机器之心&ArXiv Weekly Radiostation
参与:杜伟,楚航,罗若天
本周的重要论文有何恺明组提出的超越 EfficientNet 的新型网络设计范式,以及阿里达摩院推出的高性能GPU专用模型TResNet。
Designing Network Design Spaces
A Survey of Deep Learning for Scientific Discovery
TResNet: High Performance GPU-Dedicated Architecture
Controllable Person Image Synthesis with Attribute-Decomposed GAN
Validation Set Evaluation can be Wrong: An Evaluator-Generator Approach for Maximizing Online Performance of Ranking in E-commerce
Put It Back: Entity Typing with Language Model Enhancement
Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)
论文 1:Designing Network Design Spaces
摘要:尽管神经架构搜索(Neural Architecture Search,NAS)的有效性已经得到了证明,但其范式依然存在限制。搜索结果往往是仅仅符合特定设置(如硬件平台)的单个网络实例。这在某些情况下足以,但却不能帮助我们发掘出那些能够加深理解且泛化到新设置的网络设计准则。总之,我们需要创建一些易于理解、继承和泛化的简单模型。
在本文中,
包括何恺明在内的几位 FAIR 研究者提出了一种新型网络设计范式,它能够充分结合手工设计和神经架构搜索的优
势。他们不再将注意力放在单个网络实例的设计上,而是设计出了参数化网络群的设计空间。既像手工设计一样,研究者追求可解释性,并且旨在发现通用设计准则以描述那些结构简单、运行良好且不同设置下均能适用的网络。又像神经架构搜索一样,研究者充分利用半自动化流程来帮助实现这些目标。
![]()
![]()
移动机制下 RegNet 模型与现有网络的性能对比。
![]()
推荐:
何恺明大神组的又一力作,论文已被 CVPR 2020 接收。
论文 2:A Survey of Deep Learning for Scientific Discovery
摘要:
在本篇综述论文中,两位研究者概述了许多广泛使用的深度学习模型,涵盖了视觉、顺序和图形结构化数据,关联任务和各种培训方法,以及使用较少数据和 更好地解释这些复杂的模型。此外,他们还提供了整个设计过程的概述、实现技巧、教程链接、研究总结以及开源的深度学习 pipeline 和预训练模型。最后,
研究者希望这篇综述文章将有助于加速跨不同科学领域深度学习的使用
。
![]()
推荐:
Yann LeCun 转推并高度评价了这篇科学领域应用深度学习的综述论文。
论文 3:TResNet: High Performance GPU-Dedicated Architecture
摘要:
在本文中,来自
阿里达摩院
的研究者提出一系列架构修正,旨在提升神经网络的准确性,同时保留 GPU 训练和推理效率。他们首先验证并讨论了由 Flops 优化带来的瓶颈,然后提出更高效利用 GPU 结构和 asset 的替代设计,最后
推出了一个称为 TResNet 的 GPU 专用模型
。
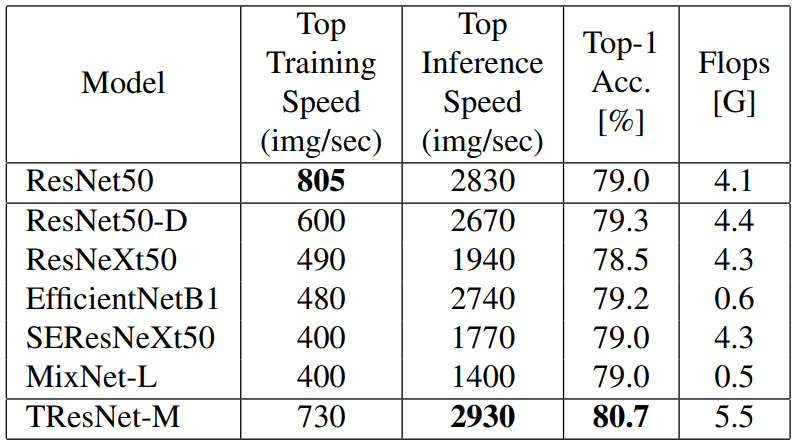
与之前的 ConvNets 模型相比,TResNet 模型具有表现出更高的准确度和效率。使用 TResNet 模型以及与 ResNet50 相似的 GPU 吞吐量,研究者在 ImageNet 上实现了 80.7% 的 top-1 准确度。此外,TResNet 模型的迁移效果也很好,在 Stanford cars (96.0%)、CIFAR-10 (99.0%)、CIFAR-100 (91.5%) 以及 Oxford-Flowers (99.1%) 等数据集上实现了当前 SOTA 准确度。
![]()
与 ResNet50、EfficientNet 以及 MixNet 等网络相比,本文提出的 TResNet-M 在 Top 推理速度和 Top-1 准确度上均实现了当前 SOTA。注意,所有的度量都是在具有混合精度的英伟达 V100 GPU 上完成。
![]()
![]()
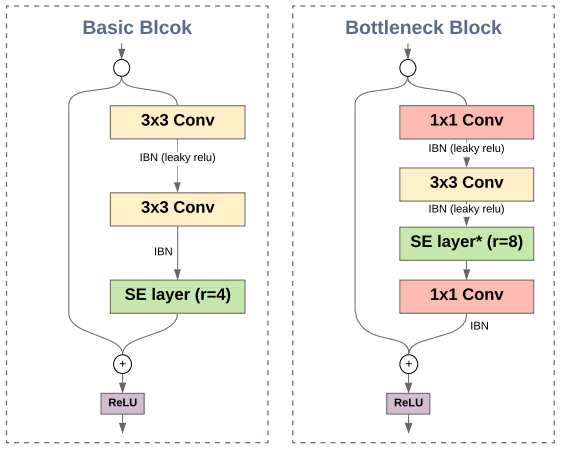
TResNet 的基本块(BasicBlock)和瓶颈设计示意图。
推荐:
本文的亮点在于,研究者提出的 TResNet 在 Top-1 准确度上超越了 ResNet50。
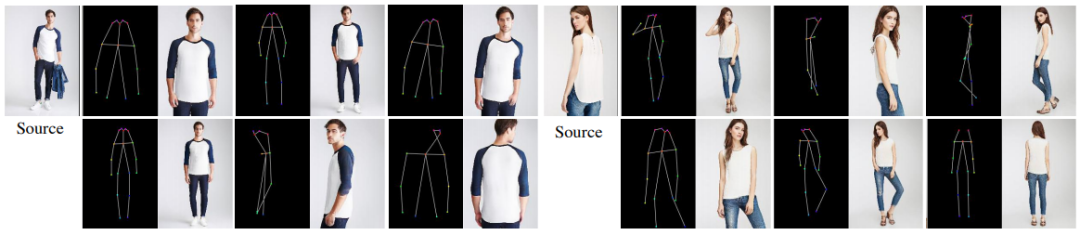
论文 4:Controllable Person Image Synthesis with Attribute-Decomposed GAN
摘要:
在本文中,来自
北大和字节跳动 AI 实验室
的研究者介绍了
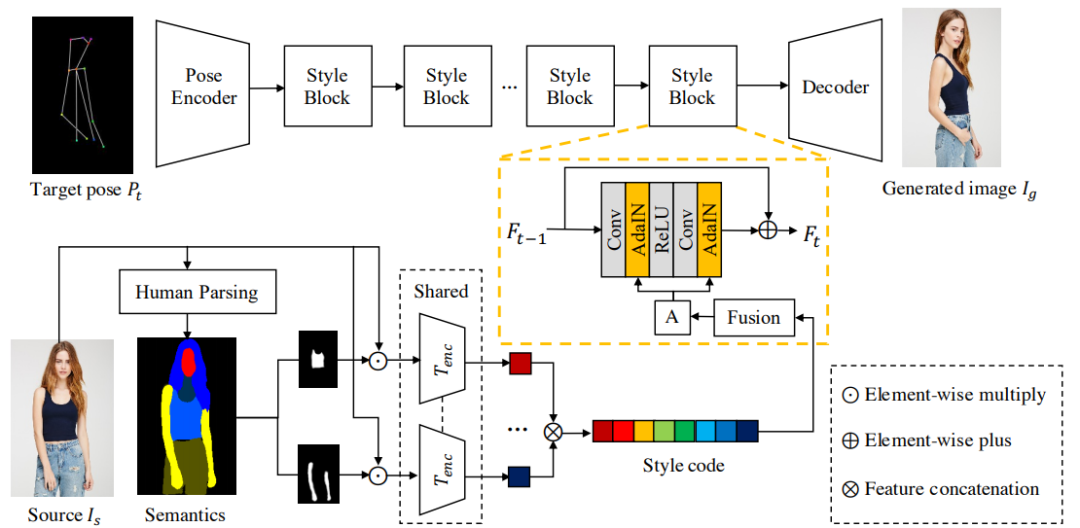
属性分解 GAN(Attribute-Decomposed GAN),这是一种用于可控人物图像合成的新型生成模型
。该模型可以在各种源输入中生成涵盖预期人物属性(例如姿态、面部、上衣和裤子)的真实人物图像,其核心思想是将人物属性作为独立代码嵌入到隐空间中,并通过在显式风格表征中执行混合和插值操作,进而实现对属性的灵活、连续控制。
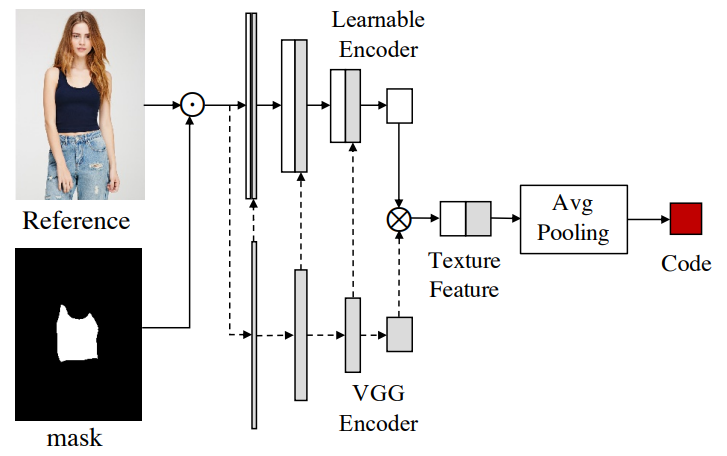
具体而言,研究者提出了一种新的体系结构,该体系结构由具有风格块连接的两个编码路径组成,以将原始映射分解为多个更容易访问的子任务。在源代码路径中,他们进一步使用现有的人类解析器提取组件布局,并将其馈入到共享的全局纹理编码器中,以分解潜在代码。这种策略可以合成更逼真的输出图像,并自动分离未标注的属性。
![]()
![]()
![]()
推荐:
实验结果显示,这种属性分解 GAN 在姿态迁移方面优于现有 SOTA 技术,并在组件属性迁移全新任务中表现出有效性。
论文 5:Validation Set Evaluation can be Wrong: An Evaluator-Generator Approach for Maximizing Online Performance of Ranking in E-commerce
摘要:
用验证集来测试算法性能、挑选模型是一种常见操作,在电商领域也是如此。但阿里巴巴与南京大学的一篇论文指出,对于在线推荐排序这种具有决策因素的环境,验证集评估得到的性能与真实的在线性能会出现很大的出入,验证集效果好的方法真实性能可能更差。「这意味着,这一方向的研究可能已经被验证集评估带歪了。」针对这一问题,他们提出了一种新的评估器-生成器方法,可显著提升商品排序的有效性。
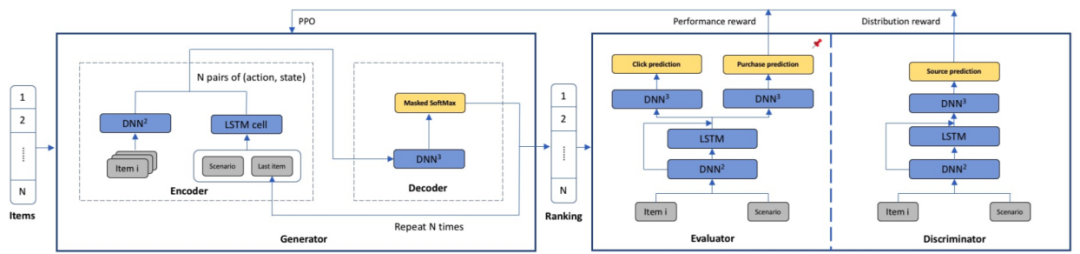
本论文为电子商务的逐分组 LTR 提出了一种评估器-生成器框架 EG-Rerank
。EG-Rerank 可使用商品及其上下文信息来预测已排序商品列表的购买概率。此外,研究者还引入了一个判别器并将其用作自信评分函数(self-confidence scoring function)。这个判别器可通过对抗训练方法来学习,可给出评估器为一个商品列表给出的分数的置信度。研究者使用这一判别器来引导生成器从判别器的视角在置信空间中输出顺序。然后,EG-Rerank 通过一种强化学习方法来训练 LTR 模型,其可在评估器的引导下探索商品的顺序。
![]()
EG-Rerank 框架。首先训练评估器并将其固定下来,然后通过 PPO 训练生成器,其奖励由评估器提供。对于 EG-Rerank+,生成器和判别器是同时训练的。
![]()
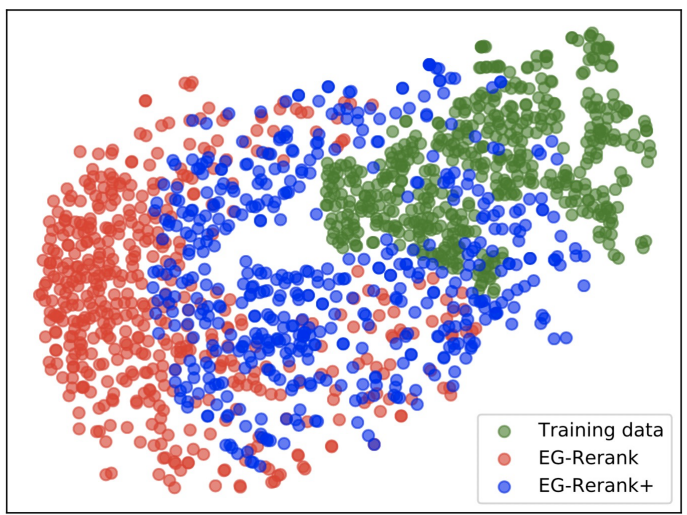
真实数据中的列表分布。为了减少在线环境中的噪声以及更好的演示,研究者移除了离各组质心最远的 20% 的记录。
![]()
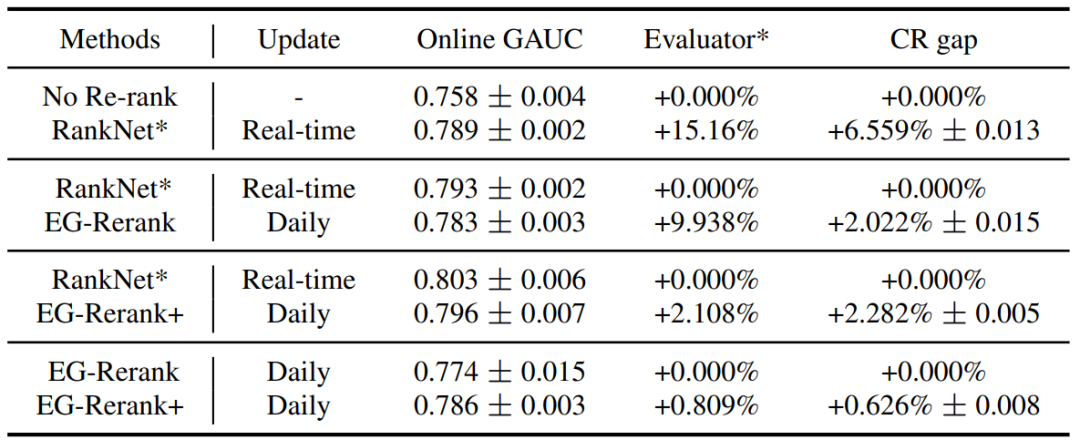
(图注)在线性能。在 CR gap 列,第一行因为是基准,所以差距始终为 0。
推荐:本文是南京大学人工智能学院俞扬教授指导完成的最新论文。相比于经过微调的产业级再排名逐对评分模型,本文提出的 EG-Rerank+ 可将转化率稳定地提升 2%——对于成熟的大型平台而言,这是非常重大的提升。
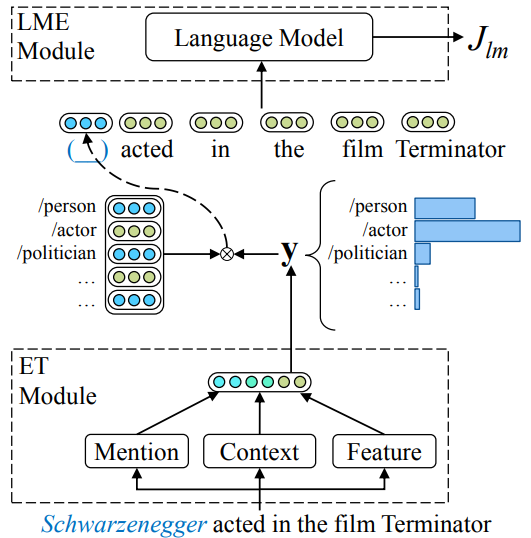
论文 6:Put It Back: Entity Typing with Language Model Enhancement
摘要:
实体分型旨在对特定语境中提及的实体的语义类型进行分类。现有的大多数模型都使用远程监督来获取训练数据,并且不可避免地会遇到噪声标签(noise label)的问题。
为了解决这一问题,来自
清华大学和加拿大滑铁卢大
学的研究者提出
使用语言模型增强来进行实体分型
。具体而言,它利用语言模型来度量上下文中句子和标签之间的兼容性,从而自动将更多注意力集中在与上下文相关的标签上。在基准数据集上进行的实验表明,他们提出的方法能够使用语言模型中的信息来增强实体分型模型,并且大大优于当前 SOTA 基线方法。
![]()
本文使用的模型结构图:实体分型(ET)模块和语言模型增强(LME)模块。
![]()
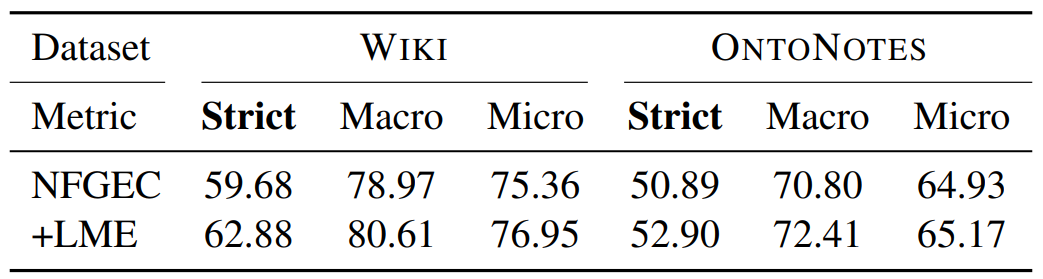
本文实体分型在 strict accuracy、macro-F1 和 micro-F1 三种度量上的性能表现。
推荐:
值得关注的是,文中的语言模型增强(LME)也得很好地适应其他实体分型系统。
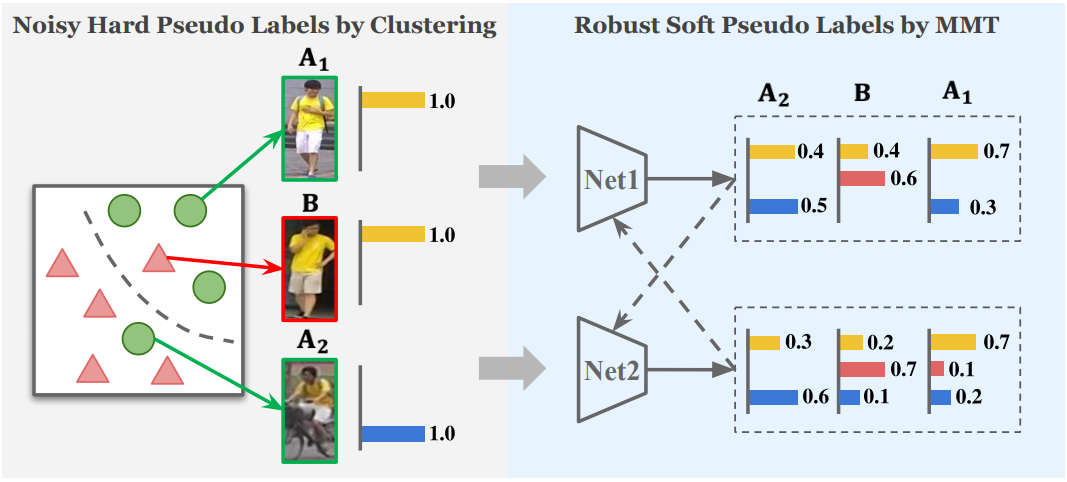
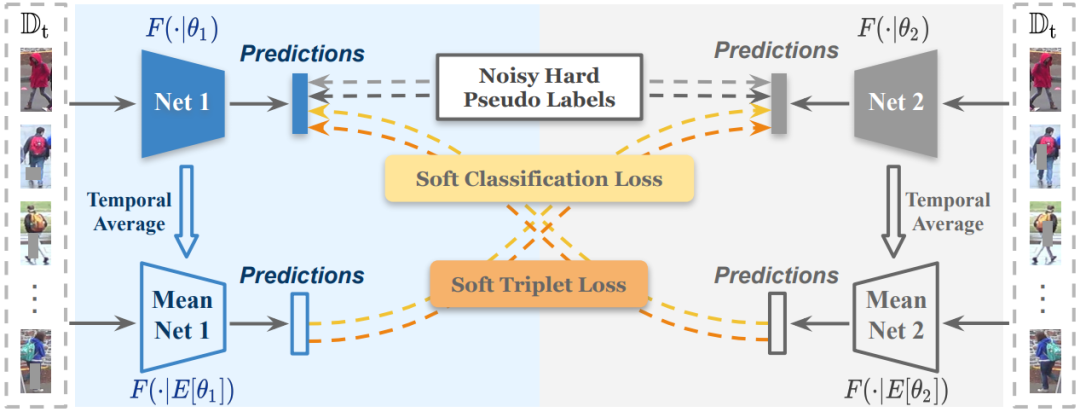
论文 7:Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification
摘要:
本文是
香港中文大学
发表于 ICLR 2020 上的一篇论文,旨在解决更实际的开放集无监督领域自适应问题,所谓开放集指预先无法获知目标域所含的类别。
这项工作在多个行人重识别任务上验证其有效性,精度显著地超过最先进技术 13%-18%,大幅度逼近有监督学习性能
。
为了有效地解决基于聚类的算法中的伪标签噪声的问题,该文提出利用"同步平均教学"框架进行伪标签优化,核心思想是利用更为鲁棒的"软"标签对伪标签进行在线优化。在这里,"硬"标签指代置信度为 100% 的标签,如常用的 one-hot 标签 [0,1,0,0],而"软"标签指代置信度<100% 的标签,如 [0.1,0.6,0.2,0.1]。总的来说,该文提出"相互平均教学"(Mutual Mean-Teaching)框架为无监督领域自适应的任务提供更为可信的、鲁棒的伪标签;针对三元组(Triplet)设计合理的伪标签以及匹配的损失函数,以支持协同训练的框架。
![]()
![]()
![]()
推荐:
本文的亮点在于,这是 ICLR 收录的第一篇行人重识别任务相关的论文,代码和模型均也已公开。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Comprehensive Named Entity Recognition on CORD-19 with Distant or Weak Supervision. (from Xuan Wang, Xiangchen Song, Yingjun Guan, Bangzheng Li, Jiawei Han)
2. Give your Text Representation Models some Love: the Case for Basque. (from Rodrigo Agerri, Iñaki San Vicente, Jon Ander Campos, Ander Barrena, Xabier Saralegi, Aitor Soroa, Eneko Agirre)
3. Igbo-English Machine Translation: An Evaluation Benchmark. (from Ignatius Ezeani, Paul Rayson, Ikechukwu Onyenwe, Chinedu Uchechukwu, Mark Hepple)
4. Procedural Reading Comprehension with Attribute-Aware Context Flow. (from Aida Amini, Antoine Bosselut, Bhavana Dalvi Mishra, Yejin Choi, Hannaneh Hajishirzi)
5. Semantic-based End-to-End Learning for Typhoon Intensity Prediction. (from Hamada M. Zahera, Mohamed Ahmed Sherif, Axel Ngonga)
6. Multilingual Stance Detection: The Catalonia Independence Corpus. (from Elena Zotova, Rodrigo Agerri, Manuel Nuñez, German Rigau)
7. NUBES: A Corpus of Negation and Uncertainty in Spanish Clinical Texts. (from Salvador Lima, Naiara Perez, Montse Cuadros, German Rigau)
8. Information-Theoretic Probing with Minimum Description Length. (from Elena Voita, Ivan Titov)
9. Low Resource Neural Machine Translation: A Benchmark for Five African Languages. (from Surafel M. Lakew, Matteo Negri, Marco Turchi)
10. A Clustering Framework for Lexical Normalization of Roman Urdu. (from Abdul Rafae Khan, Asim Karim, Hassan Sajjad, Faisal Kamiran, Jia Xu)
1. HERS: Homomorphically Encrypted Representation Search. (from Joshua J. Engelsma, Anil K. Jain, Vishnu Naresh Boddeti)
2. Alleviating Semantic-level Shift: A Semi-supervised Domain Adaptation Method for Semantic Segmentation. (from Zhonghao Wang, Yunchao Wei, Rogerior Feris, Jinjun Xiong, Wen-Mei Hwu, Thomas S. Huang, Honghui Shi)
3. MUXConv: Information Multiplexing in Convolutional Neural Networks. (from Zhichao Lu, Kalyanmoy Deb, Vishnu Naresh Boddeti)
4. Learning Human-Object Interaction Detection using Interaction Points. (from Tiancai Wang, Tong Yang, Martin Danelljan, Fahad Shahbaz Khan, Xiangyu Zhang, Jian Sun)
5. Dynamic Region-Aware Convolution. (from Jin Chen, Xijun Wang, Zichao Guo, Xiangyu Zhang, Jian Sun)
6. Memory-Efficient Incremental Learning Through Feature Adaptation. (from Ahmet Iscen, Jeffrey Zhang, Svetlana Lazebnik, Cordelia Schmid)
7. Revisiting Few-shot Activity Detection with Class Similarity Control. (from Huijuan Xu, Ximeng Sun, Eric Tzeng, Abir Das, Kate Saenko, Trevor Darrell)
8. Weakly Supervised Dataset Collection for Robust Person Detection. (from Munetaka Minoguchi, Ken Okayama, Yutaka Satoh, Hirokatsu Kataoka)
9. Synchronizing Probability Measures on Rotations via Optimal Transport. (from Tolga Birdal, Michael Arbel, Umut Şimşekli, Leonidas Guibas)
10. DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes. (from Mahyar Najibi, Guangda Lai, Abhijit Kundu, Zhichao Lu, Vivek Rathod, Tom Funkhouser, Caroline Pantofaru, David Ross, Larry S. Davis, Alireza Fathi)
1. A theory of independent mechanisms for extrapolation in generative models. (from Michel Besserve, Rémy Sun, Dominik Janzing, Bernhard Schölkopf)
2. DeepGS: Deep Representation Learning of Graphs and Sequences for Drug-Target Binding Affinity Prediction. (from Xuan Lin, Kaiqi Zhao, Tong Xiao, Zhe Quan, Zhi-Jie Wang, Philip S. Yu)
3. GraphChallenge.org Sparse Deep Neural Network Performance. (from Jeremy Kepner, Simon Alford, Vijay Gadepally, Michael Jones, Lauren Milechin, Albert Reuther, Ryan Robinett, Sid Samsi)
4. Piecewise linear activations substantially shape the loss surfaces of neural networks. (from Fengxiang He, Bohan Wang, Dacheng Tao)
5. Extreme Multi-label Classification from Aggregated Labels. (from Yanyao Shen, Hsiang-fu Yu, Sujay Sanghavi, Inderjit Dhillon)
6. MiLeNAS: Efficient Neural Architecture Search via Mixed-Level Reformulation. (from Chaoyang He, Haishan Ye, Li Shen, Tong Zhang)
7. On the Optimization Dynamics of Wide Hypernetworks. (from Etai Littwin, Tomer Galanti, Lior Wolf)
8. Improving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program). (from Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d'Alché-Buc, Emily Fox, Hugo Larochelle)
9. LIMP: Learning Latent Shape Representations with Metric Preservation Priors. (from Luca Cosmo, Antonio Norelli, Oshri Halimi, Ron Kimmel, Emanuele Rodolà)
10. MTL-NAS: Task-Agnostic Neural Architecture Search towards General-Purpose Multi-Task Learning. (from Yuan Gao, Haoping Bai, Zequn Jie, Jiayi Ma, Kui Jia, Wei Liu)
![]()