结构化数据存储,如何设计才能满足需求?

阿里妹导读:任何应用系统都离不开对数据的处理,数据也是驱动业务创新以及向智能化发展最核心的东西。数据处理的技术已经是核心竞争力。在一个完备的技术架构中,通常也会由应用系统以及数据系统构成。应用系统负责处理业务逻辑,而数据系统负责处理数据。本篇文章主要面向数据系统的研发工程师和架构师,希望对你有所启发。
前言
-
业务化: 完成最基本的业务交互逻辑。 -
规模化: 分布式和大数据技术的应用,满足业务规模增长的需求以及数据的积累。 -
智能化: 人工智能技术的应用,挖掘数据的价值,驱动业务的创新。

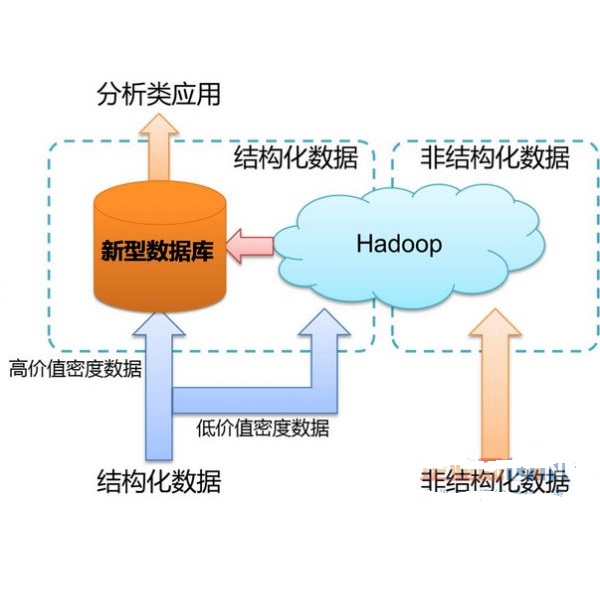
派生数据体系
-
主存储: 数据产生自业务或者是计算,通常为数据首先落地的存储。 ACID等事务特性可能是强需求,提供在线应用所需的低延迟业务数据查询。 -
辅存储: 数据主要来自主存储的数据同步与复制,辅存储是主存储的某个视图,通常面向数据查询、检索和分析做优化。

-
应用层多写: 这是实现最简单、依赖最少的一种实现方式,通常采取的方式是在应用代码中先向主存储写数据,后向辅存储写数据。 这种方式不是很严谨,通常用在对数据可靠性要求不是很高的场景。 因为存在的问题有很多,一是很难保证主与辅之间的数据一致性,无法处理数据写入失效问题; 二是数据写入的消耗堆积在应用层,加重应用层的代码复杂度和计算负担,不是一种解耦很好的架构; 三是扩展性较差,数据同步逻辑固化在代码中,比较难灵活添加辅存储。
异步队列复制:这是目前被应用比较广的架构,应用层将派生数据的写入通过队列来异步化和解耦。这种架构下可将主存储和辅存储的数据写入都异步化,也可仅将辅存储的数据写入异步化。第一种方式必须接受主存储可异步写入,否则只能采取第二种方式。而如果采用第二种方式的话,也会遇到和上一种『应用层多写』方案类似的问题,应用层也是多写,只不过是写主存储与队列,队列来解决多个辅存储的写入和扩展性问题。
-
CDC(Change Data Capture)技术: 这种架构下数据写入主存储后会由主存储再向辅存储进行同步,对应用层是最友好的,只需要与主存储打交道。 主存储到辅存储的数据同步,则可以再利用异步队列复制技术来做。 不过这种方案对主存储的能力有很高的要求,必须要求主存储能支持CDC技术。 一个典型的例子就是MySQL+Elasticsearch的组合架构,Elasticsearch的数据通过MySQL的binlog来同步,binlog就是MySQL的CDC技术。
-
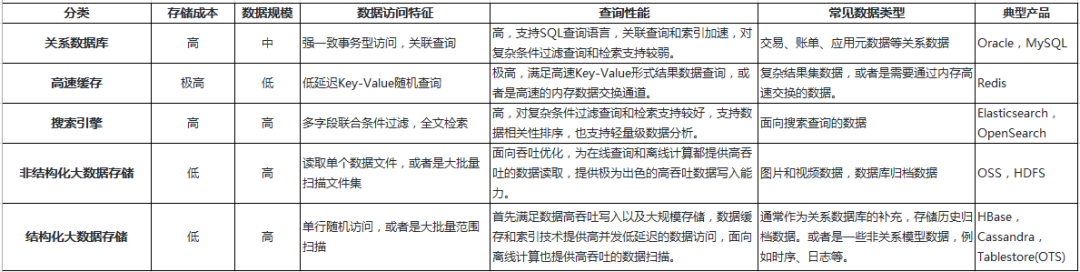
数据模型和查询语言仍然是不同数据库最显著的区别,关系模型和文档模型是相对抽象的模型,而类似时序模型、图模型和键值模型等其他非关系模型是相对具象的抽象,如果场景能匹配到具象模型,那选择范围能缩小点。 -
存储组件通常会划分到不同的数据分层,选择面向规模、成本、查询和分析性能等不同维度的优化偏向,选型时需要考虑清楚对这部分数据存储所要求的核心指标。 -
区分主存储还是辅存储,对数据复制关系要有明确的梳理。 (主存储和辅存储是什么在下一节介绍) -
建立灵活的数据交换通道,满足快速的数据搬迁和存储组件间的切换能力,构建快速迭代能力比应对未知需求的扩展性更重要。
-
数据一定需要分层 -
数据最终的归属地一定是OSS -
会由一个统一的分析引擎来统一分析的入口,并提供统一的查询语言
-
存储计算分离架构: 底层基于HDFS,分离的架构可带来存储和计算各自弹性扩展的优势,与计算引擎例如Spark可共享计算资源,降低成本。 -
LSM存储引擎: 为写入优化设计,能提供高吞吐的数据写入。 -
开发者生态成熟,接入主流计算引擎: 作为发展多年的开源产品,在国内也有比较多的应用,开发者社区很成熟,对接几大主流的计算引擎。
★ 设计理念
存储计算分离架构:采用存储计算分离架构,底层基于飞天盘古分布式文件系统,这是实现存储计算成本分离的基础。
LSM存储引擎:LSM和B+tree是主流的两个存储引擎实现,其中LSM专为高吞吐数据写入优化,也能更好的支持数据冷热分层。
Serverless产品形态:基于存储计算分离架构来实现成本分离的最关键因素是Serverless服务化,只有Serverless服务才能做到存储计算成本分离。大数据系统下,结构化大数据存储通常会需要定期的大规模数据导入,来自在线数据库或者是来自离线计算引擎,在此时需要有足够的计算能力能接纳高吞吐的写入,而平时可能仅需要比较小的计算能力,计算资源要足够的弹性。另外在派生数据体系下,主存储和辅存储通常是异构引擎,在读写能力上均有差异,有些场景下需要灵活调整主辅存储的配比,此时也需要存储和计算资源弹性可调。
多元化索引,提供丰富的查询能力:LSM引擎特性决定了查询能力的短板,需要索引来优化查询。而不同的查询场景需要不同类型的索引,所以Tablestore提供多元化的索引来满足不同类型场景下的数据查询需求。
CDC技术:Tablestore的CDC技术名为Tunnel Service,支持全量和增量的实时数据订阅,并且能无缝对接Flink流计算引擎来实现表内数据的实时流计算。
拥抱开源计算生态:除了比较好的支持阿里云自研计算引擎如MaxCompute和Data Lake Analytics的计算对接,也能支持Flink和Spark这两个主流计算引擎的计算需求,无需数据搬迁。
流批计算一体:能支持Spark对表内全量数据进行批计算,也能通过CDC技术对接Flink来对表内新增数据进行流计算,真正实现批流计算结合。
多元化索引

Tablestore提供多种索引类型可选择,包含全局二级索引和多元索引。 全局二级索引类似于传统关系数据库的二级索引,能为满足最左匹配原则的条件查询做优化,提供低成本存储和高效的随机查询和范围扫描。 多元索引能提供更丰富的查询功能,包含任意列的组合条件查询、全文搜索和空间查询,也能支持轻量级数据分析,提供基本的统计聚合函数,两种索引的对比和选型可参考这篇文章。
通道服务


-
Lambda plus架构中数据只需要写入Tablestore,Blink流计算框架通过通道服务API直读表内的实时更新数据,不需要用户双写队列或者自己实现数据同步。 -
存储上,Lambda plus直接使用Tablestore作为master dataset,Tablestore支持用户在线系统低延迟读写更新,同时也提供了索引功能进行高效数据查询和检索,数据利用率高。 -
计算上,Lambda plus利用Blink流批一体计算引擎,统一流批代码。 -
展示层,Tablestore提供了多元化索引,用户可自由组合多类索引来满足不同场景下查询的需求。

你可能还喜欢
点击下方图片即可阅读




关注「阿里技术」
把握前沿技术脉搏