【论文分享】ACL 2020 立场检测相关研究
![]()
引言
![]()

引言

从自然语言文本中自动提取语义信息是许多实际应用领域中的重要研究问题。尤其是在最近通过社交媒体网站,新闻门户网站和论坛等渠道在线发布内容之后;大量相关的科学出版物揭示了诸如情感分析,嘲讽/争议/真实性/谣言/假新闻检测以及论据挖掘等问题的解决方案的影响和意义越来越大。
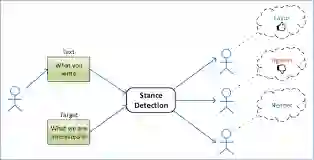
立场检测作为情感分类任务中的一个子任务,在上述领域中都起着举足轻重的作用,并且在不同的场景设置中任务的定义方式也不同,其中最常见的定义是将文本生产者的立场朝着目标自动分类为以下三个类别之一:{支持,反对,中立}。
本次DISC小编分享的三篇ACL2020论文将从不同方面围绕立场检测领域进行研究,包括新任务、新数据集、以及加入外部知识的新模型等。
![]()
文章概览
![]()
文章概览
网络论辩中的一致性预测——立场极性与强度检测(Agreement Prediction of Arguments in Cyber Argumentation for Detecting Stance Polarity and Intensity)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.509.pdf
在在线辩论中,用户对彼此的论点和想法表达不同程度的同意/反对。通常,同意/反对的语义隐含在文本中,必须经过预测才能分析集体意见。现有的立场检测方法可以预测帖子对主题或帖子的立场的极性,但不考虑该立场的强度。我们在判断两段对话的关系中引入了一个新的研究问题,即立场极性和强度预测。这个问题具有挑战性,因为立场强度上的差异通常很细微,需要细致的语言理解。在网络辩论数据中心的研究表明,将立场极性和强度数据都纳入在线辩论中可以带来更好的讨论分析。
走出“回声室”:检测反对辩论发言(Out of the Echo Chamber: Detecting Countering Debate Speeches)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.633.pdf
随着从传统新闻媒体向社交媒体和类似场所的转变,读者更倾向于被困在“回音室”中,并且可能成为假新闻和虚假信息的牺牲品,缺乏容易获得不同意见的渠道。因此,作者提出了检测反对立场发言的任务,具体来说,是给定一段辩论文本(长文本),从当前的大语料库中找到与其意见相反的辩论文本(长文本)。操作层面上,作者在文中遵循论辩领域的规范标准构建了3685篇辩论长文本作为该任务的数据集,并进行了人工以及机器模型的实验,结果显示该任务设置合理且极具挑战性。
使用可迁移的语义-情感知识增强跨领域立场检测(Enhancing Cross-target Stance Detection with Transferable Semantic-Emotion Knowledge)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.291.pdf
当有足够的带标签的训练数据可用时,立场检测任务中人们已经取得了巨大的成功。但是,注释足够的数据会占用大量人力,这为将立场分类器推广到具有新目标的数据建立了很大的障碍。在本文中,作者提出了一种用于跨目标立场检测的语义-情感知识转移(SEKT)模型,该模型使用外部知识(语义和情感词典)作为桥梁来实现跨不同目标的知识转移。在大型现实数据集上进行的大量实验结果证明,SEKT模型相对于最新的基线方法具有优越性。
![]()
数据概览
![]()
数据概览
对于立场检测任务,不同的应用场景中的任务设置会存在一定的差异,例如在最传统的设置中,立场检测被定义为给定两段文本,我们需要判断出两段文本之间的支持/反对关系;在另一些场景中可能定义为给定文本和某一主题,判断它们之间的语义关系等等,上述提到的三篇论文所使用到的数据集分别如下所示:
ICAS : 上述第一篇文章中所构建的新数据集。数据来源自作者所搭建的智能网络论辩系统(intelligent cyber argumentation system, ICAS)中2017年秋季至2019年春季所积累的数据,数据结构包含用户回复时输入文本以及他们对于自己所产生的回复的立场极性/强度的打分。
IBM Debater® - Recorded Debating Dataset - Release #5 : 第二篇论文中所构建的新数据集,作者采用(Mirkin et. al., 2018)所提出的辩论文本生成规范,通过聘请专业辩论人员进行给定主题、立场的口头陈述,再通过语音转文本技术生成对应的辩论文本,最终得到了3684条辩论长文本。
SemEval-2016 Task 6 : 第三篇论文中所使用的数据集,来自于SemEval2016年的第六个任务,共包含在4个话题上的4870条推特文本,每条推特文本都包含在一个话题上的立场标签。
![]()
论文
![]()
论文

动机
-
强度是立场关系的重要方面,这一维度的信息可以帮助我们对于用户之间的回复进行更为深入的分析; -
先前的立场检测方法大多仅判断立场的极性(同意/不同意/中立),但极少数考虑立场的强度(强,弱等)。 -
在研究立场强度的前人工作中,对于立场强度判别建模为更细粒度的分类问题(如:强烈同意/同意/中立/反对/强烈反对)并进行更为详细的标注,但发现这样的分类数据在使得模型在原来的三分类问题的任务中出现了明显的性能下降。
创新点
从上述动机出发,作者提出了给论点编码的新方式:一致值编码。
一致值编码(取值范围为[-1.0,+1.0])由两个因子构成:
-
符号(+/-/0),分别对应立场极性(支持/反对/中立) -
振幅(取值范围[0,1.0]),对应上文中所提到的立场强度(0代表无强度/中立;1.0代表完全支持/完全反对)
立场的一致值=符号*振幅
数据集
作者搭建了智能网络论辩系统(intelligent cyber argumentation system, ICAS),并邀请研究生在该平台上进行论辩互动,并为自己的回复进行一致值的标注(一致值的标注以0.2为最小间隔),如下图所示:
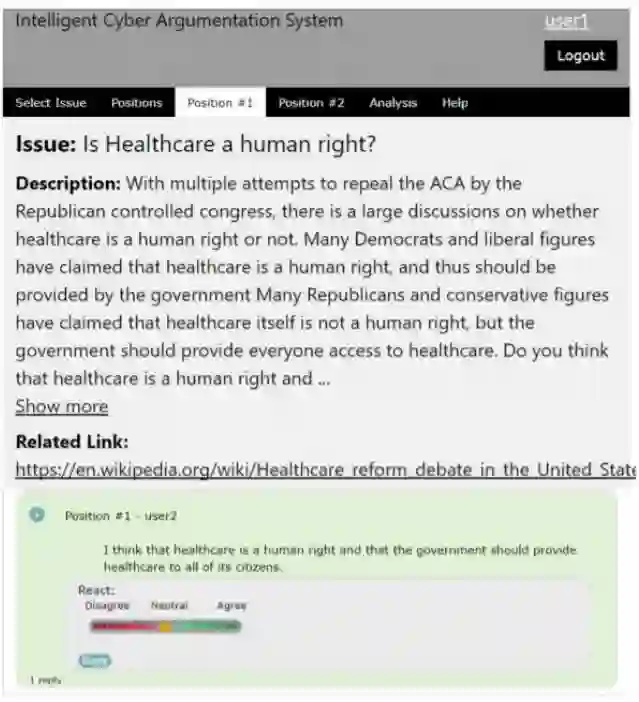
作者收集了从2017年秋季至2019年春季所记录的所有文本、一致值标注的数据,共计从904位用户中得到了22606条论点数据。
模型
作者应用了SemEval 2016 Twitter 立场检测任务中表现最好的五个模型,进行了相应改动(注:由于原本的立场检测任务为分类任务,而上文提到的强度判别为回归任务,故在本任务中需要将这些模型最后的分类层进行改为输出[-1.0,+1.0]的实值)应用到了上文所描述的新数据集中,模型分别如下所示:
-
Ridge-M以及Ridge-S
这两个回归模型基于1-3gram的词特征、2-5gram的字符特征等文本特征表示(Ridge-S模型还加入了词嵌入特征),并将其输入SVM模型从而得到在立场上的分类标签(在此任务中SVM被替换成了Ridge回归模型)。
-
SVR-RF-R整合模型
该模型利用语言特征、主题特征、词嵌入特征以及一些词法特征(共2855维),并将其输入至一个SVM分类器、一个随机森林分类器、一个朴素贝叶斯模型进行多数投票从而得到最后的分类结果(在此任务中三个模型被替换为SVR、随机森林回归器以及Ridge回归模型)。
-
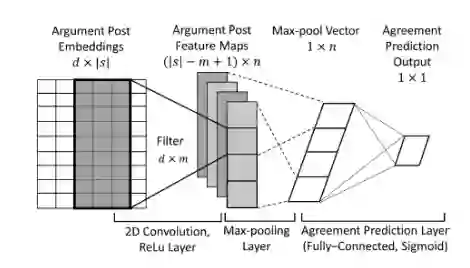
pkudblab-PIP
该模型如下图所示,是一个卷积神经网络模型,通过将输入句子的词向量依次送入2D卷积层、最大池化层、全连接稠密层从而得到最终的标签分类(该任务中输出层替换为sigmoid层,从而输出实值一致值)。
-
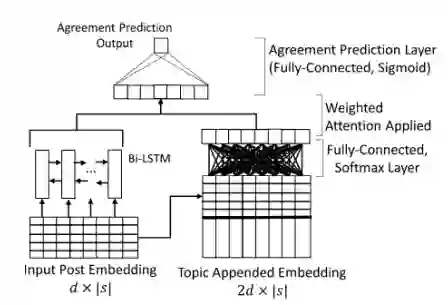
T-PAN-PIP
该模型如下图所示,是一个基于递归神经网络的模型。该模型通过将输入句子的词向量依次送入BiLSTM以及注意力层,从而得到最终的标签分类(该任务中输出替换为sigmoid层,从而输出实值一致值)。
实验
该论文的实验主要从两方面进行:
-
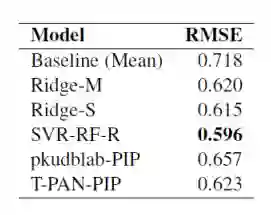
上述五个在立场极性检测中表现最好的模型在新任务新数据集上的表现:
如图所示,五个模型在新数据集上的RMSE(均方误差根)分布在0.596~0.718之间,作者称这个表现与原任务上的效果接近。其中SVR-RF-R整合模型的RMSE指标最低,取得了最好的效果。
-
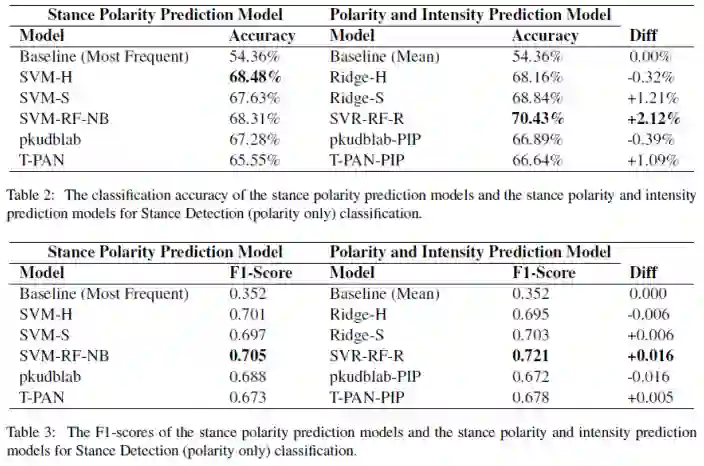
所提出的新任务是否提升了模型在原任务上的表现:
注意到当前新任务的标签以及预测都是一个取值范围为[-1.0,+1.0]的实数值,为了与传统的立场极性检测作比较,作者将新任务的一致值标签以及预测都取其符号,于是新任务又被转化成了分类问题。最终,作者将仅预测极性任务的模型性能与上述预测一致值的模型在极性标签上的性能做对比(如下图所示),发现了大多数模型(4个)在经过了一致值预测任务的训练后,在立场极性的判断上都比原分类任务的模型表现更好,从而得出了新任务单就立场极性的判断上也能提升模型的性能,是一个合理的任务。

动机
-
缺乏对特定观点提出异议的相反观点的了解,可能导致我们的决策最终基于片面或者存在偏见的信息。 -
具体操作上,该任务定义为:给定输入文本和语料库,请从该语料库中检索一个包含与输入文本中提出的论点相驳斥的反文本。
数据集
数据集构建
本篇文章作者采用(Mirkin et. al., 2018)所提出的辩论文本生成规范,通过聘请专业辩论人员进行给定主题、立场的口头陈述,再通过语音转文本技术生成对应的辩论文本,具体的数据集生成过程如下:
-
录制支持论题的演讲 -
专业辩手给定一系列论题(motion)以及相关的背景资料(从Wikipedia等在线资源网站上获得) -
每位辩手每次被给予十分钟的准备时间 -
准备时间结束后每位辩手每次录制一段长度为四分钟的的辩论演讲(用于支持给定论题) -
将上述得到的演讲录音通过语音转文字技术转换为文本 -
录制反对论题的演讲 -
专业辩手给定一系列论题(motion)、一篇由上述过程生成的支持论题的演讲稿以及相关的背景资料(从Wikipedia等在线资源网站上获得) -
每位辩手每次被给予十分钟的准备时间 -
准备时间结束后每位辩手每次录制一段长度为四分钟的的辩论演讲(用于反对给定的支持演讲稿) -
将上述得到的演讲录音通过语音转文字技术转换为文本
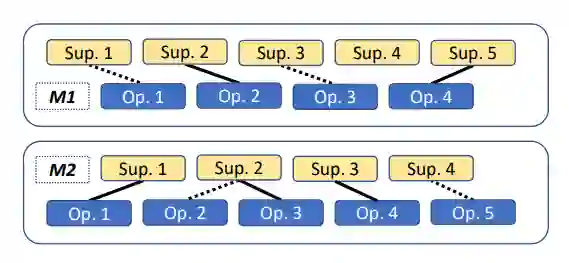
上述过程中所涉及的论题、论点之间的关系如下图所示(其中 、 为两个不同的论题, 表示支持论题的演讲, 表示反对这些支持演讲的演讲,实线和虚线分别表示显式反对与隐式反对):
数据集分析
-
共包含460个不同论题 -
总共录制了1797段支持论题的演讲 -
总共录制了1887段反对这些支持演讲的演讲 -
348篇为显式反驳 -
1389篇为隐式反驳 -
150篇为直接反对给定议题的演讲,并不驳斥任何一篇支持议题的演讲
实验
人工表现
在收集到上述数据集之后,作者先进行了人工表现的实验。作者共组织了两场实验,第一场参与者为进行过多次数据标注任务的标注专家,第二场参与者为随机招募的实验者。
对于每一段支持论题的演讲,组织方都会给出3~5段反对演讲,其中有一段是正确的驳斥所给定的支持言论,剩余则为同一论题下与支持言论不构成驳斥关系的错误选项,受试者需要从给定的候选文本给出自己认为的正确答案,当无法确定时,需要他们随机猜一个答案并说明情况。人工实验的结果如下表所示(A表示人工试验的准确率,R表示随机猜的准确率;Ex表示标注专家的结果,Cr表示随机招募的受试者的结果):
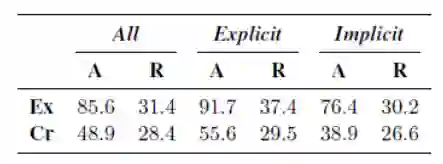
由上表我们可以得出如下几个结论:
-
人工表现远超随机猜测的准确率,说明这个任务是可行的; -
标注专家结果比受试者有明显提升; -
隐式驳斥的文本相比显示驳斥文本更难选择正确。
模型表现
在进行完人工实验之后,作者采用了较多的语言模型来进行自动化实验,实验结果如下表所示:
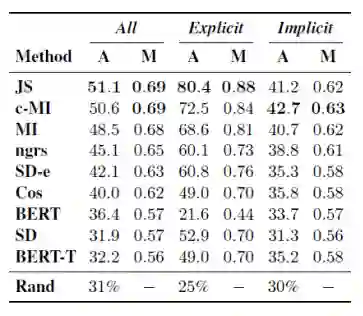
其中值得一提的是BERT的表现差强人意,在众多基于特征的方法中处于下游,甚至与随机猜的准确率相近,这是因为根据之前的方式所生成的数据集长度远超BERT的最大长度512,因此作者不得不对原文以及候选项都进行截断,但仍然未能得到使人满意的结果,这也从另一方面体现出当前对于长文本的处理方法仍存在较大的局限性。

动机&贡献
-
当前阶段尽管立场检测任务已经有了长足发展,但跨领域的的目标立场检测(指训练集和数据集在领域上存在差异)进展较小。 -
本文从语义相关和情感相关的词汇表中构建语义情感知识图(SE图),并通过应用图卷积网络(GCN)对上述的情感知识图进行表示学习,并将传统的BiLSTM进行了改进,使其可以更好地使用上述SE图所带来的外部知识。 -
实验结果显示,通过上述方式的处理,模型在跨领域的目标立场检测任务上取得了SOTA的表现。
数据集
本篇文章所采用的数据集来自于SemEval2016年的第六个任务,共包含在4个话题,包括Donald Trump (DT), Hillary Clinton (HC), Legalization of Abortion (LA), 和Feminist Movement (FM)上的4870条推特文本,每条推特文本都包含在一个话题上的立场标签。作者还向其中加入了一个新的话题,Trade Policy (TP),其包含了1245条推特文本。之后作者将这五个话题按照其语义分为了两组:妇女权利(FM, LA)以及美国政治(DT,HC,TP)。由此,作者构造出了八组跨领域的目标立场检测任务 ( DT→HC, HC→DT, FM→LA, LA→FM, TP→HC, HC→TP, TP→DT, DT→TP)。(左箭头表示从源领域到目标领域)
模型
作者所提出的模型SEKT整体架构如下图所示,其主要由两部分构成:SE图以及知识增强的BiLSTM:
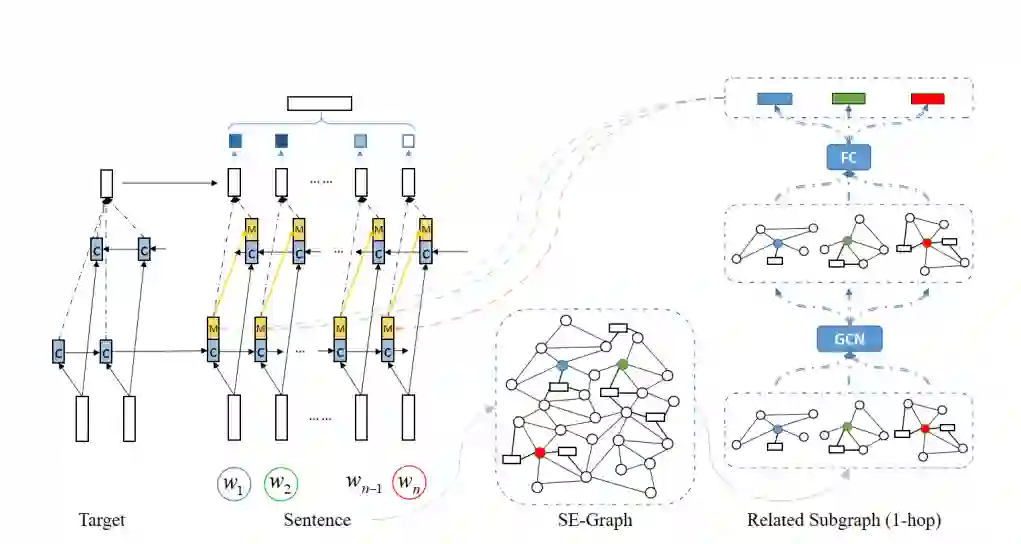
语义-情感知识图(SE图)构建
-
将SenticNet中的同义/近义词两两之间连边 -
将EmoLex中每个词及其对应的可能的情感两两连边
上述过程如下图所示,注意这里我们构建的是包含词和情感标签的异质网络图:
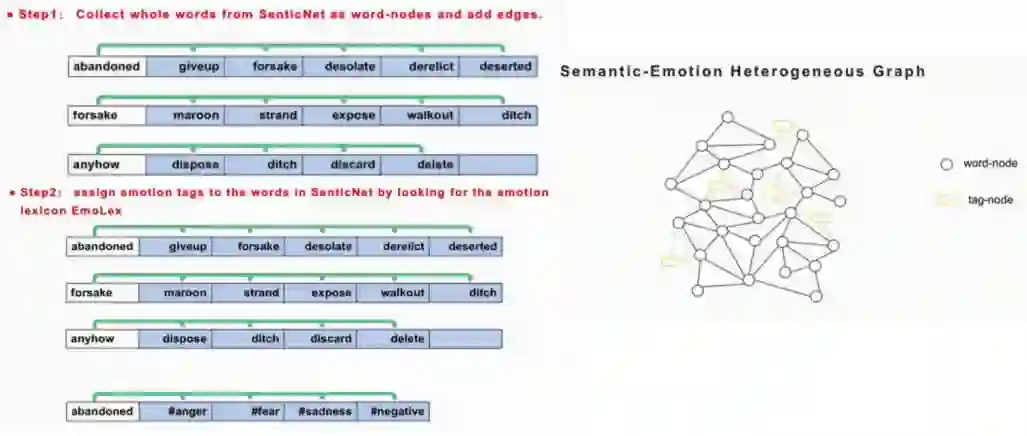
语义-情感知识图表示
-
对于每个节点 ,我们从全知识图中抽出一个 的子图 (文中k取1) -
接下来把 传到一个两层GCN中 -
-
最后我们将 传入一个全连接层来得到图的最终表示
知识增强的BiLSTM
该模块结构如下图所示:
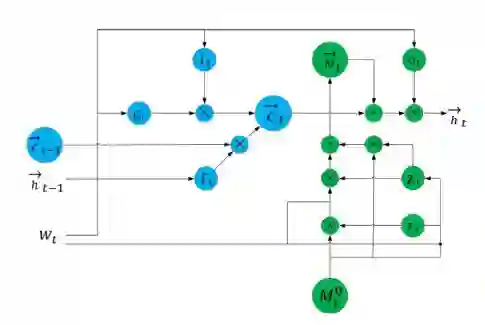
上图中左边蓝色部分为普通BiLSTM的结构组件,按如下公式更新状态:
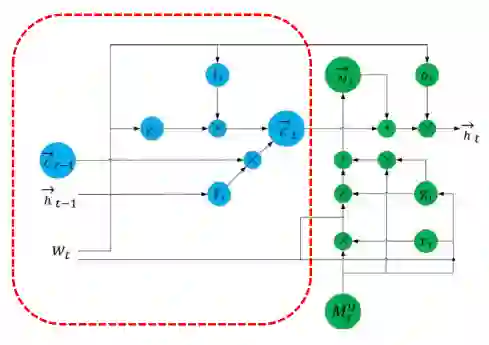
该模块中右半部分为知识知晓的记忆模块,按如下方式更新状态:
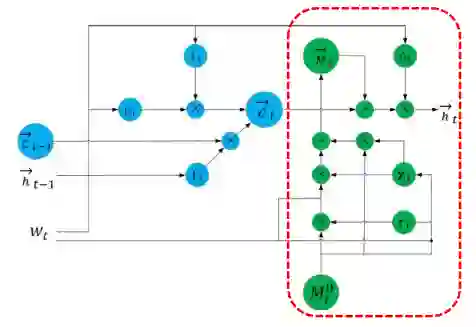
对于每一个词
,我们从SE图中抽取出其对应的实体,并且获得以其为中心的
子图表示
。
最终,将所得到的目标表示以及句子表示再通过一个注意力层,便可得到句子在目标上的立场分类预测结果。
实验
与基线模型相比
作者所提出的完整模型在SemEval 2016 任务6数据集上的表现如下图所示:

可以看出作者的SEKT模型在8个跨领域的目标立场检测任务中的表现都超过了大多数基线模型,达到了SOTA的效果,说明作者这种通过加入语义词典与情感词典的外部知识模型,完成了领域迁移中对于关键词的表示以及关系建模。
消融实验
在验证了完整模型的SOTA性能后,作者进一步进行了消融实验,在上述8个任务中去掉SE图建模以及将拓展的BiLSTM替换为传统LSTM,分别进行性能对照,结果如下图所示:
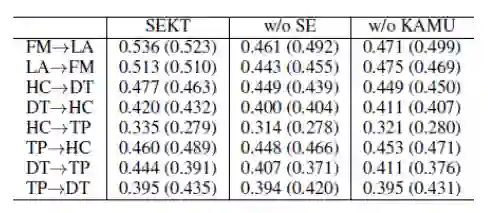
可以看出在大多数跨领域的目标立场检测中,去掉SE图表示或去掉对于BiLSTM的改进,都会使得模型性能下降0.02左右的指标,从而证明了这两部分的重要性。(注:作者此处的消融实验不仅仅是去掉了SE两个词典中的信息以及图表示学习的信息,而是保留这些信息,但在模型层面去掉上述较为复杂的操作,因此在不影响输入的信息量的情况下,但就模型设计方面证明了所提模型的优越性)。
参考文献
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦



