GitOps是皇帝的新衣吗

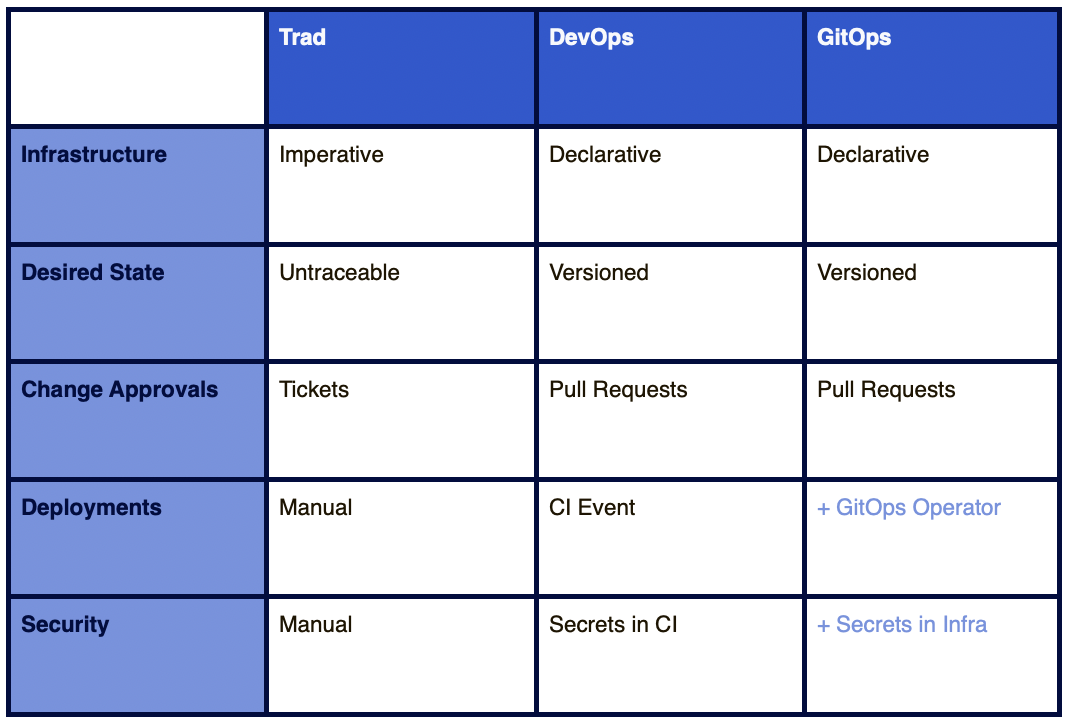
将一切视为代码并存放在 Git 中确实有很多好处,静态定义、实践指南和规范在各个方面都很有用。
然而,这些定义并不能帮助我们理解动态环境,这就是我认为 GitOps 存在的问题。GitOps 声称它提供了更好的安全性、历史记录以及漂移和协调的解决方案,但我疑惑这些是否是真的。在这篇文章中,我将解释为什么我会这么想。GitOps 让我想起了一个关于真实与想象的古老的安徒生童话。皇帝宣称他穿着衣服,但是否有可能他实际上什么都没穿?
在深入探究之前,我们先基于 weveworks 的四个原则为我们所讨论的 GitOps 设置一个基线:
整个系统是以声明的方式进行描述的。
期望的系统状态被版本化在 Git 中。
有一些已批准的变更可以自动被应用到系统中。
软件代理可以确保正确性并在出现异常时发出警报。
就像敏捷宣言一样,这四个原则很容易被人们所接受。但与敏捷一样,将理论转化为实践才是有趣的部分。
GitOps 的核心思想是通过持续运行的软件代理让系统状态趋近于期望状态。

那么,我们如何使用典型的 GitOps 来协调这些状态呢?
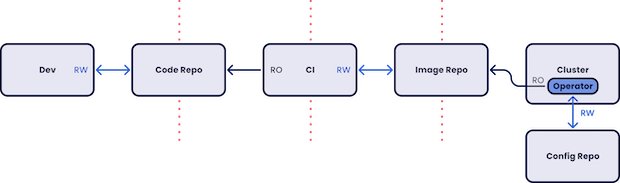
我们在集群中安装 Operator(或代理),它从 Git 配置库中“拉取”所需的状态,做出决策,并相应地调整工作负载。
这是针对标准 DevOps 管道(将变更“推送”到集群中)的替代方案。
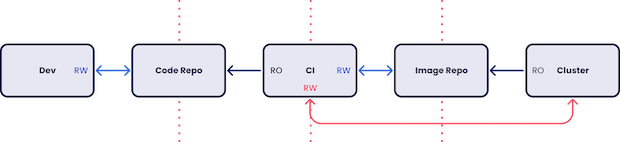
我们已经概述了 GitOps 的理论并描述了基本的实践,现在来说说 GitOps 的好处。
首先,我们来看看安全性。与简单地向集群推送变更相比,“基于拉取”的方法的好处是什么?它的主要优点是 CI 服务器不需要生产访问权限,因此我们可以说这提高了安全性。
然而,这真的带来了额外的安全性吗?如果 CI 系统可以更新配置,那么 GitOps 如何防止访问 CI 的恶意操作者部署非法的工作负载?
GitOps 的另一个主要卖点是环境的版本化历史。这在一定程度上是真的,但常规的 DevOps 中也有(假设你的管道和部署信息存放在源存储库中)。版本历史很有用,但它并非环境变化的真实记录。
GitOps 中的回滚是否更简单?我的观点是,你最好使用常规的 DevOps,只需要回退已提交的变更即可。这样做的好处是,它让回滚成为标准开发者工作流的一部分,并可以进行版本控制。如果有任何问题,进行简单的 Git 回退即可。
如果整个集群停止运行了该怎么办?如果你想要启动一个新集群该怎么办?这些都是很可能出现的情况。但大多数团队并没有使用蓝绿集群,大多数公司都使用了静态集群。大多数灾难恢复不会因为需要运行部署管道而受到阻碍,我认为这使用脚本即可,而不需要 GitOps。所以我对 GitOps 在灾难恢复方面所带来的好处持怀疑态度,但在考虑实现 GitOps 时必须做出的权衡时,我有更多的保留意见。
GitOps 带来的第一个挑战是它对管道的影响。部署阶段与管道较早阶段的分离导致它们变成分布式的。从整个链路来看,这使得从变更提交到生产部署的整个路径变得难以理解。它将较早阶段的职责与较晚阶段分开。
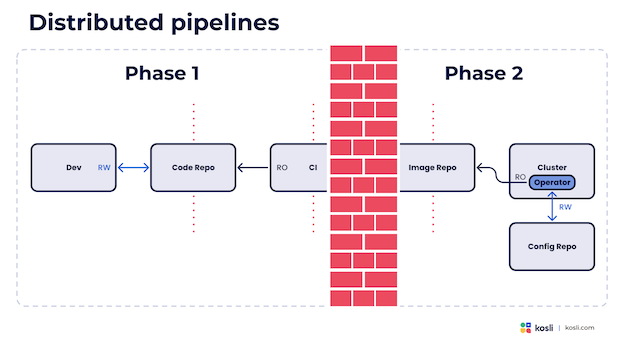
这很重要,因为它从整个链路中移除了开发者的反馈。一旦部署失败,将从哪里获得反馈?开发者如何获得关于部署流程的信息?他们如何用收到的通知增强部署过程?他们如何改进部署过程?
第二个副作用是这加大了开发和运维之间的差距。
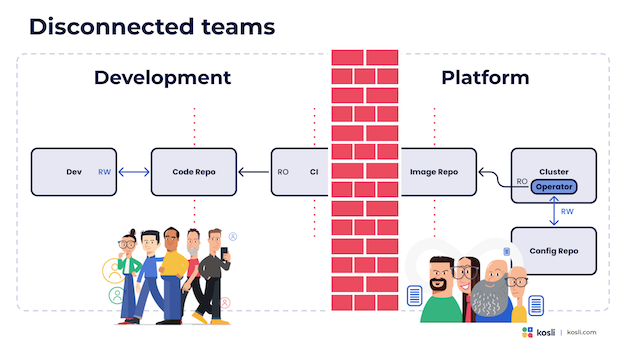
通常,平台团队负责运行和管理 GitOps 工具,CI 系统通常也处在这个团队的管辖范围内。
使用单独的配置存储库来保存系统状态将进一步扩大团队之间的差距:
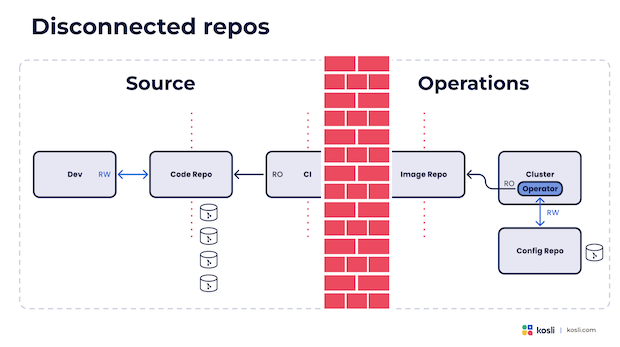
通常,在微服务的 Git 存储库通之外会有一个单独的描述所需环境状态的公共存储库。一个是以代码和开发者为中心的,一个是以运维为中心的。此外,我们还经常编写胶水管道脚本来更新配置存储库。
GitOps 的主要创新似乎是转移到了基于拉取的模式。这似乎是一个很大的变化,但如果仔细观察,我不认为这是真的。
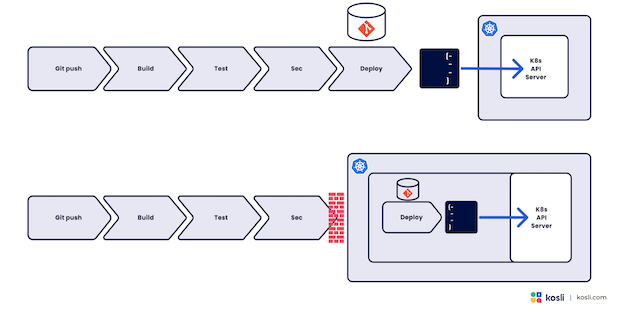
通常,Operator 从 Git 存储库读取配置,对其应用转换,然后将其推送给 Kubernetes API 服务器。这正是部署工具在基于推送的模型中所做的!使用 GitOps,我们将管道分布到两个异步工具中,使用一个 Git 存储库作为信号量,但使用这两种方法,我们都可以将变更推送到集群中。
GitOps 的另一个主要优势是协调循环——自动修复漂移或手动变更。任何没有文档记录的变更都将被移除,并让环境与 Git 定义保持一致。
从表面上看,这似乎是一笔巨额奖励。然而,我对此有不同的看法。在我们开始讨论协调无文档记录的变更之前,我们需要首先问一下为什么会出现这些变更。也许我们不希望它们得到协调?在某些情况下,我们需要进行手动变更,并且不希望环境被自动修复。
另一个原因可能是蓄意破坏,对于这种情况,我们肯定希望有人参与调查和管理。不管是哪一种情况,配置发生漂移都应该导致适当的事件管理过程发生,而不仅仅是让协调循环向 Slack 频道发个消息,然后消失于无影。
从技术方面来看,我觉得 Kubernetes 已经有协调循环了。你可以通过声明的方式描述部署和配置,剩下的由 Kubernetes 来实现。分层调节循环似乎增加了不必要的复杂性。
我们倾向于认为 Git 配置库等同于变更,但实际上,这些静态定义与动态 DevOps 自动化中实际发生的情况之间存在差距。所有关于 GitOps 提供“单一真相来源”的说法都是不正确的。如果我想知道周四晚上运行了些什么,根本没有简单的方法可以知道。
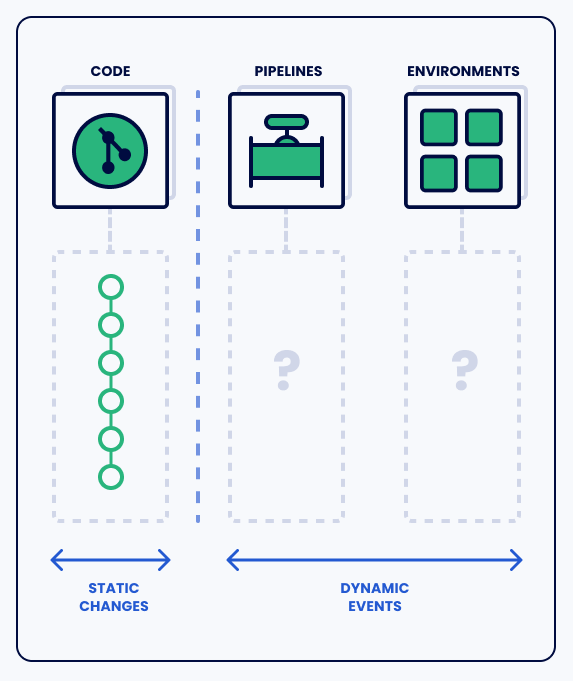
GitOps 配置没有提供对手动变更、伸缩事件、失败的协调和许多其他边缘情况的见解。这些类型的事件会导致故障发生,但当它们真的发生时,GitOps 并不会为我们提供感知。
当发生事故时,我们真正需要的是了解事情的实际变化情况。现代 GitOps 的一个大问题是,开发者和运维团队对实际发生的变更几乎没有真正的记录。我们需要明白的是,期望状态并不是实际的状态。
我一开始就说,我完全赞成把 DevOps 的实践指南、定义和规范放在版本控制系统中。它为我们提供了各种各样的好处,我们来回顾一下:
更好的透明度——支持基于熟悉的技术进行共享、评审和审计。
代码工具和工作流——支持使用分支 / 基于拉取请求的方法来集成变更。
更好的质量——你可以在自动化过程中添加 Linter、检查器和静态分析器,并强制保持变更的一致性。
不可变性——有助于最小化配置漂移。
集中化——有助于减少“配置蔓延”,即进程的配置分散到多个不相连的系统中。
到目前为止还不错——但每个静态定义都有动态执行的部分。有一些自动且异步发生的事件,我们需要记录和理解它们的结果。
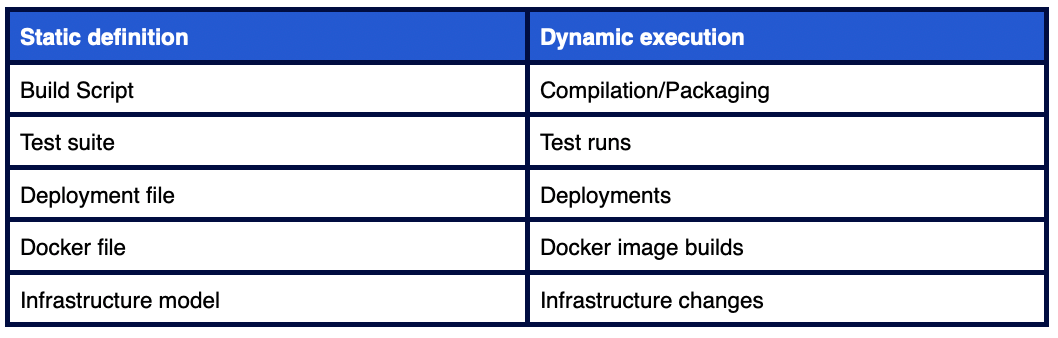
毫不夸张地说,动态的部分是真正发生事件的地方。从 GitOps 定义回溯到事件、变更、排序和依赖关系对开发者来说并不容易。如果你想知道为什么这很重要,《Google SRE 工作手册》告诉我们——“70% 的停机是由于活动系统中的变更造成的。”所以,当事情出错时,我们应该首先在动态的部分寻找答案。
就像敏捷宣言一样,GitOps 的松散定义意味着它可以并且将会以各种不同的方式被应用。Terraform 是 GitOps 吗?也许吧?我不知道!
和敏捷一样,我们每个人都经历过 FOMO(指害怕错过某些事)。如果这是下一件大事呢?我们是不是因为害怕掉队而赶时髦?对于敏捷,我们需要问“谁是敏捷的?”对于 GitOps,也许我们需要问“谁是 GitOps 的?”和以往一样,我们真正需要问自己的是“我们使用这些工具为谁提供服务?我们试图解决什么问题?”
在《皇帝的新衣》的结尾,周围的人继续对皇帝的新衣赞不绝口,即使他们意识到他是完全赤裸的。当我们全身心投入某件事,并希望它是真实的,都有可能会陷入这种尴尬的境地。就像人群中那个大喊“但是皇帝什么也没穿”的小孩一样,有时候,我们只需要把看到的说出来,就有可能让事情变得没那么复杂。
原文链接:
https://thenewstack.io/does-the-gitops-emperor-have-no-clothes
声明:本文为InfoQ翻译,未经许可禁止转载。
马斯克称 Twitter 可能破产;Meta 暴裁 1.1 万人,小扎承认犯了错;GitHub 年度报告:印度开发者增速超中国 | Q 资讯
动动嘴就能写代码了!Copilot测试新功能“嘿,GitHub”,告别键盘编码


