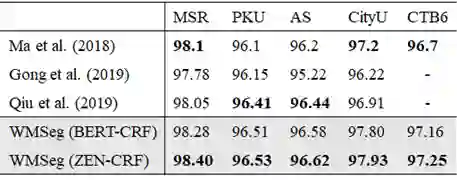
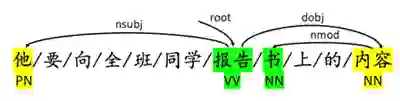
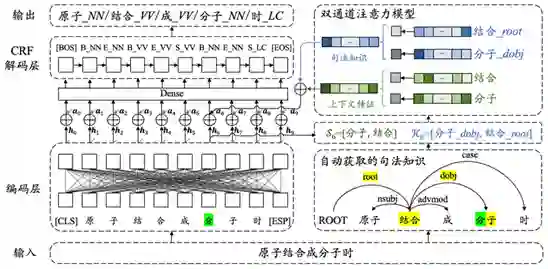
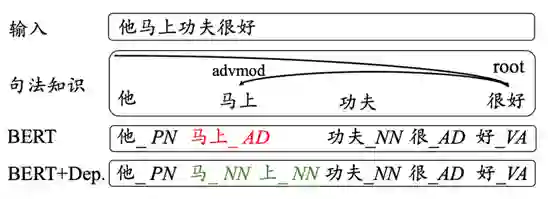
"Improving Chinese Word Segmentation with Wordhood Memory Networks"
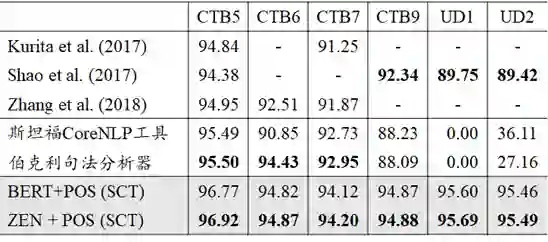
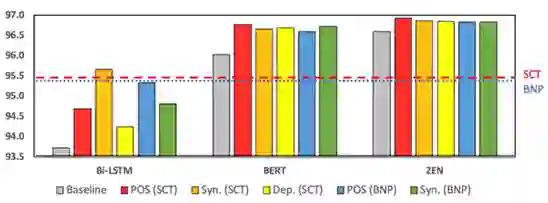
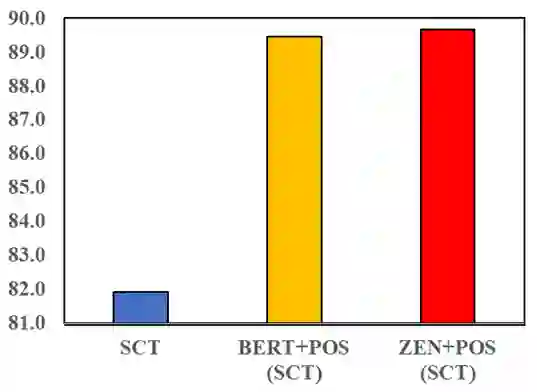
"Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-way Attentions of Auto-analyzed Knowledge" 7 月 8 日上午,创新工场大湾区人工智能研究院执行院长宋彦针对这两篇入选论文进行了线上的分享解读。他指出,虽然现有的很多文字编码器,例如像贝尔模型,虽然你能大到很好的效果, 但是依然无法达到效果和性能的额平衡。尤其是在工业场景下,我们需要进行人工干预以及后续处理, 才能将一句话进行合理的 fenci 处理。