深度学习在搜索业务中的探索与实践
作者介绍:翟艺涛,美团高级技术专家。2010年硕士毕业于中科院计算所,曾在网易有道等公司工作,先后从事网页搜索、购物搜索、计算广告等方向的研发工作,原有道词典广告算法负责人。2016年加入美团,现负责美团酒店搜索排序技术,对深度学习技术兴趣浓厚,成功将深度学习应用到美团酒店搜索中。2017Kaggle卫星图像分类大赛亚军。
本文根据美团高级技术专家翟艺涛在2018 QCon全球软件开发大会上的演讲内容整理修改而成。文章分享了深度学习在酒店搜索NLP中的应用,并重点介绍了深度学习排序模型在美团酒店搜索的演进路线。
引言
2018年12月31日,美团酒店单日入住间夜突破200万,再次创下行业的新纪录,而酒店搜索在其中起到了非常重要的作用。本文会首先介绍一下酒店搜索的业务特点,作为O2O搜索的一种,酒店搜索和传统的搜索排序相比存在很大的不同。第二部分介绍深度学习在酒店搜索NLP中的应用。第三部分会介绍深度排序模型在酒店搜索的演进路线,因为酒店业务的特点和历史原因,美团酒店搜索的模型演进路线可能跟大部分公司都不太一样。最后一部分是总结。
酒店搜索的业务特点

美团的使命是帮大家“Eat Better,Live Better”,所做的事情就是连接人与服务。用户在美团平台可以找到他们所需要的服务,商家在美团可以售卖自己提供的服务,而搜索在其中扮演的角色就是“连接器”。大部分用户通过美团App找酒店是从搜索开始的,搜索贡献了大部分的订单,是最大的流量入口。在美团首页点击 “酒店住宿”图标,就会进入上图右侧的搜索入口,用户可以选择城市和入住时间并发起搜索。
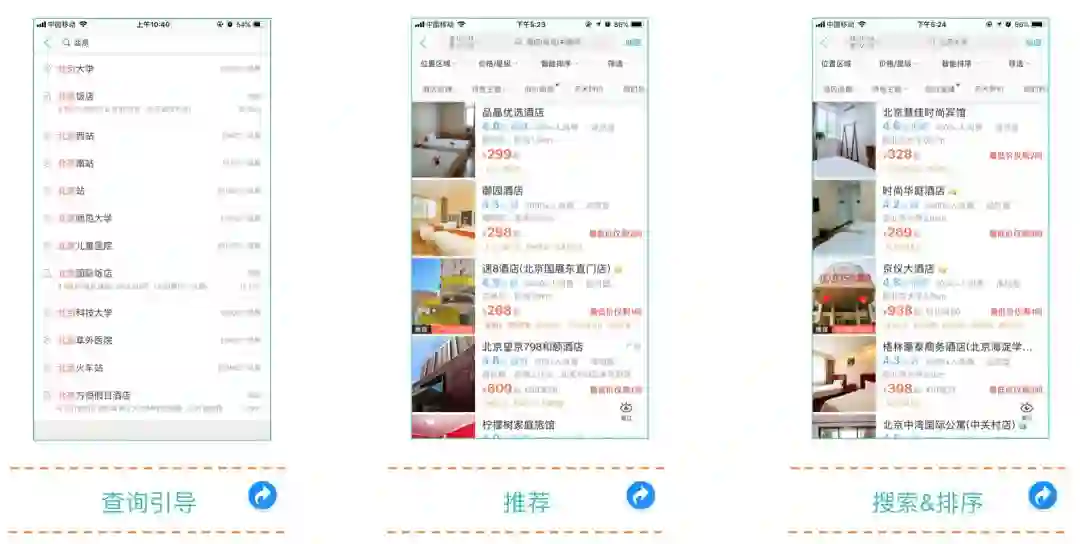
酒店搜索技术团队的工作不仅有搜索排序,还有查询引导、推荐等工作,查询引导如搜索智能提示、查询纠错等。之所以还有推荐的工作,是因为很多用户在发起搜索时不带查询词,本质上属于推荐,此外还有特定场景下针对少无结果的推荐等。本文主要介绍搜索排序这方面的工作。
不同搜索对比
现在,大家对搜索都很熟悉,常见的有网页搜索,比如Google、百度、搜狗等;商品搜索,像天猫、淘宝、京东等;还有就是O2O(Online To Offline)的搜索,典型的就是酒店的搜索。虽然都是搜索,但是用户使用搜索的目的并不相同,包括找信息、找商品、找服务等等,不同搜索之间也存在很大的差别。
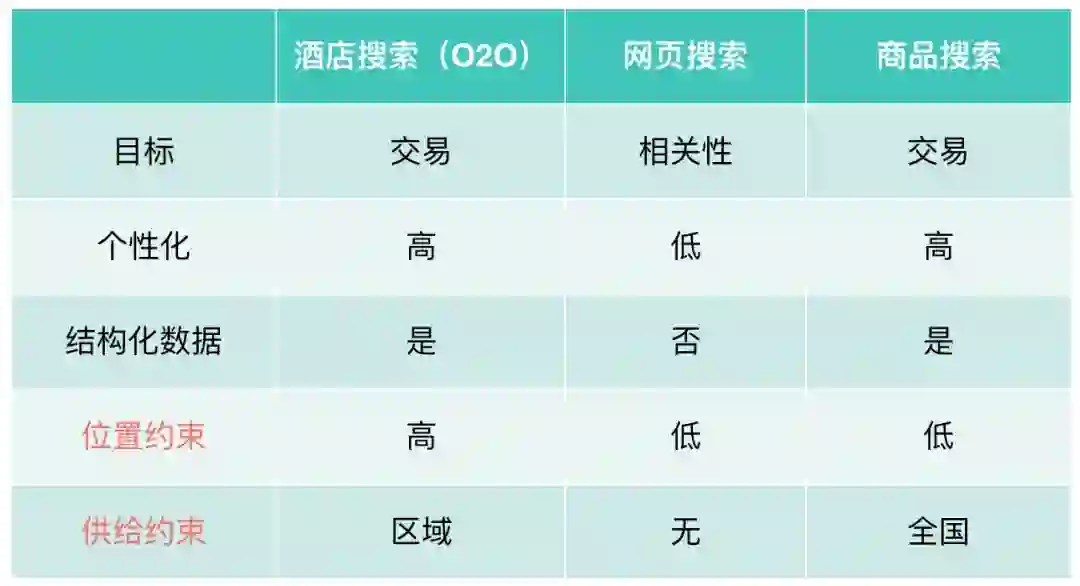
上图对不同搜索进行了简单对比,可以从5个维度展开。首先是目标维度。因为用户是来找信息,网页搜索重点是保证查询结果和用户意图的相关性,而在商品搜索和酒店搜索中,用户的主要目的是查找商品或服务,最终达成交易,目标上有较大区别。用户使用不同搜索的目的不同,从而导致不同搜索对个性化程度的要求不同。交易属性的搜索,包括商品搜索和酒店搜索,对个性化程度的要求都比较高,因为不同用户的消费水平不同,偏好也不一样。
在技术层面上,也存在很多不同点。网页搜索会索引全网的数据,这些数据不是它自己生产,数据来源非常多样,包括新闻、下载页、视频页、音乐页等各种不同的形态,所以整个数据是非结构化的,差异也很大。这意味着网页搜索需要拥有两种技术能力,数据抓取能力和数据解析能力,它们需要抓取网页并解析形成结构化数据。在这个层面上,酒店搜索和商品搜索相对就“幸福”一些,因为数据都是商家提交的结构化数据,相对来说更加规范。
此外,酒店作为一种O2O的服务,用户在线上(Online)下单,最终需要到线下(Offline)去消费,所以就有一个位置上的约束,而位置的约束也就导致出现供给侧的约束,供给只能在某个特定位置附近。比如北京大学方圆几公里之内的酒店。这两点约束在网页搜索和商品搜索中就不用考虑,网页可以无限次的进行阅读。商品搜索得益于快递业的快速发展,在北京也可以买到来自浙江的商品,供给侧的约束比较小。

介绍完不同搜索产品的特点,接下来看不同搜索产品的优化目标。通用搜索的优化目标是相关性,评价指标是DCG、NDCG、MAP等这些指标,要求查询结果和用户意图相关。对商品搜索来说,不同电商平台的优化目标不太一样,有的目标是最大化GMV,有的目标是最大化点击率,这些在技术上都可以实现。
而对酒店搜索而言,因为它属于O2O的业务形态,线上下单,线下消费,这就要求搜索结果必须和用户的查询意图“强相关”。这个“强相关”包括两层含义,显性相关和隐性相关。举个例子,用户搜索“北京大学”,那么他的诉求很明确,就是要找“北京大学”附近的酒店,这种属于用户明确告诉平台自己的位置诉求。但是,如果用户在本地搜索“七天”,即使用户没有明确说明酒店的具体位置,我们也知道,用户可能想找的是距离自己比较近的“七天酒店”,这时候就需要建模用户的隐性位置诉求。
美团是一个交易平台,大部分用户使用美团是为了达成交易,所以要优化用户的购买体验。刻画用户购买体验的核心业务指标是访购率,用来描述用户在美团是否顺畅的完成了购买,需要优化访购率这个指标。总结一下,酒店搜索不仅要解决相关性,尽量优化用户购买体验、优化访购率等指标,同时还要照顾到业务诉求。
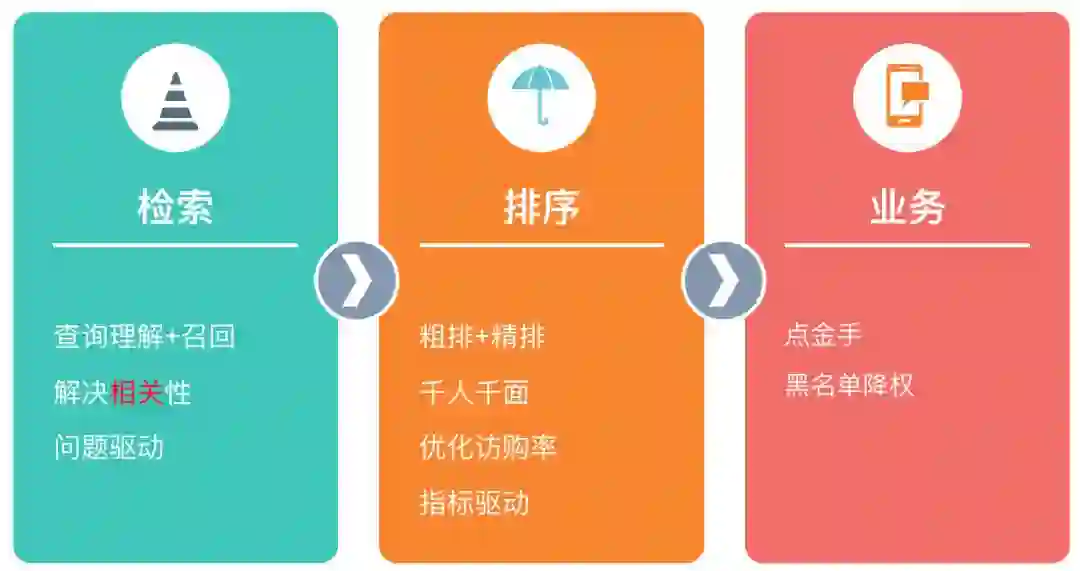
根据上面的分析,酒店搜索的整个搜索框架就可以拆分成三大模块:检索、排序以及业务规则。检索层包括查询理解和召回两部分,主要解决相关性问题。查询理解做的事情就是理解用户意图,召回根据用户意图来召回相关的酒店,两者强耦合,需要放在一起。检索的核心是语义理解,比如用户搜索“北京大学”,平台就知道用户想找的是“北京大学附近的酒店”,所以这个模块的优化方式是问题驱动,不断地发现问题、解决问题来进行迭代。
接下来,从检索模块检索出来的酒店都已经是满足用户需求的酒店了。还是上面“北京大学”的那个例子,检索模块已经检索出来几百家“北京大学”附近的酒店,这些都是和用户的查询词“北京大学”相关的,怎么把用户最有可能购买的酒店排到前面呢?这就是排序模块要做的事情。
排序模块使用机器学习和深度学习的技术提供“千人千面”的排序结果,如果是经常预定经济连锁型酒店的用户,排序模块就把经济连锁型酒店排到前面。针对消费水平比较高,对酒店要求比较高的用户,排序模块就把高档酒店排到前面,对每个用户都可以做到个性化定制。排序属于典型的技术驱动模块,优化目标是访购率,用这个技术指标驱动技术团队不断进行迭代和优化。
最后是业务层面,比如有些商家会在美团上刷单作弊,针对这些商家需要做降权处理。
整体框架
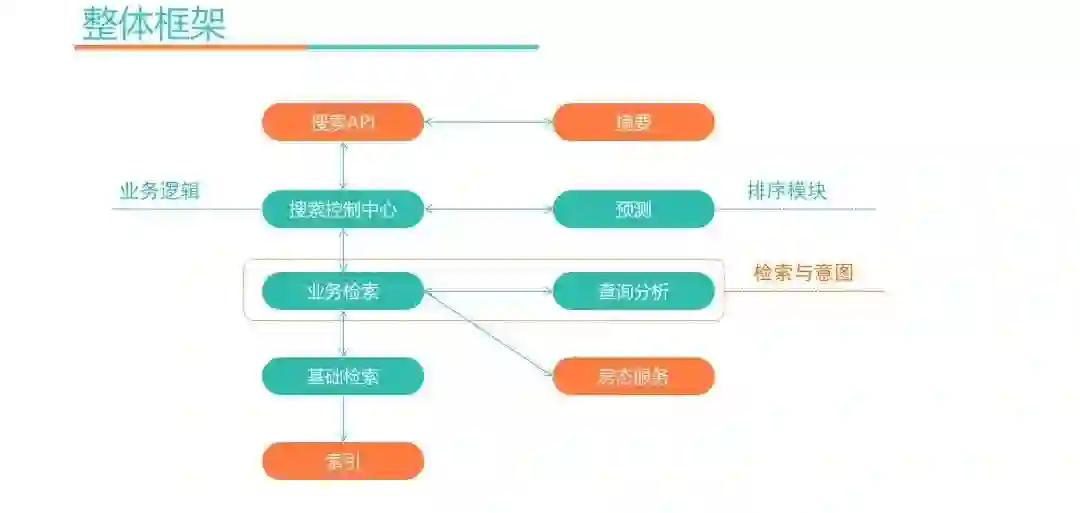
上图是搜索的整体框架,这里详细描述下调用过程:
搜索API负责接收用户的查询词并发送给搜索控制中心。
控制中心把接收到的查询请求发送到检索与意图模块,搜索词会先经过查询分析模块做用户的查询意图分析,分析完之后,会把用户的查询意图分析结果传回去给业务检索模块,业务检索模块根据意图识别结果形成查询条件,然后去基础检索端查询结果。
基础检索访问索引得到查询结果后,再把结果返回给上层。
业务检索模块获取基础的检索结果后,会调用一些外部服务如房态服务过滤一些满房的酒店,再把结果返回给控制中心。
此时,控制中心得到的都是和用户查询意图强相关的结果,这时就需要利用机器学习技术做排序。通过预测模块对每个酒店做访购率预测,控制中心获取预测模块的排序结果后,再根据业务逻辑做一些调整,最终返回结果给搜索API。
可以看到,模块划分和前文描述的思想一致,检索模块主要解决用户意图识别和召回问题,也就是解决相关性。预测模块做访购率预测,业务逻辑放在搜索控制中心实现。接下来会介绍一下意图理解和排序模块中涉及的一些深度学习技术。
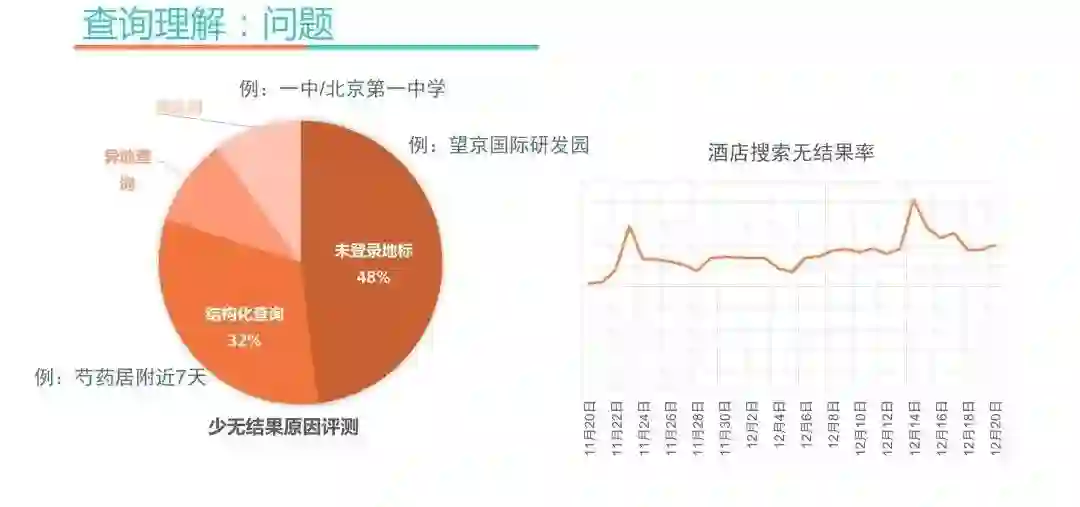
先来看下查询理解的问题,这个模块通过数据分析和Case分析,不断的发现问题、解决问题来迭代优化。之前的评测发现少无结果的原因,主要包括以下几种:
地标词:比如用户搜索“望京国际研发园”,但是后台没有一家酒店包含“望京国际研发园”这几个字,其实用户想找的是望京国际研发园附近的酒店。
结构化查询:比如芍药居附近7天,酒店描述信息中没有“附近”这个词,搜索体验就比较差。这种需要对查询词做成分识别,丢掉不重要的词,并且对不用类别的Term走不同的检索域。
异地查询:用户在北京搜索“大雁塔”没有结果,其实用户的真实意图是西安大雁塔附近的酒店,这种需要做异地需求识别并进行异地跳转。
同义词:在北京搜索“一中”和搜索“北京第一中学”,其实都是同一个意思,需要挖掘同义词。
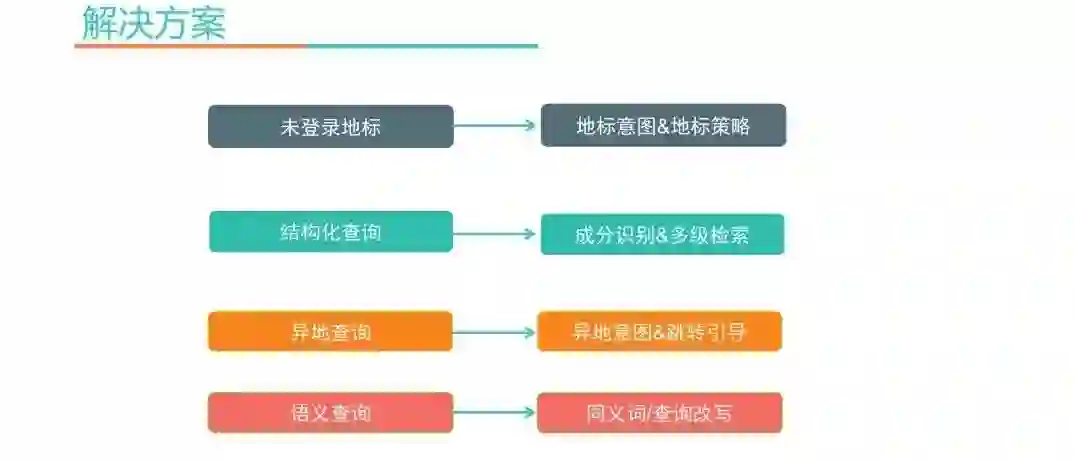
针对这几类问题,我们分别作了以下工作:
针对地标词问题,提供地标意图识别和地标策略,把地标类别的查询词改成按经纬度进行画圈检索。
针对结构化查询的问题,我们对查询词做了成分识别,设计了少无结果时的多级检索架构。
针对异地查询的问题,做异地意图识别和异地的跳转引导。
针对语义查询的问题,做同义词和查询改写。
这里的每一个模块都用到了机器学习和深度学习的技术,本文挑选两个酒店搜索中比较特殊的问题进行介绍。

地标问题是O2O搜索的一个典型问题,在网页搜索和商品搜索中都较少出现此类问题。当用户搜索类似“望京国际研发园”这种查询词的时候,因为搜索的相关性是根据文本计算的,需要酒店描述中有相关文字,如果酒店的描述信息中没有这个词,那就检索不出来。比如昆泰酒店,虽然就在望京国际研发园旁边,但是它的描述信息中并没有出现“望京国际研发园”,所以就无法检索出来,这会导致用户体验较差。
经过分析,我们发现有一类查询词是针对特定地点的搜索,用户的诉求是找特定地点附近的酒店,这种情况下走文本匹配大概率是没有结果的。这个问题的解法是针对这种类型的查询词,从“文本匹配”改成“坐标匹配”,首先分析查询词是不是有地标意图,如果是的话就不走文本匹配了,改走坐标匹配,检索出来这个坐标附近的酒店就可以了。这时就产生了两个问题:第一,怎么确定哪些查询词有地标意图;第二,怎么获取经纬度信息。

针对这个问题,我们做了地标策略,步骤如下:
多渠道获取可能包含地标词的候选集,这些候选集包括用户少无结果的查询词,以及一些酒店提供的描述信息。
对候选集合进行命名实体识别(NER,Named Entity Recognition),可以得到各个命名实体的类型,标识为“地标”类型的就是疑似地标词。
把疑似地标词放到美团地图服务中获取经纬度,经过人工校验无误后,存入线上数据库中;线上来查询请求时,先会去匹配精准地标库,如果匹配成功,说明这个查询词是地标意图,这时就不走文本检索了,直接在意图服务层走经纬度检索。
经过人工校验的精准地标库补充到NER模型的训练数据中,持续优化NER模型。
这里提到了NER模型,下面对它做一下详细的介绍。

NER是命名实体识别,是机器学习中的序列标注问题,比如输入“北大附近的七天”,就会标注出来每个词的成分,这里“北大”是地标,“七天”是酒店品牌。这里的类别是根据业务特点自己定义的,酒店业务中有地标、品牌、商圈等不同的类别。与分类问题相比,序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与前后的预测标签相关,即预测标签序列之间有强相互依赖关系。
解决序列标注问题的经典模型是CRF(Conditional Random Field,条件随机场),也是我们刚开始尝试的模型。条件随机场可以看做是逻辑回归的序列化版本,逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型,可以看做是考虑了上下文的分类模型。
机器学习问题的求解就是“数据+模型+特征”,数据方面先根据业务特点定义了几种实体类别,然后通过“人工+规则”的方法标注了一批数据。特征方面提取了包括词性、Term文本特征等,还定义了一些特征模板,特征模板是CRF中人工定义的一些二值函数,通过这些二值函数,可以挖掘命名实体内部以及上下文的构成特点。标注数据、模型、特征都有了,就可以训练CRF模型,这是线上NER问题的第一版模型。
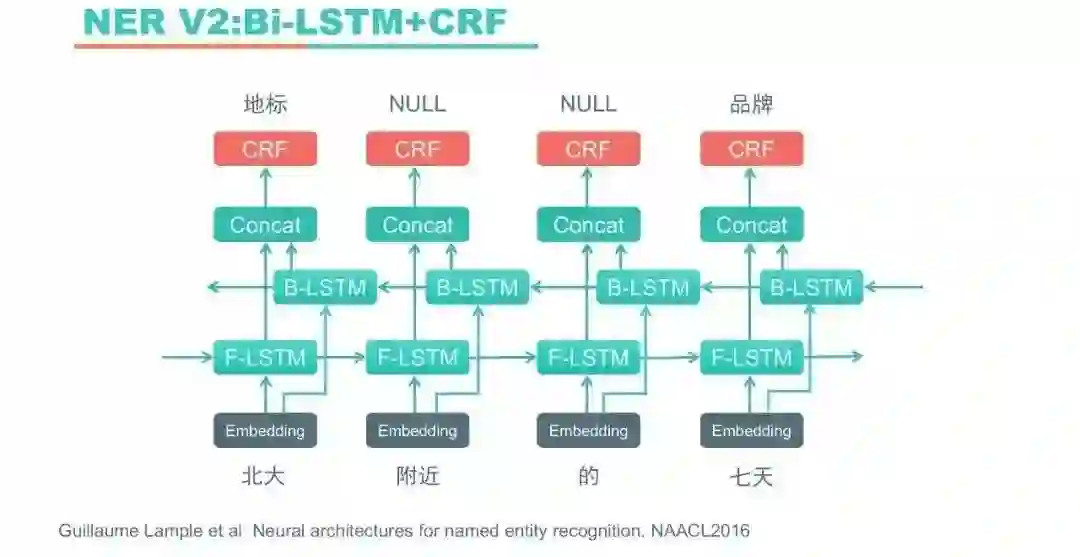
随着深度学习的发展,用Word Embedding词向量作为输入,叠加神经网络单元的方法渐渐成为NLP领域新的研究方向。基于双向LSTM(Long Short-Term Memory)+CRF的方法成为NER的主流方法,这种方法采用双向LSTM单元作为特征提取器替代原有的人工特征,不需要专门的领域知识,框架也通用。Embedding输入也有多种形式,可以是词向量,可以是字向量,也可以是字向量和词向量的拼接。
我们尝试了双向LSTM+CRF,并在实际应用中做了些改动:由于在CRF阶段已经积累了一批人工特征,实验发现把这些特征加上效果更好。加了人工特征的双向LSTM+CRF是酒店搜索NER问题的主模型。
当然,针对LSTM+CRF的方法已经有了很多的改进,比如还有一种NER的方法是融合CNN+LSTM+CRF,主要改进点是多了一个CNN模块来提取字级别的特征。CNN的输入是字级别的Embedding,通过卷积和池化等操作来提取字级别的特征,然后和词的Embedding拼接起来放入LSTM。这种方法在两个公开数据集上面取得了最好的结果,也是未来尝试的方向之一。
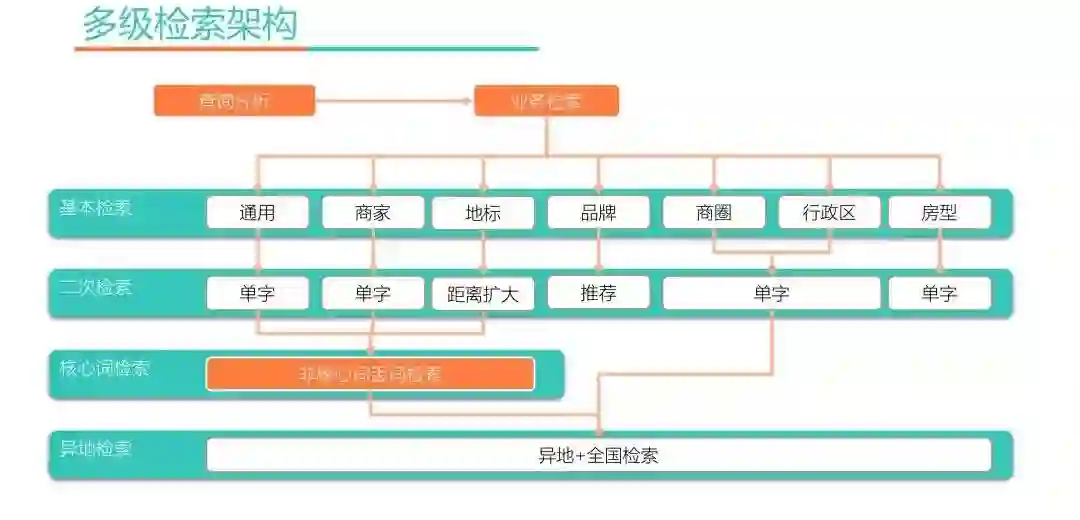
为了解决少无结果的问题,我们设计了多级检索架构,如上图所示,主要分4个层次:基本检索、二次检索、核心词检索和异地检索。
基本检索会根据查询词的意图选择特定的检索策略,比如地标意图走经纬度检索,品牌意图只检索品牌域和商家名。
基本检索少无结果会进行二次检索,二次检索也是分意图的,不同意图类型会有不同的检索策略,地标意图是经纬度检索的,二次检索的时候就需要扩大检索半径;品牌意图的查询词,因为很多品牌在一些城市没有开店,比如香格里拉在很多小城市并没有开店,这时比较好的做法,是推荐给用户该城市最好的酒店。
如果还是少无结果,会走核心词检索,只保留核心词检索一遍。丢掉非核心词有多种方式,一种是删除一些运营定义的无意义词,一种是保留NER模型识别出来的主要实体类型。此外还有一个TermWeight的模型,对每个词都有一个重要性的权重,可以把一些不重要的词丢掉。
在还没有结果的情况下,会选择”异地+全国“检索,即更换城市或者在全国范围内进行检索。
多级检索架构上线后,线上的无结果率就大幅度降低了。
排序
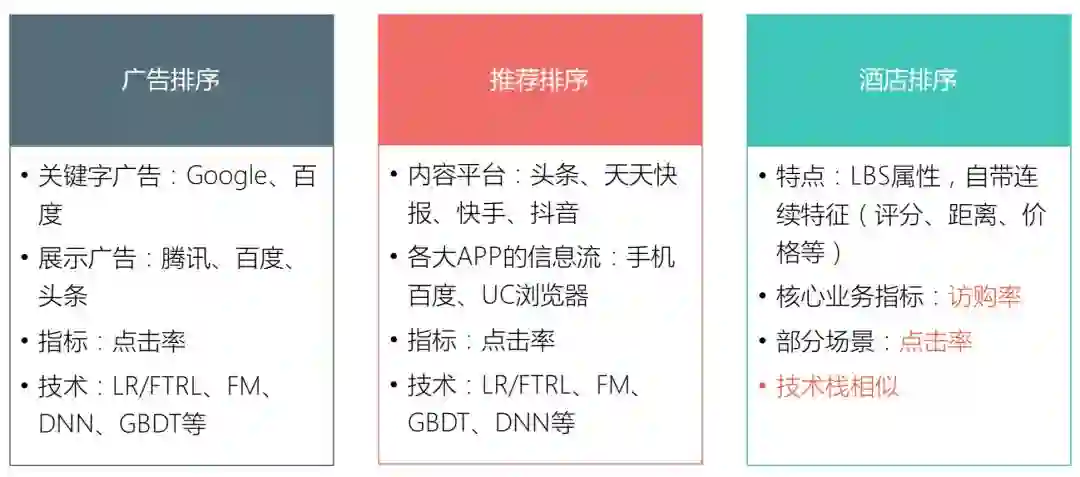
排序其实是一个典型的技术问题,业界应用比较广泛的有广告排序和推荐排序,广告排序比如Google和百度的关键字广告排序,今日头条、腾讯的展示广告排序。推荐排序比如快手、抖音这些短视频平台,以及各大App、浏览器的信息流。广告排序和推荐排序优化的目标都是点击率,技术栈也比较相似,包括LR/FTRL、FM/FFM、GBDT、DNN等模型。
跟以上两种排序应用相比,酒店排序有自己的业务特点,因为美团酒店具有LBS属性和交易属性,天生自带很多连续特征,如酒店价格、酒店评分、酒店离用户的距离等,这些连续特征是决定用户购买行为的最重要因素。优化目标也不一样,大部分场景下酒店搜索的优化目标是访购率,部分场景下优化目标是点击率。在技术层面,酒店排序整体的技术栈和广告、推荐比较相似,都可以使用LR/FTRL、FM/FFM、GBDT、DNN等模型。
面临的挑战
具体到酒店排序工作,我们面临一些不一样的挑战,主要包括以下4点:
数据稀疏。住酒店本身是一种低频行为,大部分用户一年也就住一两次,导致很多特征的覆盖率比较低。
业务众多。美团酒店包括国内酒店业务、境外酒店业务,以及长租、钟点房等业务,同时有美团和点评两个不同的App。
场景复杂。按照用户的位置可以分成本地和异地,按照用户的诉求可以分成商务、旅游、本地休闲等几大类,这些用户之间差异很明显。比如商务用户会有大量复购行为,典型例子是美团员工的出差场景,美团在上海和北京各有一个总部,如果美团的同学去上海出差,大概率会在公司差旅标准内选一家离公司近的酒店,从而会在同一家酒店产生大量的复购行为;但是如果是一个旅游用户,他就很少反复去同一个地方。
供给约束。酒店行业供给的变化很快,一个酒店只有那么多房间,一天能提供的间夜量是固定的,全部订出的话,用户提价也不会提供新的房间,这种情况在劳动节、国庆这种节假日特别明显。
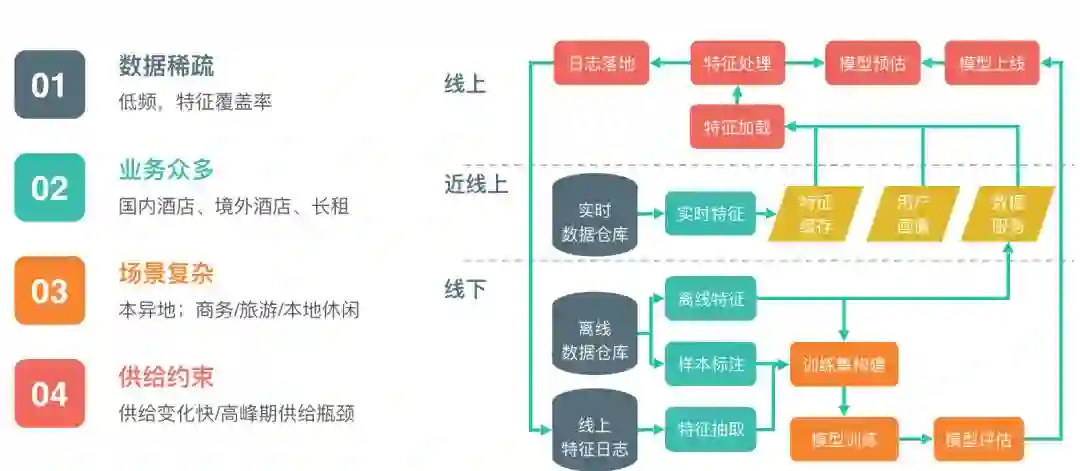
上图右侧是排序的整体架构图,分为线下、线上和近线上三个部分。在线下部分,主要做离线的模型调优和评估,线上部分做预测。这里比较特别的是近线上部分,我们在实时层面做了大量的工作,包括用户的实时行为、酒店实时价格、实时库存等等,以应对供给变化快的特点。

这里介绍一个业务特点导致的比较独特的问题:模型切分。美团酒店有很多业务场景,包括国内酒店、境外酒店、长租、钟点房等;还有两个App,美团App和大众点评App;还有搜索和筛选两种场景,搜索带查询词,筛选没有查询词,两种场景差异较大;从地理位置维度,还可以分成本地和异地两种场景。
面对这么多的业务场景,第一个问题就是模型怎么设计,是用统一的大模型,还是分成很多不同的小模型?我们可以用一个大模型Cover所有的场景,用特征来区分不同场景的差异,好处是统一模型维护和优化成本低。也可以划分很多小模型,这里有一个比较好的比喻,多个专科专家会诊,胜过一个全科医生。切分模型后,可以避免差异较大的业务之间互相影响,也方便对特殊场景进行专门的优化。
在模型切分上,主要考虑三个因素:
第一,业务之间的差异性。比如长租和境外差异很大,国内酒店和境外业务差异也很大,这种需要拆分。
第二,细分后的数据量。场景分的越细,数据量就越小,会导致两个问题,一是特征的覆盖率进一步降低;二是数据量变小后,不利于后续的模型迭代,一些复杂模型对数据量有很高的要求。我们做过尝试,国内酒店场景下,美团和大众点评两个App数据量都很大,而且用户也很不一样,所以做了模型拆分;但是境外酒店,因为本身是新业务数据量较小,就没有再进行细分。
第三,一切以线上指标为准。我们会做大量的实验,看当前数据量下怎么拆分效果更好,比如美团App的国内酒店,我们发现把搜索和筛选拆开后,效果更好;筛选因为数据量特别大,拆分成本、异地效果也更好,但是如果搜索场景拆分成本地、异地模型就没有额外收益了。最终,一切都要以线上的实际表现为准。
模型演进

接下来介绍一下排序模型的演进过程,因为业务特点及历史原因,酒店搜索的排序模型走了一条不一样的演进路线。大家可以看业界其他公司点击率模型的演进,很多都是从LR/FTRL开始,然后进化到FM/FFM,或者用GBDT+LR搞定特征组合,然后开始Wide&Deep。
酒店搜索的演进就不太一样。酒店业务天生自带大量连续特征,如酒店价格、酒店和用户的距离、酒店评分等,因此初始阶段使用了对连续特征比较友好的树模型。在探索深度排序模型的时候,因为已经有了大量优化过的连续特征,导致我们的整个思路也不太一样,主要是借鉴一些模型的思想,结合业务特点做尝试,下面逐一进行介绍。
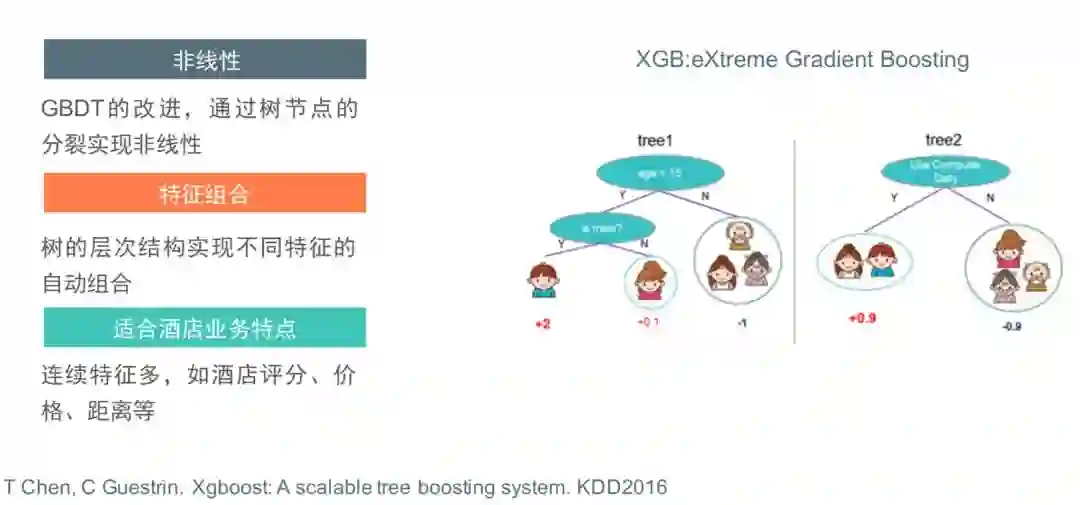
初始阶段线上使用的模型是XGB(XGBOOST, eXtreme Gradient Boosting)。作为GBDT的改进,XGB实现了非线性和自动的特征组合。树节点的分裂其实就实现了非线性,树的层次结构实现了不同特征的自动组合,而且树模型对特征的包容性非常好,树的分裂通过判断相对大小来实现,不需要对特征做特殊处理,适合连续特征。
树模型的这些特点确实很适合酒店这种连续特征多的场景,至今为止,XGB都是数据量较小场景下的主模型。但是树模型优化到后期遇到了瓶颈,比如特征工程收益变小、增大数据量没有额外收益等,此外树模型不适合做在线学习的问题愈发严重。酒店用户在劳动节、国庆节等节假日行为有较大不同,这时需要快速更新模型,我们尝试过只更新最后几棵树的做法,效果不佳。考虑到未来进一步的业务发展,有必要做模型升级。
模型探索的原则是从简单到复杂,逐步积累经验,所以首先尝试了结构比较简单的MLP(Multiple-Layer Perception)多层感知机,也就是全连接神经网络。神经网络是一种比树模型“天花板”更高的模型,“天花板”更高两层意思:第一层意思,可以优化提升的空间更大,比如可以进行在线学习,可以做多目标学习;第二层意思,模型的容量更大,“胃口”更大,可以“吃下”更多数据。此外它的表达能力也更强,可以拟合任何函数,网络结构和参数可以调整的空间也更大。但是它的优点同时也是它的缺点,因为它的网络结构、参数等可以调整的空间更大,神经网需要做很多的参数和网络结构层面的调整。
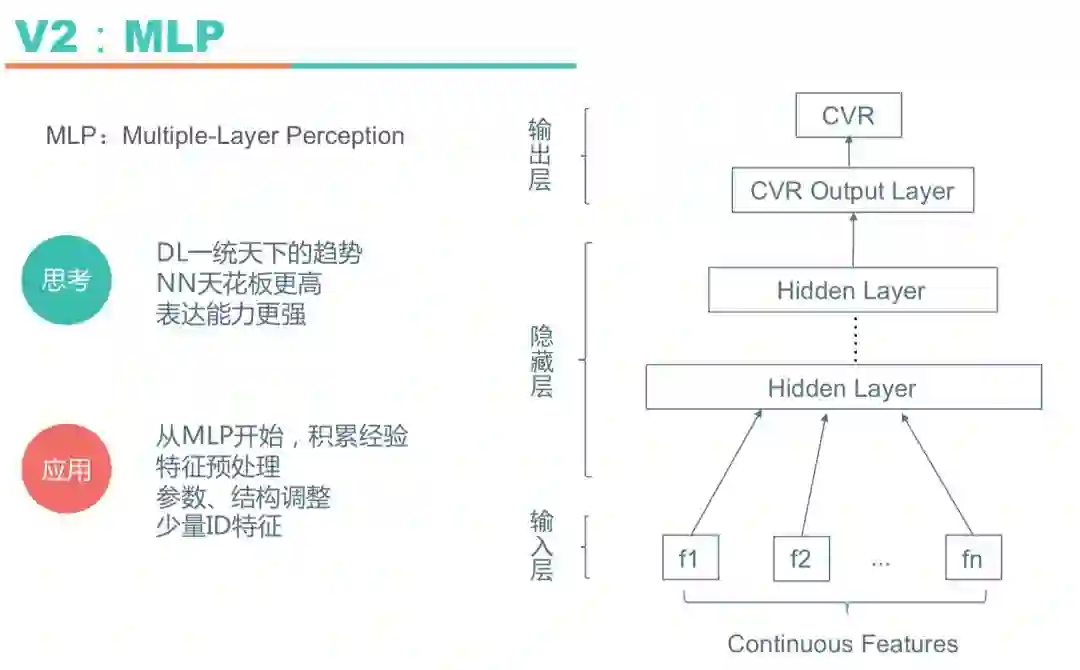
上图是MLP的网络结构图,包含输入层、若干个隐藏层、输出层。在很长一段时间内,在特征相同的情况下,MLP效果不如XGB,所以有段时间线上使用的是XGB和MLP的融合模型。后来经过大量的网络结构调整和参数调整,调参经验越来越丰富,MLP才逐步超越XGB。这里额外说明一下,酒店搜索中有少量的ID类特征,在第一版MLP里ID类特征是直接当做连续特征处理的。比如城市ID,ID的序关系有一定的物理意义,大城市ID普遍较小,小城市开城晚一些,ID较大。

在MLP阶段我们对网络结构做了大量实验,尝试过三种网络结构:平行结构、菱形结构、金字塔结构。在很多论文中提到三者相比平行结构效果最好,但是因为酒店搜索的数据不太一样,实验发现金字塔结构效果最好,即上图最右边的“1024-512-256”的网络结构。同时还实验了不同网络层数对效果的影响,实验发现3-6层的网络效果较好,更深的网络没有额外收益而且线上响应时间会变慢,后面各种模型探索都是基于3到6层的金字塔网络结构进行尝试。
MLP上线之后,我们开始思考接下来的探索方向。在树模型阶段,酒店搜索组就在连续特征上做了很多探索,连续特征方面很难有比较大的提升空间;同时业界的研究重点也放在离散特征方面,所以离散特征应该是下一步的重点方向。
深度排序模型对离散特征的处理有两大类方法,一类是对离散特征做Embedding,这样离散特征就可以表示成连续的向量放到神经网络中去,另一类是Wide&Deep,把离散特征直接加到Wide侧。我们先尝试了第一种,即对离散特征做Embedding的方法,借鉴的是FNN的思想。其实离散特征做Embedding的想法很早就出现了,FM就是把离散特征表示成K维向量,通过把高维离散特征表示成低维向量增加模型泛化能力。
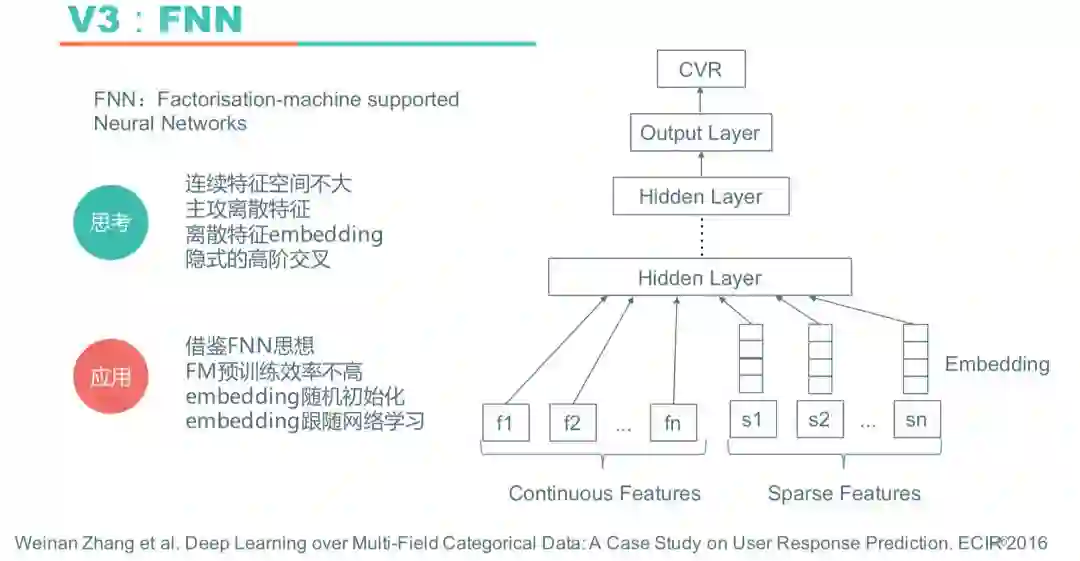
实际使用中,我们稍微做了一些改动,实验中发现使用FM预训练的效率不高,所以尝试了不做预训练直接把Embedding随机初始化,然后让Embedding跟随网络一起学习,实验结果发现比FM预训练效果还要好一点。最后的做法是没有用FM做预训练,让Embedding随机初始化并随网络学习,上图是线上的V3模型。

FNN的成功上线证明离散特征Embedding这个方向值得深挖,所以我们接着实验了DeepFM。DeepFM相对于Wide&Deep的改进,非常类似于FM相对LR的改进,都认为LR部分的人工组合特征是个耗时耗力的事情,而FM模块可以通过向量内积的方式直接求出二阶组合特征。DeepFM使用FM替换了Wide&Deep中的LR,离散特征的Embedding同时“喂”给神经网和FM,这部分Embedding是共享的,Embedding在网络的优化过程中自动学习,不需要做预训练,同时FM Layer包含了一阶特征和二阶的组合特征,表达能力更强。我们尝试了DeepFM,线下有提升线上波动提升,并没有达到上线的标准,最终没有全量。
尽管DeepFM没有成功上线,但这并没有动摇我们对Embedding的信心,接下来尝试了PNN。PNN的网络重点在Product上面,在点击率预估中,认为特征之间的关系更多是一种And“且”的关系, 而非Add“加”的关系,例如性别为男且用华为手机的人,他定酒店时属于商务出行场景的概率更高。
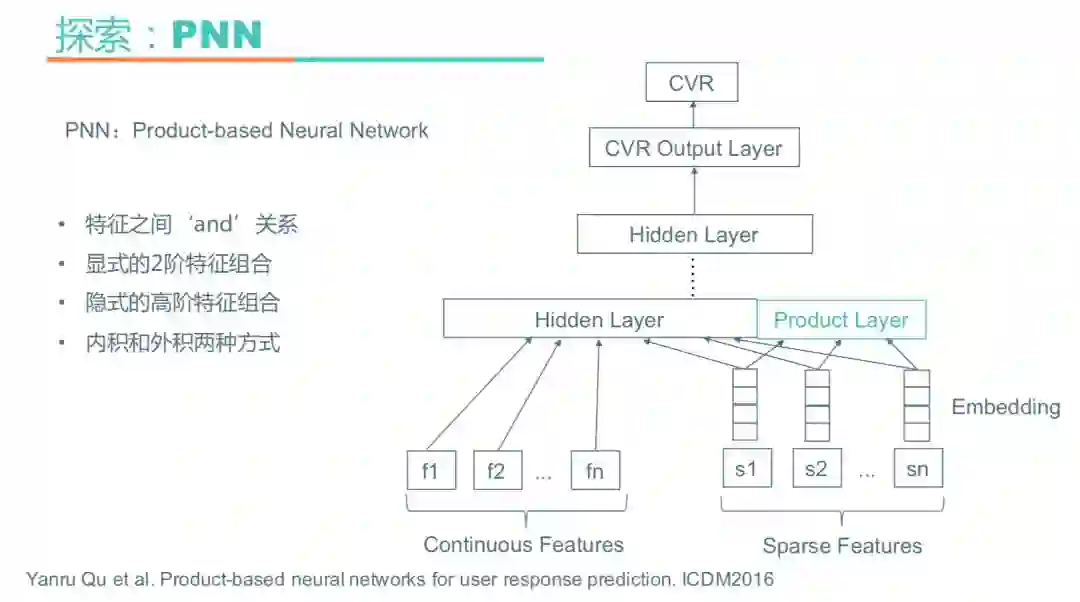
PNN使用了Product Layer进行显式的二阶特征组合。上图右边是PNN的网络结构图,依然对离散特征做Embedding,Embedding向量同时送往隐层和Product层,Product通过内积或者外积的方式,对特征做显式的二阶交叉,之后再送入神经网的隐层,这样可以做到显式的二阶组合和隐式的高阶特征组合。特征交叉基于乘法的运算实现,有两种方式:内积和外积。我们尝试了内积的方式,线下略有提升线上也是波动提升,没有达到上线标准,所以最终也没有全量上线。

PNN之后我们认为Embedding还可以再尝试一下,于是又尝试了DCN(Deep&Cross Network)。DCN引入了一个Cross Network进行显式的高阶特征交叉。上图右边是论文中的图,可以看到Deep&Cross中用了两种网络,Deep网络和Cross网络,两种网络并行,输入都一样,在最后一层再Stack到一起。
Deep网络和前面几种网络一样,包括连续特征和离散特征的Embedding,Cross网络是DCN的特色,在Cross网络里面,通过巧妙的设计实现了特征之间的显式高阶交叉。看上图左下角的Cross结构示意,这里的x是每一层的输入,也就是上一层的输出。Feature Crossing部分包括了原始输入x0、本层输入x的转置、权重w三项,三项相乘其实就做了本层输入和原始输入的特征交叉,x1就包含了二阶的交叉信息,x2就包含了三阶的交叉信息,就可以通过控制Cross的层数显式控制交叉的阶数。
不得不说,DCN在理论上很漂亮,我们也尝试了一下。但是很可惜,线下有提升线上波动提升,依然未能达到上线的标准,最终未能全量上线。
经过DeepFM、PNN、DCN的洗礼,促使我们开始反思,为什么在学术上特别有效的模型,反而在酒店搜索场景下不能全量上线呢?它们在线下都有提升,在线上也有提升,但是线上提升较小且有波动。
经过认真分析我们发现可能有两个原因:第一,连续特征的影响,XGB时代尝试了600多种连续特征,实际线上使用的连续特征接近400种,这部分特征太强了; 第二,离散特征太少,离散特征只有百万级别,但是Embedding特别适合离散特征多的情况。接下来方向就很明确了:补离散特征的课。
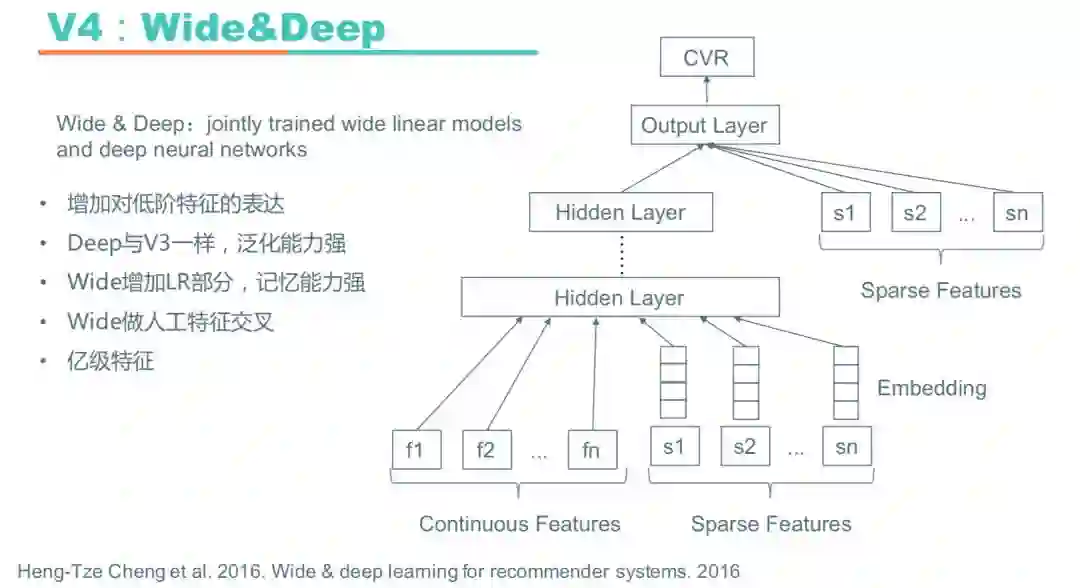
最终,我们还是把目光转回Wide&Deep。Wide&Deep同时训练一个Wide侧的线性模型和一个Deep侧的神经网络,Wide部分提供了记忆能力,关注用户有过的历史行为,Deep部分提供了泛化能力,关注一些没有历史行为的Item。之前的工作主要集中在Deep测,对低阶特征的表达存在缺失,所以我们添加了LR模块以增加对低阶特征的表达,Deep部分和之前的V3一样。刚开始只用了少量的ID类特征,效果一般,后来加了大量人工的交叉特征,特征维度达到了亿级别后效果才得到很好的提升。下图是我们的V4模型:
接下来介绍一下优化目标的迭代过程(后面讲MTL会涉及这部分内容)。酒店搜索的业务目标是优化用户的购买体验,模型的优化指标是用户的真实消费率,怎么优化这个目标呢? 通过分析用户的行为路径可以把用户的行为拆解成“展示->点击->下单->支付->消费”等5个环节,这其中每个环节都可能存在用户流失,比如有些用户支付完成后,因为部分商家确认比较慢,用户等不及就取消了。

刚开始我们采用了方案1,对每一个环节建模(真实消费率=用户点击率×下单率×支付率×消费率)。优点是非常简单直接且符合逻辑,每个模块分工明确,容易确认问题出在哪里。缺点也很明显,首先是特征重复,4个模型在用户维度和商家维度的特征全部一样,其次模型之间是相乘关系且层数过多,容易导致误差逐层传递,此外4个模型也增加了运维成本。后来慢慢进化到了方案2的“End to End”方式,直接预测用户的真实消费率,这时只需要把正样本设定为实际消费的样本,一个模型就够了,开发和运维成本较小,模型间特征也可以复用,缺点就是链路比较长,上线时经常遇到AB测抖动问题。
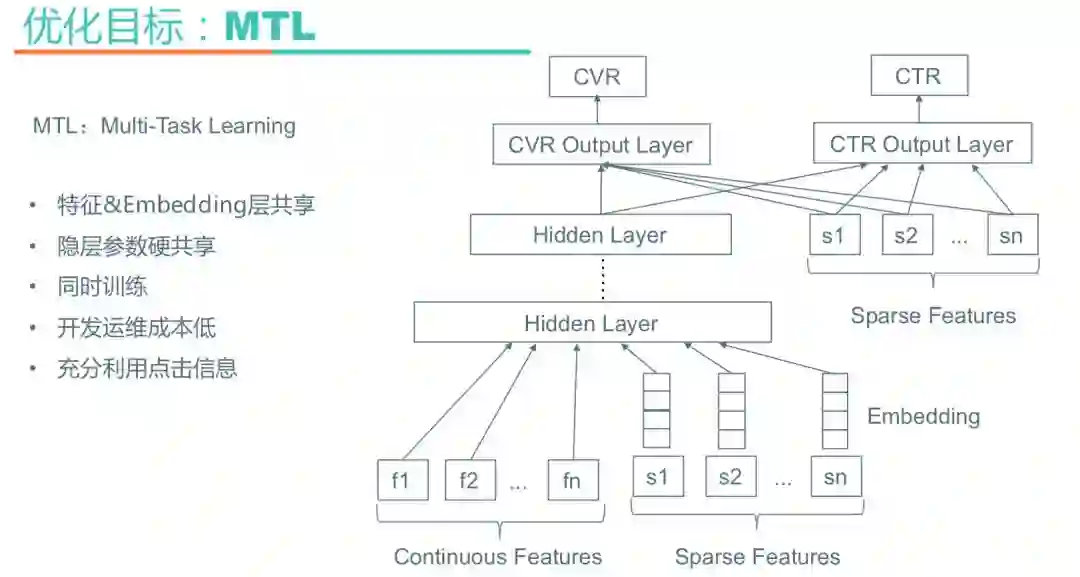
模型切换到神经网络后就可以做多任务学习了,之前树模型时代只预测“End to End”真实访购率,神经网络则可以通过多任务学习同时预测CTR展示点击率和CVR点击消费率。多任务学习通过硬共享的方式同时训练两个网络,特征、Embedding层、隐层参数都是共享的,只在输出层区分不同的任务。上图是酒店搜索当前线上的模型,基于Wide&Deep做的多任务学习。
网络结构演进路线
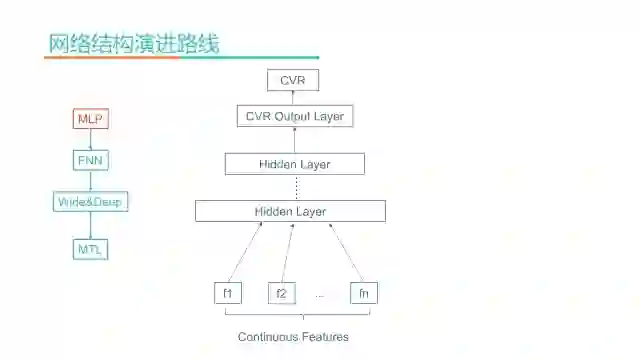
上图是酒店搜索排序的深度排序模型演进路线,从MLP开始,通过对离散特征做Embedding进化到FNN,中间尝试过DeepFM、PNN、DCN等模型,后来加入了Wide层进化到Wide&Deep,现在的版本是一个MTL版的Wide&Deep,每个模块都是累加上去的。
除了上面提到的模型,我们还探索过这个:
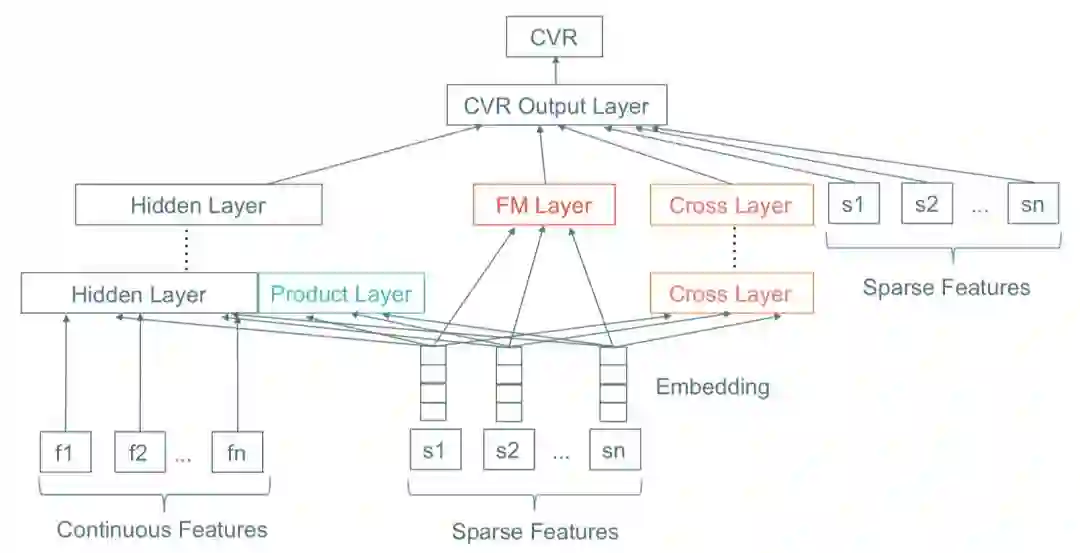
这是我们自己设计的混合网络,它融合了FNN、DeepFM、PNN、DCN、Wide&Deep等不同网络的优点,同时实现了一阶特征、显式二阶特征组合、显式高阶特征组合、隐式高阶特征组合等,有兴趣的同学可以尝试一下。
不同模型实验结果
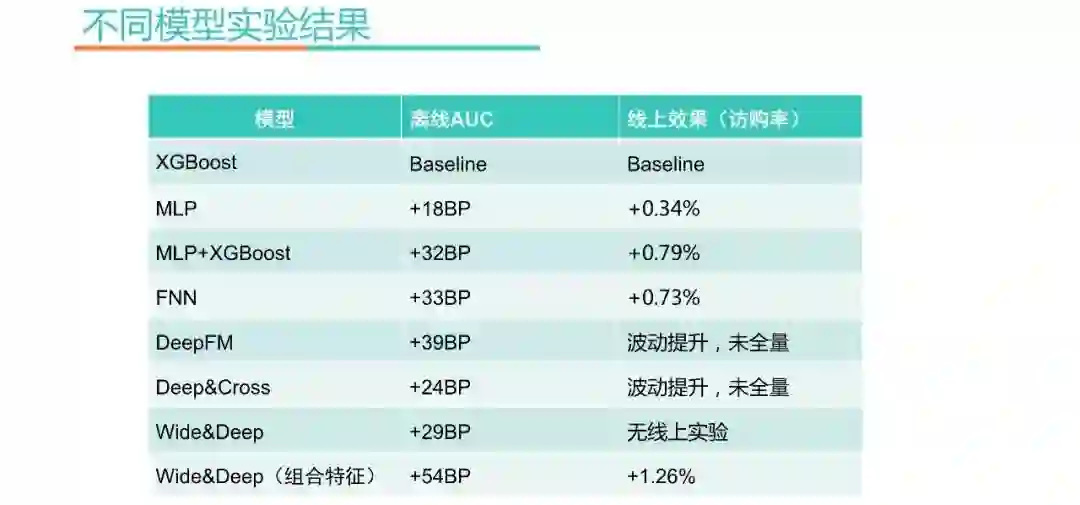
上图是不同模型的实验结果,这里的BP是基点(Basis Point),1BP=0.01%。XGB是Baseline,MLP经过很长时间的调试才超过XGB,MLP和XGB融合模型的效果也很好,不过为了方便维护,最终还是用FNN替换了融合模型。Wide&Deep在开始阶段,提升并没有特别多,后来加了组合特征后效果才好起来。我们Embedding上面的尝试,包括DeepFM、Deep&Cross等,线下都有提升,线上波动有提升,但是未能达到上线的标准,最终未能全量。

在特征预处理方面对连续特征尝试了累计分布归一化、标准化,以及手工变换如根号变换、对数变换等;累积分布归一化其实就是做特征分桶,因为连续特征多且分布范围很广,累积分布归一化对酒店搜索的场景比较有效。
离散特征方面尝试了特征Embedding及离散特征交叉组合,分别对应FNN和 Wide&Deep。这里特别提一下缺失值参数化,因为酒店业务是一种低频业务,特征覆盖率低,大量样本存在特征缺失的情况,如果对缺失特征学一个权重,非缺失值学一个权重效果较好。

参数调优方面分别尝试了激活函数、优化器等。激活函数尝试过Sigmoid、ReLU、Leaky_ReLU、ELU等;优化器也实验过Adagrad、Rmsprop、Adam等;从实验效果看,激活函数ReLU+Adam效果最好。刚开始时,加了Batch Normalization层和Dropout层,后来发现去掉后效果更好,可能和酒店搜索的数据量及数据特点有关。网络结构和隐层数方面用的是3到6层的金字塔网络。学习率方面的经验是学习率小点比较好,但是会导致训练变慢,需要找到一个平衡点。

下面介绍深度排序模型线上Serving架构的演化过程,初始阶段组内同学各自探索,用过各种开源工具如Keras、TensorFlow等,线上分别自己实现,预测代码和其他代码都放一起,维护困难且无法复用。
后来组内决定一起探索,大家统一使用TensorFlow,线上用TF-Serving,线上线下可以做到无缝衔接,预测代码和特征模块也解耦了。现在则全面转向MLX平台,MLX是美团自研的超大规模机器学习平台,专为搜索、推荐、广告等排序问题定制,支持百亿级特征和流式更新,有完善的线上Serving架构,极大地解放了算法同学的生产力。
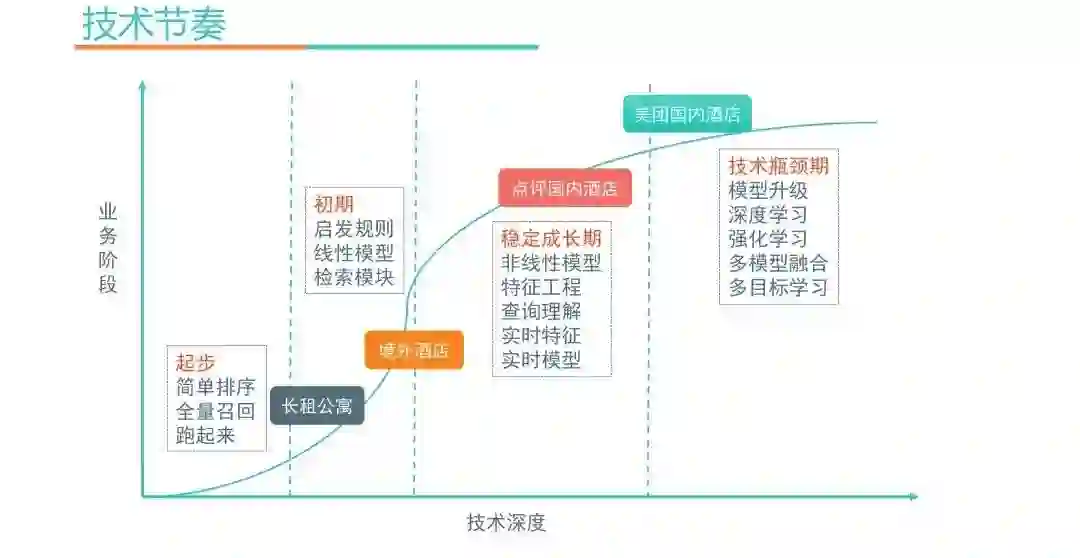
最后介绍一下我们对搜索排序技术节奏的一些理解,简单来说就是在不同阶段做不同的事情。
在上图中,横轴表示技术深度,越往右技术难度越大,人力投入越大,对人的要求也越高。纵轴是业务阶段。业务阶段对技术的影响包括两方面,数据量和业务价值。数据量的大小,可以决定该做什么事情,因为有些技术在数据量小的时候意义不大;业务价值就更不用说了,业务价值越大越值得“重兵投入”。
起步阶段:起步阶段,还没有数据,这时候做简单排序就好,比如纯按价格排序或者距离排序,目的是让整个流程快速地跑起来,能提供最基本的服务。比如2017年,美团的长租业务当时就处于起步阶段。
业务初期:随着业务的发展,就进入了业务发展初期,订单数慢慢增长,也有了一些数据,这时候可以增加一些启发式规则或者简单的线性模型,检索模型也可以加上。但是由于数据量还比较小,没必要部署很复杂的模型。
稳定成长期:业务进一步发展后,就进入了稳定成长期,这时候订单量已经很大了,数据量也非常大了,这段时间是“补课”的时候,可以把意图理解的模块加上,排序模型也会进化到非线性模型比如XGB,会做大量的特征工程,实时特征以及实时模型,在这个阶段特征工程收益巨大。
技术瓶颈期:这个阶段的特点是基本的东西都已经做完了,在原有的技术框架下效果提升变的困难。这时需要做升级,比如将传统语义模型升级成深度语义模型,开始尝试深度排序模型,并且开始探索强化学习、多模型融合、多目标学习等。
中国有句俗话叫“杀鸡焉用牛刀”,比喻办小事情,何必花费大力气,也就是不要小题大做。其实做技术也一样,不同业务阶段不同数据量适合用不同的技术方案,没有必要过度追求先进的技术和高大上的模型,根据业务特点和业务阶段选择最匹配的技术方案才是最好的。我们认为,没有最好的模型,只有合适的场景。
总结
酒店搜索作为O2O搜索的一种,和传统的搜索排序相比有很多不同之处,既要解决搜索的相关性问题,又要提供“千人千面”的排序结果,优化用户购买体验,还要满足业务需求。通过合理的模块划分可以把这三大类问题解耦,检索、排序、业务三个技术模块各司其职。在检索和意图理解层面,我们做了地标策略、NER模型和多级检索架构来保证查询结果的相关性;排序模型上结合酒店搜索的业务特点,借鉴业界先进思想,尝试了多种不同的深度排序模型,走出了一条不一样的模型演进路线。同时通过控制技术节奏,整体把握不同业务的技术选型和迭代节奏,对不同阶段的业务匹配不同的技术方案,只选对的,不选贵的。
参考文献
[1] John Lafferty et al. Conditional random fields: Probabilistic models for segmenting and labeling sequence data.ICML2001. [2] Guillaume Lample et al Neural architectures for named entity recognition. NAACL2016. [3] Zhiheng Huang, Wei Xu, and Kai Yu. 2015. [4] Bidirectional LSTM-CRF models for sequence tagging. arXiv preprint arXiv:1508.01991. [5] Xuezhe Ma et al.End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF.ACL2016. [6] T Chen, C Guestrin. XGBoost: A scalable tree boosting system. KDD2016. [7] Weinan Zhang et al. Deep Learning over Multi-Field Categorical Data: A Case Study on User Response Prediction. ECIR 2016. [8] Huifeng Guo et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. IJCAI2017. [9] Yanru Qu et al. Product-based neural networks for user response prediction. ICDM2016. [10] Heng-Tze Cheng et al. 2016. Wide & deep learning for recommender systems. 2016.In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. [11] Ruoxi Wang et al. Deep & Cross Network for Ad Click Predictions. ADKDD2017.

目前大会8 折报名中,立减 1760 元。点击 「阅读原文」或识别二维码了解 QCon 十周年的精心策划。有任何问题欢迎联系票务小姐姐 Ring:电话 010-53935761,微信 qcon-0410。




