有了这个开源项目,说你是老板都有人信?
来自:开源最前线(ID:OpenSourceTop)
连接:https://towardsdatascience.com/you-can-now-speak-using-someone-elses-voice-with-deep-learning-8be24368fa2b
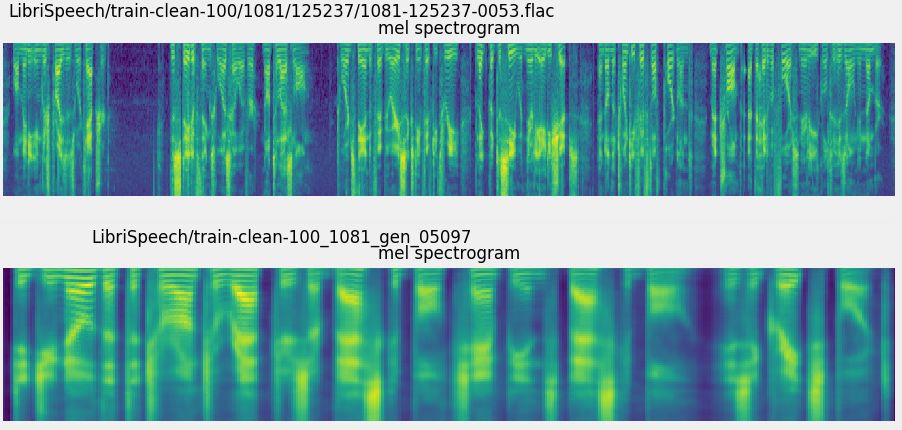

git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git
pip3 install -r requirements.txt
python demo_toolbox.py -d <datasets_root>
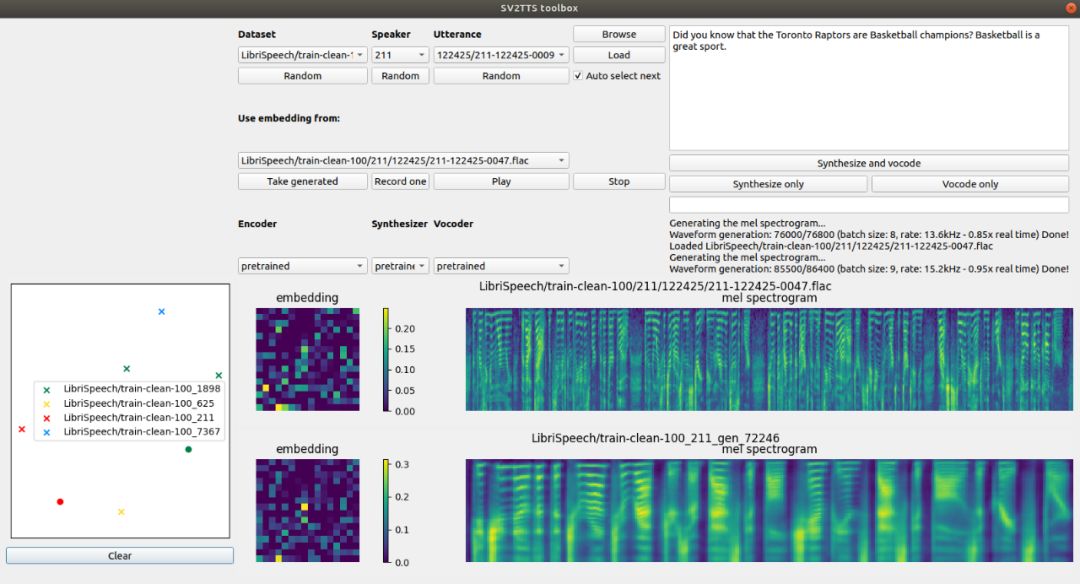
●编号888,输入编号直达本文
●输入m获取文章目录

开源最前线
登录查看更多
相关内容

语音合成(Speech Synthesis),也称为文语转换(Text-to-Speech, TTS,它是将任意的输入文本转换成自然流畅的语音输出。语音合成涉及到人工智能、心理学、声学、语言学、数字信号处理、计算机科学等多个学科技术,是信息处理领域中的一项前沿技术。
随着计算机技术的不断提高,语音合成技术从早期的共振峰合成,逐步发展为波形拼接合成和统计参数语音合成,再发展到混合语音合成;合成语音的质量、自然度已经得到明显提高,基本能满足一些特定场合的应用需求。目前,语音合成技术在银行、医院等的信息播报系统、汽车导航系统、自动应答呼叫中心等都有广泛应用,取得了巨大的经济效益。
另外,随着智能手机、MP3、PDA 等与我们生活密切相关的媒介的大量涌现,语音合成的应用也在逐渐向娱乐、语音教学、康复治疗等领域深入。可以说语音合成正在影响着人们生活的方方面面。




相关VIP内容
相关资讯
相关论文