彻底开源、十倍性能的背后:TDengine 核心技术首度公开

曾几何时,“万物互联”还只是人们对未来美好的设想和愿望。但随着物联网产业的快速进化,尤其是受到传统工业数字化转型浪潮的推动,接入物联网的设备总量已经呈井喷趋势。从路灯到电表,从生产线传感器到智能家居设备,物联网正深入到社会生产生活的方方面面,逐渐成为数字化经济时代关键的底层基础设施。
当万物互联的理想一步步走向现实,物联网产业也开始面对一系列前所未有的挑战。其中,缺乏针对海量设备数据的处理工具是众多从业者面临的关键问题:互联网流行的大数据解决方案在物联网领域往往显得“水土不服”,在性能、成本、复杂性、灵活性等方面都很难满足行业期望。由于物联网大数据具备许多独有的特性,物联网产业亟需一种专为自身设计优化的大数据平台技术,解决不断增长的海量数据处理需求。
面对这一市场空白,来自北京的涛思数据开发了自主可控的高性能、可伸缩、高可靠、零管理的物联网大数据平台 TDengine,可广泛运用于物联网、车联网、工业互联网、IT 运维等领域。通过一系列技术创新,TDengine 取得了比通用大数据平台高出 10 倍以上的性能与更低的总体成本,解决了困扰物联网企业的一大难题。开源以来,TDengine 在 GitHub 已收获 14k Star 和 3.6k fork,得到了广泛的关注和好评,成为中国开源软件的榜样力量。
2020 年 11 月 7 日,涛思数据联合 InfoQ 在中关村举办了开发者分享活动,邀请涛思数据创始人与核心开发团队为大家介绍 TDengine 的设计思想与开发经验,帮助更多开发人员和物联网从业者深入了解 TDengine 的优势与技术理念。
相比现有的通用数据库技术,TDengine 可以每秒处理数百万请求,性能提升 10 倍以上。本次活动开场,涛思数据创始人陶建辉为与会者深度解析了 TDengine 达到如此高性能背后所做的技术创新。

就本质而言,TDengine 的设计目标是一个面向物联网的大数据平台,使用户无需集成 Kafka、Spark、Redis 等额外的解决方案,从而降低开发和维护成本。另一方面,TDengine 的轻量化特性(完整安装包 2MB 左右)也可以在边缘侧代替 SQlite,并提供了后者不具备的数据保留策略、流式计算、采样等功能。TDengine 还可以对接 Kafka、组态软件、Python 等语言和技术应用,实际使用中非常灵活。
TDengine 之所以能够实现极高的性能,是因为产品充分利用了物联网大数据的十大特性:1)时序;2)结构化;3)采集点数据源唯一性;4)数据较少更新 / 删除;5)数据多按日期删除;6)写操作为主,读操作为辅;7)数据流量平稳;8)数据包含统计 / 聚合等实时计算操作;9)数据多按指定时间段和区域查找;10)数据量较大。TDengine 从设计之初就针对上述特性专门优化,为物联网场景量身定制。另一方面,TDengine 的代码库完全自主编写,不包含任何第三方库,因而可以在优化层面做到极致。
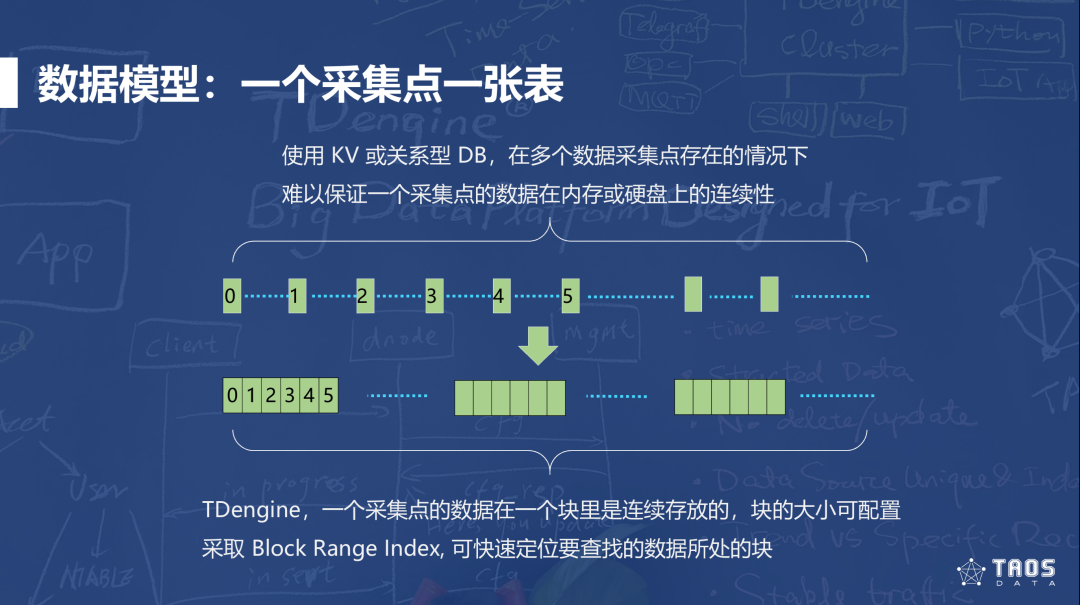
物联网传感器采集的数据都是符合时间顺序的,针对这一特性,TDengine 创新地改变了数据模型,引入“一个采集点一张表”的模式和分块连续存储,从而简化了单点的数据添加操作,加快了数据的插入和查询速度。
在写入流程方面,TDengine 将每个传感器当作一个消息队列,在内存中先进先出,保证新采集的数据都在内存中。数据库则按时间段分区,可以快速定位读取历史数据。这样的模型还利于多级存储,通过时间段区分数据热度来降低存储成本。

为了解决新模型带来的数据表数量过于庞大的问题,TDengine 还引入了“超级表”的理念,用超级表来描述数据的各个类型,为数据表加上了带有静态属性的标签,便于众多采集点的高速数据聚合查询。超级表将时序数据和标签数据分离存储,可以大幅节约存储空间,实现全内存高速存储和查询。由于标签可以事后增删改查,因此很适合处理历史数据和多维分析。TDengine 的数据订阅功能支持表 / 超级表订阅,后者还可以实现条件过滤。最后,TDengine 还通过数据订阅支持边云协同,可实现多级结构。
在后续开发计划中,TDengine 还将在数据采集侧提供更多连接器,在数据分析侧无缝对接各种可视化 /BI 工具,并提供事件驱动的流式计算功能。TDengine 还将持续为各行业提供特有的分析函数,例如电力行业的截面数据、化工行业的特殊函数等等,为更多应用场景提供高度优化的解决方案。

2020 年 8 月发布的 TDengine 2.0 是一次重大更新,引入了大量全新特性。陶老师的分享之后,涛思数据联合创始人关胜亮介绍了 TDengine 2.0 集群的设计思想与工作机制。
TDengine 2.0 的关键特性是采用了 FQDN(完全限定域名)来区分物理和数据节点。物理节点是独立的计算机,而数据节点是前者上的实例,包含许多虚拟节点。通过多个虚拟节点,TDengine 可以将计算资源和数据分片在很多异构机器上。此外,特定虚拟节点还会充当管理节点。
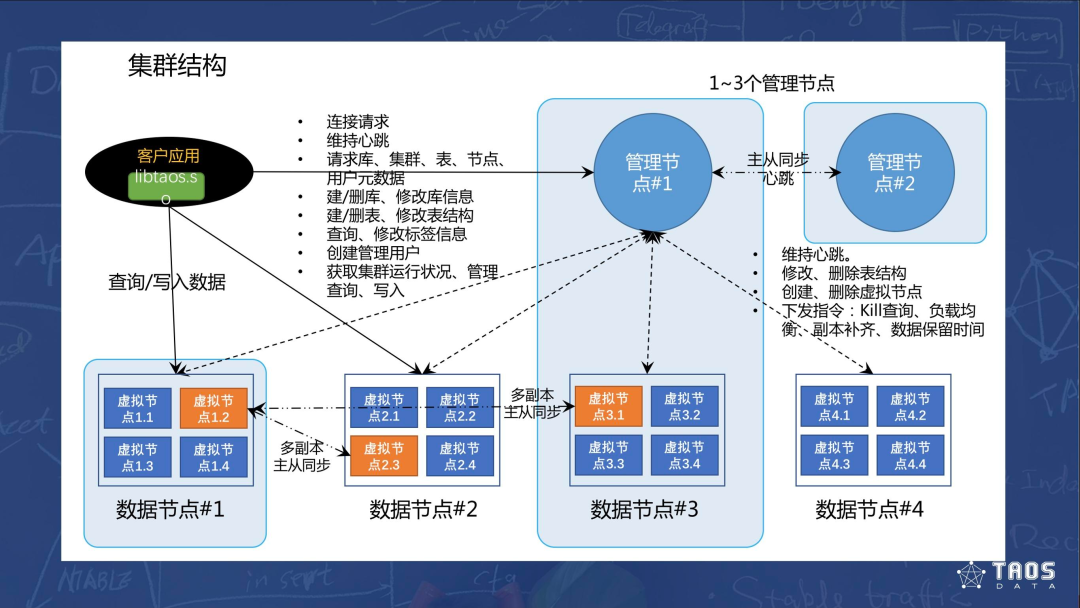
在上述结构中,心跳负责维持管理状态,客户端需要查询 / 写入时则从管理节点获取虚拟节点的路由信息,然后找到对应的数据节点获得服务。不同节点之间的数据采用主从复制模式,通讯则采用 TCP/UDP 混合模式。

由于数据节点实现了虚拟化,就可以将节点数据根据需要分散在不同物理机器上,以防止数据过热、倾斜并提升可靠性等等。当数据在不同节点有多个副本时,通过主从选举的方式选出主节点。在不同节点之间的数据复制默认为异步,以显著提升复制速度。但平台也针对安全性需求较高的场景提供了同步复制选项。出现数据不同步的问题时,平台还提供了数据恢复的机制。
TDengine 的数据分片是基于虚拟节点(Vnode)的,每个表只进入一个虚拟节点,每个虚拟节点则包含多个表。新建虚拟节点时,系统会自动选择负载较低的物理机器创建节点。每个虚拟节点大约维持在一万表左右以实现最佳性能。管理节点则根据各虚拟节点的负载状况进行实时打分,并根据打分情况实施负载均衡。由于分片策略是在表建立时确定的,因此可能存在多个热点表同时进入单个虚拟节点的情况,造成节点过热,这是目前存在的设计缺陷。不过由于数据表数量较多,因此这种情况出现的几率较少。在数据负载均衡调整时,通过副本动态增加和减少可以持续提供服务,防止中断。

健壮性层面,引擎会严格保证异步或掉线节点不能提供服务,并会在数据同步和查询时校验每个数据块,保证数据完整性。
存储和压缩技术是数据科学中的关键环节,优秀的大数据平台必须搭配优秀的存储算法。关胜亮分享结束后,涛思数据联合创始人程洪泽讲解了 TDengine 的存储和压缩算法技术细节。
如前所述,TDengine 主要针对时序数据进行优化设计。有的时序数据会长时间固定,有的会存在变化趋势,还有的会有一定波动范围;此外,各种数据都可能会产生跳变异常。针对这些特性,TDengine 采用单采集点单张表、数据连续存储和 BRIN 索引方法。由于数据分片的基础是虚拟节点,因此很容易利用虚拟节点实现多核并发加速。同一个虚拟节点内的数据按时间分区,同一时间段数据存放在同一文件内,这样可以更好地适应按时间段查询和删除的操作。
TDengine 针对时序数据的特点,专门研发了 TSDB 存储和查询引擎。TSDB 存放了虚拟节点中表的 META 信息以及时序数据(采集信息),后者以行和列两种结构存储。META 包括表 / 超级表的 SCHEMA、子表 TAG 值、TAG SCHEMA 和子表 / 超级表的从属关系。META 操作先在内存中进行,最后序列化并写入硬盘。
META 数据根据子表的第一个 TAG 值建立一个内存索引,而虚拟节点只对 TAG 的第一个值索引,因此速度最快。META 数据写入内存时会同时生成序列化记录,以 append only 形式存储到内存 buffer。内存数据达到一定量后触发落盘,更新的序列化 META 数据以 append only 形式写入硬盘 META 文件。
TSDB 内存中的时序数据为行存储,因而支持以 append only 形式添加 buffer,从而充分利用内存资源,有利于压缩。落盘时,时序数据会转化为列存储,维护 BRIN 索引,引入 LAST 文件和 SUB-BLOCK 机制处理文件碎片化。
TSDB 启动时会事先分配一个 BUFFER POOL 作为写入缓冲,缓冲区块大小和个数可配,区块个数可修改。META 数据和采集数据从缓冲块申请写入空间,写入引擎向 BUFFER POOL 申请缓冲区块,写满的缓冲区块占总缓冲区块的三分之一时触发落盘操作。落盘时,缓冲区块中的数据写入到 META 等文件中,落盘结束后缓冲区块归还给 BUFFER POOL,形成循环机制。
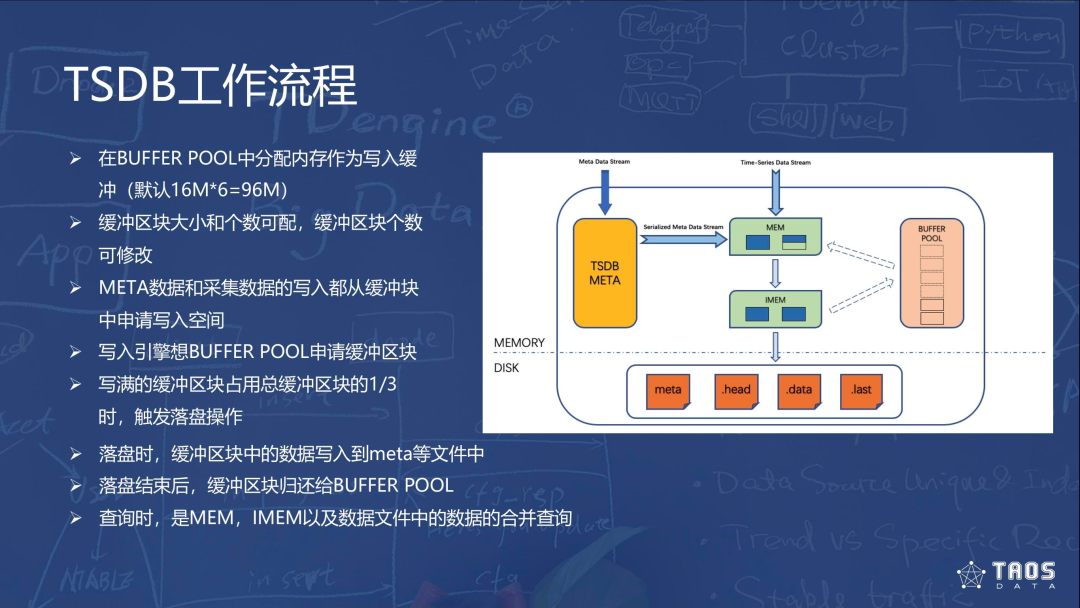
查询时需要查询 MEM、iMEM 以及对硬盘的文件数据进行合并查询。时序数据有一定的乱序情况,如果由 LSM 来处理会有大量的文件合并。为了避免这个问题,TSDB 将标签数据和时序数据分离存储。但由于硬盘上只对时间戳做了索引,对非主键没有做索引,因此非主键的查询和过滤效率相对较低;由于硬盘是列存储,为提升压缩效率就需要足够的数据量,所以这对内存也有一定的要求。
压缩算法方面,TDengine 对于不同的数据类型采用不同的压缩算法,有三种压缩设置。首先是无压缩;然后是一级压缩,根据不同的数据类型进行压缩;二级压缩在不同的列进行压缩后,用通用的压缩算法进行压缩。
TDengine 使用的压缩算法包括 DELTA-OF-DELTA、ZIG ZAG Encoding 等。相比很多数据库来说,TDengine 的列存储和二级压缩特性使其对于时序数据能有很大的压缩效率。
作为国内开源软件企业的佼佼者,涛思数据很早就形成了基于 GitHub 的完整 CI/CD 流程,在长期的实践中积累了丰富的经验。在本场活动的最后,研发工程师刘溢清向与会者介绍了涛思数据总结出的 CI/CD 最佳实践。
今天的软件产业呈现开源、全球化和高度协作的特征,同一款软件可能有很多来自世界各地的开发与贡献者。从 0.9^5=0.59 这一公式来看,如果开发过程中有 5 个环节,都只做到 90 分,那么整个流程的成绩就要下降到 59 分,这是非常显著的累积效应。为了消除不同开发人员的个体影响,软件开发流程应该高度信任 CI/CD,确保流程质量不打折。
在涛思数据,平均每天需要处理 8 次推送请求,目前总共有 858 个测试用例,PR 总量达 2558。为了解决所有这些测试需求,涛思数据通过 CI/CD 解决了四大问题:
实时发现代码错误并报警,帮助开发人员快速修正错误;
无人工干预,减少人为错误的出现几率;
自动生成代码质量报告,帮助开发人员检查动态开发质量。静待代码质量则使用静态检查工具;
自动生成各模块版本标识。
在涛思数据,开发团队以 GitHub 为 CI/CD 的核心平台,并使用 Travis 和 Appveyor 分别负责 Linux 和 Windows 版本的测试。全量测试和交付由 Jenkins 完成。COVERALLS 主要保证代码覆盖率。
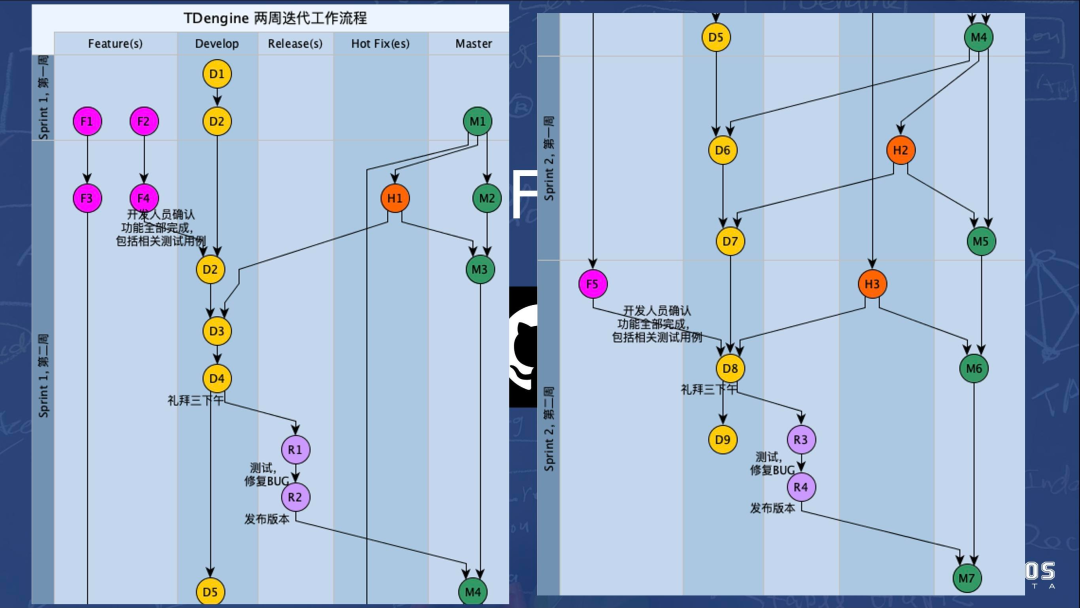
团队现在每两周发布一次版本并做更新。开发流程主要分为两部分:第一部分针对新特性,新特性合并完成后,在第二周周三下午拉一个分支测试并修复,之后发布新版本,并合并到 master 分支。当用户在 M1 版本发现问题时,团队就要对这个分支进行问题修复并交付给用户,同时合并到 master 分支来保证代码的一致性。
每当提交代码后,Windows/Linux 版本需要分别通过 Appvayor 和 Travis 做简单的编译和测试,两项通过以后再由开发人员合并代码,保证代码中的错误可以第一时间得到修复。
由于公司测试用例较多,因此引入了 Jenkins 应对全量测试需求。Jenkins 可以自由化部署,没有运行时间和资源限制,大家可以根据自己的服务器来配置。Jenkins 跨平台很方便,对各种 OS 和指令集平台都有很好的支持。它还有丰富的插件,可以简化很多流程。
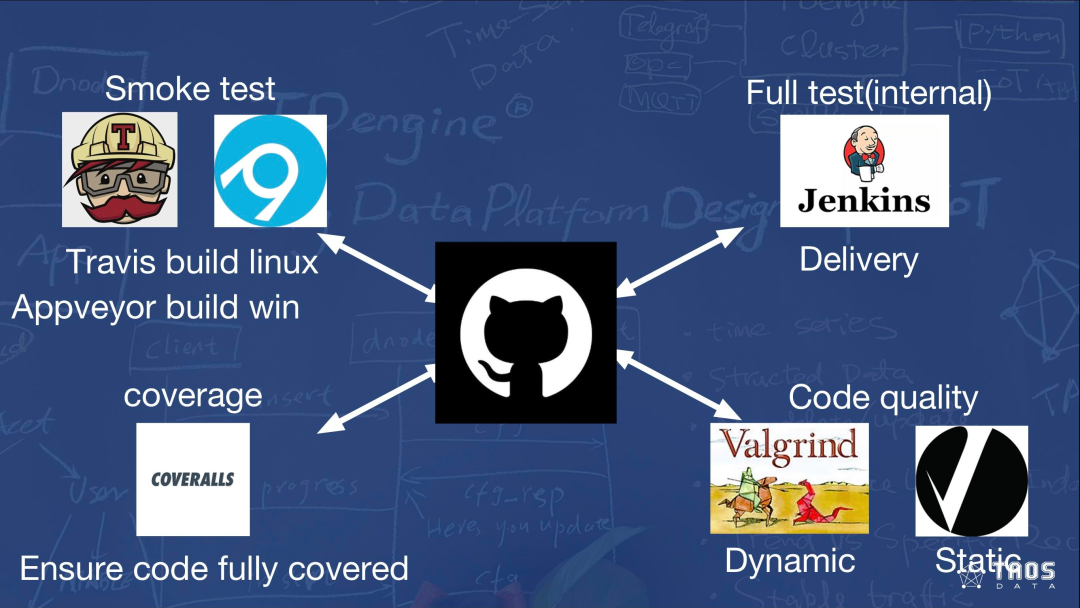
整个 CI/CD 流程来看,分为预编译、编译工作、全量测试和版本发布几大环节。每天下班以后会持续做全量测试。COVERALLS 检查代码覆盖率,目前 TDengine 的覆盖率是 77.43%,还有一些提升空间。Valgrind 监测内存泄露并做代码监测,Coverity Scan 提供整体反馈。
通过这一套 CI/CD 体系,涛思数据获得了明显的生产力提升:
检查代码的时间成本下降到了过去的七分之一。
case 覆盖率提升两倍。
代码从提交到发布的速度比之前快六倍。
除了几位老师的高质量分享,本场活动还特别设置了两个颁奖环节。首先是涛思数据举办的 Hive MQ 插件开发竞赛,大赛旨在奖励大数据时代的前沿探索者,来自大连的谭雪峰荣获大奖。
第二个奖项是 TDengine 的最佳贡献奖,颁发给 TDengine 的两位社区优秀贡献者,以此感谢开源社区为 TDengine 的发展作出的努力和支持。在颁奖环节中陶老师介绍,TDengine 的社区贡献者已有将近 50 人,做出了很多非凡的工作。作为年届 50 的老一代程序员,陶老师希望更多开发者参与开源社区的建设活动,为软件产业的开放合作贡献自己的力量,证明自身的价值。

自 2017 年成立以来,涛思数据已经在物联网大数据领域打响了自己的知名度,获得了业内多方的赞誉和认可。通过创新技术思想与开源包容的理念,TDengine 有望在万物互联时代成为物联网数据的解决方案标杆。如今,涛思数据得到了重量级资本的支持,正走在快速扩张的发展道路上。陶老师也代表涛思数据发出号召,希望更多优秀人才加入涛思数据,在研发、测试、社区运营、商务、售前、售后技术支持等岗位发光发热,并携手广大社区贡献者一起,与涛思数据共赢精彩未来。
关注公众号,后台回复“1107”获取本次 TDengine 技术开发日活动视频和 PPT~

点个在看少个 bug 👇



