2021年浅谈多任务学习



浅谈多任务学习
全文约1w字,阅读时间约23分钟。
写此文的动机:
最近接触到的几个大厂推荐系统排序模型都无一例外的在使用多任务学习,比如腾讯PCG在推荐系统顶会RecSys 2020的最佳长文:
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations;
2019年RecSys中Youtube排序模块论文:
Recommending what video to watch next: a multitask ranking system;
以及广告推荐、新闻推荐、短视频推荐、问答推荐算法工程师们都经常使用/尝试过的MMOE模型Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts。
当然还有诸多优秀的多任务学习就不在此一一列举啦。
NLP中著名的多跳(multi-hop)问答数据集榜单HotpotQA上出现了一个多任务问答框架(2020年11月是榜1模型,名字叫IRRR),把open domain question answering中的信息抽取,排序,问答统一用一个模型来解决,既简洁又拿了高分!
引用斯坦福nlp组里这篇论文的原话:
We employ a single multi-task model to perform all the necessary subtasks---retrieving supporting facts, reranking them, and predicting the answer from all retrieved documents---in an iterative fashion。
当然不仅仅是NLP和推荐系统,最近CV和强化学习使用多任务学习进行创新的研究也是非常多的,但由于笔者对于CV和强化学习的多任务学习理解太浅,本文在谈多任务学习的时候更多会用NLP和推荐系统中的模型来举例和分析。
早在2017年,SEBASTIAN RUDER研究员就对当时的多任务学习进行了详细总结:An Overview of Multi-Task Learning in Deep Neural Networks。知乎上对于多任务学习高赞文章也是学习和翻译的这篇文章,那么在2021年已经开始的今天,笔者认为多任务学习并没有褪去光环,反而在各个机器学习任务上发光发热。个人感觉有必要再一次对多任务学习进行一次新的讨论和学习了。

下面介绍本文的基本安排,对部分章节比较熟悉的大佬们可以跳过,选感兴趣的部分进行阅读,欢迎大佬们批评指导:
1. 多任务学习的概念
2. 多任务学习为什么活跃在各个AI领域?
3. 多任务学习改进的方向在哪里?
4. 多任务学习在实际使用的时候有什么技巧和注意事项?
下文大部分时间将多任务学习(multi task learning)简称为MTL。
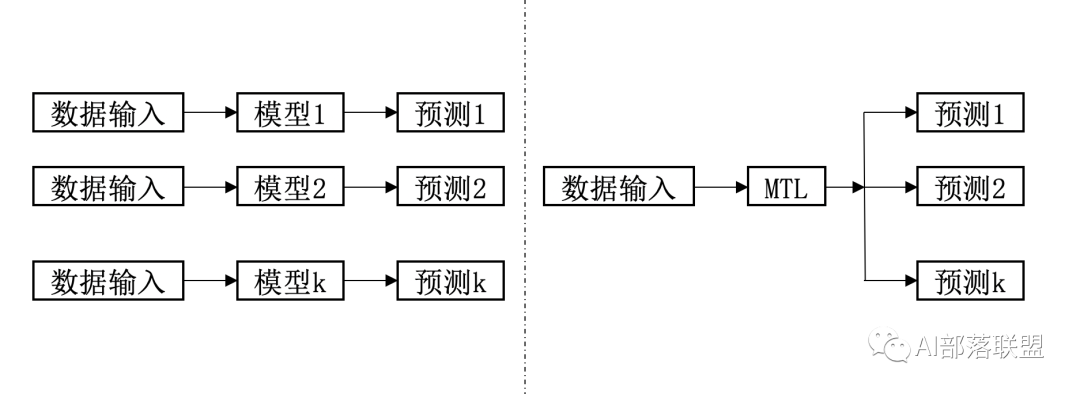
图1:单任务学习vs多任务学习
与“多”相对应是“单”,单任务学习vs多任务学习直白解释:
单任务学习(single task learning):一个loss,一个任务,例如NLP里的情感分类、NER任务一般都是可以叫单任务学习。
多任务学习(multi task learning):简单来说有多个目标函数loss同时学习的就算多任务学习。例如现在大火的短视频,短视频APP在向你展示一个大长腿/帅哥视频之前,通常既要预测你对这个视频感兴趣/不感兴趣,看多久,点赞/不点赞,转发/不转发等多个维度的信息。这么多任务既可以每个任务都搞一个模型来学,也可以一个模型多任务学习来一次全搞定的。
2.1 先谈为什么适用于多个领域:
从图1可以看出,对于有监督深度学习/机器学习而言,基本流程都是通过输入数据,模型根据输入数据来预测结果,训练阶段根据预测和监督信号之间的差异(loss)来修正模型的参数,让模型参数尽可能可能符合数据的分布。多任务学习这个框架可以将多个基本训练流程放在一起,因此不管是CV、NLP还是推荐系统,都是适合这个框架的。
虽然说适合多个领域,但如果各个领域不需要多任务学习,多任务学习也不会出现在个大AI领域了,既然多个任务可以通过拆解为多个子任务来学习,为什么还需要这个多任务学习呢?
2.2 为什么需要?
一句话:模型统一,方便高效效果好,以及那内心深处的呐喊:
几句话:
如上面短视频和hotpotqa的多任务模型例子:
方便,一次搞定多个任务,这点对工业界来说十分友好。
假设要用k个模型预测k个任务,那么k个模型预测的时间成本、计算成本、存储成本、甚至还有模型的维护成本都是大于一个模型的,咱们聪明的算法小哥哥小姐姐们当然更喜欢多任务学习了,除非多任务学习的效果远远低于单任务学习。
多任务学习不仅方便,还可能效果更好!
针对很多数据集比稀疏的任务,比如短视频转发,大部分人看了一个短视频是不会进行转发这个操作的,这么稀疏的行为,模型是很难学好的(过拟合问题严重),那我们把预测用户是否转发这个稀疏的事情和用户是否点击观看这个经常发生事情放在一起学,一定程度上会缓解模型的过拟合,提高了模型的泛化能力。
多任务学习能提高泛化能力,从另一个角度来看,对于数据很少的新任务,也解决了所谓的“冷启动问题”。
多个任务放一起学的另一个好处:
数据增强,不同任务有不同的噪声,假设不同任务噪声趋向于不同的方向,放一起学习一定程度上会抵消部分噪声,使得学习效果更好,模型也能更鲁棒。
NLP和CV中经常通过数据增强的方式来提升单个模型效果,多任务学习通过引入不同任务的数据,自然而言有类似的效果。
任务互助,某些任务所需的参数可以被其他任务辅助训练的更好,比如任务A由于各种限制始终学不好W1,但是任务B却可以轻松将W1拟合到适合任务A所需的状态,A和B搭配,干活儿不累~。
当然另一种机器学习角度的理解:多任务学习通过提供某种先验假设(inductive knowledge)来提升模型效果,这种先验假设通过增加辅助任务(具体表现为增加一个loss)来提供,相比于L1正则更方便(L1正则的先验假设是:模型参数更少更好)。
2.3 多任务学习的基本模型框架
再讲讲多任务学习的基本方法,也就能更加明白为什么各个领域都可以把这个框架拿来使用和研究了。
通常将多任务学习方法分为:hard parameter sharing和soft parameter sharing。区别在于对图1右边MTL那一个方块。
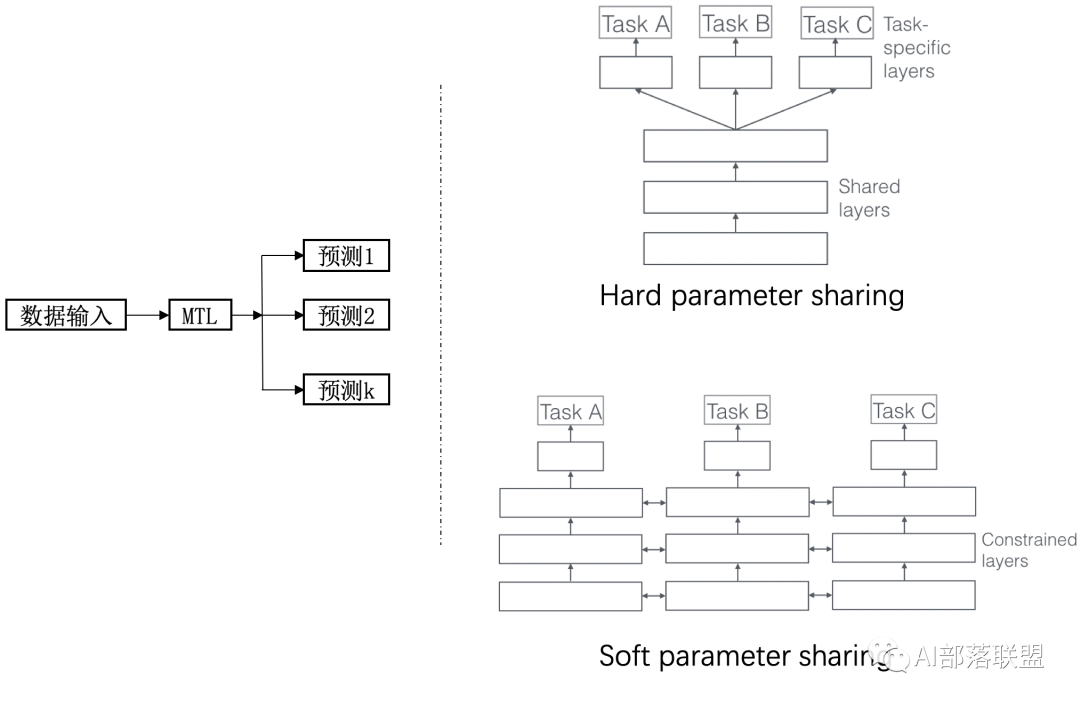
图2 硬共享和软共享
一个老当益壮的方法:hard parameter sharing
即便是2021年,hard parameter sharing依旧是很好用的baseline系统。它的基本框架如图所示。无论最后有多少个任务,底层参数统一共享,顶层参数各个模型各自独立。由于对于大部分参数进行了共享,模型的过拟合概率会降低,共享的参数越多,过拟合几率越小,共享的参数越少,越趋近于单个任务学习分别学习。形象理解为:几个人在一张桌子上吃几盘菜,自己碗里有自己的饭(北方吃面的不管了先),共享的就是桌子、几盘菜,不共享的就是自己碗里的,桌子上菜越多,自己碗里的越少,吃腻的概率更小;自己碗里一自己的饭,桌子上没几个菜,一会儿饭就吃腻了orz。
现代研究重点倾向的方法:soft parameter sharing
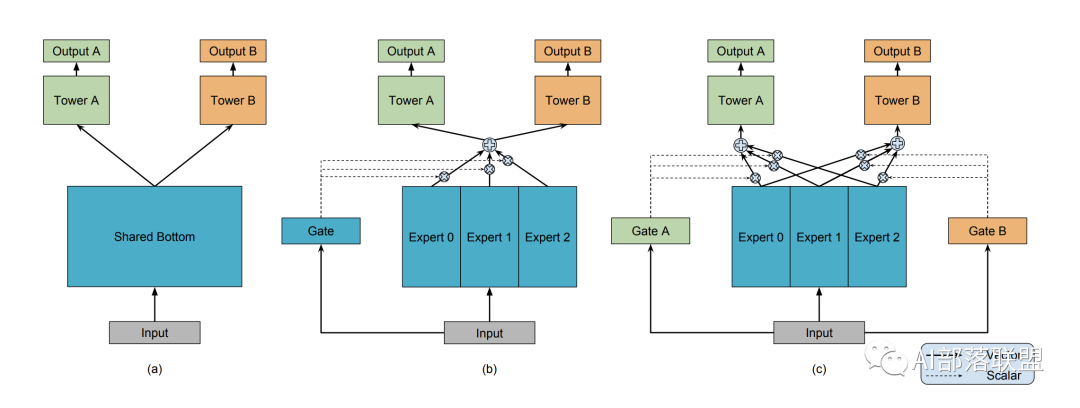
图3 引用谷歌MMOE模型图
底层共享一部分参数,自己还有独特的一部分参数不共享;顶层有自己的参数。底层共享的、不共享的参数如何融合到一起送到顶层,也就是研究人员们关注的重点啦。这里可以放上咱们经典的MMOE模型结构(图3),大家也就一目了然了。和最左边(a)的hard sharing相比,(b)和(c)都是先对Expert0-2(每个expert理解为一个隐层神经网络就可以了)进行加权求和之后再送入Tower A和B(还是一个隐层神经网络),通过Gate(还是一个隐藏层)来决定到底加权是多少。(超纲部分:聪明的小伙伴看到这个加权求和,是不是立刻就想到Attention啦?要不咱们把这个Gate改为一种Attention?对不同专家的Attention来决定求和权重,那你得想办法设计Attention的query啦,是个有趣的点。)
看到这里,相信你已经对MTL活跃在各大AI领域的原因有一定的感觉啦:把多个/单个输入送到一个大模型里(参数如何共享根据场景进行设计),预测输出送个多个不同的目标,最后放一起(比如直接相加)进行统一优化。
既然多任务学习在多个领域都能拿来用,那我们做研究/搞算法的小伙伴是不是都想拿来试一试?万一就涨几个点,搞出了一个SOTA?解决了一个基本理论问题呢?当然试不能乱试,咱得有针对性的试,先聊一聊哪些方向可以试。
我们先假设多个任务适合放在一起,对于这些适合放在一起的任务,我们有哪些方向呢?
3.1 模型结构设计:哪些参数共享,哪些参数不共享?
模型结构设计这里主要谈最近的两个大思路:把模型共享参数部分想象成榴莲千层,想象一下我们是竖着切了吃,还是横着一层侧概念拨开了吃。

图4 榴莲千层(我的口水

A . 竖着切了吃:对共享层进行区分,也就是想办法给每个任务一个独特的共享层融合方式。图3的MOE和MMOE模型就是竖着切了吃的例子。另外MMOE在MOE的基础上,多了一个GATE,意味着:多个任务既有共性(关联),也必须有自己的独特性(Task specific)。共性和独特性如何权衡:每个任务搞一个专门的权重学习网络(GATE),让模型自己去学,学好了之后对expert进行融合送给各自任务的tower,最后给到输出,2019年的SNR模型依旧是竖着切开了吃,只不过竖着切开了之后还是要每一小块都分一点放一起送给不同的流口水的人。(可能某块里面榴莲更多?)
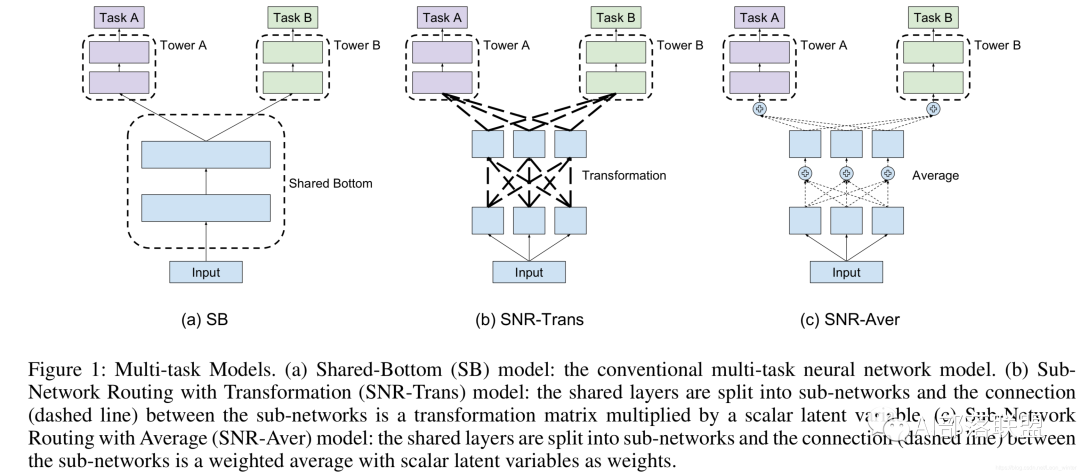
图5 谷歌SNR模型
B:一层层拿来吃:对不同任务,不同共享层级的融合方式进行设计。如果共享网络有多层,那么通常我们说的高层神经网络更具备语义信息,那我们是一开始就把所有共享网络考虑进来,还是从更高层再开始融合呢?如图6最右边的PLE所示,Input上的第1层左边2个给了粉色G,右边2个给了绿色G,3个都给了蓝色G,然后第2层左边2块给左边的粉色G和Tower,右边两块输出到绿色G和Tower。
NLP的同学可以想象一下phrase embedding, sentence embedding。先用这些embedding按层级抽取句子信息之后,再进行融合的思路。图4最右边PLE第2层中间的蓝色方块可以对应sentence embedding,第2层的粉色方块、绿色方块可以对应两个phrase embedding。虽然一句话里的多个短语有自己的含义,但是毕竟还是在一句话里,他们在自己独特的语义表示上,当然也会包含了这句话要表达核心思想。
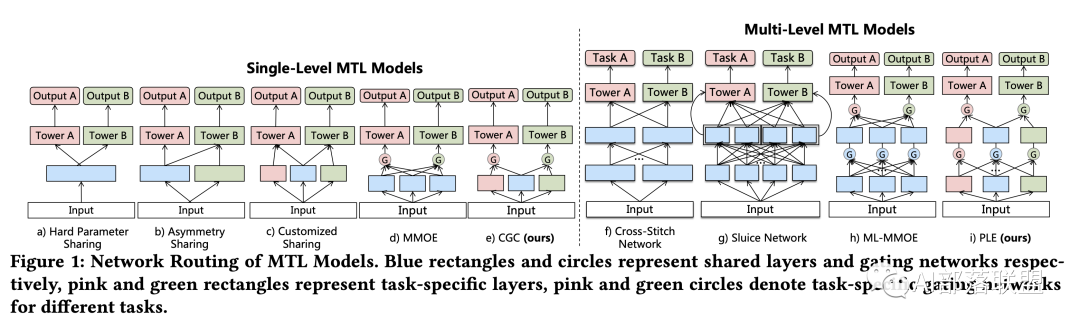
图6 腾讯PCG PLE网络(RecSys 2020 Best paper)
图片如果不清晰可以下载原文仔细看看(原文似乎要付费?或者留言找我要)。
个人感觉如果完全理解了MMOE+PLE的这两张图里所有的结构,对于模型结构共享/不共享层设计一块肯定有自己的见解啦~~
3.2 MTL的目标loss设计和优化改进
既然多个任务放在一起,往往不同任务的数据分布、重要性也都不一样,大多数情况下,直接把所有任务的loss直接求和然后反响梯度传播进行优化,是不是不合适呢?
通常多任务学习的loss function可以写为:
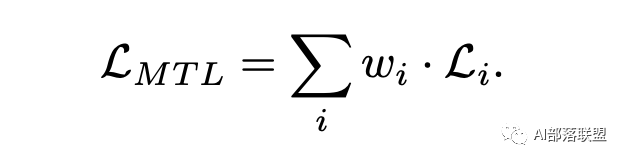
那么对于共享参数Wsh在梯度下降优化时:
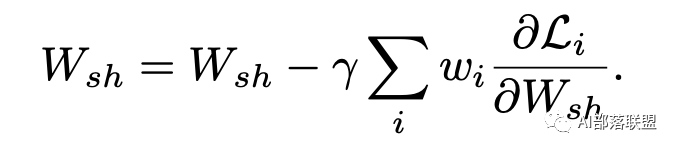
从上面的表达式可以看出,Wsh 的优化受到所有loss的影响,并且不同loss对于共享参数的影响可以使用权重w进行调节。那么优化思路自然而然可以为:
loss的权重进行设计,最简单的权重设计方式是人为给每一个任务一个权重;
根据任务的Uncertainty对权重进行计算,读者可参考经典的:
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics。
由于不同loss取值范围不一致,那么是否可以尝试通过调整loss的权重w让每个loss对共享Wsh 参数贡献平等呢?
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks,另外一篇相似思路的文章End-to-end multi-task
learning with attention 提出一种Dynamic Weight Averaging的方法来平衡不同的学习任务。
Multi-Task Learning as Multi-Objective Optimization对于MTL的多目标优化理论分析十分有趣,对于MTL优化理论推导感兴趣的同学值得一看。
小小预告一下下一篇的内容:各个任务回传的梯度如果值大小差距很大、甚至向量距离还很远、是不是有什么办法修正修正?
3.3 直接设计更合理的辅助任务!
前面的方法一个要设计网络结构,一个要设计网络优化方式,听起来其实实践上对于很多新手不是很友好,那这里再介绍一个友好的方式!对于MTL优化的一个方向为什么不是找一个更合适的辅助任务呢?只要任务找的好,辅助loss直接加上去(
辅助任务设计的常规思路:
找相关的辅助任务!
不想关的任务放一起反而会损害效果的!
如何判断任务是否想关呢?
当然对特定领域需要有一定的了解,比如视频推荐里的:
是否点击+观看时长+是否点赞+是否转发+是否收藏等等。
。
对于相关任务不太好找的场景可以尝试一下对抗任务,比如学习下如何区分不同的domain的内容。
预测数据分布,如果对抗任务,相关任务都不好找,用模型预测一下输入数据的分布呢?
比如NLP里某个词出现的频率?
推荐系统里某个用户对某一类iterm的点击频率。
正向+反向。
以机器机器翻译为例,比如英语翻译法语+法语翻英语,文本纠错任务中也有类似的思想和手段。
NLP中常见的手段:
language model作为辅助任务,万精油的辅助任务。
那推荐系统里的点击序列是不是也可以看作文本、每一个点击iterm就是单词,也可以来试一试language model呢?
(纯类比想象,虽然个人感觉有点难,毕竟推荐系统的点击序列iterm不断变化,是个非闭集,而NLP中的单词基本就那些,相对来说是个闭集)。
Pretrain,某正程度上这属于transfer learning,但是放这里应该也是可以的。
预训练本质上是在更好的初始化模型参数,随意想办法加一个帮助初始化模型参数的辅助任务也是可以的~~。
预测要做的任务该不该做,句子中的词位置对不对,该不该放这里,点击序列中该不该出现这个iterm?
这也是一个有趣的方向。
比如文本纠错任务,可不可以先预测一下这个文本是不是错误的呢?
对推荐系统感兴趣的同学可以阅读阿里的DIN:Deep Interest Evolution Network for Click-Through Rate Prediction,看看阿里爸爸如何科学的加入辅助loss。另一篇ESSM也可以从辅助任务设计这个角度学习学习:Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate。
对NLP感兴趣的同学呢,也可以从如下角度入手看看是否可行:
比如对于问答(QA)任务而言,除了预测答案的起始位置,结束位置之外,预测一下哪一句话,哪个段落是否包含答案?其实个人实践中,先过滤掉一些噪声段落,再进行QA大概率都是会提升QA效果的~~特别是有了预训练BERT、Roberta、XLNET这些大规模语言模型之后,把句子、段落是否包含答案作为二分类任务,同时预测答案的位置,模型的Capacity是完全够的!
对于信息抽取任务,是否可以把词/短语级别的sequence labeling 任务和关系抽取任务放一起呢?比如SRL和关系抽取,entity识别和entity关系抽取。不过在那之前,建议看看danqi chen这个令人绝望的模型:A Frustratingly Easy Approach for Joint Entity and Relation Extraction。
对于multilingual task和MT(机器翻译),其实有个比较简单的思路就是多个语言、多模态一起学,天然的辅助任务/多任务。另外在以前的机器翻译任务里)大家还喜欢加上POS/NER这种任务来辅助翻译。
比较有资源的大厂呢,比如微软,Multi-Task Deep Neural Networks for Natural Language Understanding,百度的ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding,
其实这一章的内容或多或少已经在上一章节中提到了不少,毕竟改进方向也就是要注意的地方了。但为什么还要有这一章?想强调一下,在一头扎入多任务模型共享参数改进、loss设计的时候不要忘记了深度学习/机器学习最纯真的东西:
数据!洗掉你的脏数据!
NLP领域大家都专注于几个数据集,很大程度上这个问题比较小,但推荐系统的同学们,这个问题就更常见了,静下心来理解你的数据、特征的含义、监督信号是不是对的,是不是符合物理含义的(比如你去预测视频点击,结果你的APP有自动播放,自动播放算点击吗?播放多久算点击?)。
对于想快速提升效果的同学,也可以关注以下几点:
如果MTL中有个别任务数据十分稀疏,可以直接尝试一下何凯明大神的Focal loss!
笔者在短视频推荐方向尝试过这个loss,对于点赞/分享/转发这种特别稀疏的信号,加上它说不定你会啪一下站起来的。
仔细分析和观察数据分布,如果某个任务数据不稀疏,但负例特别多,或者简单负例特别多,对负例进行降权/找更难的负例也可能有奇效果哦。正所谓:负例为王。
另外一个其实算trick吧?
将任务A的预测作为任务B的输入。
实现的时候需要注意:
任务B的梯度在直接传给A的预测了。
最后是:读一读机器学习/深度学习训练技巧,MTL终归是机器学习,不会逃离机器学习的范围的。该搜的超参数也得搜,Dropout,BN都得上。无论是MTL,还是single task,先把baseline做高了做对了,走在正确的道路上,你设计的模型、改正的loss,才有置信的效果~~。
笔者水平有限,望大家批评指正,也希望能对阅读的你有帮助,感觉不错的帮点个赞/在看/分享吧(这才是我的榴莲千层,是我分享的动力!)~谢谢。
放上几个经典的代码库,方便大家操作和学习:
multi task example:
https://github.com/yaringal/multi-task-learning-example.git
MMOE https://github.com/drawbridge/keras-mmoe.git
NLP福利库包含各大SOTA的BERT类模型:
https://github.com/huggingface/transformers.git
百度ERNIE https://github.com/PaddlePaddle/ERNIE.git
微软MT-DNN https://github.com/namisan/mt-dnn.git
参考文献:
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics。
ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation
ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
Multi-Task Deep Neural Networks for Natural Language Understanding
A Frustratingly Easy Approach for Joint Entity and Relation Extraction
https://ruder.io/multi-task-learning-nlp/
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
Deep Interest Evolution Network for Click-Through Rate Prediction
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations
https://zhuanlan.zhihu.com/p/32423092
Multi-Task Learning as Multi-Objective Optimization
https://zhuanlan.zhihu.com/p/68846373
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
Multi-Task Learning for Dense Prediction Tasks:A Survey
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
https://zhuanlan.zhihu.com/p/27421983
https://zhuanlan.zhihu.com/p/59413549
https://ruder.io/multi-task/
https://cs330.stanford.edu/
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


