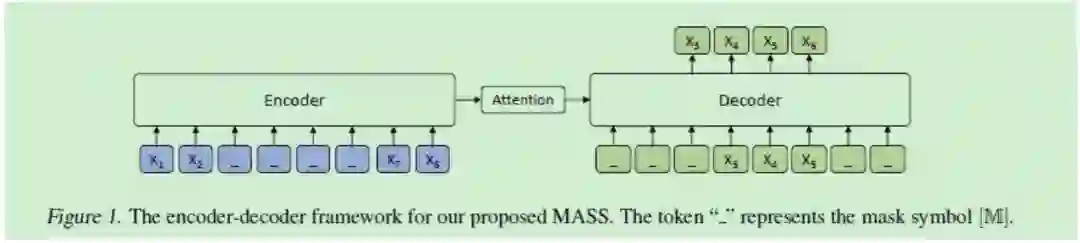
Encoder:输入为随机mask掉连续部分token的句子,使用transformer对其进行编码
Decoder:输入为与encoder同样的句子,但是mask掉的正好与encoder相反,使用attention机制训练,但是只预测encoder端被mask的单词。该操作可以迫使decoder预测的时候更依赖于source端的输入而不是前面预测出的token,防止误差传递。
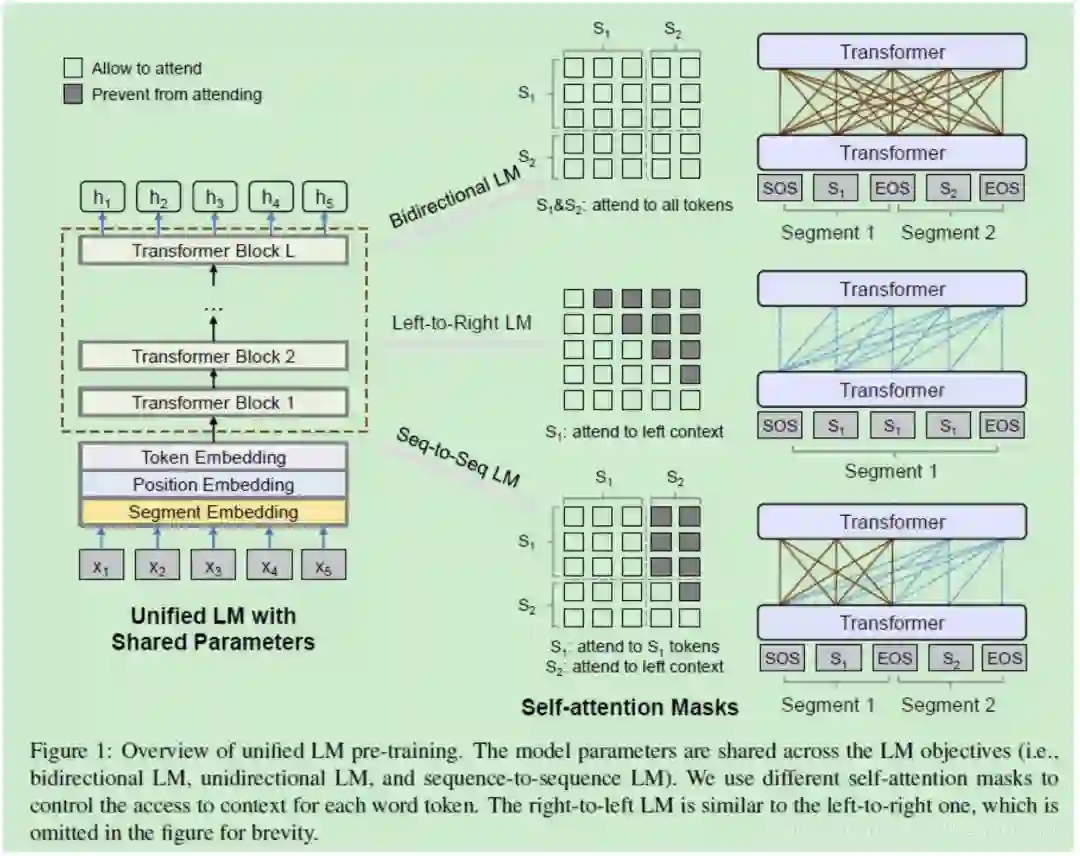
预训练了一个微调后可以同时用于自然语言理解和自然语言生成的下游任务模型,核心框架transformer,预训练和目标结合了以下三个:
单向语言模型(同ELMO/GPT),在做attention时只能mask其中一个方向的上下文
双向语言模型(同BERT),可以同时看到两个方向的上下文
seq2seq语言模型,输入为两个片段S1和S2,encoder是双向的,decoder是单向的,仅能attention到一个反向的token以及encoder的token
论文:Cross-lingual masked language model.
即跨语言掩码语言模型。对于无监督机器翻译而言,跨语言预训练模型XLM已被证实是有作用的,但是现有的工作中,预训练模型的跨语言信息只是通过共享BPE空间得到。这样得到的跨语言信号非常隐式,而且受限。CMLM可以将显式的跨语言信息作为训练信号,更好的训练跨语言预训练模型。方法分为3步:
由n-gram向量推断得到n-gram翻译表。分别用两种语言的单语语料通过fasttext训练单语的n-gram向量,之后通过无监督跨语言词向量的方法得到跨语言n-gram向量,并由两种语言的n-gram向量相似度推断得到两种n-gram之间的翻译表。
在n-gram翻译表的辅助下,用提出的新的训练任务CMLM进行跨语言预训练:随机的mask掉n-gram的字符,在模型输出端,让其预测被mask掉的n-gram字符对应的几个翻译选项。由于n-gram BPE字符的长度与其对应的翻译候选可能不一样,为此借助IBM Model 的思想进行改进。
用预训练的模型初始化翻译模型得到的编码器和解码器,进行无监督机器翻译模型的训练。
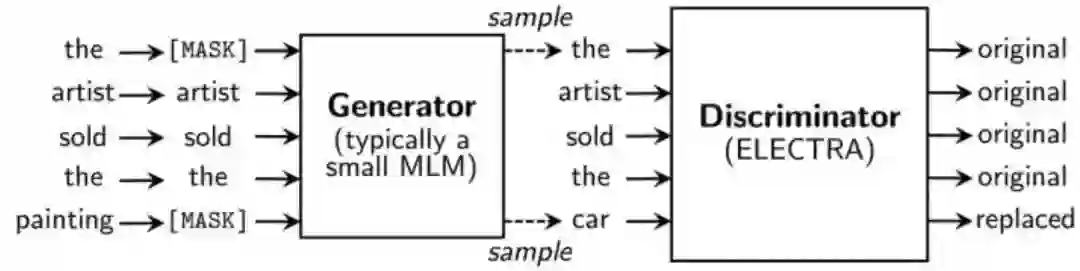
论文:Efficiently Learning an Encoder that Classifies Token Replacements Accurately.
提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。使用一个MLM的G-BERT来对输入句子进行更改,然后给D-BERT去判断哪个字被改过,如下:
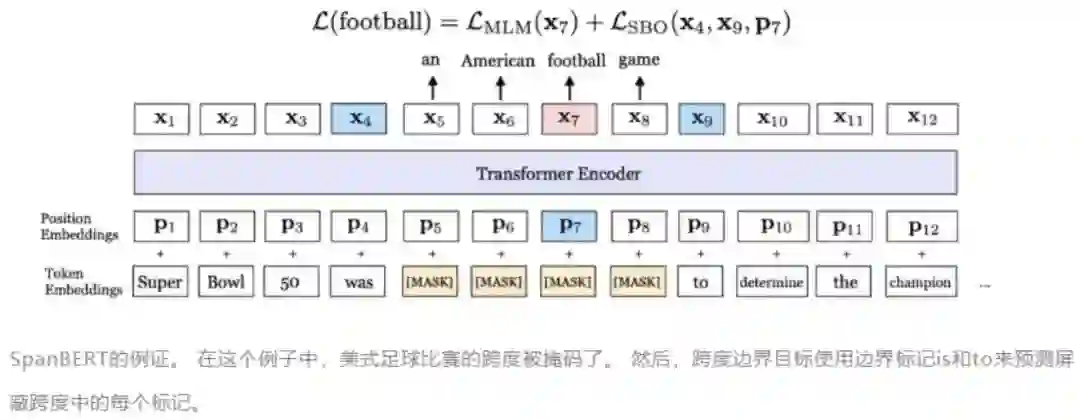
论文:SpanBERT:Improving Pre-training by Representing and Predicting Spans.
在跨度选择任务(例如问答和共指解析)方面取得了实质性进展。训练的方法主要是通过:
论文:A Lite BERT For Self-Supervised Learning Of Language Representations.
试图解决大部分预训练模型训练成本高,参数量巨大的问题。ALBERT为了减少模型参数主要有以下几点:
词嵌入参数因式分解;
隐藏层间参数共享

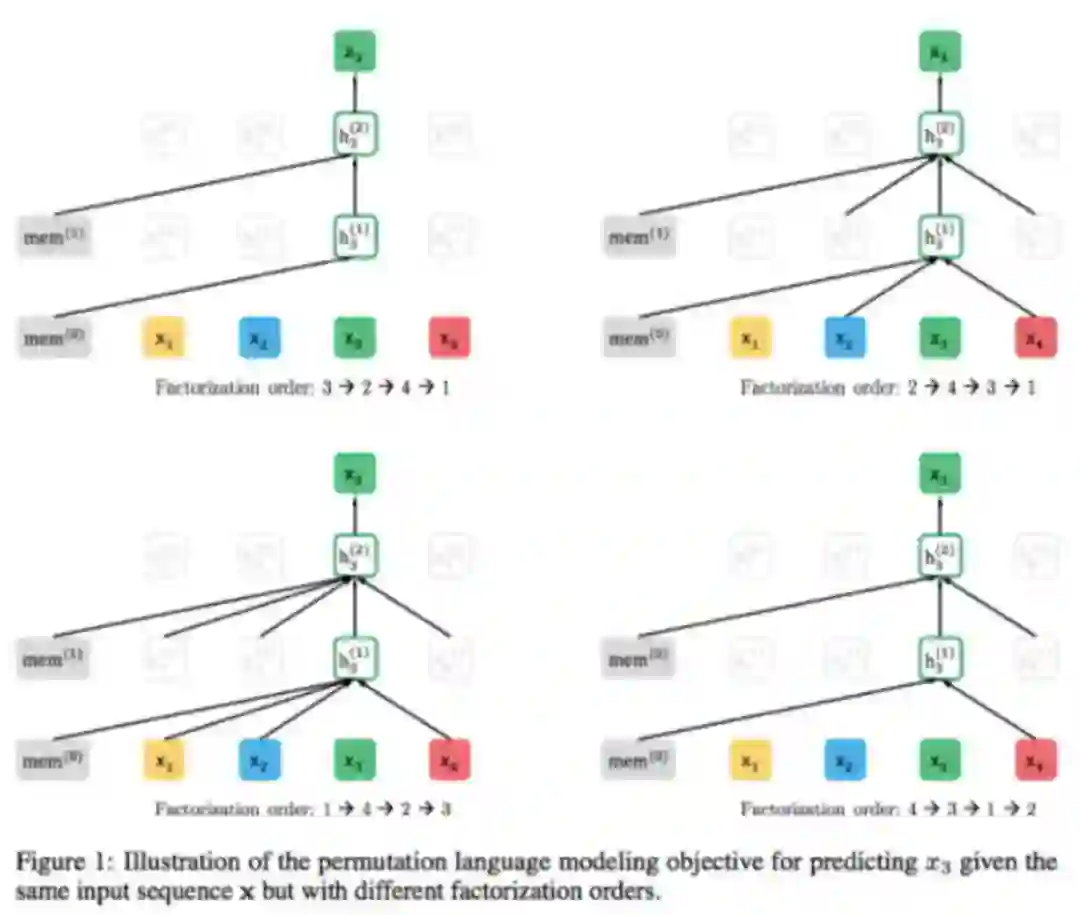
论文:Net: Generalized Autoregressive Pretraining for Language Understanding.
结合了自回归和自编码的优势,仍遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段,但是改动第一个阶段,不像Bert那种带Mask符号,而是采用排列组合的方式,借鉴自回归语言模型的方法预测下一个单词。且采用了双流自注意力机制。
本文转载自深度学习自然语言处理,作者朝九晚九
推荐阅读
大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。



