Scikit-learn 更新至0.24版,这10个新特性你需要了解
选自towardsdatascience
Scikit-learn 更新了,新特 性主要包括选择超参数更快的方法、ICE 图、直方图 boosting 改进、OneHotEncoder 支持缺失值等。
自 2007 年发布以来,Scikit-learn 已经成为 Python 领域非常重要的机器学习库,支持分类、回归、降维和聚类四大机器学习算法,还包括了特征提取、数据处理和模型评估三大模块。
总的来说,Scikit-learn 有以下优点:
完善的文档,上手容易;
丰富的 API,在学术界颇受欢迎;
封装了大量的机器学习算法,包括 LIBSVM 和 LIBINEAR 等;
内置了大量数据集,节省了获取和整理数据集的时间。
和其他众多的开源项目一样,Scikit-learn 目前主要由社区成员自发进行维护。可能是由于维护成本的限制,Scikit-learn 相比其他项目要显得更为保守。但在刚刚到来的 2021 年,Scikit-learn 0.24.0 版本更新了,让我们看看新版本有哪些值得关注的新特性。
1. 选择超参数更快的方法
HalvingGridSearchCV 和 HalvingRandomSearchCV 将 GridSearchCV 和 RandomizedSearchCV 合并为超参数调优家族中资源密集度较低的成员。
新类使用锦标赛方法(tournament approach)选择最佳超参数。它们在观测数据的子集上训练超参数组合,得分最高的超参数组合会进入下一轮。在下一轮中,它们会在大量观测中获得分数。比赛一直持续到最后一轮。
确定传递给 HalvingGridSearchCV 或 halvingAndomSearchCV 的超参数需要进行一些计算,你也可以使用合理的默认值。
HalvingGridSearchCV 使用所有超参数组合。RandomGridSearchCV 使用随机子集,就如 RandomizedSearchCV 一样。
一些建议:
如果没有太多的超参数需要调优,并且 pipeline 运行时间不长,请使用 GridSearchCV;
对于较大的搜索空间和训练缓慢的模型,请使用 HalvingGridSearchCV;
对于非常大的搜索空间和训练缓慢的模型,请使用 HalvingRandomSearchCV。
在使用之前,这些类需要从 experimental 模块导入:
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingRandomSearchCV
from sklearn.model_selection import HalvingGridSearchCV
2. ICE 图
Scikit-learn 0.23 版本引入了部分依赖图(PDP),PDP 对显示平均特征非常重要。而 Scikit-learn 0.24 版本则提供了显示个体条件期望(ICE)图的选项。
与 PDP 一样,ICE 图显示了目标和输入特征之间的依赖关系。不同之处在于, ICE 图显示了对每个样本特征的预测依赖性——每个样本一行。特征的平均 ICE 为 PDP。
通过将关键字参数 kind='individual'传递给 plot_partial_dependency 函数可以查看 ICE 图。而 PDP 和 ICE 则可以通过关键字参数 kind='both'进行查看。
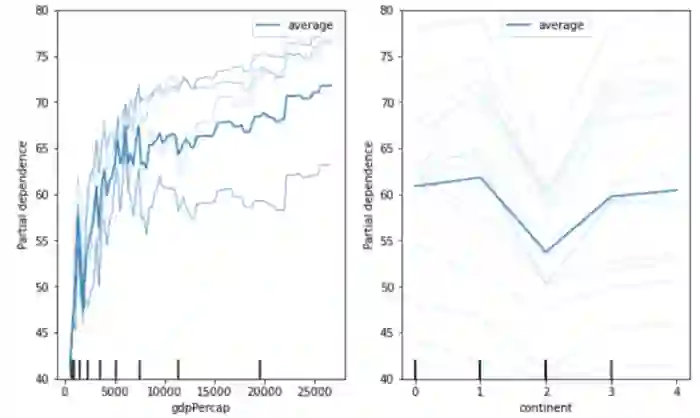
来自 scikit-learn gapminder 数据集的 PDP 和 ICE 图。
3. 直方图 boosting 改进
受 LightGBM 启发, HistGradientBoostingRegressor 和 HistGradientBoostingClassifier 现在有一个 categorical_features 参数,可用来提供分类特征支持。因为基于直方图的 booster 支持连续特征,这是一个不错的选择。与 one-hot 编码相比,它节省了训练时间,并且性能优于其他编码选项。
但是,模型的输入特征需要是数值型的。如果分类特征不是数值型的,可以使用 OrdinalEncoder 进行数字编码。然后通过传递一个布尔掩码或一个整数数组来告诉 booster 哪些特征是用来分类的。例如:
model = HistGradientBoostingRegressor(categorical_features=[True, False])
在 scikit-learn 0.24 版本中,直方图 boosting 算法在速度和内存使用方面得到了改进。在 2020 年末,HistGradientBoostingClassifier 的基准拟合速度(benchmark fit speed)下降了近 75%。
此外,请注意,基于直方图的估计器支持缺失值,因此,如果你不需要填充缺失值,则无需进行插补。这些估计器还处于试验阶段,因此启用估计器需要从 sklearn.experimental 导入。
4. 前向选择用于特征选择
选择特征子集时,SequentialFeatureSelector 从无特征开始,通过前向选择,逐渐添加特征,首先添加第一个最有价值的特征,然后添加第二个最有价值的特征,依此类推,直到到达选择的停止点。
不同于特征选择转换器 RFE 和 SelectFromModel,SequentialFeatureSelector 不需要底层模型来公开 coef_或 feature_importances_属性。但是,SequentialFeatureSelector 可能比 RFE 和 SelectFromModel 这两个选项慢,因为它使用交叉验证来评估模型。
5. 多项式特征展开的快速逼近
PolynomialFeatures 转换器创建交互项和特征的高阶多项式。然而,这会让模型训练变得非常缓慢。来自 kernel_approximation 命名空间的 PolynomialCountSketch 核近似函数提供了一种更快的方法来训练具有预测优势的线性模型,该模型可以使用 PolynomialFeatures 进行近似。
或者,你可以将 PolynomialCountSketch 视为具有径向基函数核的支持向量机的更快版本,只是在预测方面,性能差一点。
PolynomialFeatures 返回平方特征和交互项(如果需要,还可以返回高阶多项式)。相反,PolynomialCountSketch 返回在 n_components 参数中指定的特征数。默认值为 100,建议文档字符串(docstring)中包含的特征数量是原始特征数量的 10 倍。这些特征表示多项式特征展开近似,但不能直接解释。
6. 用于半监督学习的 SelfTrainingClassifier
SelfTrainingClassifier 是一个新的用于半监督学习的元分类器。它允许所有可以预测属于目标类的样本概率的监督分类器作为半监督分类器,从未标记的观测结果中学习。
请注意,y_train 中未标记值必须为 - 1,不能设置为 null。
7. 平均绝对百分比误差 (MAPE)
mean_absolute_percentage_error 函数现已被添加为回归问题评分指标。和 R-squared 一样,MAPE 在不同的回归问题中提供了一些比较值。
你可以使用 np.mean(np.abs((y_test — preds)/y_test)) 手动计算 MAPE,但总体来说,这个函数还是非常有用的。
8. OneHotEncoder 支持缺失值
scikit-learn 0.24 版本的 OneHotEncoder 可以处理缺失值。如果在 X_train 中有一个 null 值,那么在转换后的列中将有一个列来表示缺失值。
9. OrdinalEncoder 可以处理测试集中的新值
你是否有存在于测试集中、但在训练集中没有的类别?如果有这种情况的话,将 handle_unknown='use_encoded_value' 关键字参数和新的 unknown_value 参数一起使用。你可以将 unknown_value 参数设置为未出现在序数编码值中的整数或 np.nan。这使得 OrdinalEncoder 更易于使用。
10. 递归式特征消除(RFE)接受一定比例的特征保留
向 n_features_to_select 传递一个 0 到 1 之间的浮点数,以控制要选择特性的百分比。这种添加使得以编程方式消除部分特征变得更容易。
原文链接:https://towardsdatascience.com/the-10-best-new-features-in-scikit-learn-0-24-f45e49b6741b
2021年 2 月的第一周,机器之心将携手二十余位 AI 人耳熟能详的重磅嘉宾进行在线直播,通过圆桌探讨、趋势Talk,报告解读及案例分享等形式,为关注人工智能产业发展趋势的AI人解读技术演进趋势,共同探究产业发展脉络。连续七天,精彩不停。
添加机器之心Pro小助手(syncedai 或 syncedproii),备注「2021」,进群一起看直播。



