面试官:你说对 MySQL 事务很熟?那我问你 10 个问题



什么是事务?

BEGIN 或
START
TRANSACTION 显式地开启一个事务;
COMMIT /
COMMIT
WORK二者是等价的。提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK /
ROLLBACK
WORK。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier 在事务中创建一个保存点,一个事务中可以有多个
SAVEPOINT;
RELEASE
SAVEPOINT identifier 删除一个事务的保存点;
ROLLBACK
TO identifier 把事务回滚到标记点;
SET
TRANSACTION 用来设置事务的隔离级别。
InnoDB 存储引擎提供事务的隔离级别有
READ UNCOMMITTED、
READ COMMITTED、REPEATABLE
READ 和
SERIALIZABLE

招商银行(CMBC):“存么?白痴!”
中国工商银行(ICBC): “爱存不存!”
中国建设银行(CCB): “存?存不?”
中国银行(BC): “不存!”
中国农业银行(ABC): “啊,不存!”
民生银行(CMSB):“存么?SB!"
兴业银行(CIB):“存一百。”
国家开发银行(CDB):“存点吧!”
汇丰银行(HSBC):“还是不存!”
这个转账的操作可以简化抽成一个事务,包含如下步骤:
查询CMBC账户的余额是否大于100万
从CMBC账户余额中减去100万
在ICBC账户余额中增加100万
START
TRANSACTION;
SELECT balance
FROM CMBC
WHERE username=
'lemon';
UPDATE CMBC
SET balance = balance -
1000000.00
WHERE username =
'lemon';
UPDATE ICBC
SET balance = balance +
1000000.00
WHERE username =
'lemon';
COMMIT;

事务的ACID特性是什么?
原子性(atomicity)
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作。致性(consistency)
数据库总是从一个一致性的状态转换到另外一个一致性的状态。在前面的例子中,一致性确保了,即使在执行第三、四条语句之间时系统崩溃,CMBC账户中也不会损失100万,不然lemon要哭死,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。隔离性(isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时如果有其他人准备给lemon的CMBC账户存钱,那他看到的CMBC账户里还是有100万的。持久性(durability)
一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失。持久性是个有点模糊的概念,因为实际上持久性也分很多不同的级别。有些持久性策略能够提供非常强的安全保障,而有些则未必。而且「不可能有能做到100%的持久性保证的策略」否则还需要备份做什么。

什么是脏读、不可重复读、幻读
脏读

不可重复读

幻读

不可重复读与幻读有什么区别?
不可重复读的重点是修改:在同一事务中,同样的条件,第一次读的数据和第二次读的「数据不一样」。(因为中间有其他事务提交了修改)
幻读的重点在于新增或者删除:在同一事务中,同样的条件,第一次和第二次读出来的「记录数不一样」。(因为中间有其他事务提交了插入/删除)
四个隔离级别知道吗?解决了什么问题

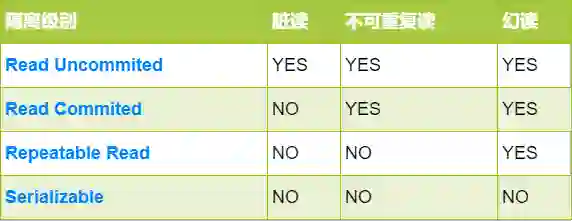
隔离级别对比
MySQL中哪些存储引擎支持事务?

什么是自动提交?
在事务中可以混合使用存储引擎吗?

show
table
status
from
'your_db_name'
where
name=
'your_table_name';
查询结果表中的`Engine`字段指示存储引擎类型。
InnoDB存储引擎的特点和应用场景?
历史
特点
MyISAM存储引擎的特点和应用场景?
特性
InnoDB与MyISAM对比

其他存储引擎

引擎列表


☞154 万 AI 开发者用数据告诉你,中国 AI 如何才能弯道超车?| 中国 AI 应用开发者报告
☞任何性能指标越界或造成 APP 崩溃,优酷通用性能测试一招搞定
☞一文教你如何使用 MongoDB 和 HATEOAS 创建 REST Web 服务