中科院&深睿开源:FastFCN,用于语义分割的新型上采样模块JPU,重新思考扩张卷积!
点击上方“CVer”,选择"星标"和“置顶”
重磅干货,第一时间送达

本文经机器之心(almosthuman2014)
授权转载,禁止二次转载
作者:Huikai Wu 等 参与:杜伟、Chita、路
扩张卷积在获取高分辨率最终特征图中发挥重要作用,但它也有一些缺陷,比如增加了计算复杂度和内存占用。近日,来自中科院自动化所以及深睿AI实验室的研究人员提出一种新型联合上采样模块 Joint Pyramid Upsampling(JPU),可在多种方法中替代扩张卷积,在不损失模型性能的情况下,有效降低计算复杂度和内存占用。
语义分割是计算机视觉领域的基础任务之一,其目的是为图像的每个像素分配语义标签。现代方法通常采用全卷积网络(FCN)来解决这一任务,并在多个分割基准上获得巨大成功。
原版 FCN 由 Long 等人 [22] 提出,它由用于图像分类的卷积神经网络(CNN)变换而来。原版 FCN 继承了 CNN 用于图像分类的设计,并通过步幅卷积(stride convolution)和/或空间池化层(spatial pooling layer)逐步对输入图像进行下采样,最终得到低分辨率特征图。最终的特征图编码了丰富的语义信息,却丢失了精细的图像结构信息,导致目标边界预测不准确。如图 1a 所示,原版 FCN 通常对输入图像进行 5 次下采样,将最终特征图的空间分辨率降低 32 倍。
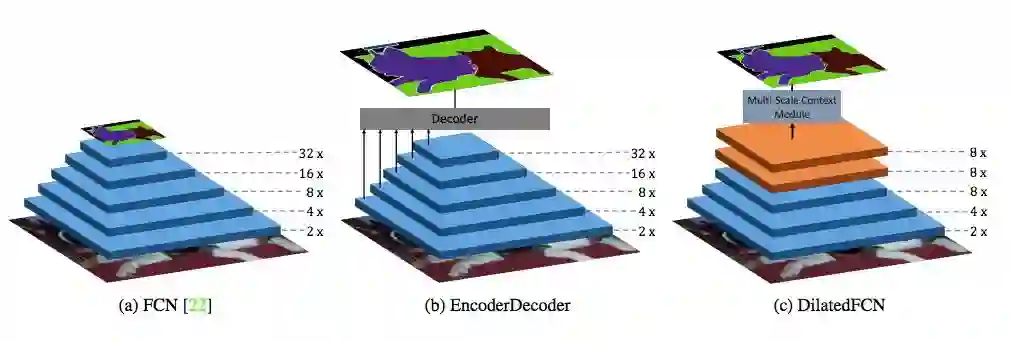
图 1:不同类型的语义分割网络。(a)原版 FCN,(b)编码器-解码器样式的语义分割网络,(c)利用扩张卷积得到高分辨率的最终特征图。
为了得到高分辨的最终特征图,[3, 28, 18, 30, 27] 将原版 FCN 作为编码器来捕获高级语义信息,而解码器则通过结合来自编码器的多级特征图来渐进地恢复空间信息。如图 1b 所示,研究者将这种方法称为 EncoderDecoder,其中解码器生成的最终预测具有高分辨率。
此外,DeepLab [5] 从原版 FCN 中移除最后两个下采样操作,并引入扩张(空洞)卷积以保持感受野(receptive field)不变。紧随 DeepLab,[38, 6, 36] 在最终特征图之上应用多尺度语境模块(context module),其性能在多个分割基准上明显优于大多数 EncoderDecoder 方法。如图 1c 所示,DilatedFCN 的最终特征图的空间分辨率是原版 FCN 的四倍,因而保留了更多结构和位置信息。
扩张卷积在保持最终特征图的空间分辨率中发挥重要作用,使模型性能优于大多数 EncoderDecoder 方法。但是,引入的扩张卷积使计算复杂度和内存占用均大大增加,从而限制了它在众多实时应用中的使用。以 ResNet-101 [13] 为例,相较于原版 FCN,DilatedFCN 中的 23 个残差块(69 个卷积层)需要四倍的计算资源和内存,而 3 个残差块(9 个卷积层)需要 16 倍的资源。
在本文中,研究人员旨在解决扩张卷积造成的上述问题。为了实现这一目的,研究人员提出了一种新型联合上采样模块(joint upsampling module)来替代耗时又耗内存的扩张卷积,即 Joint Pyramid Upsampling(JPU)。
因此,新方法将原版 FCN 作为主干网络,同时运用 JPU 对输出步幅(OS)为 32 的低分辨率最终特征图执行上采样,从而生成一个高分辨率特征图(OS=8)。因而,整个分割框架的计算时间和内存占用大幅减少。与此同时,以 JPU 替代扩张卷积时,性能不会出现损失。研究人员将此归因于 JPU 能够利用跨多级特征图的多尺度语境。
为了验证该方法的有效性,研究人员首先进行了系统性实验,证明 JPU 可以取代多种流行方法中的扩张卷积,且不会引起性能损失。之后,研究人员在多个分割基准上对提出的方法进行测试。结果显示,该方法可以实现当前最佳性能,并且运行速度提高了两倍以上。
具体来说,该方法在 Pascal Context 数据集上的性能显著优于所有基线,取得了 53.13% 的 mIoU 最佳性能。在 ADE20K 数据集上,该研究以 ResNet50 作为主干网络获得了 42.75% 的 mIoU,在验证集上创造了新纪录。此外,该研究使用 ResNet-101 在 ADE20K 测试集上实现了当前最佳性能。
总之,该研究的贡献有三:其一,提出了一种计算效率高的联合上采样模块 JPU,以替代主干网络中耗时又耗内存时间和内存的扩张卷积;其二,基于 JPU,整个分割框架的计算时间和内存占用可以减少 3 倍以上,同时获得更好的性能;其三,提出的方法在 Pascal Context 数据集和 ADE20K 数据集上均实现最佳性能。
论文:FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation

论文链接:https://arxiv.org/pdf/1903.11816.pdf
github:https://github.com/wuhuikai/FastFCN
现代语义分割方法通常会在主干网络中使用扩张卷积来提取高分辨率特征图,这带来了极大的计算复杂度和内存占用。为了取代耗时又耗内存的扩张卷积,本研究提出了新型联合上采样模块 Joint Pyramid Upsampling (JPU)。JPU 将提取高分辨率特征图的任务转换为联合上采样问题。
它在不影响性能的情况下,将计算复杂度降低了三倍多。实验表明,JPU 优于其它上采样模块,它可用于很多现有方法来降低计算复杂度、提高性能。通过用 JPU 模块替代扩张卷积,该方法在 Pascal Context 数据集(53.13% 的 mIoU)和 ADE20K 数据集(最终分数 0.5584)上都达到了当前最佳水平,同时运行速度快了两倍。
方法
在这部分中,研究人员首先介绍了最流行的语义分割方法 DilatedFCN,然后用新型联合上采样模块 JPU 改进 DilatedFCN 架构。最后,研究者先简单介绍了联合上采样、扩张卷积和步幅卷积,再详细讨论了 JPU 方法。
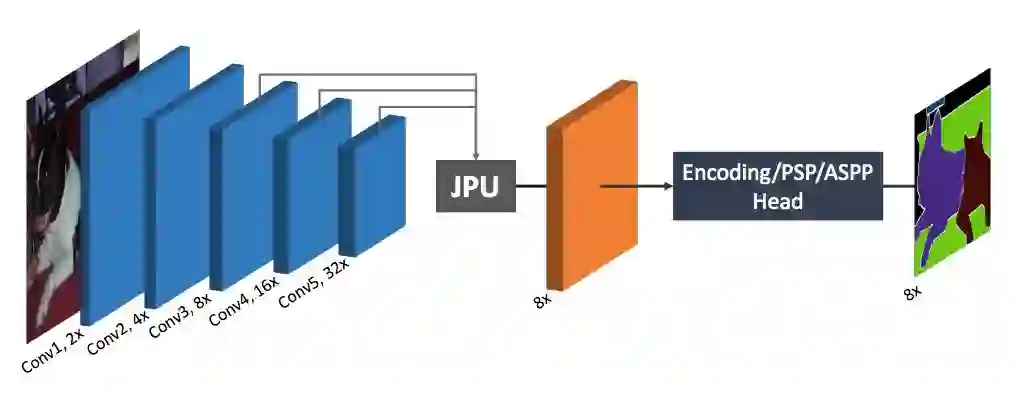
图 2:本文方法的框架概览。该方法采用了原版 FCN 作为主干网络。在主干之后,研究人员提出了新型上采样模块 JPU,该采样模块将最后三个特征图作为输入并生成了高分辨率特征图。然后使用多尺度/全局上下文模块来生成最终标签图。
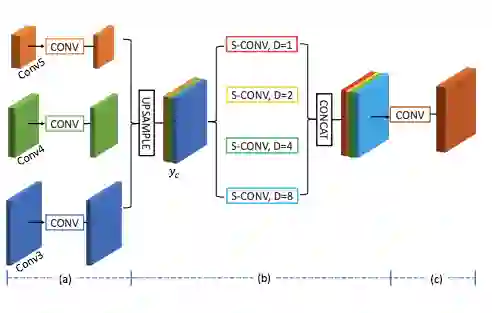
图 4:JPU 概览。
实验
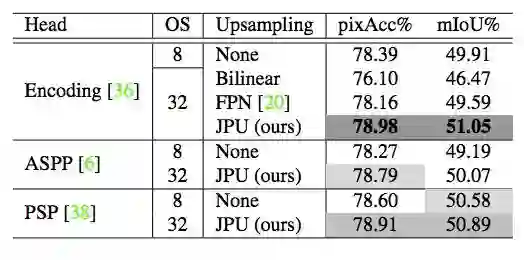
表 1:以 ResNet-50 作为主干网络时,多种方法在 Pascal Context 验证集上的性能。

图 6:以 ResNet-50 作为主干网络且使用 Encoding Head 时,不同上采样模块的可视化结果对比。
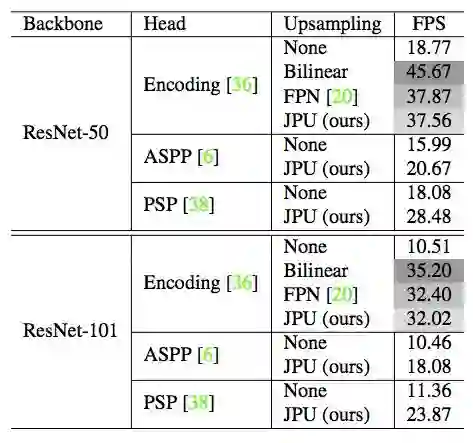
表 2:计算复杂度对比。FPS 是以 512×512 的图像作为输入在 Titan-Xp GPU 上测量的,该结果是 100 次运行的平均值。
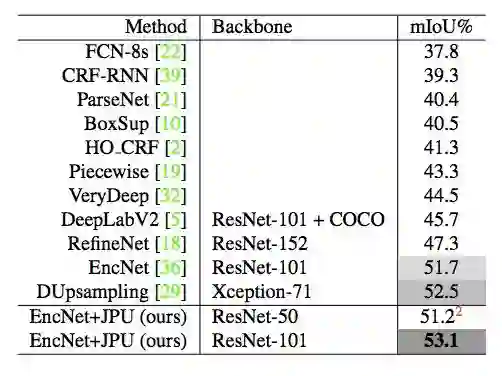
表 3:当前最佳方法在 Pascal Context 验证集上的结果。
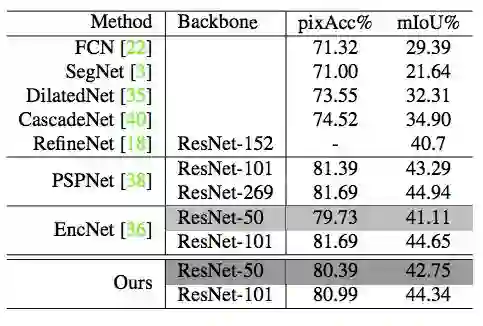
表 4:在 ADE20K 验证集上的结果。

表 5:在 ADE20K 测试集上的结果。前两项在 2017 年的 COCO-Place 挑战赛中分别排名第一和第二。

图 7:本文方法 (ResNet-101) 的可视化结果。第一行来自 Pascal Context 验证集,第二行来自 ADE20K 验证集。

CVer图像分割交流群
扫码添加CVer助手,可申请加入CVer-图像分割群。一定要备注:图像分割+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡)

▲长按加群
这么硬的论文精读,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!


