观点 | 我在谷歌大脑工作的 18 个月中,是怎样研究强化学习的?

AI 科技评论按:在强化学习领域,谷歌大脑的研究内容一直是业界重点关注的对象。Marc G. Bellemare 是谷歌大脑的研究员,研究方向为分布式强化学习、表征学习等。他将自己在谷歌大脑 18 个月中研究经历和心得写成了文章并进行发表。 AI 科技评论全文编译如下。
时间回溯到 2017 年夏天,在欧洲一段时间的告别旅行中,我被当时在蒙特利尔新成立的谷歌大脑团队录用 (当时我进行远程办公)。我在家里的办公室可以看到伦敦北部贝尔塞斯公园(Belsize Park)的绝美景色,而且还曾招待了谷歌蒙特利尔的整个强化学习团队,这是真的。
从那以后,我搬到了另一个大陆,在 AI 实习生、学生研究者和全职谷歌员工三重角色中转换。现在,谷歌团队的规模有了相当大的扩展 (而且还在继续扩展:Marlos C. Machado 也加入了我们)。事后看来,2018 年是相当多产的一年。这篇博客回顾了这段时间我们的科研产出,以一个全景视角介绍了蒙特利尔谷歌大脑团队在强化学习方面研究进展以及我们所参与过的非常棒的合作,从而让我们对不远的未来有了一个认识。
分布式强化学习
「它很好。但它如何实现呢?」
在强化学习中,分布式的方法认为我们应该预测随机收益的分布,而不是预测它们的期望值 (Bellemare, Dabney, Munos, ICML 2017 链接:http://www.marcgbellemare.info/static/publications/bellemare17distributional.pdf)。然而,大多数分布式智能体仍然通过将行动值 (action value)分布提取还原为它们各自的期望值,然后选择期望值最高的操作来运行。预测,然后提取。那么,为什么它在实践中表现得如此出色呢?
为了回答这个问题,我们开发了一种正式语言来分析分布式强化学习方法,尤其是基于样本的方法(Rowland 等,AISTATS 2018)。通过这一形式,我们发现原来的分布式算法(称为 C51)隐式地最小化了概率分布之间的距离(Cramér 距离)。但是我们的一些结果表明,分布式算法应该最小化分布之间的 Wasserstein 距离,而不是 Cramér 距离。我们(我指的是 Will Dabney)用一种叫做分位数回归(quantile regression,)的技术重新修正了大部分的 C51,在一定程度上最小化了 Wasserstein 距离。由此产生的智能体(这个称为 QR-DQN)在 Atari 2600 基准上表现出强大的性能(Dabney et al.,AAAI 2018 链接:https://arxiv.org/abs/1710.10044)。另一个令人兴奋的结果是, Mark Rowland 最近发现了分布式强化学习中统计量和样本之间的一个有趣的失配,这就解释了为什么这些算法有效,而其他算法注定会失败(Rowland et al.,2019 链接:https://arxiv.org/abs/1902.08102)。
根据 Mark 对 C51 的分析,我们从基本原理推导出了一个分布式算法——在本例中,使用的是更容易处理的 Cramér 距离。我们的目标是开发出一项能显式地对分配损失执行梯度下降(C51 和 QR-DQN 都没有这样做)的分配算法,而最终开发出来的是一项我们命名为 S51 的算法(Bellemare 等人,AISTATS 2019 链接:https://arxiv.org/abs/1902.03149);「S」代表「有符号的」,因为算法可能会输出有效的负概率。由于其相对简单,我们能够证明,当与线性函数近似(linear function approximation)结合时,S51 能够保证收敛性。在此过程中,我们还收集了一些证据,证明在一些病态的例子中,预测+提取的方法比直接预测期望值的表现更糟糕。这是一位评论者所提到的「更容易出现模型错误识别」所导致的自然而然的结果。
此后,我们也证明了将预测+提取的方法结合到表格表征中实际上是无效的,同时证实了如果将该方法结合到线性表示中,其性能可能比预期的强化学习更差(Lyle, Castro, Bellemare, AAAI 2019 链接:https://arxiv.org/abs/1901.11084)。这使我们排除了不依赖于表征选择的常见解释,如「分布式强化学习减少方差」或「平均分布式预测导致更准确的值估计」。这些解释某种程度上错误地引用了 Holmes 先生的话,一旦你排除了不可能,剩下的一定是真相:分布式强化学习一旦与深层网络结合,似乎就会变得有用。
为了收集这方面的进一步证据,我们在 Cartpole 域中训练了智能体,要么使用固定的低维表示(一阶傅里叶基 链接:https://people.cs.umass.edu/~pthomas/papers/Konidaris2011a.pdf),要么使用类似的深度网络。结果(总结如下面的图表所示)相当有说服力:在固定表征的情况下,分布式方法的性能比基于预期的方法差;但使用深度表征后,它们就表现得更好了。这篇论文还表明,基于 Cramér 的方法应该输出累积分布函数(cumulative distribution function),而不是概率质量函数(probability mass function,PMFs)。
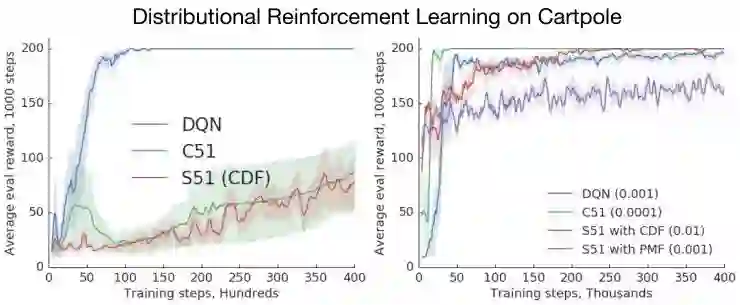
一名深度学习实践者会很自然地得出这样的结论:分布式强化学习是有用的,因为「它有助于更好地学习表征」。但这在形式上意味着什么呢?如何证明或反驳这种说法呢?这些问题促使我们研究了一个非常热门的话题:将表征学习应用于强化学习。
表征学习
去年夏天,Will Dabney 和我为强化学习中的表征学习设计了一个我们称之为「苹果派」(apple pie)的实验:用一个简单的设置去研究学习好的表征意味着什么。这个实验包括 1)一个综合环境 (四室域);2)训练一个非常大的深度网络; 3)做出各种预测。我们将表征定义为从状态到 d 维特征向量的映射,之后又将这些特征向量线性映射到预测。在所有的实验中,d 都小于状态数。这个设置允许我们回答这样的问题:「当我们训练网络预测 X 时,得到的表征是什么?」,其中 X 可能是值函数、值分布或一些辅助任务。
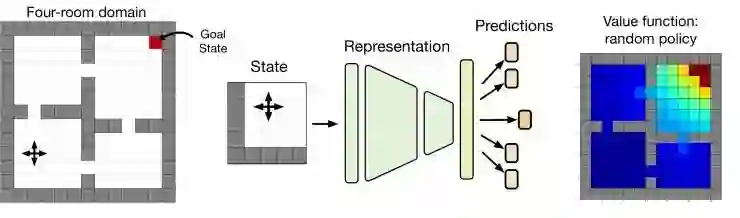
通过对这个小问题的不断探索,我们意识到可以为表征制定一个最优准则。该准则指出,最优表征应该最小化所有「可实现」值函数的近似误差。这里我用「可实现」表示「由某些策略生成」(Bellemare et al.,2019 链接:https://arxiv.org/abs/1901.11530)。事实上,我们只需要考虑此类值函数的一个非常特殊的子集,即对偶值函数(adversarial value functions,AVFs),以反映最优性准则的极小值特征。因为这些参数基本上是几何化的,得出的这些结果也很有趣。在整个过程中,我们发现值函数的空间本身是高度结构化的:虽然还存在着一些不直观的特征,但它整体来看是一个多面体(Dadashi et al .,2019 链接:https://arxiv.org/abs/1901.11524)。
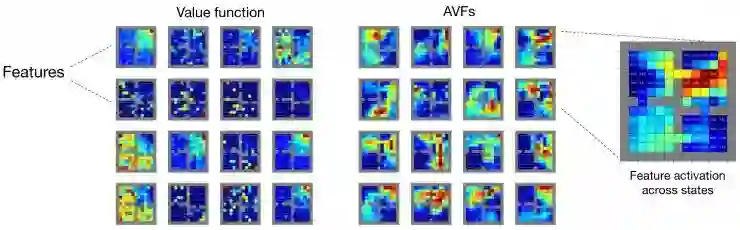
我们使用「用于表征的 FMRI 」(见上)来可视化该方法的效果(上图;Marlos C. Machado 提供代码)。这里,每个单元格将特征的归一化激活描述为输入状态的函数。图中对比了网络被训练用来预测单个值函数或多个 AVFs 时的情况。在仅使用值表征的时候,得出的结果有点不令人满意:单个特征要么在状态之间不活跃,要么是预测值函数的副本;此外,在激活模式中还存在噪声。相比之下,AVFs 方法产生的结构很漂亮。
我们可以使用相同的工具来确认分布式强化学习确实学习了更丰富的表征。下图是使用 C51(左)或使用 QR-DQN(右)预测随机策略值分布时学到的特性的可视化情况。分位数回归得到的特征提供了一系列的响应,从目标附近的高度峰值(左下角第二行)到相对分散(右上角)。这两组特性都比刚刚前面提到强化学习在学习值函数时更加结构化(前面的图左)。
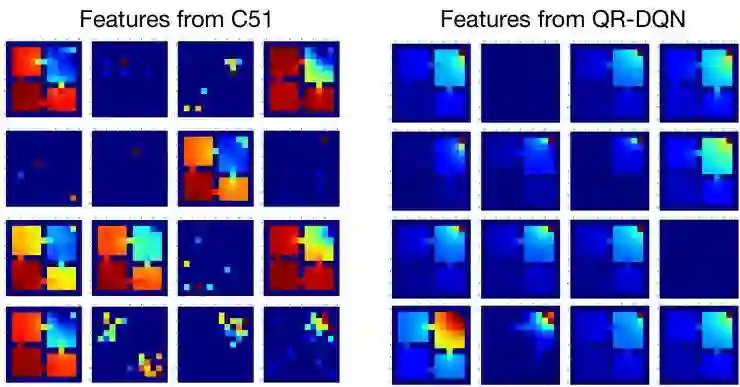
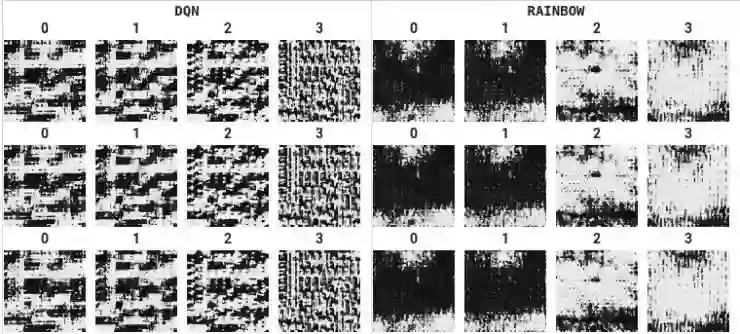
作为这些结果的补充,我们可视化了 Atari 2600 游戏智能体中隐藏单位的激活。这些构成了与 Pablo Samuel Castro、Felipe Such、Joel Lehman 以及其他许多人在「Atari Zoo」项目中非常出色的合作的一部分(如 et al.,Deep RL Workshop at NeurIPS, 2018 链接:https://arxiv.org/abs/1812.07069)。为了强调其中一个结果,分布式算法(该算法是 Hessel等人对 C51 的扩展,叫做 Rainbow)学习到的卷积特性通常比非分布式 DQN 学习到的卷积特性更详细、更复杂,如下面的 Seaquest 游戏示例所示:
同样重要的是,我们发现预测多个折扣率的值函数也是在 Atari 2600 游戏中制作辅助任务的一种简单而有效的方法 (Fedus et al.,2019 链接:https://arxiv.org/abs/1902.06865)。
毫无疑问,不同的强化学习方法会产生不同的表征形式,并且在深度学习和强化学习之间会发生复杂的交互作用。如果幸运的话,在接下来的一年,我们也会找出这些表征与智能体的经验表现之间的关系。
软件
如果你曾参加我去年的一次演讲,你可能会看到我的演讲内容如下:
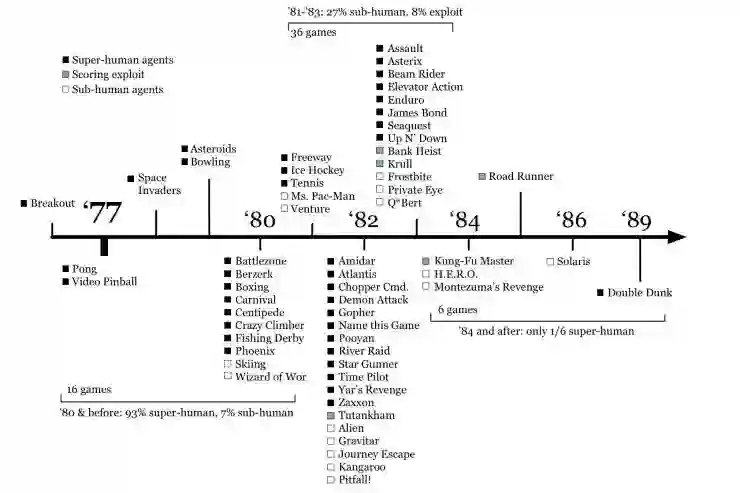
根据发行日期,时间轴按时间顺序对 Arcade Learning Environment 提供的 60 款游戏进行排列。每个标题标出了(主观)估计的性能最好的学习智能体:超人的(黑色格),近似人类的(红白格),最后也为游戏中的 AI 不为完成游戏,而纯粹以得分为目的游戏打出了分值(灰色格)。时间轴显示,前面标上「超人的」标签的游戏,比重要高于后面的游戏。我认为,这证明了早期游戏要比后期游戏更容易,部分原因在于电子游戏体验的转变:从反应性游戏(Pong)转变为认知性游戏(Pitfall!)
注意,时间表是从 2017 年年中开始的,现在有点过时了,经过调整,我们也考虑到了其他的游戏,例如 Montezuma's Revenge 通过运用模仿学习(Hester et al.,2017 链接:https://arxiv.org/abs/1704.03732;Aytar et al., 2018 链接:https://arxiv.org/abs/1805.11592)和非参数方案(Ecofett et al.,2019 链接:https://arxiv.org/abs/1901.10995)在性能上实现了巨大进步,不过即使是这样,我们或许还是遗漏了很少一部分有代表性的游戏。鉴于 ALE 在推动深度强化学习研究复兴方面发挥了重要的作用,因此在强化学习领域应该积极寻找「下一个 Atari」。
但这张图表也帮我说明了另一点:ALE 现在是一个成熟的基准,应该区分对待它和新出现的挑战。用 Miles Brundage 的话来说就是:Atari 游戏,「如果你在意样本效率,那么它可以作为强化学习基准」。深度强化学习本身也在不断成熟:想要更好地了解当前的技术,请参阅 Vincent François-Lavet's review (2019)(链接:https://arxiv.org/abs/1811.12560)。在取得令人兴奋的早期成功后,深度强化学习可能准备回归基础。
这种成熟的结果之一是对 ALE 论文进行二次更新,这项工作由我当时的学生 Marlos C. Machado 主导,新的成果与新的代码一同发布。该代码的发布解锁了额外的难度级别(flavours),这证明新成果是对迁移学习研究非常有用的(Machado et al.,2018 链接:https://jair.org/index.php/jair/article/view/11182)。在这篇论文中有太多的好东西要列出,但是首先要讨论的是如何评估学习 Atari-playing 算法的重复性和公平性。在 Go-Explore 博客发布的 Twitter-eddies 中可以看到一个关于社区如何接受这一点的很好的例子:经过讨论之后,作者们重新使用我们推荐的「粘性行为」评估方案来评估他们的方法。(如果你感兴趣,这是 Jeff Clune 的一条推特 链接:https://twitter.com/jeffclune/status/1088857228222709760)。
去年 8 月,我们还发布了开源强化学习框架,Dopamine(白皮书:Castro et al.,2018 链接:https://arxiv.org/abs/1812.06110)。我们想从简单的 Dopamine 入手,坚持开发对强化学习研究有用的一小部分核心功能。因此,框架的第一个版本由大约 12 个 Python 文件组成,并为 ALE 提供了一个单 GPU、最先进的 Rainbow 智能体。Dopamine 2.0(2 月 6 日 Pablo Samuel Castro 的博客文章)扩展了第一个版本,更广泛地支持离散操作域。我们最近几乎所有的强化学习研究都使用 Dopamine。
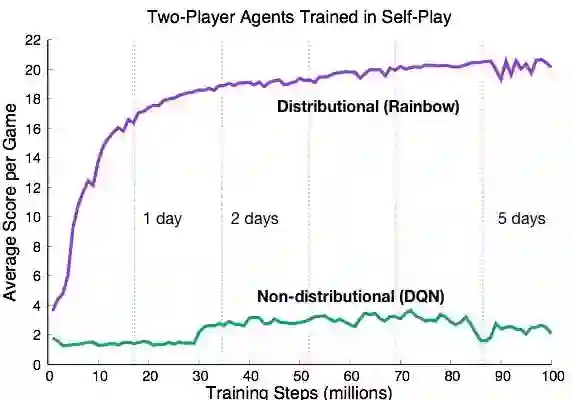
最后同样值得一提的是,我们最近还与 DeepMind 合作发布了一个基于热门纸牌游戏 Hanabi(Bard et al.,2019)的人工智能方法新研究平台。Hanabi 是独一无二的,因为它结合了合作(而不是竞争!)和部分可观察性。代码中包含一个基于 Dopamine 的智能体,因此你可以随时将代码用起来。我已经在另一篇博文中(http://www.marcgbellemare.info/blog/a-cooperative-benchmark-announcing-the-hanabi-learning-environment/)对此进行了更多的讨论,但最后我想说,这是这段时间以来我研究的最有趣的问题之一。顺便说一下:分布式强化学习和非分布式强化学习之间似乎存在很大的性能差距,如下面的学习曲线所示。这是一个小小的谜团。
结语
这篇文章没有讨论如何探索强化学习,尽管这个话题对我来说仍然很重要。值得注意的是,通过 Adrien Ali Taiga,我们在理解伪计数如何帮助我们探索方面取得了一些进展(Ali Taiga, Courville, Bellemare, 2018 链接:https://arxiv.org/abs/1808.09819)。很高兴看到强化学习的越来越多的研究者们迎接挑战,致力于解决 Montezuma’s Revenge 等艰难的探索问题。尽管 epsilon-贪婪(epsilon-greedy)算法和熵正则化(entropy regularization)在实践中仍然占据主导地位,但我认为我们离显著提高算法样本效率的集成解决方案,也不远了。
尽管蒙特利尔市中心的风景可能与伦敦北部不尽相同,但我在谷歌大脑这段时间的研究经历绝对令人兴奋。蒙特利尔和加拿大是多位世界上最优秀的深度强化学习研究人员的家乡,能与这么多本地和谷歌大脑团队的人才交流,我感到很不胜荣光。
via:marcgbellemare



