AI 向善:实时手语检测推动视频会议无障碍化

视频会议应让所有人都无障碍使用,其中包括使用手语的用户。然而,由于大多数视频会议应用的窗口会自动聚焦于大声讲话的参会人员,使得手语人士很难得到“发言”机会,因此也就无法轻松有效地进行交流。同时,由于应用需要使用大量动态视频作为输入来进行分类,计算量非常大,因此在视频会议中实时检测手语并非易事。在某种程度上,正是由于这些挑战的存在,关于手语检测的研究寥寥无几。
在“Real-Time Sign Language Detection using Human Pose Estimation”(在 SLRTP2020 上展示并在 ECCV2020 上演示)中,我们展示了一种实时手语检测模型,并演示了其在视频会议系统中如何将手语交流者识别为当前发言人。
Real-Time Sign Language Detection using Human Pose Estimation
https://research.google/pubs/pub49425/
以色列手语翻译 Maayan Gazuli 正在演示手语检测系统
模型介绍
针对各种视频会议应用提供实时的有效解决方案,我们需要设计一个“即插即用”的轻量级模型。之前我们曾尝试在客户端上集成视频会议应用模型,结果无一例外都证明了轻量级模型的重要性:使用的 CPU 时间更少,可最大限度降低对通话质量的影响。为了减少输入维度,我们从视频中分离了模型所需的信息,以便对每个帧进行分类。
由于手语涉及到用户的身体和手部,因此我们首先运行姿势预测模型 PoseNet。如此一来,只需输入用户的一小部分身体关键特征点(包括眼睛、鼻子、肩膀、手等)即可,无需输入整个高清图像。我们通过这些关键特征点来计算帧到帧的光流 (Optical Flow),从而将模型要使用的用户动作量化,而不保留用户特定的信息。按照人的肩膀宽度将每个姿势都进行归一化,以确保模型能够捕捉到与相机特定距离范围内使用手语的人士。然后,按照视频的帧速率对光流进行归一化,再传递给模型。
PoseNet
https://github.com/tensorflow/tfjs-models/tree/master/posenet
为了测试这种方法,我们使用了德语手语语料库 (DGS),该语料库包含人们使用手语交流的长视频,并包含指示手语发生在哪个帧中的区域注释。作为一个简单的基线,我们使用光流数据训练了线性回归模型用于预测人们何时使用手语。此基线的准确率达到 80%,且每帧仅需要约 3 微秒(0.000003 秒)的处理时间。将前 50 个帧的光流作为该线性模型的上下文输入,其准确率甚至可以达到 83.4%。
德语手语语料库
https://www.aclweb.org/anthology/2020.signlang-1.12/
为了泛化上下文的使用,我们使用了一个长短期记忆 (LSTM) 架构,该架构包含之前时间步的记忆,但不可回溯。通过使用单层 LSTM,再加上线性层,该模型可实现高达 91.5% 的准确率,每帧处理时间为 3.5 毫秒(0.0035 秒)。

分类模型架构:(1) 从每一帧中提取姿势;(2) 根据每两个连续帧计算光流;(3) 通过 LSTM 馈送;以及 (4) 进行分类
概念验证
在得到有效的手语检测模型后,我们需要使用模型设计一种方式来触发视频会议应用中的当前发言人功能。我们开发了一个轻量级的实时手语检测网络演示,它可以连接到各种视频会议应用,并可以将手语交流者设置为“发言人”。此演示通过使用 tf.js 在浏览器中运行的 PoseNet 快速人体姿势预测和手语检测模型,保证了模型使运行的实时性和可靠性。
tf.js
https://www.tensorflow.org/js
当手语检测模型确定用户正在进行手语交流时,它会传递超声波提示音,任何视频会议应用都可以检测到这种提示音,就像手语交流者正在“讲话”一样。提示音以 20kHz 传输,在人类的听觉范围之外。由于视频会议应用通常以音频的“音量”作为检测是否有人正在讲话的标准(而非单纯检测语音),因此应用会误以为手语交流者正在讲话。
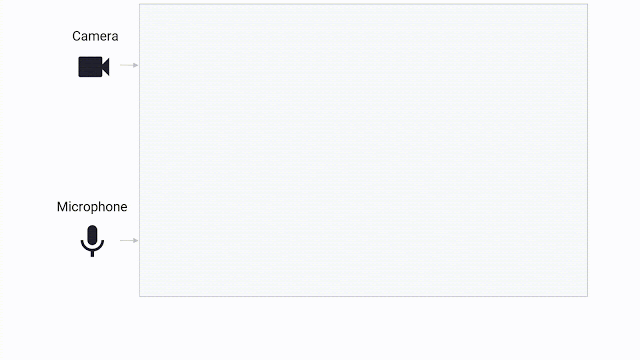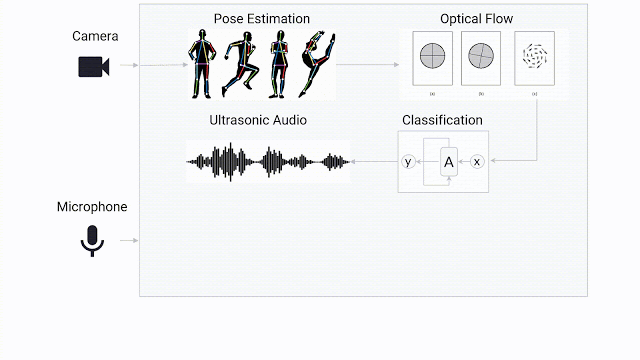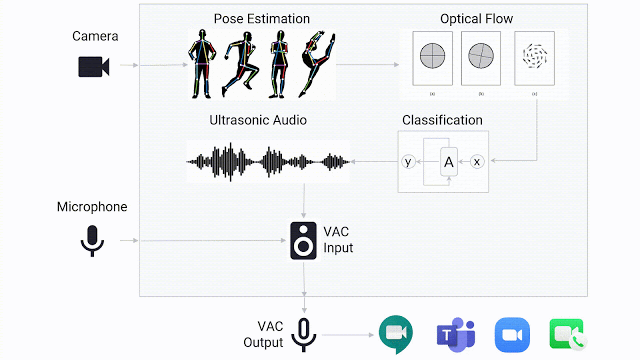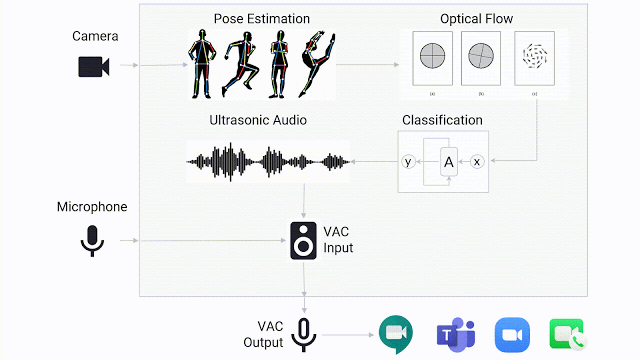
手语检测演示将摄像头的视频动态作为输入,并在检测到用户进行手语交流时通过虚拟麦克风传输音频
欢迎立即试用我们的实验性演示!默认情况下,它可充当手语检测器。我们已在 GitHub 上提供了训练代码和模型以及网络演示源代码。
实验性演示
http://sign-language-detector.web.app/训练代码和模型
https://github.com/google-research/google-research/tree/master/sign_language_detection网络演示
https://github.com/AmitMY/sign-language-detector
演示
在下面的视频中,我们演示了该模型的使用方法。请注意,左上角的黄色图表表示模型确定检测到的活动确实是手语的可信值。当用户使用手语时,图表值将增加到接近 100;而当用户停止使用手语时,图表值将降至 0。此过程以每秒 30 帧的速度实时发生,这也是所用摄像头的最大帧速率。
以色列手语翻译 Maayan Gazuli 正在展示手语检测演示
用户反馈
为了深入了解该演示在实践中的使用效果,我们进行了一项用户体验研究,让参与者在视频会议中使用我们的实验性演示,并像往常一样通过手语进行交流。我们还要求参与者互相使用手语,以及对发言的参与者使用手语作为回应,以检测发言人切换功能。据参与者反馈称,演示模型能够检测到手语并将其视为有声语音,并且成功识别了使用手语交流的与会者,触发了会议系统的音频仪表图标,将画面聚焦到了使用手语交流的与会者。
结论
我们认为视频会议应用应让所有人无障碍使用,希望这项研究能够“抛砖引玉”,为后续研究提供一些思路。经实践证明,我们的模型能让手语交流者在视频会议中更便捷地进行交流。
致谢
感谢 Amit Moryossef、Ioannis Tsochantaridis、Roee Aharoni、Sarah Ebling、Annette Rios、Srini Narayanan、George Sung、Jonathan Baccash、Aidan Bryant、Pavithra Ramasamy 和 Maayan Gazuli。
更多 AI 相关阅读:





