数据产品经理和一般产品经理有什么区别?
很多朋友咨询我,数据产品经理和一般的产品经理有什么不同?想了很久,没想到一个好的回答。后来看书翻到过一个案例,通过这个案例,来说明一下,数据产品经理和一般产品经理的最大区别是什么?
我们先看这几个图,这是我今天在墨迹天气APP里,那个生活指数那块儿,点进去之后的截图:
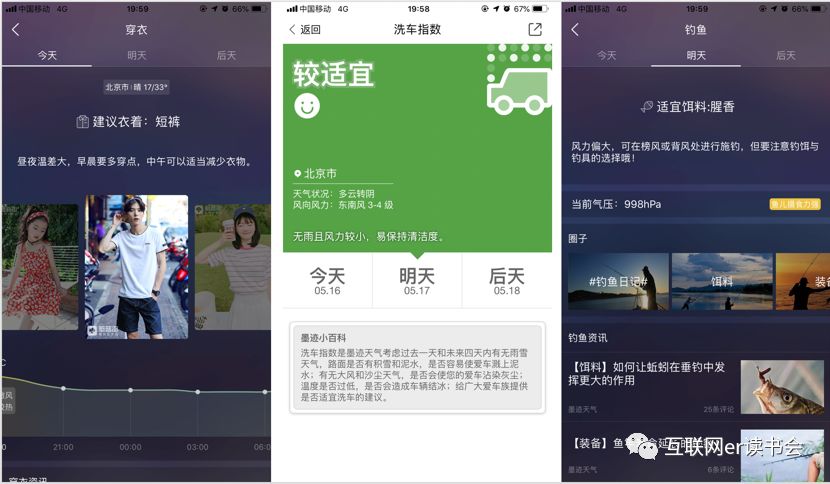
你知道,这几个指数,为什么只有今天、明天和后天三天吗?
你应该不会想到下面这个吧~

这也不是今天明天和后天,这是昨天今天和明天。
在回答这个“为什么只有今天、明天和后天三天吗?”问题之前,我们继续看另外一个指数:
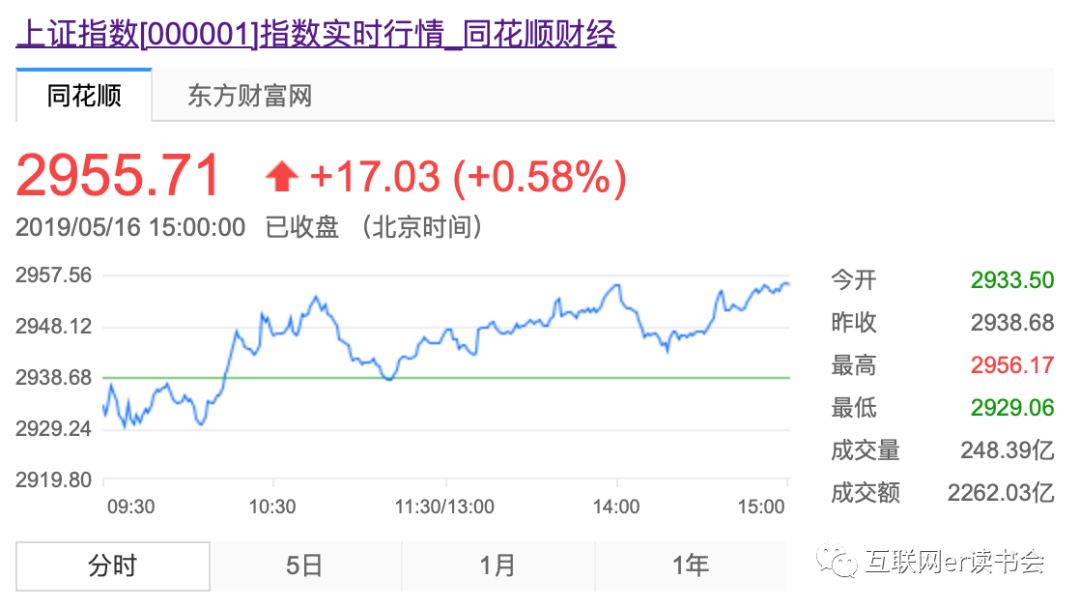
呀,今天还涨了。要不是为了写文章,可能还不知道今天涨了。
跑题了……
说正事儿,上证指数是什么意思?又是怎么算出来的呢?
随手百度一下,百度会告诉我们,上证指数和它的计算公式,这里就不写了。估计咱们也没啥耐心看完。
我给你讲一个案例,来告诉你,为什么上面那三种图,只有三天?
也用这个案例,告诉你,数据产品经理和一般的产品经理有什么不同。
一、洗车指数
就用这个案例里面最中间这个:洗车指数,来回答一下。不知道你有没有注意到,洗车指数,这个图,里面有一个解释。
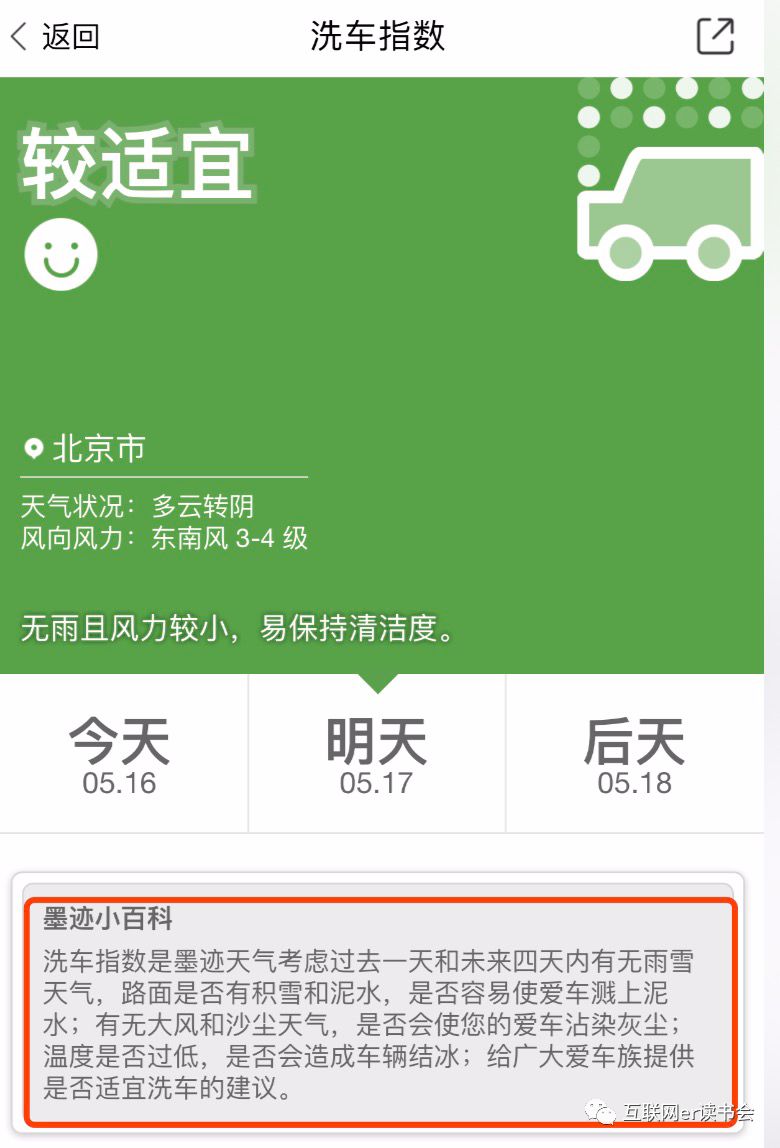
上面红色框起来的部分,墨迹有解释的。这个指数啥意思呢?洗车指数是墨迹天气考虑过去一天和未来四天有无雨雪天气,路面是否有积雪和泥水,是否容易使爱车溅上泥水;有无大风和沙尘天气,是否会使您的爱车沾染灰尘;温度是否过低,是否会造成车辆结冰;给广大爱车族提供是否适宜洗车的建议。
(三年前,这段话不长这样。。)
不知道,你有没有去数,洗车指数,这段描述里面,涉及了几个参考数据?
然后,下面这一段红色的字,APP没给解释。不过,如果你打开墨迹天气,看一看,你能猜得到。
洗车指数共分为4级:1级为适宜,2级为较适宜,3级为较不适宜,4级为不适宜。级数越高,就越不适宜洗车。
二、洗车指数出现的背景
先介绍一下这个指数出现的背景:
2016年4月,国内著名的天气预报APP墨迹天气正式上线了墨迹洗车生活服务功能,这是基于墨迹天气自身的气象能力衍生而来的服务。墨迹洗车提出了“洗车3日内下雨,墨迹天气全额赔”的承诺,这有别于以往的O2O洗车服务。
(没想到吧,这个指数上线,当时是要和O2O洗车做竞争,但其实,O2O洗车,上门洗车,用户有需求,但企业成本太高,根本玩不转。价格一高,用户就不来了。自然都死了。)
墨迹洗车实时播报洗车指数,用户进入洗车界面后可以随时查看天气情况,并根据天气变化合理地安排洗车时间,从而帮助用户有效避免遭遇“一洗车就下雨”的尴尬。
不仅如此,墨迹洗车还为用户提供了洗车后的保障,这种保障不同于保险公司的普通理赔。
例如,墨迹洗车提示“适宜洗车”,用户在洗车3日内(含洗车当日)如果遭遇下雨(雪)天气,则墨迹天气将全额赔付用户当次洗车费用,这就类似于一种基于气象数据的保险服务。
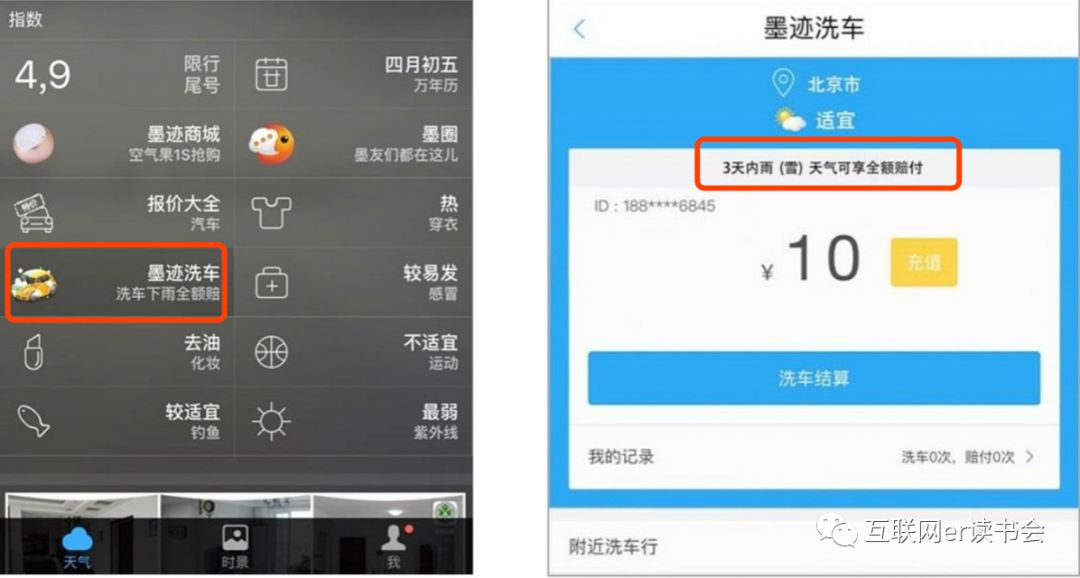
这个指数背后,其实带着企业的商业需求,成本如此之高的一项O2O服务,这个洗车指数又是怎么定义来的?
让我们回到2016年,作为一个数据产品经理,你领导给你下了一个任务,我们最近要上线一款O2O洗车产品,运营模式是上面描述的那样子的。你作为数据产品经理,要去设计一个洗车指数,2016年的你,该怎么办?
其实,作为一个专业的数据产品经理,你已经想到了一个办法了。
三、洗车指数建立方法
1.建立洗车指数等级
一般将洗车指数的等级V设为4个等级:V1~V4,如图所示,其中V1表示适宜洗车,指的是从洗车当日开始计算,可以保证连续3天以上不下雨;V2表示较适宜洗车,指的是可以保证2~3天不下雨;V3表示比较不适宜洗车,只能保证两天不下雨;V4表示不适宜洗车,预估1天内就会下雨。
洗车指数等级

2.建立影响洗车指数的因素集
因素集就是那些与洗车等级有较大关系的一些因素的集合。
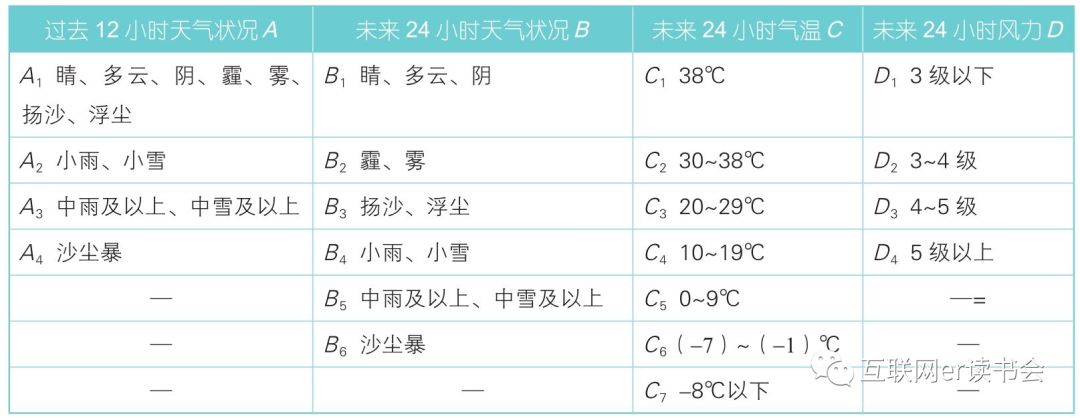
通过人为经验得出了以下4个变量会与洗车指数有强相关性:过去12小时天气状况A、未来24小时天气状况B、未来24小时气温C和未来24小时风力D。其中,过去12小时及未来24小时天气现象分类标准如图所示,其中每一列代表不同的影响因素的分类等级,未来24小时天气现象的分类比未来12小时天气现象分类更细一些。
洗车指数影响因素分类标准
3.确定各影响因素的权重
根据历史经验数据和相关分析,得出各影响因素变量与洗车指数的相关性,图中的值就是每天记录的4个变量和洗车指数的历史数据,通过相关分析计算得出的相关系数矩阵。其中行和列的名称是一样的,自身与自身的相关系数即为1,因此矩阵的对角线上的相关系数都为1。
洗车指数与影响因素变量的相关系数矩阵
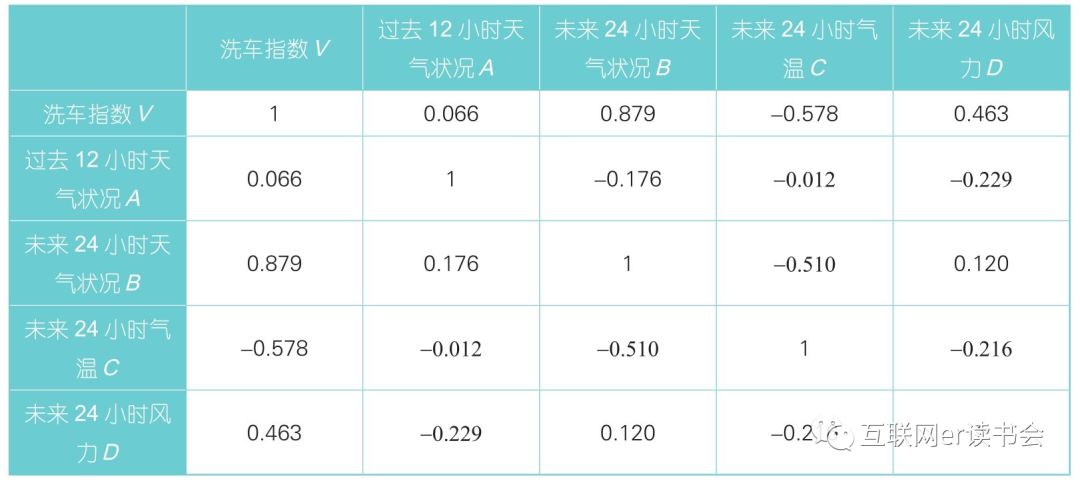
根据图中可以看出,未来24小时天气状况B与洗车指数V的相关性最强,即R=0.879;未来24小时风力D与洗车指数V的相关系数为R=0.463;未来24小时气温C与洗车指数V的相关系数为R=-0.578,呈负相关,即气温越高越不适宜洗车;过去12小时天气状况A与洗车指数V之间的相关系数为R=0.066,即对洗车指数的影响很小。
权重a不是一个固定数列,不同的天气状况会选择不同的权重,根据上述结果,设定a=(A,B,C,D)权值=(0.1,0.38,0.2,0.32),权值之和等于1。
(需要注意的是,这个a,是人为定义的,用相关性作为参考。)
4.确定各影响因素对等级模糊子集的隶属度
根据各因素与洗车指数的相关性大小,初步人为确定各影响因素对洗车等级模糊子集的隶属度。
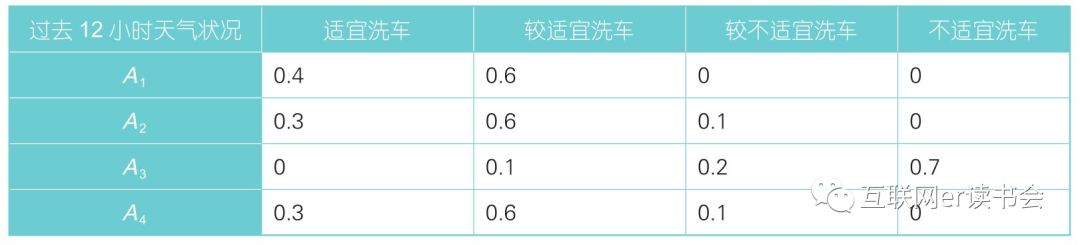
过去12小时天气状况不同级别天气对评判集的隶属度如下图,其中每一行代表在某种天气状况下(如A1)人为经验判定出适宜洗车、较适宜洗车、较不适宜洗车和不适宜洗车这4种洗车等级的权值,每一行的权值加起来等于1。
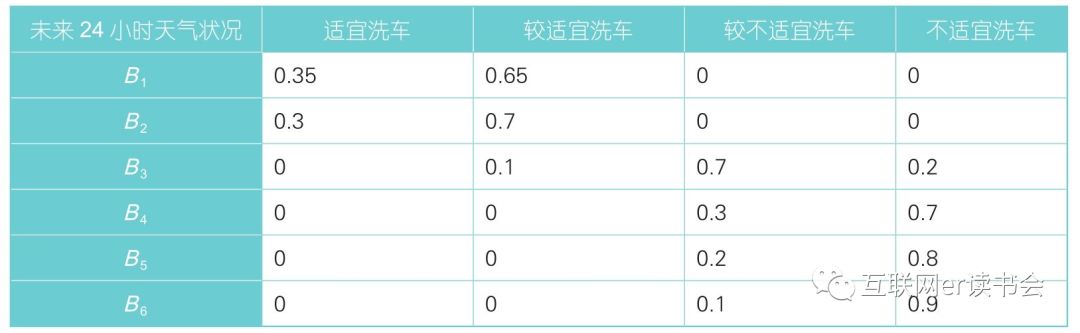
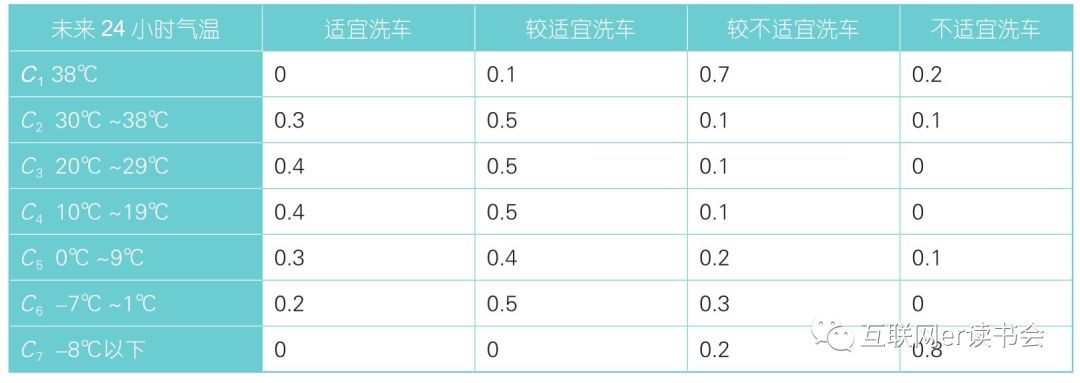
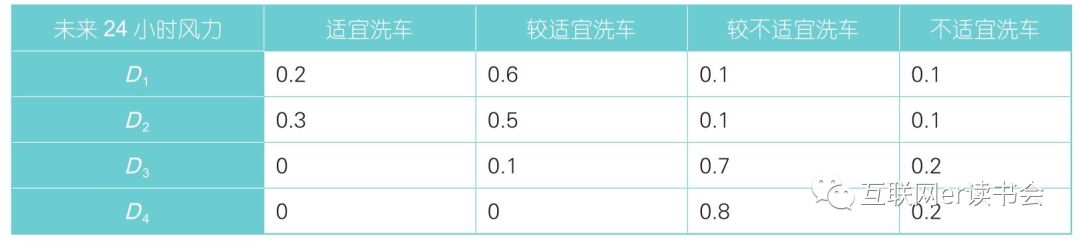
同理,未来24小时天气状况不同级别对评判集的隶属度,未来24小时气温各级别对评判集隶属度,未来24小时风力对评判集隶属度。
过去12小时天气状况隶属度
未来24小时天气状况隶属度
未来24小时气温隶属度
未来24小时风力隶属度
假设:现在需要判断在北京的某一天是否适宜洗车,则首先要了解当天的天气状况。具体天气情况如图所示,当天天气组合为(A2,B1,C3,D1),根据上面四个图表中的数据,天气组合中各影响因素对应哪一个级别,就取哪一行数据,因此得到矩阵R如下:
北京洗车当天的天气状况
5.计算综合评判
在之前的步骤里,已经求出了a与R,计算综合评判B=a*R,具体采用先取最小值再取最大值的算法。a*R的具体计算步骤如下。
(1)将a1与R中第一列的第一个数据比较,取最小值;将a2和第一列的第二个数据比较,取最小值;a3和第一列的第三个数据比较,取最小值;将a4和第一列的第四个数据比较,取最小值;获得新的数据集E1=(e11,e12,e13,e14),最后在这4个数据中取最大值,即为e1i。
(2)将a1与第二列的第一个数据比较,取最小值;将a2与第二列的第二个数据比较,取最小值;将a3与第二列的第三个数据比较,取最小值;将a4与第二列的第四个数据比较,取最小值;获得数据集E2=(e21,e22,e23,e24),在这4个数据中取最大值,即为e2i。
(3)以此类推,最后获得一组数据B=(e1i,e2i,e3i,e4i),代表对4个评判等级的隶属度,哪个值最大,就说明对哪个等级隶属度最高。
以北京的天气为例,具体计算步骤如下:
确认各影响因素权重a=(0.1,0.38,0.2,0.32),根据北京天气状况获取矩阵R如下:
计算综合评判B如下:
将a中第一个数字和R中第一列的第一个数字比较,取最小值,即0.1;
将a中第二个数字和R中第一列的第二个数字比较,取最小值,即0.35;
将a中第三个数字和R中第一列的第三个数字比较,取最小值,即0.2;
将a中第四个数字和R中第一列的第四个数字比较,取最小值,即0.2。
在(0.1,0.35,0.2,0.2)数列中取最大值0.35,以此类推得B=(0.35,0.38,0.1,0.1)。因为这4个数加和不为1,因此需要进行归一化,归一化得到B'=(37.6%,40.9%,10.8%,10.8%)。B'中最大值为40.9%,因此较适宜洗车,洗车级别为2级。
在上述的模糊综合评判过程中,建立单因素评判矩阵R和确定权重分配a,是两项关键的工作,没有统一的格式可以遵循,一般采用统计实验或专家评分等方法求出。
有的时候用户不是没有数据,而是有太多的数据,不知道怎么去看,不知道如何解读它们,这个时候需要数据产品经理设计恰当的数据指标以供用户分析。
数据指标的设计最考验一名数据产品经理的能力,也是数据产品经理有别于一般产品经理的方面。
-End-
觉得有启发,点个在看,转给朋友们






