自然语言处理顶会COLING2020最佳论文出炉!
计算语言学国际会议 COLING 2020(The 28th International Conference on Computational Linguistics)是计算语言学和自然语言处理领域的重要国际会议,由ICCL(International Committee on Computational Linguistics)主办,每两年举办一次,是CCF-B类推荐会议。本届COLING 2020将于2020年12月8日至13日以在线会议的形式举办。COLING 2020共计收到2180篇论文投稿,其中包括2021篇主会投稿、48篇Demo投稿、111篇工业论文投稿,最终有1900余篇论文进入审稿流程。官方Twitter公布了最佳论文。
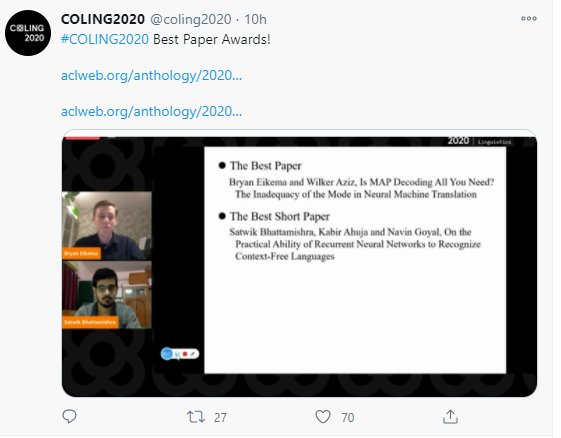
最佳论文

https://www.aclweb.org/anthology/2020.coling-main.398/
Recent studies have revealed a number of pathologies of neural machine translation (NMT) systems. Hypotheses explaining these mostly suggest there is something fundamentally wrong with NMT as a model or its training algorithm, maximum likelihood estimation (MLE). Most of this evidence was gathered using maximum a posteriori (MAP) decoding, a decision rule aimed at identifying the highest-scoring translation, i.e. the mode. We argue that the evidence corroborates the inadequacy of MAP decoding more than casts doubt on the model and its training algorithm. In this work, we show that translation distributions do reproduce various statistics of the data well, but that beam search strays from such statistics. We show that some of the known pathologies and biases of NMT are due to MAP decoding and not to NMT’s statistical assumptions nor MLE. In particular, we show that the most likely translations under the model accumulate so little probability mass that the mode can be considered essentially arbitrary. We therefore advocate for the use of decision rules that take into account the translation distribution holistically. We show that an approximation to minimum Bayes risk decoding gives competitive results confirming that NMT models do capture important aspects of translation well in expectation.
最佳短论文

https://www.aclweb.org/anthology/2020.coling-main.129/
While recurrent models have been effective in NLP tasks, their performance on context-free languages (CFLs) has been found to be quite weak. Given that CFLs are believed to capture important phenomena such as hierarchical structure in natural languages, this discrepancy in performance calls for an explanation. We study the performance of recurrent models on Dyck-n languages, a particularly important and well-studied class of CFLs. We find that while recurrent models generalize nearly perfectly if the lengths of the training and test strings are from the same range, they perform poorly if the test strings are longer. At the same time, we observe that RNNs are expressive enough to recognize Dyck words of arbitrary lengths in finite precision if their depths are bounded. Hence, we evaluate our models on samples generated from Dyck languages with bounded depth and find that they are indeed able to generalize to much higher lengths. Since natural language datasets have nested dependencies of bounded depth, this may help explain why they perform well in modeling hierarchical dependencies in natural language data despite prior works indicating poor generalization performance on Dyck languages. We perform probing studies to support our results and provide comparisons with Transformers.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“COLING” 可以获取《自然语言处理顶会COLING2020最佳论文》专知下载链接索引







