BERT的成功是否依赖于虚假相关的统计线索?

本文介绍论文 Probing Neural Network Comprehension of Natural Language Arguments,讨论 BERT 在 ACRT 任务下的成绩是否依赖虚假的统计线索,同时分享一些个人对目前机器学习尤其是自然语言理解的看法。


论文解读
Abstract
BERT 在 Argument Reasoning Comprehension Task (ARCT) 任务上的准确率是 77%,这比没受过训练的人只低 3 个百分点,这是让人惊讶的好成绩。但是我们(论文作者)发现这么好的成绩的原因是 BERT 模型学习到了一些虚假相关的统计线索。我们分析了这些统计线索,发现很多其它的模型也是利用了这些线索。所以我们提出了一种方法来通过已有数据构造等价的对抗(adversarial)数据,在对抗数据下,BERT 模型的效果基本等价于随机的分类器(瞎猜)。
Introduction
论辩挖掘(argumentation mining)任务是找到自然语言论辩的结构(argumentative structure)。根据标注的结果分析,即使是人类来说也是一个很难的问题。
这个问题的一种解决方法是关注 warrant——支持推理的世界知识。考虑一个简单的论证(argument):(1) 因为现在在下雨;(2)所以需要打伞。而能够支持(1)到(2)推理的 warrant 是:(3)淋湿了不好。
Argument Reasoning Comprehension Task, ACRT 是一个关注推理并且期望模型发现隐含的 warrant 的任务。给定一个论证,它包括一个 Claim(论点)和一个 Reason,同时提供一个 Warrant 和一个 Alternative。其中 Warrant 是支持从 Reason 到 Claim 推理的世界知识;而 Alternative 是一个干扰项,它无法支持从 Reason 到 Claim 的推理。用数理逻辑符号来表示就是:
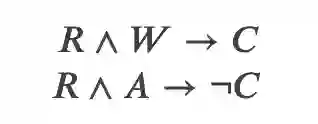
注意:ACRT 数据集提供的 Alternative 一定能推出相反的结论。如果我们找一个随机的 Alternative,它不能推导出 C,但是也不一定能推导出 ¬C。而这个数据集保证两个候选句子中一个是 Warrant(一定能推导出 C),而另一个 Alternative 一定能推导出 ¬C。这个特性在后面的构造 adversarial 数据集会非常有用。
下面是 ACRT 数据集的一个例子:

论点是:Google 不是一个寡头垄断。原因是:人们可以不使用 Google。Warrant 是:其它的搜索引擎不会重定向到 Google。而 Alternative 是:其它的搜索引擎会重定向到 Google。
因为其它搜索引擎不会重定向到 Google,而且人们可以不使用 Google,因此 Google 就不是一个垄断者。
因此这是一个二分类的问题,但是要做出正确的选择除了理解问题之外还需要很多的外部世界知识。在 BERT 之前,大部分模型的准确率都是达不到 60% 的准确率,而使用 BERT 可以达到 77% 的准确率,如下表所示。
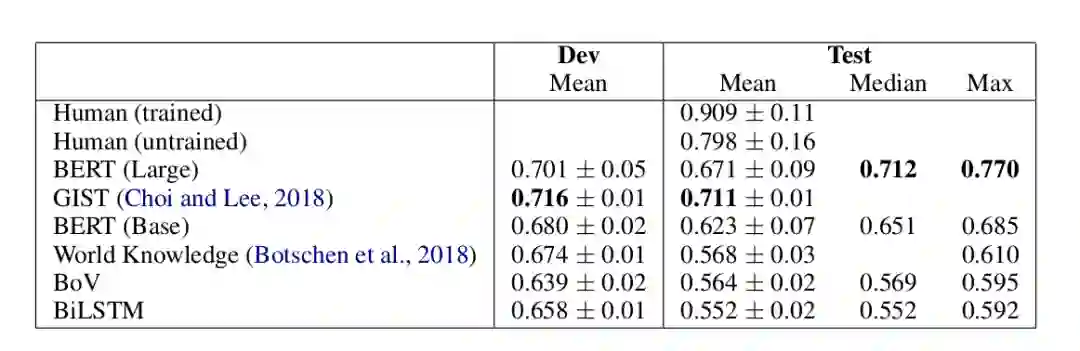
▲ 图:ACRT任务上Baseline和BERT的效果
这比没有训练过的人只低 3 个点,这是非常让人震惊的成绩。因为训练数据里都没有提供这些世界知识,如果 BERT 真的表现这么好,那么唯一的解释就是它通过无监督的 Pretraining 从海量的文本里学到了这些世界知识。
为了研究 BERT 的决策,我们选择了那些多次训练 BERT 都比较容易正确预测的例子来分析。根据 SemEval-2018 Task 12: The Argument Reasoning Comprehension Task,Habernal 等人在 SemEval 的任务上的做了类似的分析,和他们的分析类似(参考后面作者的观点),我们发现 BERT 利用了 warrant 里的某些词的线索,尤其是“not”。通过寻根究底(probing)的设计实验来隔离这些效果(不让数据包含这种词的线索),我们发现 BERT 效果好的原因就是它们利用了这些线索。
我们可以改进 ACRT 数据集,因为这个数据集上很好的特性 R∧A→¬C,因此我们可以把结论反过来(加一个否定),然后 Warrant 和 Alternative 就会互换,这样就可以保证模型无法根据词的分布来猜测哪个是 Warrant 哪个是 Alternative。而通过这种方法得到的对抗(adversarial)数据集,BERT 的准确率只有 53%,比随机瞎猜没有强多少,因此这个改进的数据集是一个更好的测试模型的数据集。
任务描述和Baseline
假设 i=1,…,n 是训练集 D 中每个训练数据的下标,因此 |D|=n。两个候选 Warrant 的下标 j∈{0,1},它的分布是均匀的,因此随机猜测正确的可能性是 50%。输入是 Claim ,Reason
,Warrant0
和 Warrant1
;而输出是
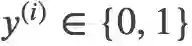
下图是解决这个问题的通用的模型结构,它会独立的考虑每一个 Warrant。
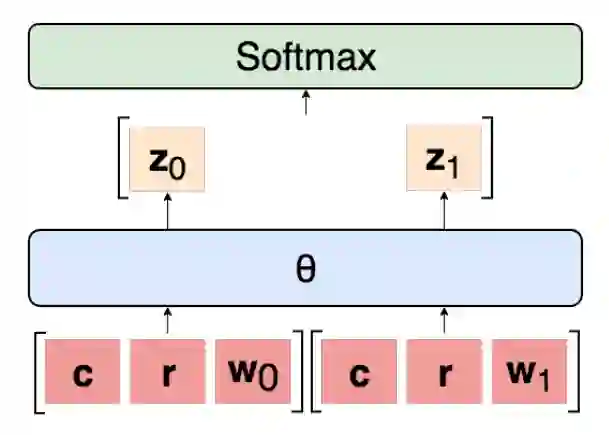
▲ 图:实验的模型结构
因此给定、
和
,模型最终会输出一个 score,表示 Warrant-j 是正确的 Warrant 的可能性(logit),然后使用 softmax 把两个 logits 变成概率。注意这个模型是独立考虑每一个 Warrant 的,每个 Warrant 的打分是和另外一个无关的,如果是相关的,则模型的输入要同时包含
和 Warrant1
。用数学公式描述其计算过程为:
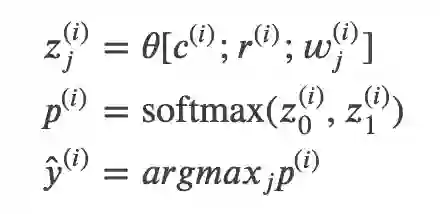
模型 θ 可以有很多种,这里的 Baseline 包括 Bag of Vector (BoV)、双向 LSTM (BiLSTM)、SemEval 的冠军 GIST 和人类。结果如上图所示。对于所有的实验,我们都使用了网格搜索(grid search)的方法来选择超参数,同时我们使用了 dropout 和 Adam 优化算法。
当在验证集上的准确率下降的话我们会把 learning rate 变为原来的 1/10,最后的模型参数是在验证集上准确率最高的那组参数。BoV 和 BiLSTM 的输入是 300 维的 GloVe 向量(从 640B 个 Token 的数据集上训练得到)。用于复现实验的代码、具体的超参数都放在作者的 GitHub 上:
https://github.com/IKMLab/arct2
BERT
我们的 BERT 模型如下图所示。
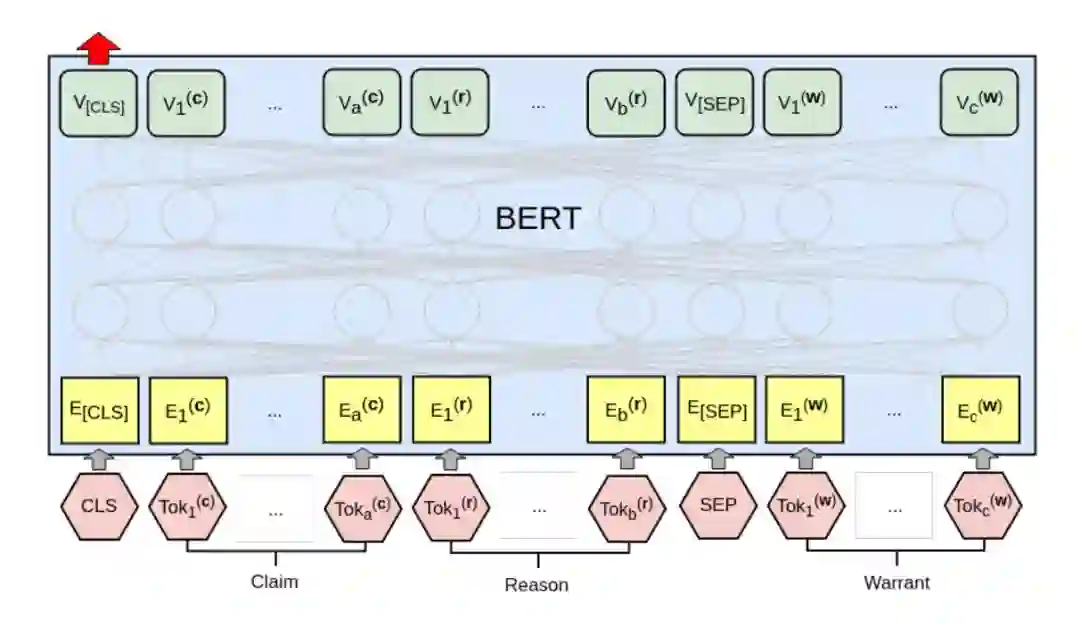
▲ 图:处理argument-warrant对的BERT模型
我们把 Claim 和 Reason 拼接起来作为 BERT 的第一个”句子”(它们之间没有特殊的分隔符,因此只能靠句号之类的线索,这么做的原因是 BERT 最多输入两个句子,我们需要留一个句子给 Warrant),而 Warrant 是第二个”句子”,它们之间用特殊的 SEP 来分割,而最前面是特殊的 CLS。
CLS 本身无语义,因此可以认为它编码了所有输入的语义,然后在它之上接入一个线性的全连接层得到一个 logit 。两个 Warrant 都输入后得到
和
,最后用 softmax 变成概率。不熟悉 BERT 的读者可以参考 BERT 课程 [1]、BERT 模型详解 [2] 和 BERT 代码阅读 [3]。
整个模型(包括 BERT 和 CLS 上的线性层都会参与 Fine-tuning),learning rate 是,最大的 Epoch 数是 20,选择在验证集上效果最好的那组参数。我们使用的是 Hugging Face 的 PyTorch 实现 [4]。
Devlin 等人在 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 里指出,对于很小的数据集,BERT 经常会无法收敛,从而得到很差的效果。
ARCT 是一个很小的数据集,它只有 1,210 个训练数据。在 20 次训练中有 5 次出现了这种情况,我们把它去掉后平均的准确率是 71.6±0.04。这已经达到了之前最好的 GIST 的效果,而最好的一次是 77%。我们只分析最好的 77% 的模型。
统计线索
虚假相关的统计线索主要来源于 Warrant 的不均匀的语言(词)分布,从而出现不同标签的不均匀词分布。虽然还有更复杂的线索,这里我们只考虑 unigram 和 bigram。我们会分析如果模型利用这些线索会带来多大的好处,以及这种现象在这个数据集上有多么普遍。
形式化的,假设是第 i 个训练数据的第 j(j=0 或者 1)个 warrant 的所有的 Token 的集合。我们定义一个线索(比如一个 unigram 或者 bigram)的 applicability
为 n 个训练数据中只在一个标签里出现的次数。用数学语言描述就是:
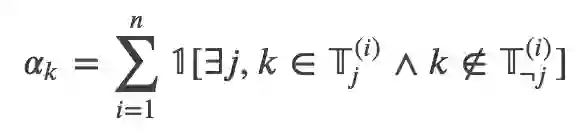
用自然语言处理再来描述一下就是:如果某个线索(unigarm/词或者 bigram)只在某个 warrant 里出现了,就加一。如果某个线索在两个warrant里都出现或者都不出现,则模型无法利用这个线索。最极端的,比如某个词只出现在 warrant0 里,那么模型可能就会学到错误的特征——一旦看到这个词出现就倾向于把它分到 warrant0。
注意:这个特征不见得就是错误的特征,比如情感分类任务里某个词或者某个词组(bigram)出现了确实就容易是正面或者负面的情感。但是对于 ACRT 这样的任务来说,我们一般认为(其实可能也可以 argue)这样的特征是不稳定的,只有其背后的世界知识才是推理的真正原因,所以某些词(尤其是 not 这样的否定词)的出现与否与这个世界知识是无关的(我们可以用否定或者肯定来表示同样的语义:我很忧伤和我不高兴是一个语义,是肯定还是否定的表示方法与最终的结论无关)。
此外我们定义 productivity 为:
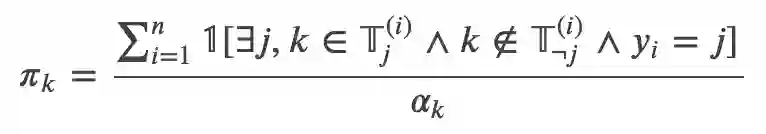
分母是,分子是
里的并且模型分类和线索是同时出现的数量。比如”not”在 n 个训练数据里单独出现了 5 次,有 3 次只出现在 warrant0,有 2 次只出现在 warrant1。
如果”not”只出现在 warrant0 的 3 次里有 2 次模型预测正确(预测为 0),”not”只出现在 warrant1 的 2 次里有 1 次预测正确(预测为 1),则分子就是 2+1=3,分母就是 5,则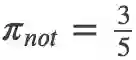
最后我们定义 coverage 
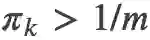
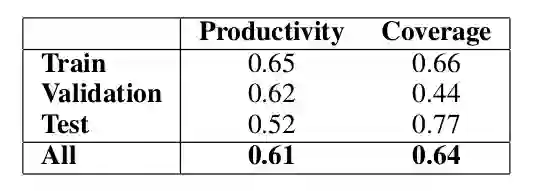
▲ 图:”not”的productivity和coverage
它的意思就是平均来说,64% 的数据都有”not”出现,如果只利用这个线索能够得到准确率为 61% 的分类结果。那么我们可以这么来得到一个分类器:如果”not”出现,我们就分类为 0(假设训练数据中”not”出现更容易分类为 0);如果”not”不出现,我们就随机分类。那么这个分类器的准确率是多少呢?64%*61%+(1-64%)*50%=0.57。
根据前面的描述,大部分分类器的准确率都没有超过 0.6,而使用这样的特征就可以做到 0.57。如果还有和”not”类似的特征,而且它们不完全相关(有一定的额外信息),那么再加上其它的这类词特征可以进一步提高预测的准确率(前提是假设测试数据的词分布也是和训练数据一样的)。
Probing实验
如果某个模型能只利用了 Warrant 的词的线索,那么我们只把 warrant 作为输入也应该会得到类似的准确率。当然这不是”真正”的解决了这个问题,因为你连 claim(论点)和 reason 都没有看到,只看到 warrant 里出现了 not 就分类为 0,这显然是不对的。
举个前面的例子,我们的分类器会把”Other search engines don’t redirect to Google”分类为 0,这显然是正确的,但是它分类的理由是:因为这个 warrant 包含了”not”。这显然是不对的。
类似的我们也可以只把 warrant 和 claim、warrant 和 reason 作为输入来训练模型,这样的模型学到的特征也肯定是不对的。但是实验的结果如下:
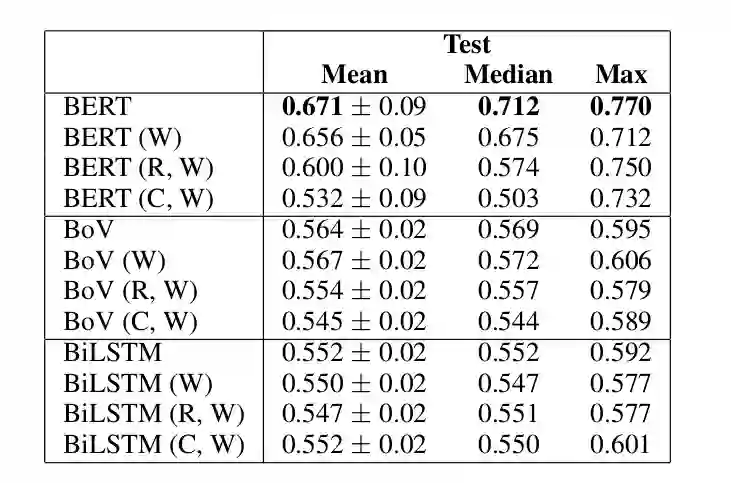
▲ 图:BERT Large、BoV和BiLSTM模型的probing实验
我们看到在 BERT Large 模型里只用 Warrant 作为输入就可以得到 71% 的准确率,这和之前最好的 GIST 模型差不多,而把 Warrant 和 Reason 作为输入可以得到最高 75% 的准确率。因此 ACRT 数据集是有问题的,我们的输入不完整就可以得到 75% 的准确率,这就好比老师的题目还没写完,你就把答案写出来了,这只能说明你作弊或者是瞎猜的。
对抗测试数据
ACRT 数据集的词的统计不均匀问题可以使用下面的技巧来解决。因为 R∧A→¬C,我们可以把 claim 变成它的否命题,这样 Warrant 和 Alternative 就会互换,这样就能保证通用一个句子既是 Warrant0 也是 Warrant1,从而在所有的 Warrant 里词的部分完全是均匀的。下图是一个示例。

▲ 图:一个原始的训练数据以及有它生成的对抗数据
这个对抗例子为:我们可以使用其它的搜索引擎,但是其它搜索引擎最终会重定向到 Google,所以 Google 是一个垄断者。也就是把 Claim 加一个否定(双重否定就是肯定,就可以去掉 not),原来的 Alternative 就变成的新的 Warrant。这样”All other search engines redirect to Google”在 Warrant0 和 Alternative 都出现一次,从而词的分布是均匀的。
对于这种方法生成的对抗训练数据,我们做了两个实验。第一个实验使用原始的(没有加入对抗样本)训练数据和验证数据训练模型,然后在对抗数据集上测试,其结果比随机猜(50%)还差,因为它过拟合了某些根本不对的特征,测试数据根本不是这样的分布。第二个使用是使用对抗数据进行训练和测试,则 BERT 最好的效果只有 53%。
补充一点
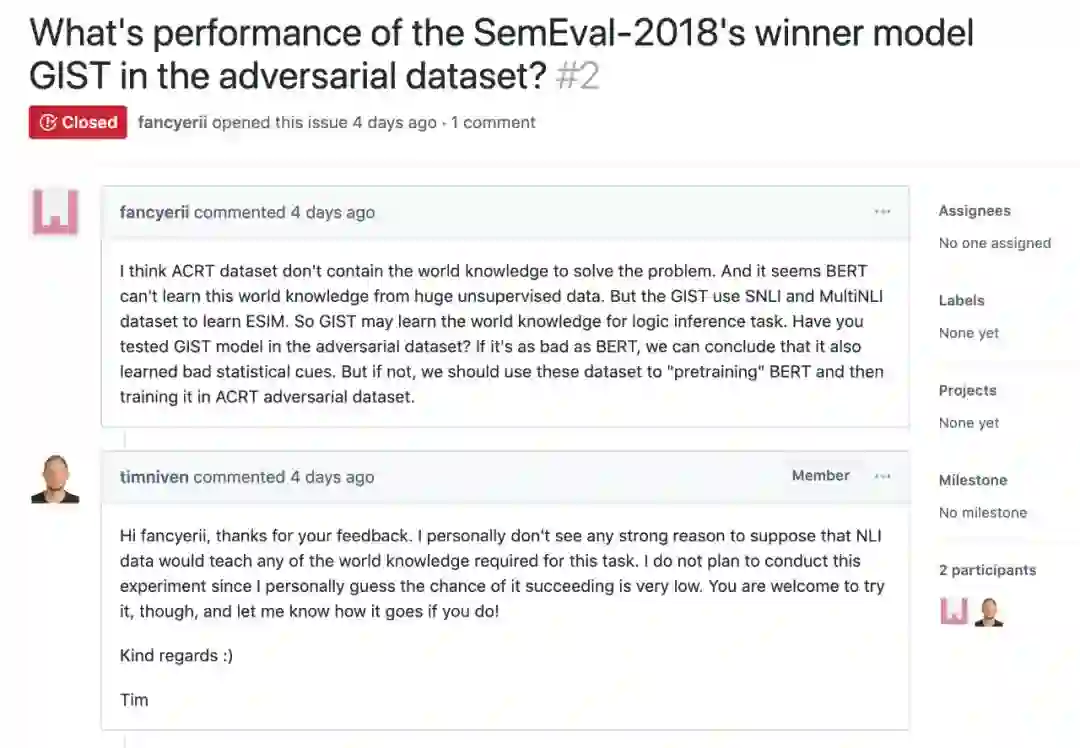
我个人觉得这篇文章还有一点小缺陷,那就是没有使用 ACRT 排名第一的模型 GIST 跑一下对抗数据集。因为 GIST 会使用 SNLI 等 NLI 任务的数据进行预训练,也许从这里可以学到一些世界知识用于解决 ACRT 的推理问题。
我在这里提了这个问题,不过作者认为 NLI 的数据并不包含解决 ACRT 问题的世界知识,因此没有必要做这个实验(也许更主要的问题是不想重新实现一遍 GIST 模型?这也许说明了论文开源代码的价值,别的研究者可以很容易的 check 和利用其工作)。
相关讨论
这里收集了一些来自 Reddit 的帖子 BERT’s success in some benchmarks tests may be simply due to the exploitation of spurious statistical cues in the dataset. Without them it is no better then random. 讨论里的一些观点。
下面的内容都是我摘录和翻译(意译)的部分观点。
观点1(贴主orenmatar)
首先我们来看 Reddit 帖子的标题:BERT 在某些 benchmark 上的成功是因为简单的利用了不相关的统计线索。如果不(能)利用这些线索,它的效果就是随机的瞎猜。这个观点相对比较客观,只是描述了一个事实。
观点2(neato5000)
赞成贴主的观点,并且提到 Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference 里有类似的结论。
观点3(lysecret)
同意贴主的观点,但是认为 BERT 模型依然很有用,在 3 个个人项目中比其它模型好很多。贴主 orenmatar 同意 BERT,他说自己发帖并没有否定 BERT 的价值,但是强调只是在 ACRT 这个特定集合上 BERT 学到的只是不相关的统计线索。
观点4(贴主orenmatar)
这种论文应该更多一些。我们每天都听到 NLP 的各种突破,每过几个月就出现更好大模型,得到超乎想象的结果。但是很少有人实际的想办法分析这些模型是否只是因为学习到一些无意义的特征。因此我们有必要往后一步,仔细看看数据集和分析一下模型到底学到了什么东西。
针对观点 4,melesigenes 认为这个观点对于文章大家结论过于扩大范围了(overgeneralizing)。BERT 在 ACRT 数据集上没有学到什么并不代表在其它的数据集上没有学到有意义的东西。
观点5(dalgacik)
这个观点认为这篇论文并没有说明 BERT 模型有什么问题,只是指出了 ACRT 这个数据集有问题。
观点6(gamerx88)
很多进展其实都是模型过拟合了这个数据集而已,这在很多比赛类的任务都出现过。
观点7(fiddlewin)
我发现很多评论错误的解读了论文?论文只是说模型(包括 BERT 和其它)在某个特定任务(ARCT)上利用了统计线索(比如是否出现”not”)。当引入对抗样本从而去掉这些线索之后,BERT 的性能只有 50%,和没有训练的人的 80% 相比差别很大,说明这个任务很难需要很深层次的语义理解。
但是这篇论文从来没有怀疑 BERT 在其它任务的能力,这也是符合常识的——学习算法解决问题的方法不一定是人(想象)那样的。
观点8(lugiavn)
这篇文章 TLDR (Too long, don’t read) 的描述了一个很简单的事实:不平衡数据上训练的模型在和训练集不同分布的测试集上表现不会太好。这并没有什么稀奇。所有的机器学习模型都是这样。为什么要把 BERT 单独拎出来呢?
delunar 对这个观点持不同态度,他认为这不是不平衡数据的问题。而是因为 BERT 错误的”理解”了文本的意思但是做出了相对程度正确的预测。
作者观点
这篇文章之所以引起大家的关注首先是因为 BERT 模型最近很火,另外一个原因其实就是很多研究者对于现在机器学习(深度学习)社区对于这种刷榜的研究风气的担忧。很多研究者不在模型结构和其它方面做创新,只是使用更大的模型和更多的数据追求在某些公开数据集上刷榜。而这篇文章正是在这样的背景下引起了极大的关注。
其实类似的文章还包括 SemEval-2018 Task 12: The Argument Reasoning Comprehension Task、Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference 和 Is It Worth the Attention? A Comparative Evaluation of Attention Layers for Argument Unit Segmentation。
另外在计算机视觉领域最近也有一篇文章 Natural Adversarial Examples,大家可能认为 ImageNet 已经是一个解决的问题。但是作者找到了很多”自然”(真实)的对抗性的数据,现有的模型在上面的分类准确率非常低,基本都到不了 5%。即使通过一些办法来优化,作者也只能做的 15%。下面是一些示例数据:

▲ 图:ImageNet-A中的自然对抗数据
比如最右边的图,实际分类是牛蛙(bullfrog),但是模型很容易分成黑松鼠(fox squirrel)。当然视觉和语言还是有较大的区别,但是现在的模型确实有可能学到的特征和人类(甚至动物)学到的有很大区别(当然也可以 argue 人或者动物大脑学到的也许是类似的东西)。
我们还是回到语言和 BERT 是否学到不相关的统计线索的问题上来。首先我认为 BERT 是非常用于的一种模型,它最大的优点是可以是无监督的 Pretraining 从海量的数据中学习 Token(词)的上下文语义关系。因此 Fine-tuning 之后能在很多(浅层)的语言理解任务上去掉了很好的效果。但是 BERT 不是万能的,论文里也提到训练数据很少的情况下它可能不能训练。
我们在工作中也发现了一个很有趣的意图分类的例子——有一个客户的数据量很少,大概 1000+ 训练数据作用,而意图数(分类数)是 100+。我们发现使用简单的 Logistic Regression 或者 CNN 都能达到非常好的效果——在测试集合上能有 99%,但是使用 BERT 怎么调参也只有不到 80%。
后来我们分析数据发现这个客户的意图定义的很特别——只有包含某个词就作为一个意图(分类),它并不需要特殊的泛化和上下文。因此我们猜测可能的原因是因为 BERT 的参数过多,而且同样一个词在不同的上下文可能会被编码成不同的向量,因此在训练数据不够的情况下反而没有学到这个任务最简单和重要的特征——只要有这个词就分为这个类别。
其次我认为就是现在的 NLP 模型(不管是 BERT 还是其它的模型)它没有办法获得(足够多的)常识(世界知识)。虽然海量的文本里包含了大量的世界知识(其实我觉得很多世界知识是不能在 Wiki 这样的地方找到的,比如前面的例子:下雨为什么要打伞,因为淋湿了不好。淋湿的感觉不舒服,那这个不舒服能用精确的语言描述吗?也许可以,也许在文学作品里有描述,但是很难用数学语言描述,很多要靠类比,但是淋过雨的人都有类似的感受),但是现在的模型(包括 BERT)都很难学习到这些知识。
因为它看到的只是这些世界知识通过语法编码后的文字,通过分析文字的共现之类的方法可能发现一些浅层的语法和语义,但是很难学到更深层次的语义和逻辑。至少我们人类的学习不是这样的——给你 100TB 的火星文,然后遮住某个词让你猜测可能是哪个词。
语言只不过是人类定义的用于沟通的符号系统,它背后的根源还是我们生存的这个宇宙以及我们通过视觉、听觉等感觉器官对这个世界的感觉。当然除了当下的感觉之外也包括很久以前的感觉甚至是我们出生前通过文化传承下来的先人们的感觉。如果抛开我们的身体和感觉器官,只是从符号的角度来研究自然语言,我觉得是不能根本解决这个问题的。
当然这并不是说 BERT 这样的模型不重要,我们在还没有更好的方法的时候这些模型可以帮助我们解决一些问题,但是千万不能以为它们能解决所有问题。更多关于语言以及人工智能哲学的问题讨论,感兴趣的读者可以参考《人工智能能否实现?》[5]。
相关链接
[1] https://fancyerii.github.io/2019/03/05/bert-prerequisites/
[2] https://fancyerii.github.io/2019/03/09/bert-theory/
[3] https://fancyerii.github.io/2019/03/09/bert-codes/
[4] https://github.com/huggingface/pytorch-transformers
[5] https://fancyerii.github.io/2019/03/14/philosophy/

点击以下标题查看更多往期内容:

深度学习理论与实战:基础篇

李理 / 编著
本书不仅包含人工智能、机器学习及深度学习的基础知识,如卷积神经网络、循环神经网络、生成对抗网络等,而且也囊括了学会使用 TensorFlow、PyTorch 和 Keras 这三个主流的深度学习框架的*小知识量;不仅有针对相关理论的深入解释,而且也有实用的技巧,包括常见的优化技巧、使用多 GPU 训练、调试程序及将模型上线到生产系统中。
本书希望同时兼顾理论和实战,使读者既能深入理解理论知识,又能把理论知识用于实战,因此本书每介绍完一个模型都会介绍其实现,读者阅读完一个模型的介绍之后就可以运行、阅读和修改相关代码,从而可以更加深刻地理解理论知识。

长按识别二维码查看详情
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问作者博客


