深度召回在招聘推荐中的挑战和实践


分享嘉宾:李祖定 58同城 算法架构师
编辑整理:郭嘉伟
内容来源:58推荐系统技术沙龙
出品平台:DataFunTalk
导读:招聘业务是多行为场景,用户需求和交互周期短、行为稀疏。本次分享基于业务挑战,将介绍代价敏感、向量检索等技术在招聘深度召回中的应用,最后总结实践中的教训与心得。
主要内容包括:
58招聘业务场景
招聘推荐系统
基于行为的向量化召回
实时深度召回
教训和心得
首先和大家分享下58招聘涉及的业务及场景。
1. 58招聘业务
招聘行业:
据2018年统计,我国总人口13.9亿,就业人口7.7亿,三大产业就业人口占比分别为26.11%、27.57%、46.32%;据2019年8月统计,城镇调查失业率达到5.2%,25~59岁人口失业率达到4.5%;2019年800万+毕业生进入求职市场;求职者和招聘方的需求都十分强烈。
58招聘:
58招聘在互联网招聘界占有率居首;服务于大规模求职者及大中小型企业;平台上每天达成海量连接,促成大量成功就业。
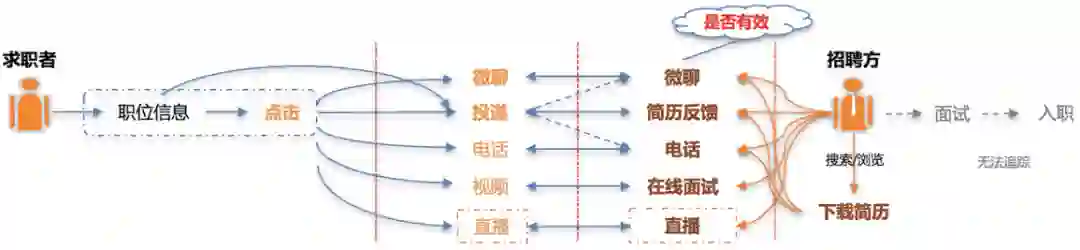
求职场景分为C端求职者和B端招聘方:
求职者进入App后,会在展现的职位信息中产生行为,如直接投递简历,或者点击进入职位详情页后通过简历投递、IM、电话等多种方式与招聘方交互;
招聘方可以搜索/浏览合适的简历,通过IM、电话、在线面试等多种方式与求职者交互,对简历进行反馈。找到心仪的求职者并进行面试乃至入职的后续流程。
58招聘是一个典型的双边业务,交互渠道非常多样。
2. 58招聘推荐场景
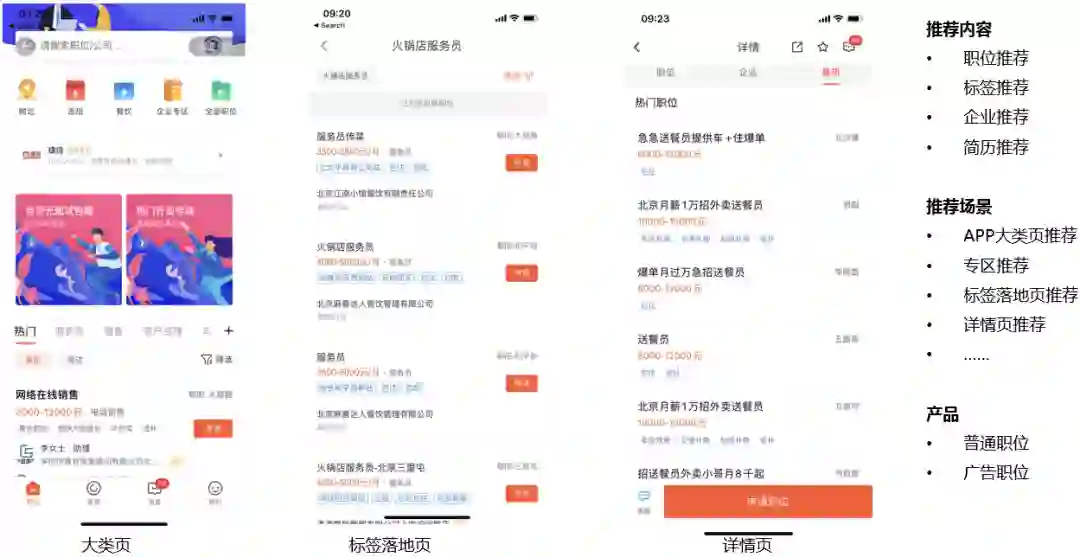
58招聘主要实现了以下招聘场景的推荐:
大类页:分为专区推荐和搜索推荐;
标签落地页:58招聘Feed流推荐的代表,根据用户搜索的请求匹配相应的职位,用户在展现页可以选择投递职位或进入详情页查看;
详情页:展示具体的职位信息。
推荐内容主要包括toC的职位推荐、标签推荐、企业推荐,以及toB的简历推荐。
产品主要包括普通职位和广告职位。
3. 58招聘场景下面临的问题与挑战
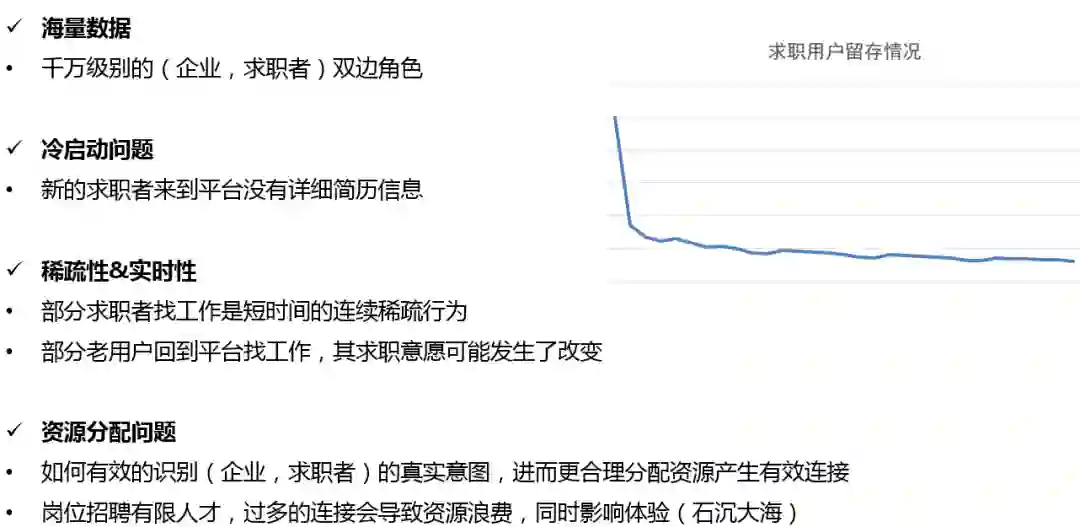
在我们的工作中,主要面临以下问题和挑战:
海量数据:千万级别的双边 ( 企业、求职者 ) 角色,用户行为非常复杂。
冷启动问题:新的求职者来到平台没有详细简历信息,在这种场景下如何引导用户进行投递行为。
稀疏性&实时性:找工作这种活动的性质决定了部分求职者的行为是短时间的连续稀疏行为,通常在几天或者一周之内完成;部分老用户回到平台找工作,其求职意愿可能发生了改变;用户行为周期过短并且用户意图经常变化对深度模型的搭建造成了很大的挑战。
资源分配问题:如何有效的识别用户 ( 企业、求职者 ) 的真实意图,进而更合理地分配资源从而产生有效连接;岗位招聘希望高效匹配人才,过多的连接会导致资源浪费,同时影响体验 ( 石沉大海 )。
下面和大家分享下58招聘推荐系统的整体架构和召回实现。
58招聘推荐系统
1. 58招聘推荐系统整体实现
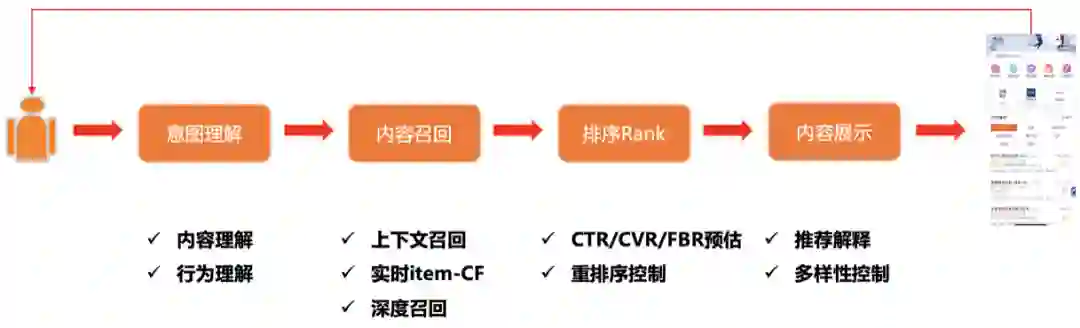
58招聘推荐系统的整体处理流程和其他场景的推荐系统大同小异。在用户到来后首先进行用户意图理解,从职位池中多路召回职位,对召回职位根据优化目标进行精排和重排序,最后加入多样性等策略将最终内容展现给用户。
意图理解:C端用户进入后通过内容理解、行为理解
内容召回:上下文召回、实时item-CF、深度召回以及粗排的等多种召回方式
排序Rank:优化目标有很多,除了传统的CTR预估、CVR预估,还有招聘场景下针对B端用户进行的FBR ( FeedBack Rate ) 预估;重排序控制
内容展示:针对业务考虑推荐的解释性及多样性,进行排序并最终展现
2. 58招聘推荐系统的召回策略
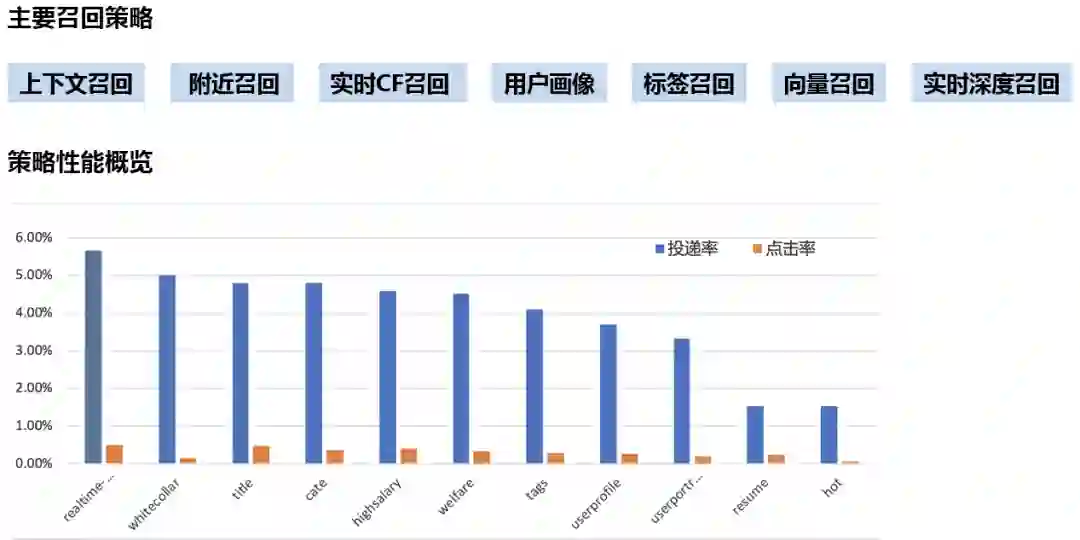
58招聘推荐系统的召回策略多达十几种。主要有:上下文召回、附近召回、实时CF召回、用户画像、标签召回、向量召回、实时深度召回。
从图中直观地看,实时召回在召回序列中性能最优。
基于行为的向量化召回
1. 深度召回的整体框架
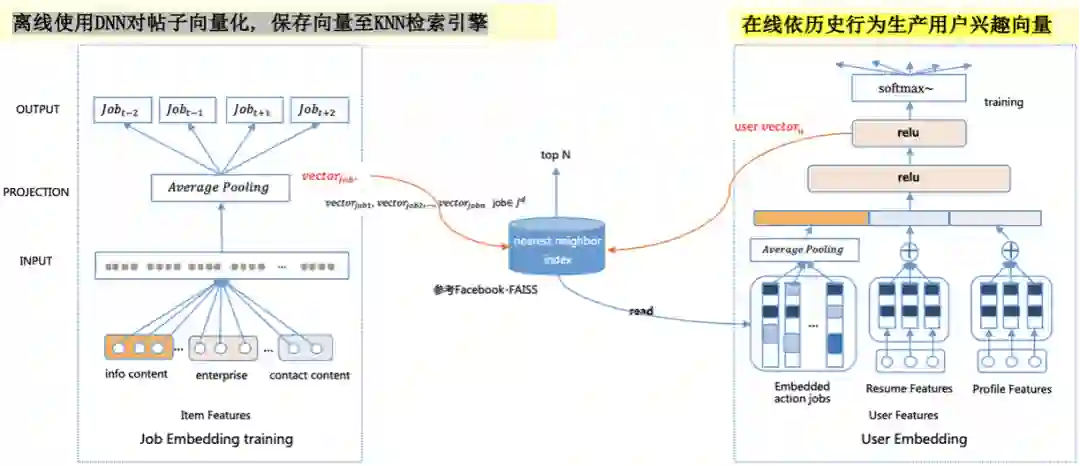
不论传统或深度召回方法,都要先构建物品的索引和理解用户的请求,对用户的请求返回匹配的物品。不同处在于深度召回中物品索引和用户请求表现为向量的形式。
离线使用DNN对招聘帖向量化,保存向量至KNN检索引擎:
该检索引擎参考了Facebook的开源项目Faiss,目前58内部已应用到生产并且有完备的中台支持
招聘帖的特征包括:内容、企业信息、企业联系方式等,将多个特征经过相同的Embedding层后再通过一个平均池化作为招聘帖最终的向量表示
用户的招聘帖历史行为可转化为一个行为链,在多条行为链上使用自然语言处理中常见的Skip-Gram加负采样的做法训练招聘帖的向量表示
在线依历史行为生产用户兴趣向量:
用户特征,包括:用户的历史行为、用户的上下文、用户自身属性等。
2. 职位向量化的原理及假设
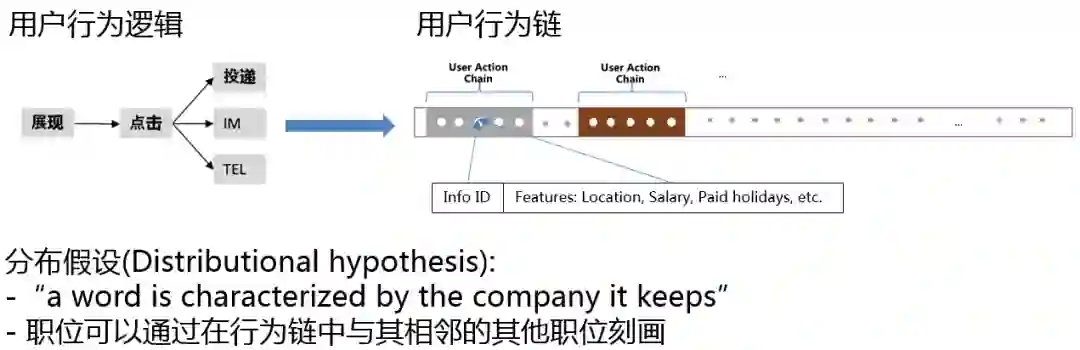
推荐系统将物品对用户展现后,用户可能会产生点击、投递、电话、IM等多种行为。上图右上展示了58招聘如何收集用户行为链。图中每一个点代表一个行为,点中有两个属性,招聘帖自身信息和用户行为。
招聘帖自身信息:
招聘帖id
职位的地点、薪水、假期等
用户行为:
点击、投递等
在语言学中,分布式假设可以表述为:一个单词的特征可以被总和它一同出现的单词所描述。我们自然可以联想到:职位可以通过在行为链中与其相邻的其他职位刻画。当然这只是一种假设,并没有严格的证明。
特别的,用户行为的重要性是不同的。在招聘推荐场景下,显然投递行为的价值大于点击。
3. 职位向量化采取的主要优化点

网络架构上节已介绍过,在实践过程中我们主要有以下几个优化点。
① Session优化:
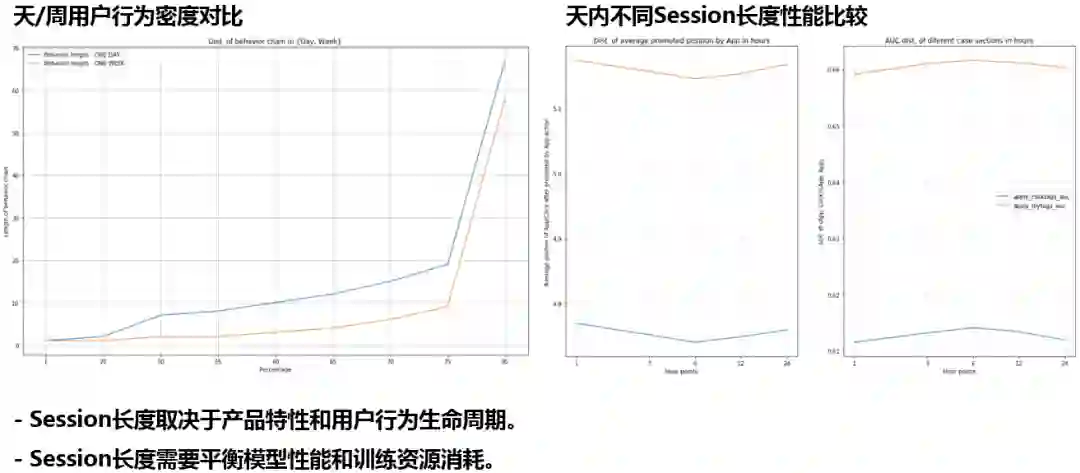
Airbnb的经验是将Session划分为2周,58招聘则进行不同的尝试;上图左半部显示的是将Session划分为1天或1周时的用户行为密度对比,其中蓝色表示划分间隔为1天,黄色为1周,图中纵轴表示用户不区分点击或投递的行为链长度,纵轴表示长度所占百分比,可以看出差异并不显著,故初步选定为1天;上图右半部显示的是天内不同Session长度性能比较,左图表示不同划分时平均推荐位置排序,越小表示相关结果的推荐越靠前,右图表示预测结果的AUC,越高代表预测结果越准确,两个度量指标均为6小时划分最优;Session长度取决于产品特性和用户行为生命周期;Session长度需要平衡模型性能和训练资源消耗。
② 正向样本Left-wise采样,负向样本全局空间负采样加局部市场空间采样:
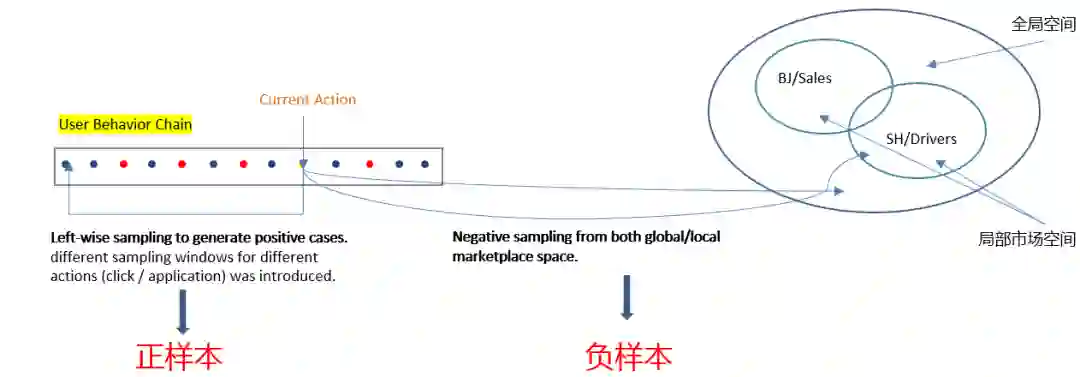
负采样时按照不同的地区和职位的类别划分
正样本Left-wise采样为避免用户未来行为的干扰,只采样当前行为发生之前的行为
不同行为的权重不同,点击行为只给一个较小的采样窗口,投递行为则给一个较长的采样窗口
负向样本同时在全局空间和局部市场空间采样,当前用户行为的招聘帖具有位置和种类等属性,可以在同位置、同种类的局部市场空间采样
③ 行为权重代价敏感损失:

图中上面的公式表示不考虑代价敏感时向量训练的损失函数,其作用是使正样本之间的向量表示更相似,同时正负样本之间的表示区别更大。图中下面的公式是考虑代价敏感时向量训练的损失函数,具体做法是区分点击和投递两种行为,在正样本之间加入一个代价矩阵,表示该样本的行为是哪一种,表示不同行为之间的代价权重,是一个根据经验给出的超参数。
4. 职位向量化的离线评估与业务效果

评估方法:
展现给用户的职位会形成一个列表,用户行为链中包含点击、投递,同时用户可能会对展现列表中的职位进行点击、投递;依照用户历史行为链中职位和展现行为职位间的Cosine距离,考察行为链对展现职位的位置提升。
离线评估结果:
图中表格显示了用户历史行为链对展现职位的位置提升,如在没有使用Embedding时,历史行为链投递的职位与展现列表中产生投递行为的职位计算Cosine距离重排序后,平均位置为7.1074,使用Embedding后平均位置为4.8236,得到了32.09%的提升,类似的,历史行为链中的点击行为与展现列表中产生投递行为的职位计算Cosine距离重排序,显示对展现职位的位置得到了29.73%的提升。
我们对所有的职位都生产一个向量, 使用Faiss构建向量相似度检索库,对每个职位都计算与其最相近的top k职位,最终离线形成职位与职位之间的索引。在线上推荐时我们首先根据用户的历史点击行为链和历史投递行为链分别在索引库中召回职位,再经过精排和补充策略后展现给用户。
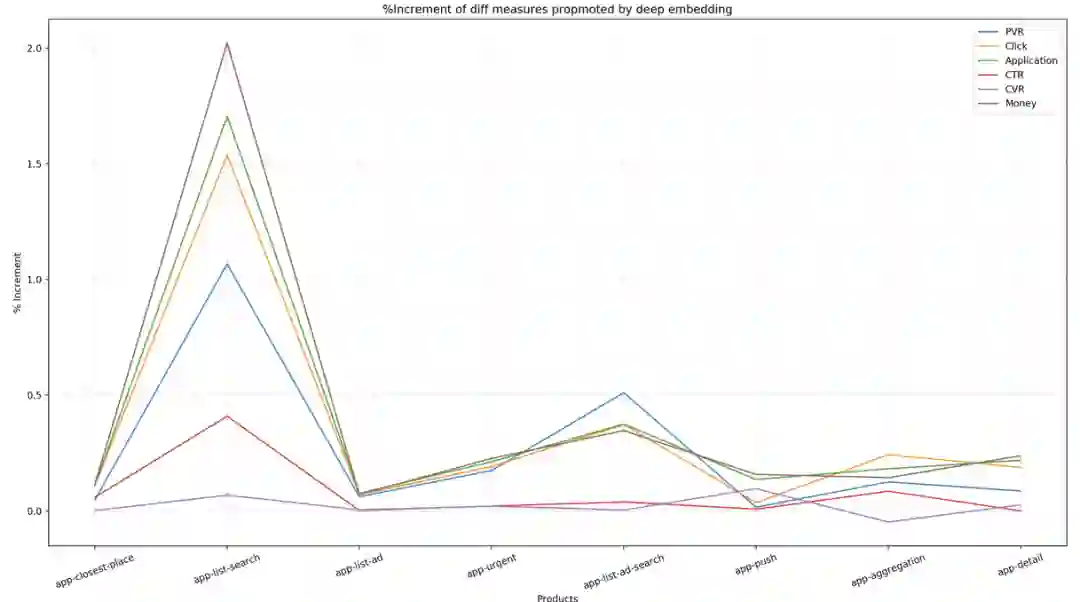
业务效果:
上图中横轴表示不同的展现位,纵坐标表示提升幅度,不同的曲线表示不同指标下的提升,包括PVR、CTR、Money等;从图中看出,所有主体指标在线上的反馈都是正向的,且产出较大。
1. 网络架构
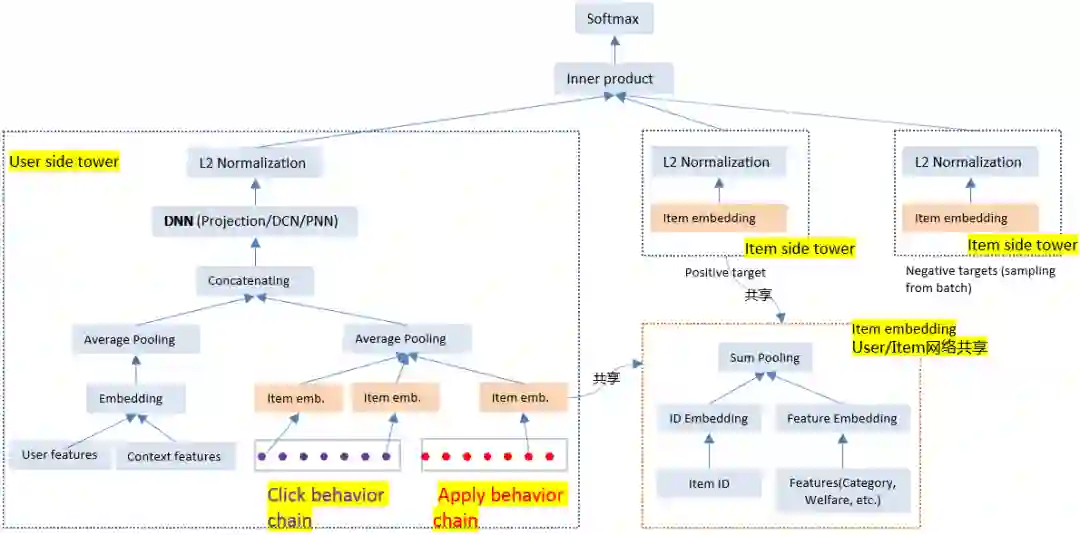
使用双塔架构进行实时召回在业界得到了极为广泛的使用,Facebook、微软、百度等公司都针对自身业务提出了各自的双塔网络架构。58招聘则参考了Youtube技术团队19年提出的双塔架构[1]。
用户侧的处理流程:
用户侧信息:用户特征如简历信息、画像信息等,上下文信息如位置、种类等,以及用户点击行为链和用户投递行为链;
用户特征和上下文特征等多种信息以独立向量的形式输入Embedding层后进行平均池化;
用户行为链中每一个招聘帖信息经过Item Embedding层后进行平均池化;
上述两个经过平均池化的向量连接后输入一个DNN ( Deep Neural networks ),58招聘在DNN的选择上进行了多种尝试,如projection ( 单层神经网络 )、DCN[2]和PNN[3];
最终经过一个L2归一化操作,得到用户侧的表示向量;
特别的,Item Embedding层由用户侧和物品侧共享。
物品侧的处理流程:
招聘帖信息经过与用户侧共享的Item Embedding层后再进行一次L2的归一化操作。
其中,共享Item Embedding层的操作为:
对招聘帖的ID进行ID Embedding,对招聘帖的特征进行Feature Embedding;
对上述两个Embedding向量进行一次加和池化。
2. 增量训练中的负采样处理
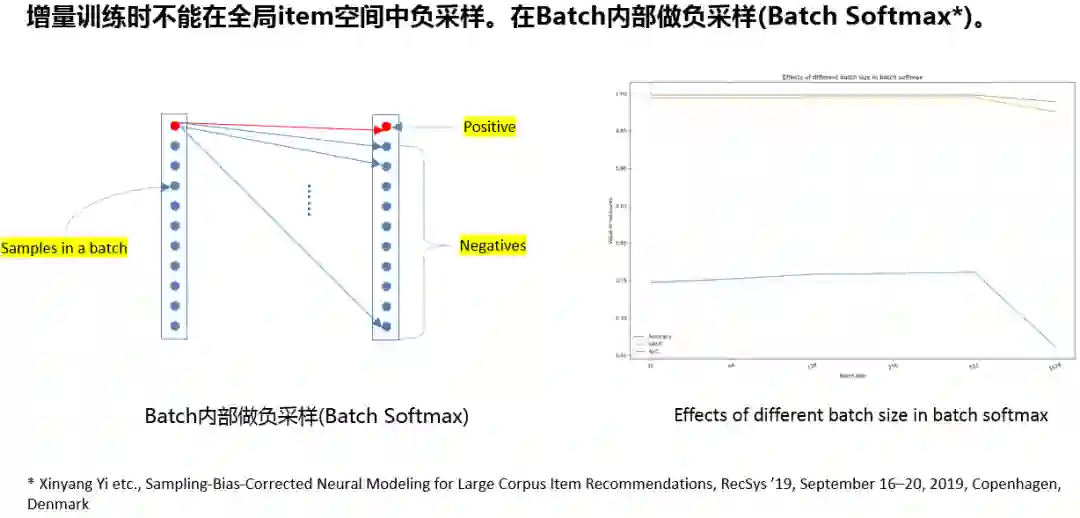
实时召回时要对模型进行在线的增量更新,无法使用离线时的负采样操作;我们参考了Youtube团队19年提出的batch softmax方法,在batch内进行负采样,具体细节请参考论文[1]。
我们比较了不同batch size的效果区别,实践表明batch取512时效果最优。
3. 实时深度召回的线上AB测试效果
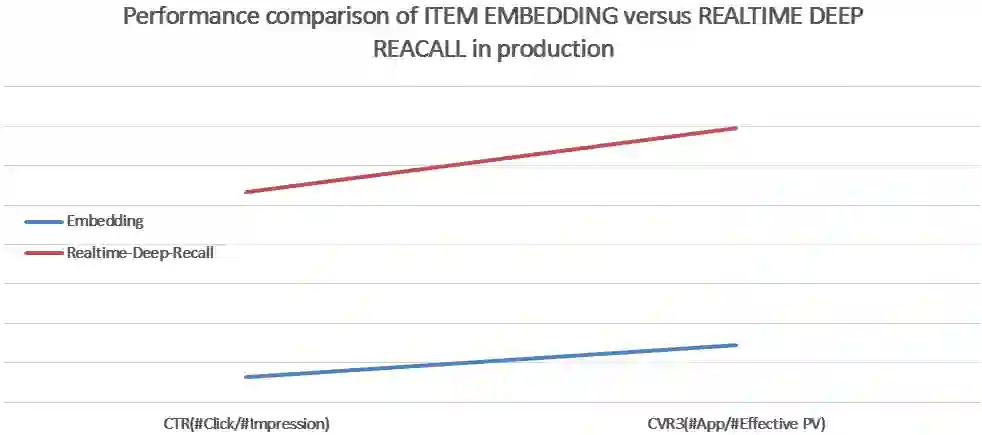
实时深度召回目前在58招聘还没有完全开展,所以整体的业务效果不能给大家呈现,目前只能给大家展示与上节介绍的Embedding方法的效果对比。
实时深度召回方法在CTR、CVR指标上都有1个百分点以上的提高。
05
1. 召回优化总体思路

我们将召回分成了三个阶段,分别为前、中、后。
召回前:
意图增强:识别场景,用户,产品三方意图和状态;
策略调度:在多路召回中采取动态调配创建组装下游召回策略,增加召回质量和规模,动态调节召回参数如召回量、距离等。
召回中:
意图本地化:通过优化用户搜索行为中的query和用户行为链的理解,更加精准/实时的构建用户的画像和query理解;
信息检索:在用户行为画像、简历画像方面,加强查询条件,如加入福利、年龄等。
召回后:
粗排:在中段无法加入的强且显性因素在这一阶段加入;
过滤:强匹配因子加在这一阶段,如性别,确保重复的各强度匹配的召回规模,部分因子必须在后端处理。
总之,召回阶段需要考虑的主要有:场景匹配、实时性、需求意图匹配、个性化。场景匹配我们主要在召回前进行,在三个阶段则都要加强实时性。需求意图匹配包括对C端和B端两部分,个性化主要体现在召回中和召回后阶段。
召回前的优化得到了约32%的收益提升,召回中的优化得到了约64%的收益提升,召回后的优化只得到了约4%的收益提升,召回后阶段还有很大的优化空间。
2. 心得体会
业务先行:所有的问题都是因业务而产生,因此无论模型设计、Session划分、代价敏感损失,以及评估指标等,都要站在业务的角度去考虑;
Pair-review:Pipeline和设计、实施过程、结果都做Pair-review,算法的迭代周期长,每个阶段的review都非常重要;
监控:覆盖在线/离线全Pipeline的监控,每个召回的通道的召回量是多少、进入粗排的量是多少、粗排过滤后的量是多少、进入精排后想要什么样的结果等等,只有通过监控才能发现问题,从而才谈得上如何解决问题。
3. 后续优化点
实时深度召回从目前来看没有达到我们的预期,增长效果不明显,后续还需继续优化,并且要从部分场景开展到全场景覆盖;
召回策略动态调度:继续优化动态召回调度的策略;
C端优化到C/B两端同时优化:58招聘是双边业务,前面介绍的工作主要集中在对C端的优化,后续我们会探索双端同时优化。
[1]. Yi, Xinyang, et al. "Sampling-bias-corrected neural modeling for large corpus item recommendations." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[2]. Shan, Ying, et al. "Deep crossing: Web-scale modeling without manually crafted combinatorial features." Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016.
[3]. Qu, Yanru, et al. "Product-based neural networks for user response prediction." 2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 2016.
07

识别二维码收看
今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:



李祖定
58同城 | 算法架构师
58招聘业务推荐系统算法策略负责人,负责招聘推荐系统的算法策略建设和优化,包括召回、排序等,致力于提升平台用户体验和变现能力。
关于我们:

🤔你今天写BUG了么?👇




