超越MnasNet、Proxyless:小米开源全新神经架构搜索算法FairNAS
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Xiangxiang Chu 参与:路、杜伟
本文转载自:机器之心
近日,小米 AI 实验室 AutoML 团队放出了升级 NAS 算法的新工作,其提出的超网络训练及多目标强化演化搜索 FairNAS,解决了 DL 模型 rank 稳定性的核心问题,在 ImageNet 分类任务上超过 Google Brain 的 MnasNet(CVPR 2019)和 MIT 韩松等人提出的 Proxyless(ICLR 2019)。
小米 AI 实验室表示,此项研究可为深度学习工程师武器库再添一大利器,目前该团队已开源了模型前向模型搭建及验证代码。
论文链接:https://arxiv.org/pdf/1907.01845.pdf
模型链接(PyTorch):https://github.com/fairnas/FairNAS
根据模型真实能力进行排序的能力是神经架构搜索(NAS)的关键。传统方法采用不完整的训练来实现这一目的,但成本依然很高。而通过重复使用同一组权重,one-shot 方法可以降低成本。但是,我们无法确定共享权重是否真的有效。同样不明确的一点是,挑选出的模型具备更好的性能是因为其强大的表征能力,还是仅仅因为训练过度。
为了消除这种疑问,小米 AI 实验室 AutoML 团队的成员提出了一种全新方法——Fair Neural Architecture Search (FairNAS),出于公平继承和训练的目的,该方法遵循严格的公平性约束。使用该方法,超网络训练收敛效果很好,且具备极高的训练准确率。与超网络共享权重的采样模型,在充分训练下的性能与独立模型(stand-alone model)的性能呈现出强烈的正相关。该结果大大提升了搜索效率,并且通过一个多目标强化演化搜索后端,研究人员提出的 pipeline 在 ImageNet 数据集上生成了一组新的 SOTA 架构:FairNAS-A 在 ImageNet 上实现了 75.34% 的 top-1 验证准确率,FairNAS-B 的验证准确率为 75.10%,FairNAS-C 为 74.69%,并且与其他架构相比,multi-adds 更低,参数也更少。

图 1:超网络的训练过程。
如上图所示,实验结果表明,在严格的公平性约束下,one-shot 模型在 ImageNet 训练集上的平均准确率稳步提升,没有出现振荡。与 [2] 相比,one-shot 模型的分层样本的准确率范围大大缩小。这是一个重大进展,研究者在快速评估模型的同时也能保证准确性。
这项研究解决了什么问题?
FairNAS 解决了两个基础问题:
基于 one-shot 超网络和之前方法的采样技术区别子模型之间的区别,真的公平吗?
如何根据模型性能进行快速排序,且排序结果具备较强的置信度?
具体而言,该研究具备以下贡献:
遵循严格公平性(strict fairness),强化 one-shot 方法;
在严格公平性条件下,实验结果表明平均准确率呈稳步上升,没有出现振荡(见图 1);
尽管 one-shot 方法极大地加速了估计,但研究人员仍然面对多个现实约束以及广阔的搜索空间,于是研究人员选择多目标 NAS 方法 [5] 来解决这个需求。
使用该研究提出的 pipeline,可在 ImageNet 数据集上生成一组新的 SOTA 架构。
Strict Fairness
在某种程度上,所有 one-shot 方法都是预定义搜索空间中任意单路径模型的不同性能预测器代理(proxies for performance predictor)。好的代理不能过度高估或低估模型得分。而目前还没有人对该主题进行深入的研究,并且以往多数研究仅仅侧重于搜索得分较好的几个模型。
为了减少超网络训练过程中的先验偏置(prior bias),研究人员定义了基本和直接的要求,如下所示:

不难看出,只有单路径 one-shot 方法符合上述定义。
在超网络训练的每个步骤中,只有相应激活选择块(choice block)的参数能够得到更新。笼统来说,参数更新的目的是减少模型在小批量数据上的损失,因此它虽然能够帮助激活选择块得到比未激活选择块更高的分数,但同时也产生了偏差。
研究人员将这种减少此类偏差的直接和基本要求称之为 Expectation Fairness,其定义如下:

研究人员提出了用于公平采样和训练的更严格要求,称之为 Strict Fairness,其定义如下:
定义 3 施加了比定义 2 更严格的约束。定义 3 确保每个选择块的参数在任何阶段的更新次数相同,即 p(Y_l1 = Y_l2 = ... = Y_lm) = 1 在任何时候均成立。
小米 AI 实验室提出的新方法:FairNAS
小米 AI 实验室的研究人员在严格遵循定义 3 的前提下,提出一种公平采样和训练算法(见 Algorithm 1)。他们使用没有替换的均匀采样,在一步中采样 m 个模型,使得每个选择块在每次更新时都被激活,参见下图 2:
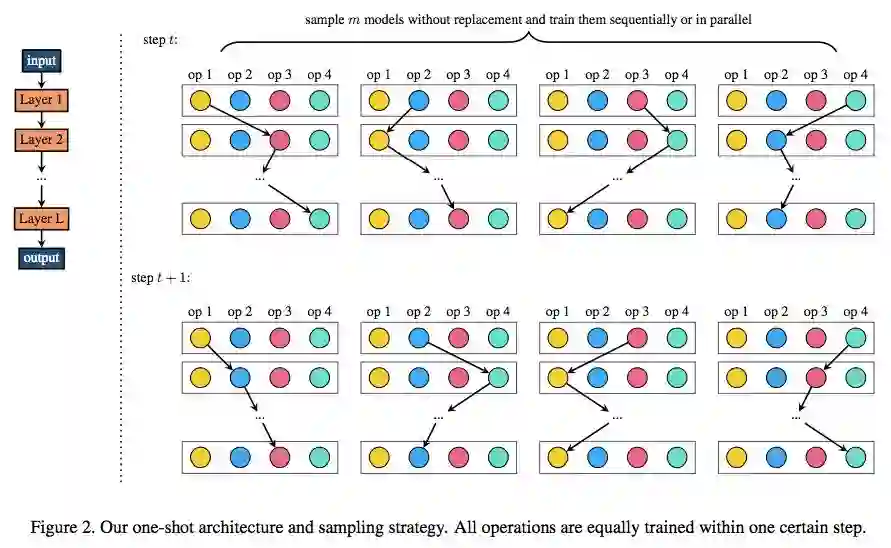
图 2:该研究提出的 one-shot 架构和采样策略。所有运算都在一个特定步内进行同等地训练。
算法 1 如下图所示:

FairNAS 架构
该研究提出的 FairNAS 架构如下图 4 所示:

图 4:FairNAS 架构。
实验
实验设置
搜索空间:搜索空间基于 MobileNetV2 的 inverted bottleneck 模块设计 [4],保留了标准 MobileNetV2 [18] 的层数,搜索空间共包含 6^16 个子模型。
数据集:所有实验均在 ImageNet [17] 数据集上进行。从该数据集训练集上随机选取 50000 张图像作为实验的验证集,训练集中的其余数据作为实验的训练集,原来的验证集作为测试集,用于衡量每个模型的最终性能。
训练参数:使用 256 的批大小训练超网络,共训练 150 个 epoch。随机梯度优化器的动量是 0.9;使用余弦学习率衰减策略且初始学习率为 0.045;使用 L2 权重衰减 (4 × 10^(−5) ) 进行正则化。
不同 SOTA 方法的性能对比
该研究考虑的三个目标是:准确率、multiply-adds 和参数,由于该研究局限于搜索仅适合特定设备的快速准确模型,因此实验中并未考虑延迟。
不同模型在 ImageNet 数据集上的性能对比如下表 2 所示。实验结果表明:在同样的搜索空间设置下,FairNAS-A 实现了新的 SOTA 结果——在 Imagenet 1k 分类数据集上的 top-1 准确率达到 75.34%;在同等 multiply-adds 的情况下,FairNAS-A 的 top-1 准确率高出 MnasNet-92 0.55%,高出 Single-Path-NAS 0.38%。
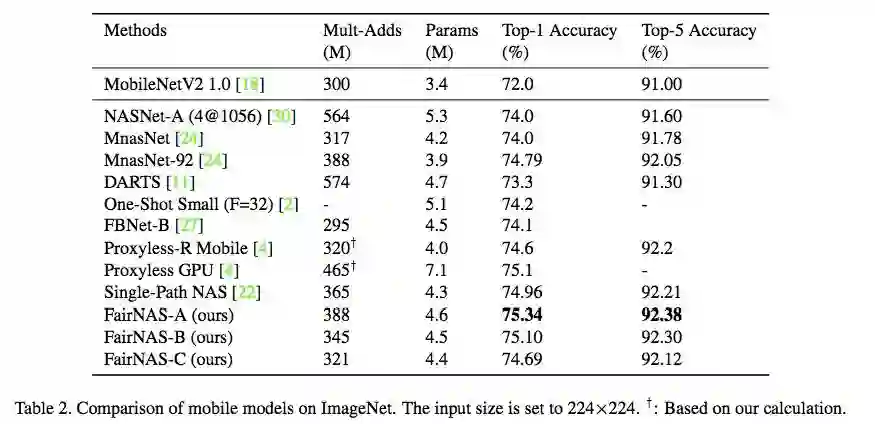
表 2:不同移动模型在 ImageNet 数据集上的性能对比。输入大小为 224×224。

图 8:FairNAS-A、B、C 架构图示。
期望公平性 vs 严格公平性
研究人员基于公平性的定义进一步对比了不同的神经架构搜索方法,如下表 1 所示:
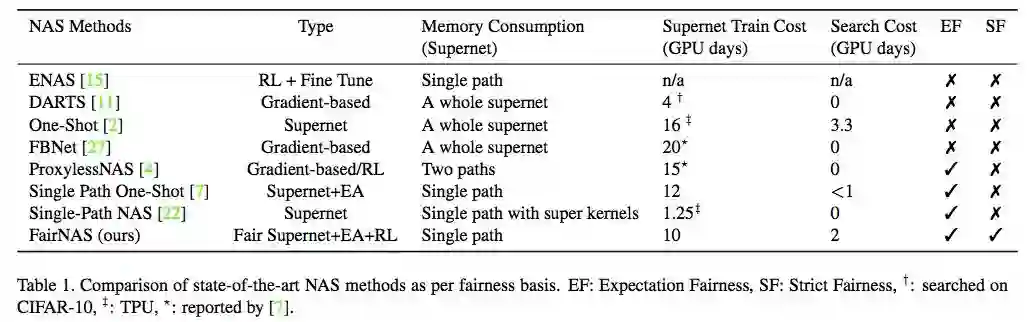
表 1:基于公平性的 SOTA NAS 方法对比。

CVer-NAS交流群
扫码添加CVer助手,可申请加入CVer-NAS交流群。一定要备注:研究方向+地点+学校/公司+昵称(如NAS+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!

