算法工程师的三观测试

文 | 小戏
编 | 小轶
如果我在谷歌输入“How to improve my machine learning models”,我会得到形形色色花样繁多的提升模型性能的方法。从调参到特征工程,从集成模型到数据增强,琳琅满目,不胜枚举。
可是如果我在这个问题上加一点限定,来问“什么才是最能提升模型性能的方法呢”时,这个问题似乎就从一个“罗列与叠加”的工程问题变成了一个“如何取舍”的艺术问题。

最近,在 Reddit 上,这样一个问题引起了广泛的讨论,提问者发问:“在你的经验里,什么是最能提升一个机器学习模型性能的东西,是调参?特征工程?模型集成?还是其他东西?”
这个问题换言之其实问的是,诚然有许许多多提升模型性能的方法,但是作为一个算法工程师我应该将自己有限的精力更多的投入到哪一部分才能收获事半功倍的效果呢?
让我们暂停一下,来做一个投票,什么是你第一反应下认为一个算法工程师最该关注的问题?(这里简单列举了一点在 Reddit 上讨论里出现的选项,如果选择了其他那么欢迎在评论区留言哦)
![]() 数据为王
数据为王![]()
 数据为王
数据为王OK,如果和 Reddit 上的结果一样,那么应该是“数据”高票当选全场最佳,榜首的回答“It is data, young Jedi. The data”收获了571条点赞。

除此之外,还有许多支持“数据”是最大影响的因素的回答,比如,有人认为“Garbage in, Garbage out”,因此数据无疑是任务执行好坏的源头活水。
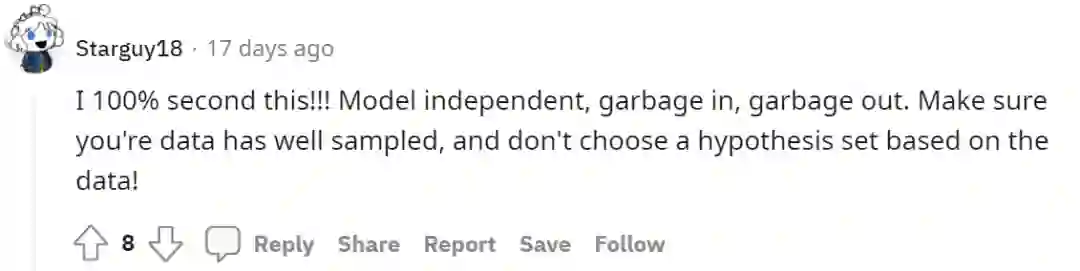
(当然,套用这个句式也可以皮一下“Garbage in, State of the art And Free money out”)
更有十年算法工程师现身说法:
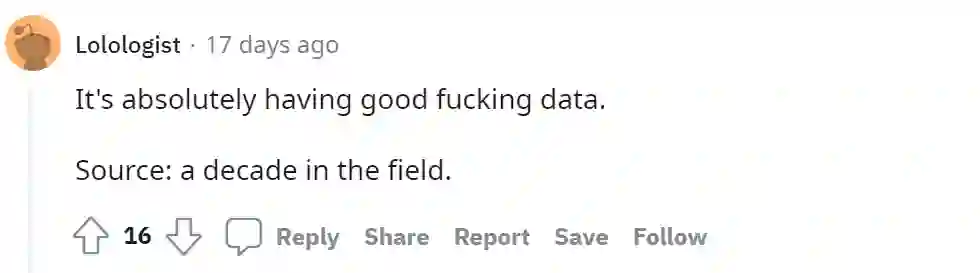
也有人认为将时间投入数据工作的投入产出比是最大的:
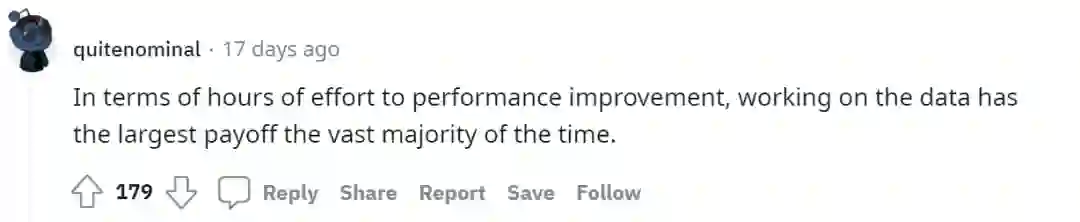
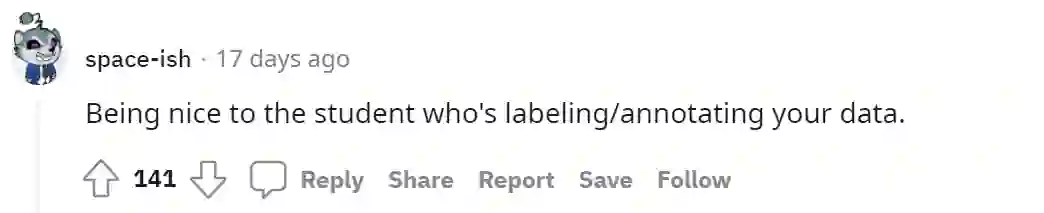
以及还有旁敲侧击从侧面论证数据的重要性,比如善意的提醒大家“善待给你标注数据的学生”
![]() 特征工程
特征工程![]()
有人做了一个经验性的排序。有两个答案都提到,提升模型性能时关注的优先级应该先是数据层面,其次是特征工程,最后才是模型层面,诸如模型类型、调参等。
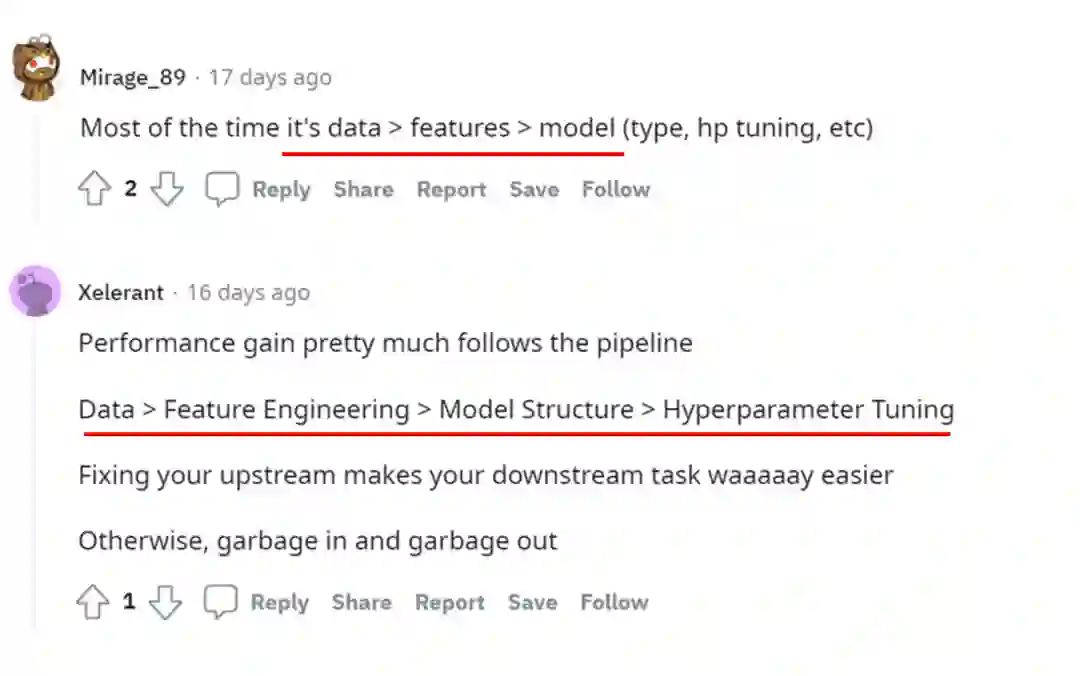
也有人将提升模型性能的过程想象成在扩大数据量级以及缩小模型量级之间找到一个甜点区的过程。
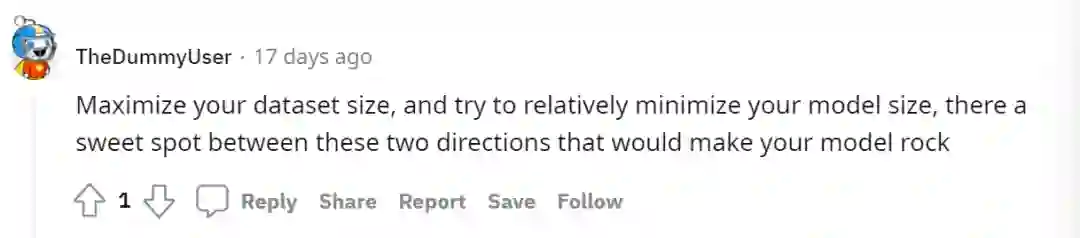
而除了主流的认为数据是最重要的影响因素的声音之外,还有一些其他的答案也十分的引人瞩目。比如,有人投票给了特征工程,认为“特征工程可以得到正确的数据以输入给正确的模型”。
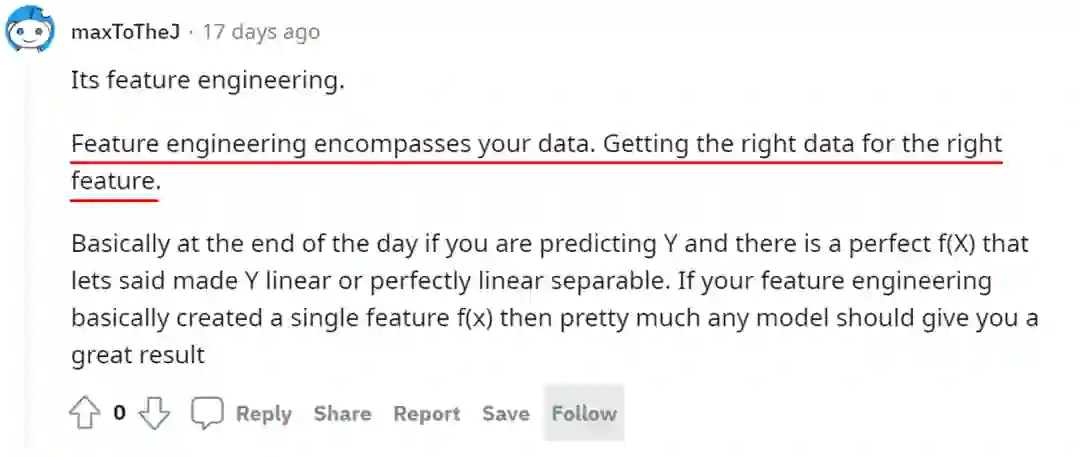
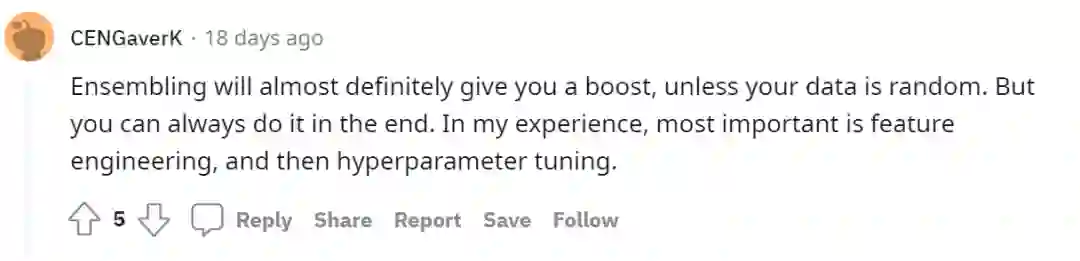
有人强调集成模型一般总会对模型性能带来提升,但他认为最重要的还是特征工程与调参。
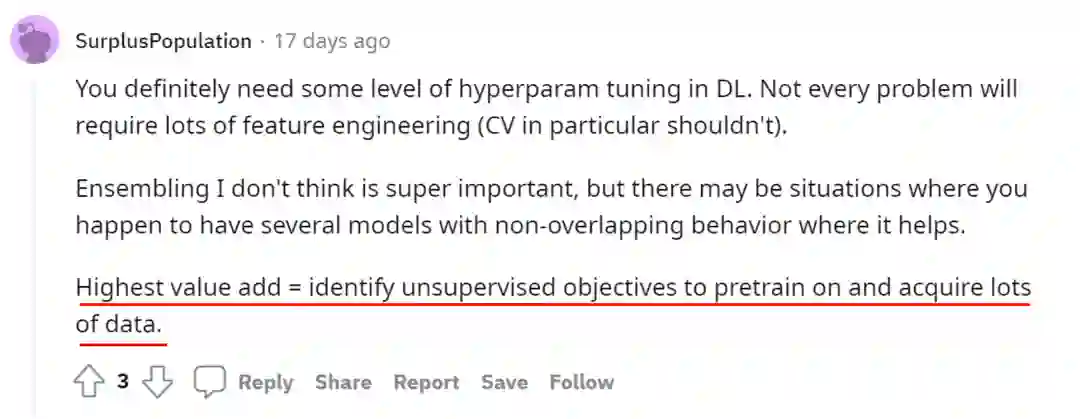
也有人则认为并不是所有任务都要求大量的特征工程,因此强调了在深度学习中预训练的重要作用。
![]() 问题重构
问题重构![]()
除了这些大家都或多或少知道的方法以外,还有人从另一个角度思考问题,指出了“重构问题”或许会更加重要,这个回答认为对问题的定义不同,会对这个问题的求解带来显著影响。
回答的作者提出了一个颇为简单的理论或者说判断准则,作者认为:从原始数据、到数据预处理、到训练得到最终模型,整个过程应该始终沿着“熵”增的方向,这样才能确保得到的结果是可靠的。该作者申明:这里“熵”指的是“whatever you can't measure in a system”。

譬如原始数据是五年的日均气温数据,如果我们将任务定义为“预测未来某天的最高/最低气温”,模型显然是学不出来的,因为原始数据都没有度量“最高/最低气温”。如果我们把任务仍然定义为“预测未来日均气温”,这样“熵”就没有发生改变。
而如果将任务重构为“预测未来的日均气温所处的区间”(即重构为分类问题:是低于-10℃,在-10℃到10℃之间,还是高于10℃)。由于问题变简单了,这样的问题定义更有可能得到好的模型效果。
因此,作者认为“重构问题”直到“正确的定义问题”有时是更加值得付出时间与精力的事情。
当然关于这个经验的判决准则,也衍生出了颇为有意思的讨论,譬如这里的“熵”究竟如何定义?在简单的例子中或许我们可以判断怎么是熵增的定义,那么在海量的数据与众多的特征之下我们应该如何判断熵这个概念等等,如果大家感兴趣的话可以进入原文看看大佬们的讨论。
![]() 其他观点
其他观点![]()
除了这些在不同方法上各抒己见的讨论之外,还有人特别反思了一下在前排整齐划一的“数据”声浪中,其他方法会失去价值吗?显然,数据是没错,但在实际情况中我们有时无法得到更多数据,因此也不应该低估其他方法的价值。
比如一直被排序在最后的模型层面的方法,在一些特殊的领域应用中,将一个 Attention 层放在正确地方上可以带来的收益可能要远大于增加一些无用数据带来的收益。
其实回想AI的发展,里程碑式的进步大多来源于模型的更新,也许正如这个回答里说的一样“可能大多数模型的改变在没有足够好与足够多的数据的支持下不会带来性能的提升,但是一旦这个模型做到了,那么它将会是一个 Game Changer”
而在这些关注数据的回答中,也有人开始反思,我们所谓的数据工作究竟意味着什么?在一些高度专业化的领域场景里,作为算法工程师,我们所做的所谓“创造性”的工作,真的只是不断的搜集更多更好的数据吗?甚至再往上推,我们的所谓更好的更多的标注数据是如何来的?答案很可能是来源于领域内的专家的知识,那么,当这些算法知识与工具的学习成本与门槛下降,一个算法工程师相对于一个懂算法的行业专家的优势何在呢?
关于这些问题的答案,乐观一点有人认为很大程度上领域知识与实际做的算法工作是独立的,我们收到标注好的数据,建立起模型,获得答案。
所谓的数据工作也就是收集更多的数据、使用数据增强技术以及数据清洗等等。尽管对算法工程师来说更好的理解自己处理的问题是必要的,但在某种程度上算法工程师与行业专家拥有不同的劳动分工
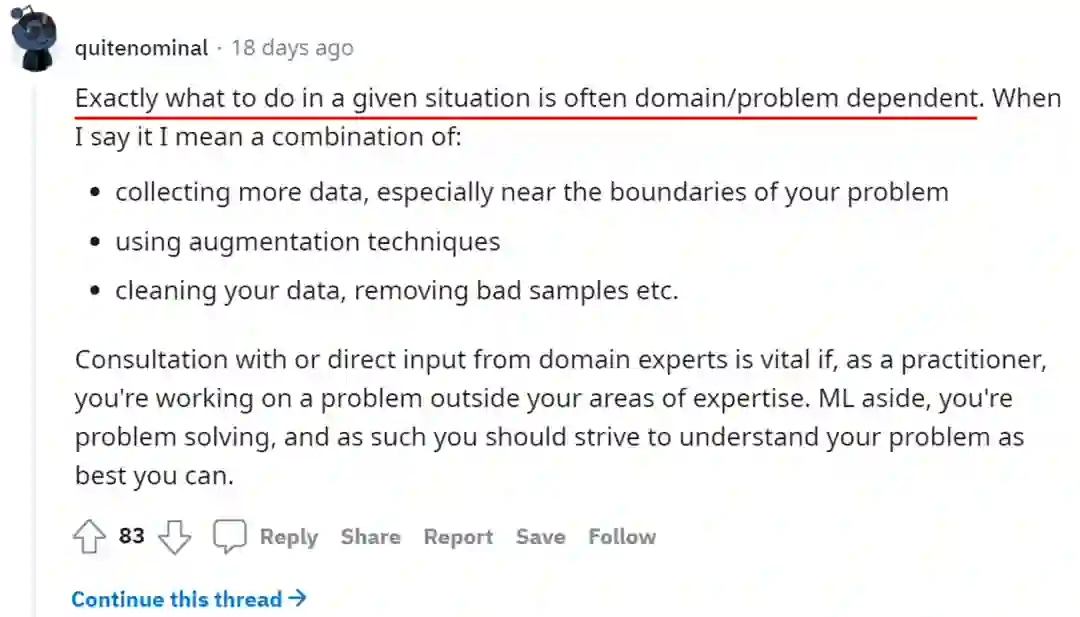
而悲观一点有人认为自己所获得的所谓“更好的数据”几乎全部来源于更好的标注。也因此目前算法工程师的高薪或者说价值其实体现在目前算法还不足够成熟以至于行业专家可以自由的使用这些工具。
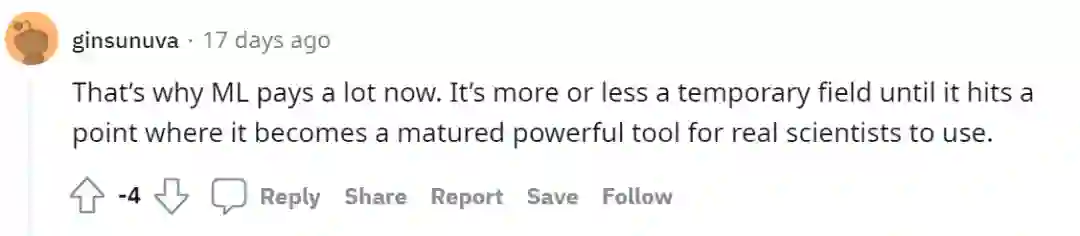
事实上这些讨论可以促使我们去思考,到底什么才是一个算法工程师的核心竞争力,作为一个算法工程师,我们的重心究竟应该落在“算法”上,还是落在这个“工程师”上?
也许如这个回答描述的一样,尽管在一些情况下似乎算法工程师被与机器学习深度学习算法捆绑在了一起,但有时为了解决问题,我们完全可以考虑不使用机器学习的算法。相比于将算法工程师的定义局限在机器学习算法之上,倒不如更加强调一点我们的工程师属性,我们需要利用一些工具去解决问题,无论这个工具是穷举搜索、是数学统计还是机器学习。
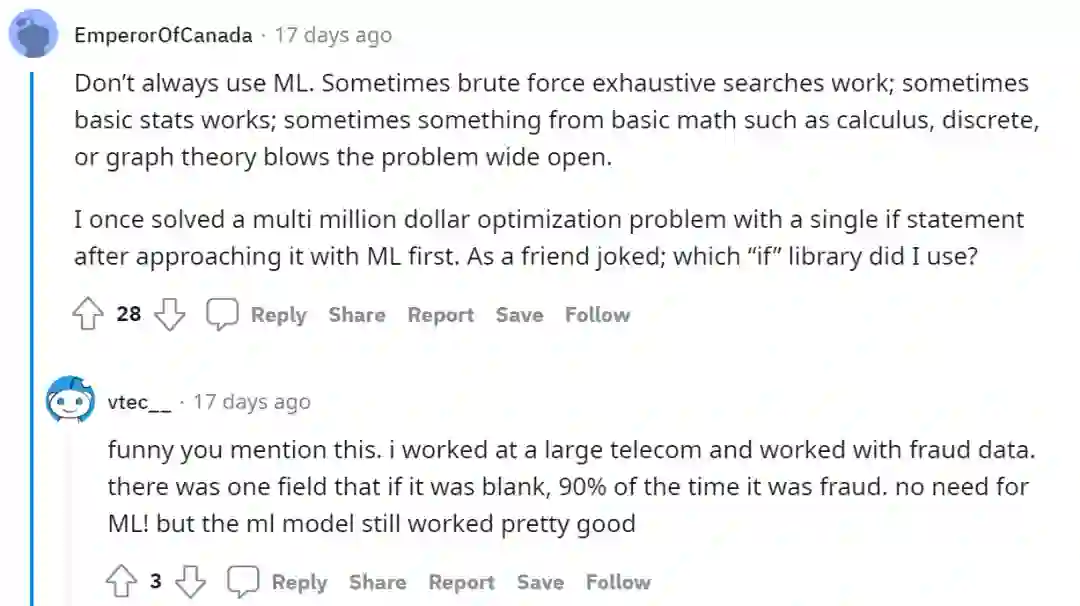
或许诚如前文所述,无论是模型还是数据,都不是解决一切问题的灵丹妙药。作为一名算法工程师,也许我们需要的更多是在特定时间特定资源的背景下去解决问题的能力。
显然,区别于单纯的调参、洗数据甚至是改模型,这都是一个更加“能动”的过程,与其说学习我应该将精力投入在数据、特征还是模型之上,不如去思考在我自己的场景之下,如何去选择合适的工具去解决面对的问题。而关于这个问题更加微观一点的答案大家可以参看卖萌屋之前的这篇文章《惊了,掌握了这个炼丹技巧的我开始突飞猛进》。

![]() 一些感想
一些感想![]()
最后,在管理学领域有一个经典的案例,工厂的机器发生了故障,当我问为什么机器会故障时,我可能会得到因为一颗螺丝钉弹出来了的答案,而当我再深入去问为什么这颗螺丝钉会弹出来时,我就会得到因为没有加润滑油的答案,而如果我再问为什么会没有加润滑油,那么答案可能将会是因为工人没有定期维护设备,如果再问一个为什么工人不会定期维护设备,那么便可能会归因于我们的管理制度没有要求或给工人以定期维护设备的激励。
在这个案例中,如果我们只问一个为什么,那么面对一颗螺丝钉弹出来这个问题我们可能会无能为力并且无法解决最终只能把它归类于小概率事件,而如果我们不断的追问为什么那么这个问题最终将会变成一个可以用管理手段去解决的问题。
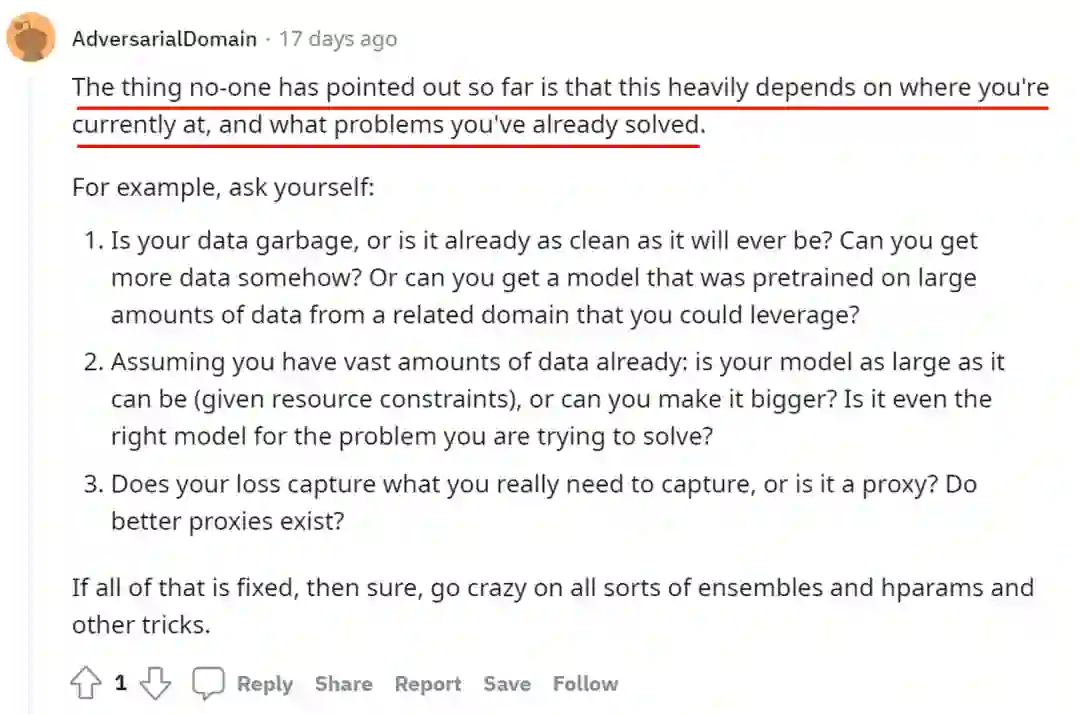
而面对模型调优也一样,当我们面对“我的模型性能不好,如何调优”这样一个问题时,与其一言不发照埋头苦干照着从数据到模型的经验法则挨个试错,不如像上面这个回答一样思考一下“我们当下面临的问题究竟是什么?”,然后根据现状不断调整,是数据的问题归数据,是模型的问题归模型,最终再面对开头这个问题,答案可能会变成“You, young Jedi. It is you. ”

萌屋作者:小戏
边学语言学边学NLP~
作品推荐
 萌屋作者:小戏
萌屋作者:小戏
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群
 后台回复关键词【入群】
后台回复关键词【入群】
