帮你省下2000块钱,入门级显卡RTX 2060做深度学习也不差
晓查 发自 凹非寺
量子位 出品 | 公众号 QbitAI

最近,NVidia发布了Turing架构的入门级显卡RTX 2060,售价只需350美元(约2400元),在老黄家新一代RTX显卡里可谓是物美价廉。
就连上一代顶级显卡GTX 1080Ti价格也是居高不下,官方定价699美元(约4700元)买不到,你还得加价买。
RTX 2060虽然只是入门级显卡,但它有一项重要特性,就是加入了张量核心(Tensor Core),这使深度学习模型能够更好地在“FP16”上进行运行,理论上最多能缩短一倍训练时间。
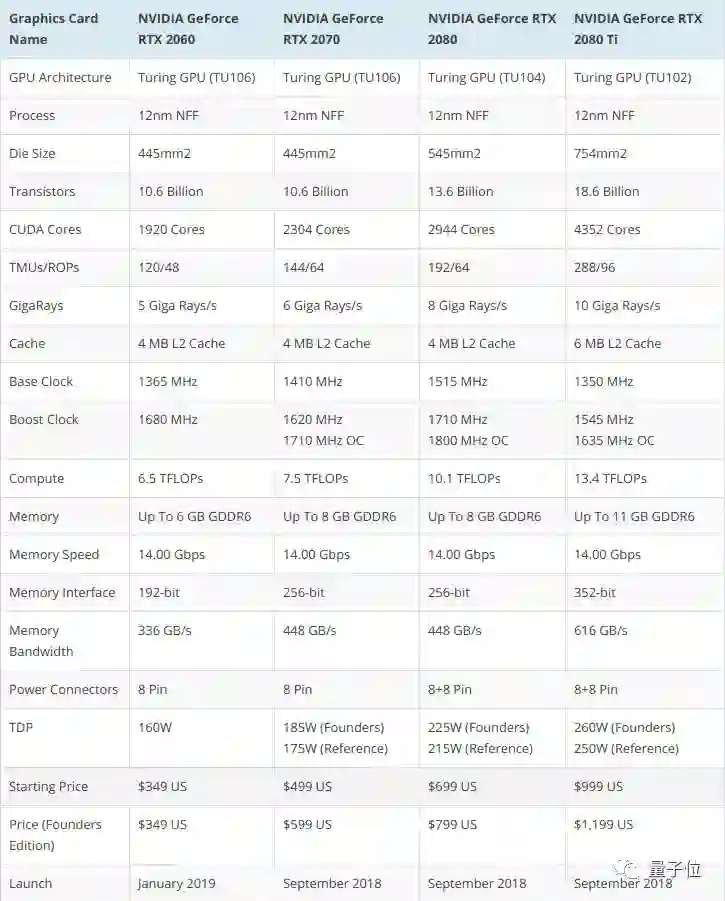
△ RTX 2060规格参数
RTX 2060各方面的优劣势如下:
大约只有GTX 1080Ti一半多的CUDA核心(1920 vs 3584);
显存带宽只有1080Ti的70%(336 vs 484 GB/s);
有240个用于深度学习的张量核心,而1080Ti没有;
功率160W,而1080Ti功率达250W;
更重要的是,作为新一代的“乞丐版”显卡,2060的价格只有1080Ti的一半!
加入张量核心,显存和CUDA核心数却比1080Ti少了近一半,在此消彼长的情况下,2060还适合用来做深度学习吗?如果你囊中羞涩,不妨看国外开发者的实际对比测试,也许能帮你省下一大笔钞票。
一位名叫Eric Perbos-Brinck的深度学习从业人员,分别在两张显卡上测试了CIFAR-10、CIFAR-100两个数据集在不同层数的ResNet上的表现。
运行环境
首先,我们看一下Eric的硬件配置:
CPU:AMD Ryzen 7 1700X 3.4GHz 8核
主板:MSI X370 Krait
内存:32GB DDR4
硬盘:1TB NVMe 三星960Evo
显卡:华硕GTX 1080Ti-11GB Turbo(800美元)、Palit RTX 2060–6GB(350美元)
软件环境:
Ubuntu 18.04 + Anaconda/Python 3.7
CUDA 10
PyTorch 1.0 + fastai 1.0
Nvidia驱动版本:415.xx
在每次运行程序前,Eric都会把训练用的显卡切换到第二个PCIe插槽,由另一张卡负责显示器的输出工作,让显卡把性能100%用在训练模型上。
测试标准的内容是,在CIFAR数据集上训练ResNet模型,比较二者的运行时间,越短越好。
运行结果
为了测试结果的可比性,Eric运行了3个不同版本的Benchmark:
在相同batch size的条件下,运行FP32和FP16;
使用batch size扩大一倍的条件(从128增加到256),运行FP16 bs * 2。
话不多说,下面开始跑分。
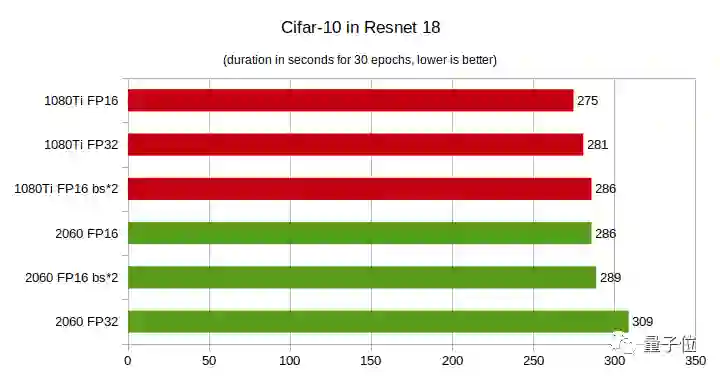
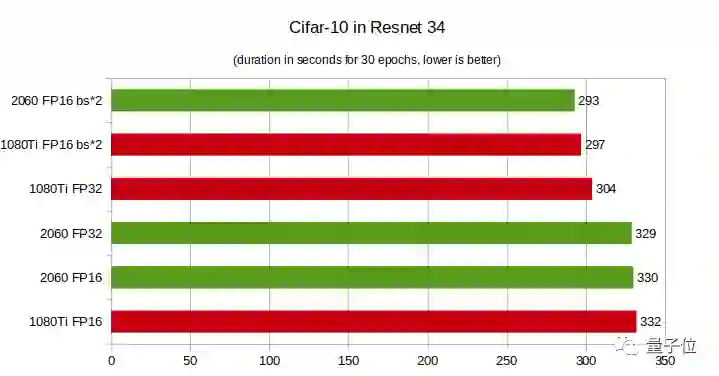
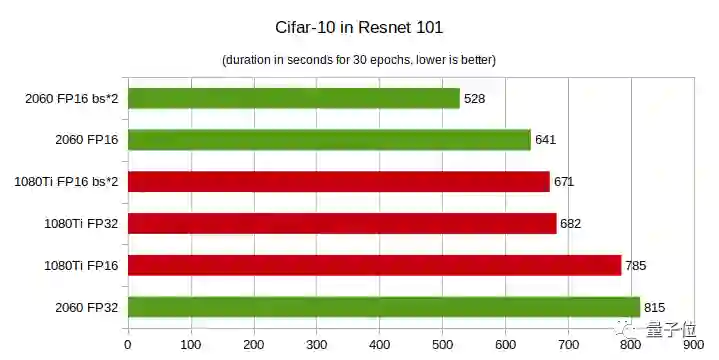
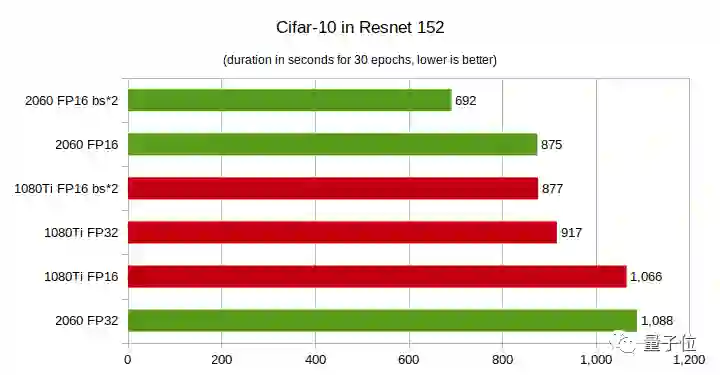
CIFAR-10测试:运行30个epoch所需的时间,越短越好

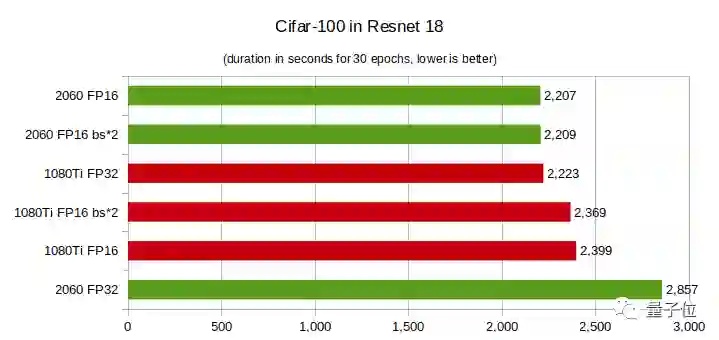
CIFAR-100测试:运行30个epoch所需的时间,越短越好
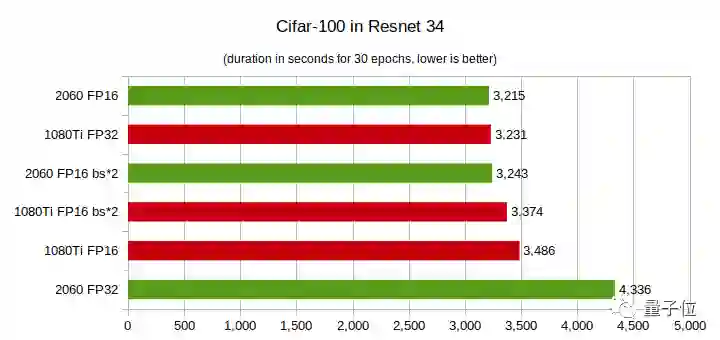
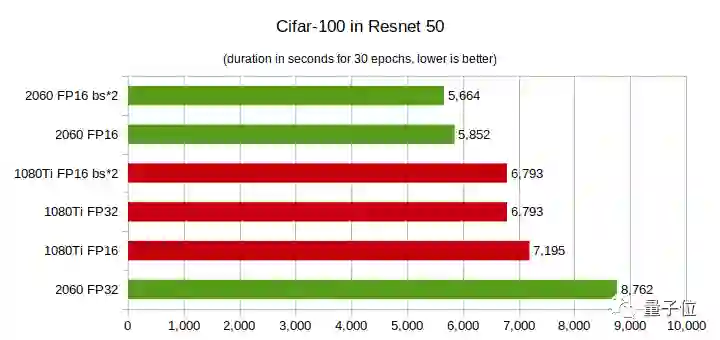
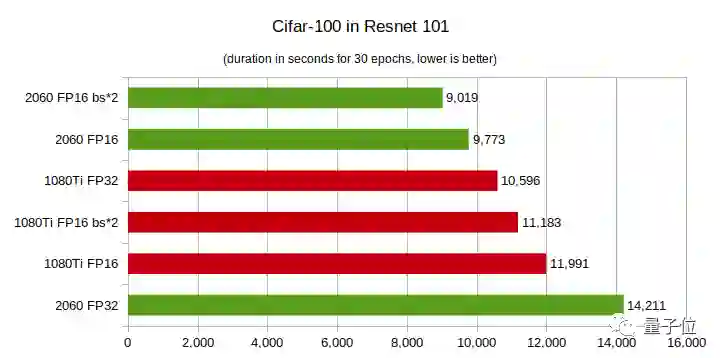
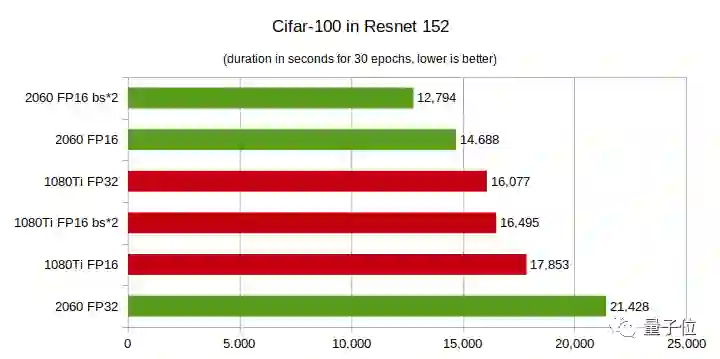
结论:
RTX 2060 FP32在多项测试中性能垫底。
当深度学习模型层数较少时,GTX 1080Ti性能更佳,随着层数增多,RTX 2060性能实现了反超,而且层数越多性能优势越大。
在CIFAR-100上,RTX 2060的性能优势更明显,即便层数较少,在FP16上的性能也好于GTX 1080Ti。
总之,你的模型层数越多,而且是在半精度(FP16)条件下训练模型,那么用RTX 2060就越划算。
One More Thing
以上的结果都是显卡在100%负责训练模型的条件下测得的。
如果你不是土豪,只有一张显卡,进行深度学习运算的同时,显卡也在负责显示器的输出。这会对性能造成多大的影响?
Eric让显卡外接两个显示器,分辨率分别为1080p和1440p,测试结果如下:
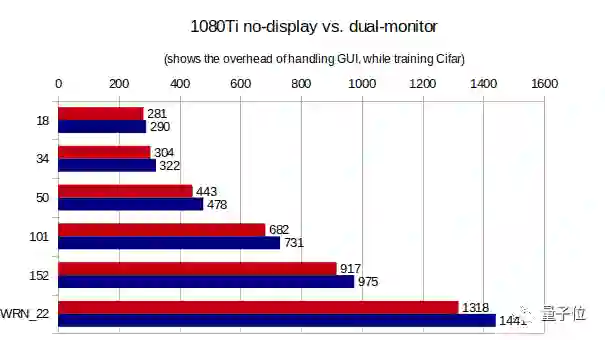
可以看出,外接双屏幕对性能的影响不超过10%。
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
加入社群
量子位现开放「AI+行业」社群,面向AI行业相关从业者,技术、产品等人员,根据所在行业可选择相应行业社群,在量子位公众号(QbitAI)对话界面回复关键词“行业群”,获取入群方式。行业群会有审核,敬请谅解。
此外,量子位AI社群正在招募,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式。
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !


