Docker 存储选型,这些年我们遇到的坑
戳蓝字“CSDN云计算”关注我们哦!

技术头条:干货、简洁、多维全面。更多云计算精华知识尽在眼前,get要点、solve难题,统统不在话下!
随着Docker 容器技术的不断发展和业内对Docker 的使用不断深入,大家已经不再满足于对Docker 的基本使用。 把玩Docker 多年的老司机应该或多或少都会遇到过一些Docker 存储方面的问题,比如因为宿主机文件系统和Docker存储类型不兼容引起的问题,或者使用AUFS 出现文件复制慢等问题,存储问题每次遇到都要心里一紧。
Docker 存储类的问题在排查上往往比较复杂,有过Docker 存储类问题排查经验的同学应该都有体会。每当遇到此类的问题笔都有一股想找Docker 公司理论的冲动,不是说好的 ” build once run anywhere” 吗?
笔者自己所在的团队也曾数次遇到关于Docker 存储的问题,每次团队内的成员基本都是避之不及,生怕会由自己处理(怕掉坑里)。为此笔者专门理了一下Docker 存储类的问题的复杂点,发现这里面很大一部分其实是因为问题处理人员对Docker 的存储类型、存储原理不了解造成的,为此我们专门整理了一份Docker 选型方面的避坑指南,供大家参考,希望可以帮助到大家。
Docker 存储概述
我们知道,每个Docker 容器里面都有一个自己的文件系统,Docker 在运行容器时需要进行文件系统的创建,这样rootfs 才能进行挂载。
Bootfs 也称引导文件系统,位于Docker 镜像和Docker 容器的最底层。bootfs 中主要包含两个部分:bootloader和kernel,bootloader 用于引导加载内核,当内核加载到内存中后bootfs 的使命就完成了,接下来bootfs会被卸载掉。rootfs 中包含了一些linux中标准的目录和文件,包括:/dev/设备文件目录、/proc/进程信息目录、/bin/二进制文件目录、/etc/配置文件目录等。
众所周知,Docker 存储的核心是镜像的分层机制,镜像分层的一大好处是镜像之间可以进行继承,也正是因为这个特性我们可以借助基镜像定制化的构建我们需要的应用镜像。
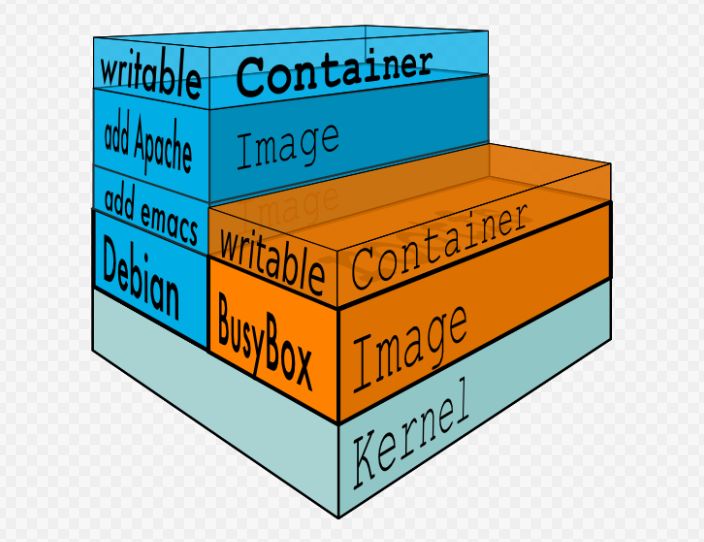
Docker官方在版本1.10 时引入一个新的可寻址的存储模型,了解过Docker 存储这方面的同学应该知道在Docker1.10之前Docker 镜像的管理是使用的随机的UUID管理,Docker1.10之后已经使用安全内容hash取代了随机UUID进行镜像的管理。同时,考虑到已经有很多用户在使用UUID的镜像管理方式,Docker 官方专门针对这个改动提供了迁移工具,帮助大家将已经存在的镜像迁移到新的模型之上。
我们知道,一个有众多版本的镜像的所有镜像占据的空间可能比单个版本的镜像占用的空间多不了多少(比如一个nginx镜像有500MB,根据配置的不同我们保存了10个版本,10个版本占用的空间一般和一个nginx镜像占用的空间接近,远低于10个镜像空间的总和)。多个版本占用的空间之所以没有明显增加是由于Docker 容器、镜像可以共享底层的基础文件系统层,虽然镜像的个数很多,但是他们占据的共享镜像层在磁盘中只存在一份,每个容器只需要在自己的最上层加上一个自己独有的可读可写层就可以正常使用了,因为这种存储机制的存在大大提高了Docker 镜像存储的效率。这种模式的主要机制就是分层模型将不同的目录挂载到了同一个虚拟文件系统之上,通过下面这个图可以很好的理解这种模式。
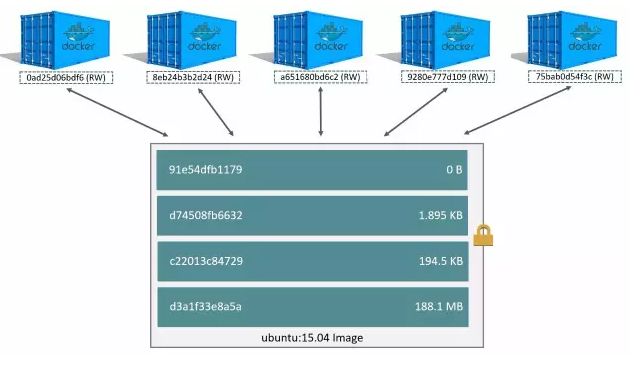
上文中我们提到docker 的镜像是分层的,但我们没有说这部分的功能具体是由哪一部分实现的。其实不仅分层镜像,包括每个Docker 容器的可读写层都是由Docker 的存储方式负责管理的。
接触容器比较早的同学可能还记得,Docker 在最初的时候只能在支持AUFS的文件系统的操作系统上运行,而当时在众多操作系统中Ubuntu 已经率先提供了对AUFS的支持,因此最开始玩Docker 的同学使用的linux发行版都是Ubuntu系列的发行版。
但是由于AUFS 未能加入Linux 内核,成为linux发行版的标配,因此为了寻求兼容性和扩展性,Docker 在内部通过graphdriver 这样一种机制以一种可以扩展的方式实现了对不同文件的系统的兼容(实际使用中可能发现有些版本还是会存在一些兼容性的问题)。
Docker 目前支持的驱动类型包括:AUFS、Device mapper、Btrfs、OverlayFS和ZFS(较新),这些驱动存在一个共同点,那就是都使用了写时复制技术。下面我们逐个看下这种存储驱动的特性以及在使用中可能会遇到的问题。
AUFS 存储驱动
1. Union File System
UnionFS(Union File System简称)是一种为Linux、FreeBSD 等操作系统而设计的,可以把其他文件系统联合到一个挂载点的文件系统服务。
简单说来联合文件系统就是将不同的目录挂载到同一个虚拟机文件系统下的文件系统。这种文件系统的一大特点就是可以一层层的叠加修改文件,除了最上面的一层之外无论底下有多少层都是只读的,只有最上层的文件系统是可以写的。
UnionFS 使用分支(branch)对不同文件系统的文件(包含目录)进行覆盖,从而最终形成一个单一的文件系统,也就是我们直接操纵的文件系统。UnionFS 使用的这些分支要么是只读的,要么是读写的,分支的这种特性决定了当我们对虚拟后的联合文件系统中写入数据的时候,数据被写到了一个新的文件中。这样看来我们似乎可以操作这个虚拟文件系统中的任何的文件,但其实我们并未改变原来的文件,导致这种情况出现的原因是UnionFS使用了写时复制(copy-on-write)这样一种资源管理技术。
写时复制也称隐式共享(此名称可能较少见),写时复制是一种可以对可修改资源实现高效复制的资源管理技术。它的核心的设计思想是,如果一个数据资源是重复的,没有做过任何的修改,这个时候不需要创建新的资源,而是让新旧实例都去共享这仅有一份的资源。当需要对资源进行数据的增加或者修改的时候才会进行新资源的创建。从上面的写时复制的原理中我们即可看出,通过这种资源共享的方式我们可以省掉对未修改资源的复制,从而为我们带来效率的提升。
2. AUFS
AUFS 全称为Advanced Multi-Layered Unification Filesystem,是一种联合文件系统,是一种文件级的存储驱动,出于对可靠性和性能的考虑,AUFS 对UnionFS1.x 进行了整个的重写,并且在重写过程中还引入了一些新的功能特性,比如对于可写的分支添加了负载均衡的功能。不仅仅是AUFS借鉴UnionFS,UnionFS也会去借鉴AUFS,比如UnionFS 2.x中借鉴了AUFS的一些实现。
有些同学可能会问,存储驱动类型这么多,为什么Docker 最开始选择AUFS作为自己的存储驱动? 笔者个人认为是因为AUFS具备的以下几个优势:快速启动容器、高效利用存储、高效利用内存。
当我们需要对一个文件进行修改时,AUFS 会为目的文件创建一个文件副本,具体是从包含该文件的只读层使用写时复制技术将文件复制到最上面的可写层。需要注意的是,当我们修改完文件之后修改后的文件是保存在最上层的可写层的,下面的只读层的文件并未被修改。
3. Docker 对AUFS的使用
在Docker 体系中,我们熟知的最上层的读写层就是容器,除最上层之外的下面的那些层就是镜像。
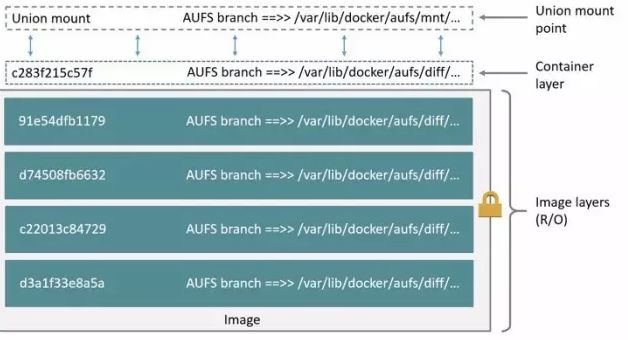
4. AUFS 避坑
了解AUFS 存储驱动的优势和劣势可以帮助我们更好的对存储驱动进行选型,同时也可在很大程度上帮助我们排查AUFS 存储驱动方面相关的问题。
好,我们先看下AUFS 作为Docker 存储驱动的优势,以便选择更合适的使用场景:
(1) 得益于AUFS 高效的目录挂载机制,Docker 可以很快的创建容器。AUFS 的读写效率很高,和直接在Docker 容器所在宿主机上的读写接近。和虚拟服务器相比,AUFS读写性能优于KVM,包括顺序读写和随机读写两个方面。除此磁盘的高效使用之外,Docker的AUFS存储驱动也可以对内存进行非常高效的使用。
(2) 相比一些出现较晚的Docker 存储驱动,Docker AUFS存储驱动性能相对比较稳定,并且AUFS目前已经有很多的生产部署实践,另外AUFS 在社区生态方面也得到大量的支持。
下面我们再看下AUFS 作为Docker 存储驱动存在的坑:
(1) AUFS 是Docker 第一个支持的存储驱动,但AUFS 目前仍未加入linux系统的内核主线,比如RedHat系列(包括CentOS)目前还无法直接使用AUFS。
(2) AUFS 目前不支持重命名的系统调用,这个会导致我们在执行拷贝和解除连接时失败。
(3) 我们知道AUFS 文件系统中每个源目录都会对应一个分支文件的挂载过程其实就是对不同分支的一个联合操作,当出现相同内容的不同分支时会进行上下层的覆盖。但是当我们写入大文件的时候,比如大的存储日志信息的文件或者存储数据库数据库的文件,动态挂载多个路径的存在会使分支越来越多,进而会导致文件查找的性能越来越差,尤其是当文件存在于较低的层时,问题会更加严重。
小结:AUFS 存储驱动建议在大并发但少I/O的场景下进行使用。
Device mapper
1. Device Mapper 原理
部署Docker 环境的时候一般都会要求Linux 内核版本最低为3.10,似乎Docker 运行需要的存储驱动是从linux 内核3.10 这个版本才进行引入的,但实际早在linux 内核版本2.6的时候DeviceMapper就已经被引入。
DeviceMapper 作为内核的一部分主要提供了逻辑卷管理和通用设备映射的功能,为了实现系统中的块设备管理提供了一个高度模块化的内核的架构。
在深入了解DeviceMapper 之前我们需要先了解下DeviceMapper 中三个比较重要的概念:Mapped Device、Mapping Table和Target Device。
Mapped Device 并不是一个实际的设备,并没有实际的物理硬件和它一一对应,相反Mapped Device 是一个逻辑上的抽象设备,简单说来,可以将其理解成为内核向外提供的逻辑设备。Mapped Device 通过另一个对象Mapping Table 和Target Device 建立映射关系。
Mapping Table 中包含Mapped Device 逻辑的起始地址、地址范围以及Target Device 代表的物理设备的地址偏移量和Target 的类型信息,需要注意的是地址和偏移量单位为扇区,即512字节。
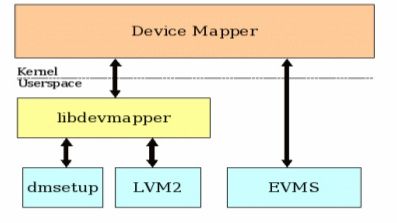
Target Device 简单说来就是Mapped Device 这个逻辑设备所映射到的一个物理设备。
Device Mapper 是块级别的存储驱动,所有的操作都是对存储块进行直接的操作,这方面和上文中讲的AUFS不同(AUFS 是文件级的存储,所有的操作都是对文件进行直接的操作)。
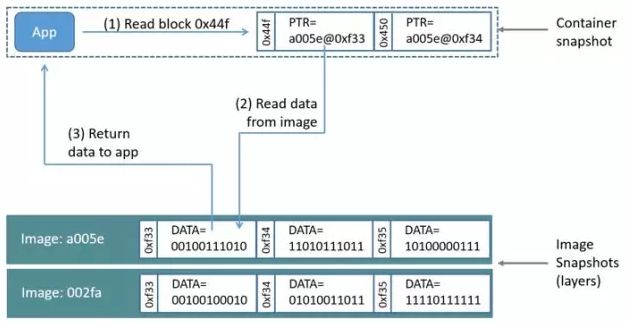
在使用Device Mapper 时,Device Mapper 会先在块设备上创建一个资源池,然后接下来会在新建的资源池上添加一个没有文件系统的基本设备,我们所有的容器镜像都是这个设备的快照,我们的Docker容器是镜像的快照。因此我们在Docker 容器中看到的文件系统系统其实是Device Mapper 资源池上基本设备上的文件系统的快照,实际上并没有为我们的Docker 容器进行空间的分配。
理解Device Mapper 的工作机制,还需要明白用时分配。用时分配是指,当我们需要写入一个文件时,我们需要为新文件分配新的存储块并,分配好存储块后才能进行数据的写入。
当我们需要去修改容器中已经存在的文件时,这个时候Device Mapper 借助写时复制技术为容器分配存储块空间,然后Device Mapper 将需要修改的数据拷贝到容器快照中前面新建的块里面,之后才会对文件中的数据进行修改。
值得一提的是,Device Mapper 存储驱动默认会创建一个100GB 文件,包含Docker 容器和Docker 镜像,需要注意的默认情况下每个容器的大小都被限制在10GB的卷以内,但可以进行自定义的设置,具体结构如下图:
另外Docker 存储驱动的信息可以通过命令docker info 或者dmsetup ls 进行查看:
[root@localhost ~]# docker info
Containers: 11
Running: 0
Paused: 0
Stopped: 11
Images: 6
Server Version: 1.10.3
Storage Driver: devicemapper
Pool Name: docker-8:3-404820673-pool
Pool Blocksize: 65.54 kB
Base Device Size: 10.74 GB
Backing Filesystem: xfs
Data file: /dev/loop0
Metadata file: /dev/loop1
Data Space Used: 12.51 GB
Data Space Total: 107.4 GB
Data Space Available: 82.06 GB
Metadata Space Used: 10.18 MB
Metadata Space Total: 2.147 GB
Metadata Space Available: 2.137 GB
Udev Sync Supported: true
Deferred Removal Enabled: false
Deferred Deletion Enabled: false
Deferred Deleted Device Count: 0
Data loop file: /var/lib/docker/devicemapper/devicemapper/data
WARNING: Usage of loopback devices is strongly discouraged for production use. Either use `--storage-opt dm.thinpooldev` or use `--storage-opt dm.no_warn_on_loop_devices=true` to suppress this warning.
Metadata loop file: /var/lib/docker/devicemapper/devicemapper/metadata
Library Version: 1.02.107-RHEL7 (2016-06-09)
Execution Driver: native-0.2
Logging Driver: journald
Plugins:
Volume: local
Network: null host bridge
Kernel Version: 3.10.0-327.36.1.el7.x86_64
Operating System: CentOS Linux 7 (Core)
OSType: linux
Architecture: x86_64
Number of Docker Hooks: 2
CPUs: 4
Total Memory: 1.781 GiB
Name: localhost.localdomain
ID: V7HM:XRBY:P6ZU:SGWK:J52L:VYOY:UK6L:TR45:YJRC:SZBS:DQRF:CFP5
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
Registries: docker.io (secure)
[root@localhost ~]# dmsetup ls
docker-8:3-404820673-pool(253:0)
2. Device Mapper 避坑
(1) Device Mapper 优势
Device Mapper 的写时复制机制的最小操作单元为64KB,块级无论是大文件还是小文件都只需要复制需要修改的块,并不复制整个文件,相比aufs存储驱动和overlay存储驱动的整个文件复制Device Mapper 的效率更高。
相比上文中我们说过的AUFS存储驱动,Device Mapper 在文件系统兼容性方面较好,另外DeviceMapper存储驱动只需要一个文件进行存储,基本不会占用文件系统的inode。
(2) Device Mapper 避坑
在内存使用方面,以Device Mapper 作为存储驱动时,启动多少个容器就需要复制多少份文件到内存中,因为Device Mapper 不支持共享存储,当有多个容器需要读同一个文件的内容时,需要生成多个该文件的副本,在较多的容器进行启动、停止的时候可能会出现磁盘溢出的情况。因此如果是容器密度高的业务场景下尽量不要部署到单台主机上。
每个容器每次在写数据时都需要占用一个新的块,由于每个存储块都需要借助存储池进行分配,且写的文件比较稀疏,尽管Device Mapper 的I/O利用率很高,但由于额外增加了VFS 开销导致性能不好。在选择存储类型时需要着重注意下这一点,强烈建议根据自己的业务场景进行压测后再进行选择。
在实际使用中,如果我们为每个容器都进行块设备的分配,当启动多个容器时数据会从磁盘被多次加载到内存中,因此在这种场景下时内存消耗较大,在选型时需要注意。
当选用的宿主机为RHEL系列(包含CentOS)时,需要注意Device Mapper 是RHEL系列下的默认的存储驱动,配置方式分为两种模式:loop-lvm和direct-lvm。其中loop-lvm是默认的模式,loop-lvm 使用操作系统的层面的离散文件来构建精简池。一般情况下生产环境推荐使用direct-lvm 模式,不建议使用默认的loop-lvm模式,经实际测试loop-lvm 的性能很难达到生产环境的要求
小结:Device Mapper 存储驱动更适合在I/O密集的场景下进行使用。
OverlayFS 文件系统
1. Overlay 原理
Overlay 存储驱动的设计和AUFS 非常相似,也是一种联合文件系统,同时也是一种文件级别的存储驱动,但和AUFS不同的是Overlay 只有两层(一个是upperdir,另一个是lowerdir,从二者的名字也可看出,upperdir 代表的是我们的容器层,lowerdir层代表的是我们的镜像层),而AUFS 有多层。相比AUFS Overlay 存储驱动进入linux较晚(Linux 内核3.18之后才进行支持)。
当需要对文件进行修改时,需要借助写时复制从只读的lowerdir 层复制到可读写的upper dir层,然后再在upperdir 层中对文件进行修改,修改完成后的文件最终也是保存在组上面的upper层中。
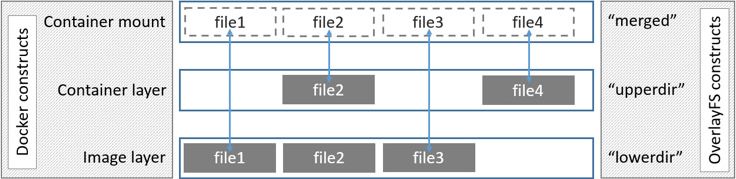
2. Ovrelay 避坑
在说Overlay 使用之前我们先看下它的优点,看下它适合的业务场景都有哪些。
(1) 从性能上来看,Overlay 存储驱动要比Device Mapper 更好,速度更快。在某些情况下Overlay 的速度也比Btrfs存储驱动快。由于Overlay 只有两层,AUFS有多层,因此Overlay在速度上也比AUFS要快,减少操作延时。
(2) Overlay 支持页缓存的共享,这样在多个容器在访问同一个文件时可以共享一个页缓存,从而提高内存使用效率。
下面我们再看下Overlay 在使用时需要注意的问题,注意避坑。
(1) Overlay 存储驱动出现较晚,目前生产环境部署的经验相对较少,实际使用中需要解决的问题可能较多。
(2) 由于Overlay存储驱动是文件级的,因此在对文件进行第一次的操作时需要将目标文件拷贝至最上面的读写层。
(3) 和其他的存储驱动相比,Overlay 消耗inode 较多(我们有个容器云曾经出现过此种情况),尤其是当我们环境中镜像和容器较多时可能会触发这个问题。为了解决这个问题,一般的建议方式是将目录/var/lib/docker直接挂到某个单独的文件系统中,这样在一定程度上可以减少其他的文件对inode的占用。
上面提到的解决方式只是最常用的一种,除了这种方式,我们还有其他的解决方式,如Overlay 版本更换为Overlay2,Overlay2中已经解决了这个问题,在我们不再详细描述。
(4) 除了上面说到的这些问题,Overlay 还存在POSIX的标准问题。Overlay的部分操作目前还不符合POSIX的标准。
(5) 最后需要注意的是Overlay 不支持rename系统调用,因此如果涉及到”copy”、”unlink ”的操作会出现失败的情况。
小结:Overlay 存储适合大并发但少I/O的场景。
Btrfs 文件系统
1. Btrfs 原理
Btrfs 文件系统也称B-tree 文件系统或者B-tree FS,Btrfs 是一种支持写入复制的文件系统,由著名公司Oracle 进行研发,第一个稳定版本于2014年进行发布。Btrfs 文件系统的目标是取代linux中的ext3文件系统。
Btrfs 被很多人称为下一代的写时复制文件系统,和Overlay 相似也是基于文件级别的存储,目前Btrfs已经并入linux内核。
和前面我们讲到的Device Mapper 类似,Btrfs 可以对底层的设备进行直接的操作。
Btrfs 中有两个重要的概念:subvolumes和snapshots,Btrfs 利用subvolumes和snapshots 管理Docker镜像和Docker 容器的分层。
Subvolumes 是指Btrfs文件系统的一部分配置,或者也可称为Btrfs文件系统的子文件系统,借助subvlolumes我们可以将一个大的文件系统划分成若干个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中进行获取,整个过程类似malloc()分配内存空间的过程。我们在使用Btrfs文件系统时,通常为了比较方便的使用设备的空间,Btrfs会将磁盘空间划分成多个块,需要注意的是划分的这些块的空间分配策略可以是不同的,比如,实际使用中我们可能会将一部分的块用来存储元数据,将另一部分的块用来存储我们实际的业务数据。
Snapshots 是subvolumes 的一个实时读写拷贝,其分配单位称为块,一般每个块的大小为1GB。
Btrfs 文件系统将一个文件系统当成一个资源池来进行看待,这个资源池中会有多个子文件系统,我们可以动态的往资源池中进行子文件系统的添加。
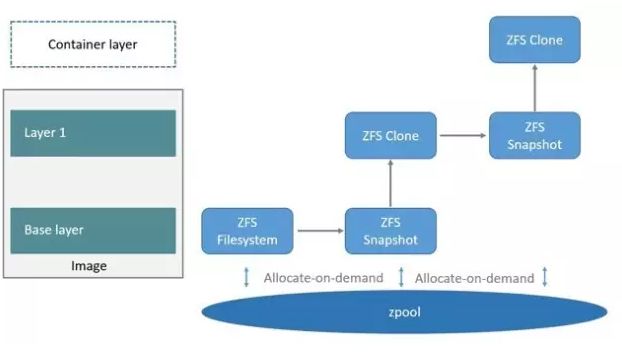
2. Btrfs避坑
先看下Btrfs 的优势和适合的业务场景。
相比我们经常使用的ext4文件系统,Btrfs 文件系统在很多方面都做了改进,比如大家熟知的支持子卷、支持快照,除了这些功能,Btrfs文件系统还内置了压缩和RAID的支持等功能。
相比传统的文件系统,虽然Btrfs 引入了很多非常棒的特性,但它存在的问题也同样的突出。
(1) Btrfs 文件系统未引入页缓存共享的机制,这就导致Btrfs 文件系统不适合在容器密度比较高的场景下进行使用。因为没有页缓存共享,多个容器在访问相同的文件时需要对文件缓存多次。
(2) Btrfs 文件系统中使用的small write 功能导致整个文件系统存在性能瓶颈。
(3) Btrfs 文件系统写数据的方式是journaling,接触过的同学应该知道这种方式会在一定程度上影响顺序写的性能。
(4) 除上面的问题外,Btrfs 还存在一个很严重的问题:碎片化。如果不对碎片进行周期性的清理,碎片化会导致很严重的性能问题。幸运的是,在新版本的Btrfs中已经可以通过mount时指定autodefrag参数来解决这个问题了。
小结:Btrfs 存储不适合在容器密度高的平台上进行使用。
下一代文件系统ZFS
1. ZFS 原理
相比上文中我们说过的文件系统,ZFS 在很多方面做了革命性的改变,它从根本上改变了文件系统的管理机制。
ZFS 文件系统中已经不再使用卷管理,不再需要创建虚拟的卷,因此所有的设备都是直接放到统一的存储池中进行管理的,即用存储池的概念对物理存储空间进行管理。
在容器环境中使用ZFS 文件系统时,会先从存储池中为Docker镜像的基础层分配一个ZFS 文件系统,Docker 镜像的其他层来自ZFS文件系统快照的克隆,当容器运行起来的时候会在Docker 镜像的最顶层生成一个可写层。
2. ZFS 避坑
(1) 虽然ZFS 是下一代的文件系统,但由于相对较新,目前一般不推荐在生产环境中的Docker 使用ZFS存储,可现在测试环境采坑积累经验后再考虑上生产。
(2) ZFS 最初并不是为普通的服务器设计的,而是为Sun Solaris服务器量身打造的,从实际经验来看,如果需要部署在普通的服务器上,建议在正式使用前先压测下内存的使用。
(3) ZFS 有缓存的功能,但并不是适合每一种场景,一般只建议在高密度的场景下进行使用。
小结:ZFS 存储适合PaaS服务密度较高的场景下使用。
存储总结
每种Docker 存储驱动都有自己的适用场景,没有好坏之分,只有合适之分。不同的存储驱动在不同的应用场景下性能不同,例如,AUFS存储驱动和Overlay存储驱动工作在文件级别,因此在内存使用上比较高效,但是在进行大文件的读写时容器层所占据的空间会变的很大,这种场景下就更适合选用在高I/O负载下存在的优势的存储驱动,如Device Mapper、Btrfs、ZFS,对于容器层数较多,且写小文件频繁的场景下选择Device Mapper 比选择Overlay 作为存储驱动更加合适。
因此建议结合自己的业务场景去选择需要的存储驱动,另外在选择存储驱动时需要结合自己宿主机的环境,注意避坑。
最后,为方便大家查询不同操作系统发行版对应的推荐存储驱动,笔者将Docker 官方给出的一个不同Linux 发行版的推荐表和不同存储驱动对应所支持的文件系统表贴一下:
不同Linux 发行版推荐表:
Linux 发行版 |
推荐存储驱动 |
Docker CE on Ubuntu |
Aufs,devicemapper,overlay2(Ubuntu 14.04 或者更新的版本,Ubuntu 16.04 或者更高的版本),overlay,zfs,vfs |
Docker CE on Debian |
Aufs、devicemapper,overlay2(限定版本Debian Stretch),overlay,vfs |
Docker CE on CentOS |
Devicemapper,vfs |
Docker CE on Fedora |
Devicemapper,overlay2(Fedora 26 或者更新的版本,experimental),overlay (experimental),vfs |
不同存储驱动支持文件系统对应表:
存储驱动名称 |
支持的文件系统 |
Overlay,overlay2 |
Ext4,xfs |
aufs |
Ext4,xfs |
devicemapper |
Direct-lvm |
btrfs |
Btrfs |
zfs |
zfs |


福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
刷了一个半月算法题,我薪资终于Double了
掌声送给TensorFlow 2.0!用Keras搭建一个CNN | 入门教程
中国AI开发者真实现状:写代码这条路,会走多久?
520 这天,我突然意识到,她根本配不上我这么聪明的男人
厉害!女学生偷师男子学校,变身区块链开发工程师
确实, 5G与物联网离不开区块链!
Linux 之父:我就是觉得苹果没意思!| 人物志