KDD 2020最佳论文奖出炉!谷歌北航获奖


在继时间检验奖,新星奖,创新奖,论文奖,服务奖等奖项公布之后,最佳论文奖也已出炉,其中最佳论文奖由谷歌研究院的 Walid Krichene 和 Steffen Rendle 摘得,最佳学生论文奖由杜克大学的 Ang Li、Huanrui Yang、陈怡然和北航段逸骁、杨建磊获得。
最佳论文奖

简介:项目推荐的任务需要在给定上下文的情况下对大量的项目进行排序。项目推荐算法是使用依赖于相关项目位置的排名指标来评估的。为了加速度量的计算,最近的工作经常使用抽样的度量,其中只有一组较小的随机项和相关项被排序。
Walid Krichene
Walid Krichene 是谷歌研究所激光小组的成员,从事机器学习和推荐。他还致力于开发使用连续时间和随机动力学的优化方法。他也是 Google 开源 ML 课程推荐系统课程的合著者,在 ML@ 资本。
个人主页:https://www.aminer.cn/profile/walid-krichene/53f44bb5dabfaec09f1de254
Steffen Rendle
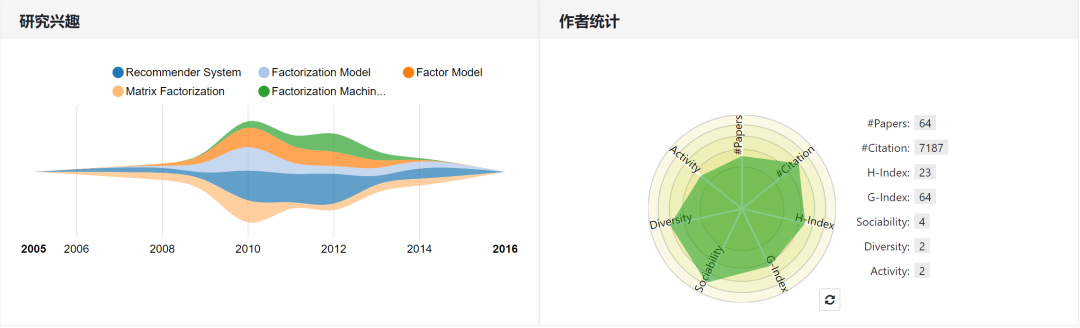
个人主页:https://www.aminer.cn/profile/steffen-rendle/53f42ec2dabfaee1c0a454a5
获奖论文:《TIPRDC: Task-Independent Privacy-Respecting Data Crowdsourcing Framework for Deep Learning with Anonymized Intermediate Representations》

为了解决学习任务未知或变化的情况,作者提出了一种基于匿名中间表示的任务无关隐私的数据众包框架 TIPRDC。该框架的目标是学习一个特征抽取器,它可以隐藏中间表征中的隐私信息,同时最大限度地保留原始数据中嵌入的原始信息,供数据采集器完成未知的学习任务。
作者设计了一种混合训练方法来学习匿名中间表示:(1)针对特征隐藏隐私信息的对抗性训练过程;(2)使用基于神经网络的互信息估计器最大限度地保留原始信息。他们广泛地评估了 TIPRDC,并将其与使用两个图像数据集和一个文本数据集的现有方法进行了比较他们的结果表明,TIPRDC大大优于其他现有的方法。本文的工作提出了第一个任务独立隐私尊重数据众包框架。
论文链接:https://www.aminer.cn/pub/5f03f3b611dc83056223205b?conf=kdd2020

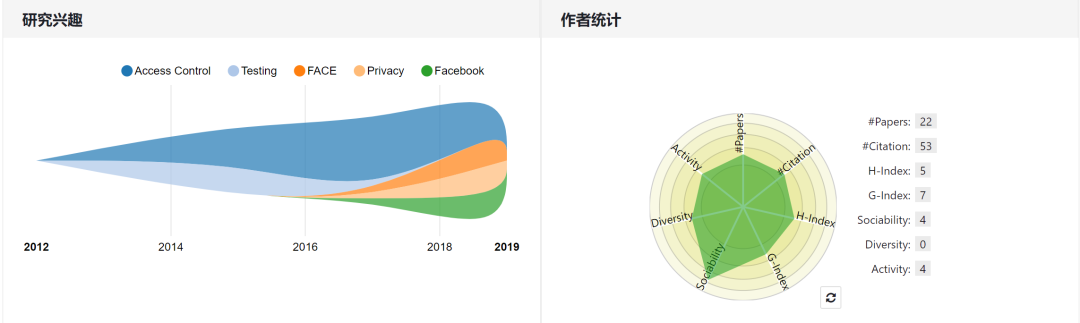
论文第一作者 Ang Li 是杜克大学电子和计算机工程系的一名在读博士,导师为陈怡然和 Hai "Helen" Li 教授。Ang Li 曾在2013 年获得北京大学软件工程硕士学位,2018 年获得阿肯色大学计算机科学博士学位。
个人主页:https://www.aminer.cn/profile/ang-li/560c7ea645ce1e59607a585a
来自弗吉尼亚大学的 Mengdi Huai、Jianhui Sun、Renqin Cai、Aidong Zhang 和来自纽约州立大学布法罗分校的 Liuyi Yao 获得了最佳论文奖的亚军,获奖论文是《Malicious Attacks against Deep Reinforcement Learning Interpretations》。

为了弥补这一差距,本文研究了 DRL 解释方法的脆弱性。具体来说,作者首先介绍了针对DRL解释的对抗性攻击的研究,并提出了一个优化框架,在此基础上可以得到最优的对抗攻击策略。此外,作者还研究了 DRL 解释方法对模型中毒攻击的脆弱性,并提出了一个算法框架来严格描述所提出的模型中毒攻击。最后,作者进行了理论分析和大量实验,以验证所提出的针对 DRL 解释的恶意攻击的有效性。
这篇论文将深度学习和强化学习结合(DRL),并证明了其在众多序列决策问题中动态建模的能力。为了提高模型的透明度,已经有研究提出了针对 DRL 的各种解释方法。但是,这些 DRL 解释方法隐式地假定它们是在可靠和安全的环境中执行的,但在实际应用中并非如此。弗吉尼亚大学的研究团队调查了一些 DRL 解释方法在恶意环境中的漏洞。具体而言,他们提出了第一个针对 DRL 解释的对抗性攻击的研究,提出了一个优化框架来解决所研究的对抗性攻击问题。
论文链接:https://aminer.cn/pub/5f03f3b611dc830562232015?conf=kdd2020
Mengdi Huai
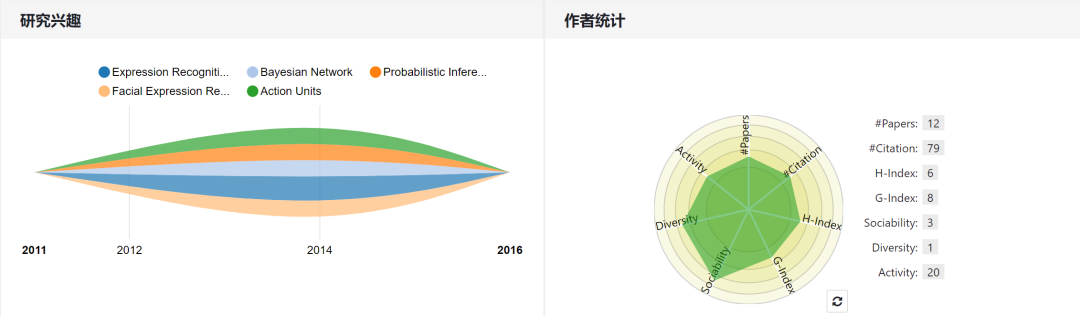
个人主页:https://www.aminer.cn/profile/mengdi-huai/562d1ff545cedb3398d5cd54
Renqin Cai是弗吉尼亚大学的博士生。研究重点是推荐系统的用户行为建模。
个人主页:https://www.aminer.cn/profile/renqin-cai/5629a4ac45cedb33988903f4
在继汤继良、盛胜利、唐杰等华人学者在本届 SIGKDD 大会上荣获了包含新星奖、时间检验研究奖、时间检验应用科学奖在内的三项大奖外, Ang Li,Mengdi Hua 等华人作者也荣获了最佳学生论文奖及最佳论文亚军奖。华人作者在本届会议表现出色!