被知乎反杀,是一种什么体验?
来自:可能是海淀区最大的喷壶「小声比比」(ZiquanM)
大家好
话说今天风和日丽
太阳红彤彤、花儿五颜六色
这时一位貌似知乎那边的人
突然要加我好友
至于事情的经过
还得从两天前说起...

熟悉我的读者可能知道
知乎刚公测那会儿我就开始玩了
最早一条回答还是2012年写的

那会儿我就觉得知乎沙雕答主干货极多
7年过去知乎的注册用户已达2亿
沉淀的优质内容自然数量惊人
而作为一个兴趣广泛的沙雕博主
知乎自然是我常逛的去处

然而在知乎的新信息流的加持下
由兴趣推荐来控制时间线
你喜欢什么它就给你推荐什么
导致它现在吞噬时间的能力极强
经常一开一关,一下午就没了
弄到九点才开始写稿,最后只好鸽鸽

因此为了避免在写稿时
被那些无关的诱人答案所吸引

我决定捣鼓一个知乎爬虫
帮我过滤那些受欢迎但无关的回答
以控制写稿期间刷知乎的时长

先设计一下爬虫的架构
em...大概长这个样子
说到爬虫,就不能不用python
毕竟它才是世界上最好的语言
这次爬取,用的是request库
爬取一个回答,很简单
就这一段代码
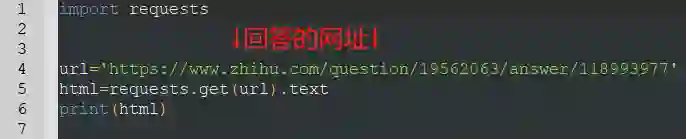
它代表什么意思是:
我要爬的网址是知乎的某个回答
并将爬到的信息打印出来
现在让我们来看看效果
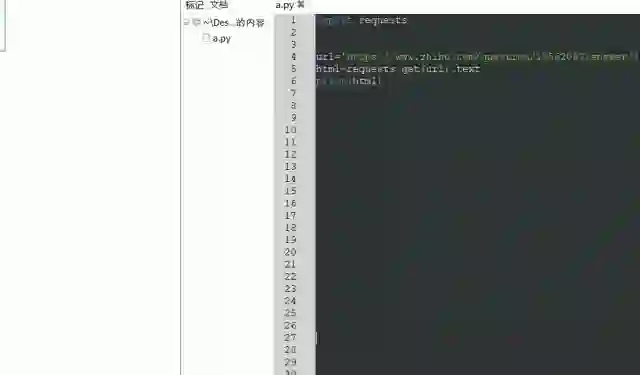
额...反应有是有,不过有点短
尤其是中间那个400
我们都知道404是
页面被和谐的意思
那么400呢?

其实它也很简单
就是一个大写加粗的——

打个比方大家就懂了
一个网站,好比一个博物馆
而大家平常用浏览器访问
就好比穿着正常的衣服去参观

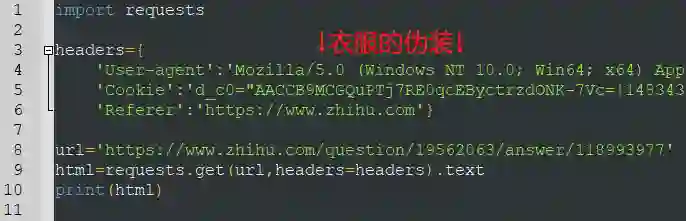
但爬虫的衣服,则长这个样子

明摆了告诉别人我是来捣乱的
所以,知乎才会给我们这一反馈

不过解决起来也简单
换身衣服就行,三行代码的事
现在再来试试知乎
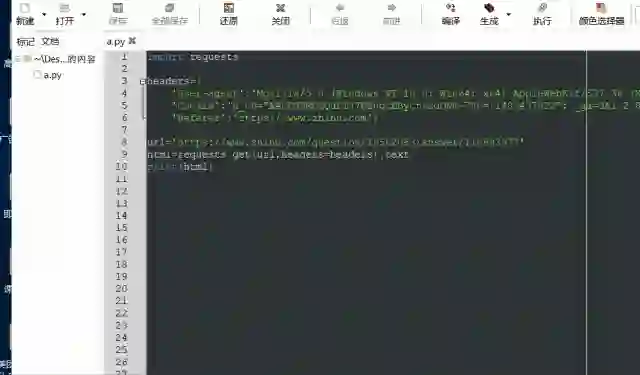
成功返回网站代码!
看来知乎也不是很难爬嘛

不过,开心没多久打脸的就来了
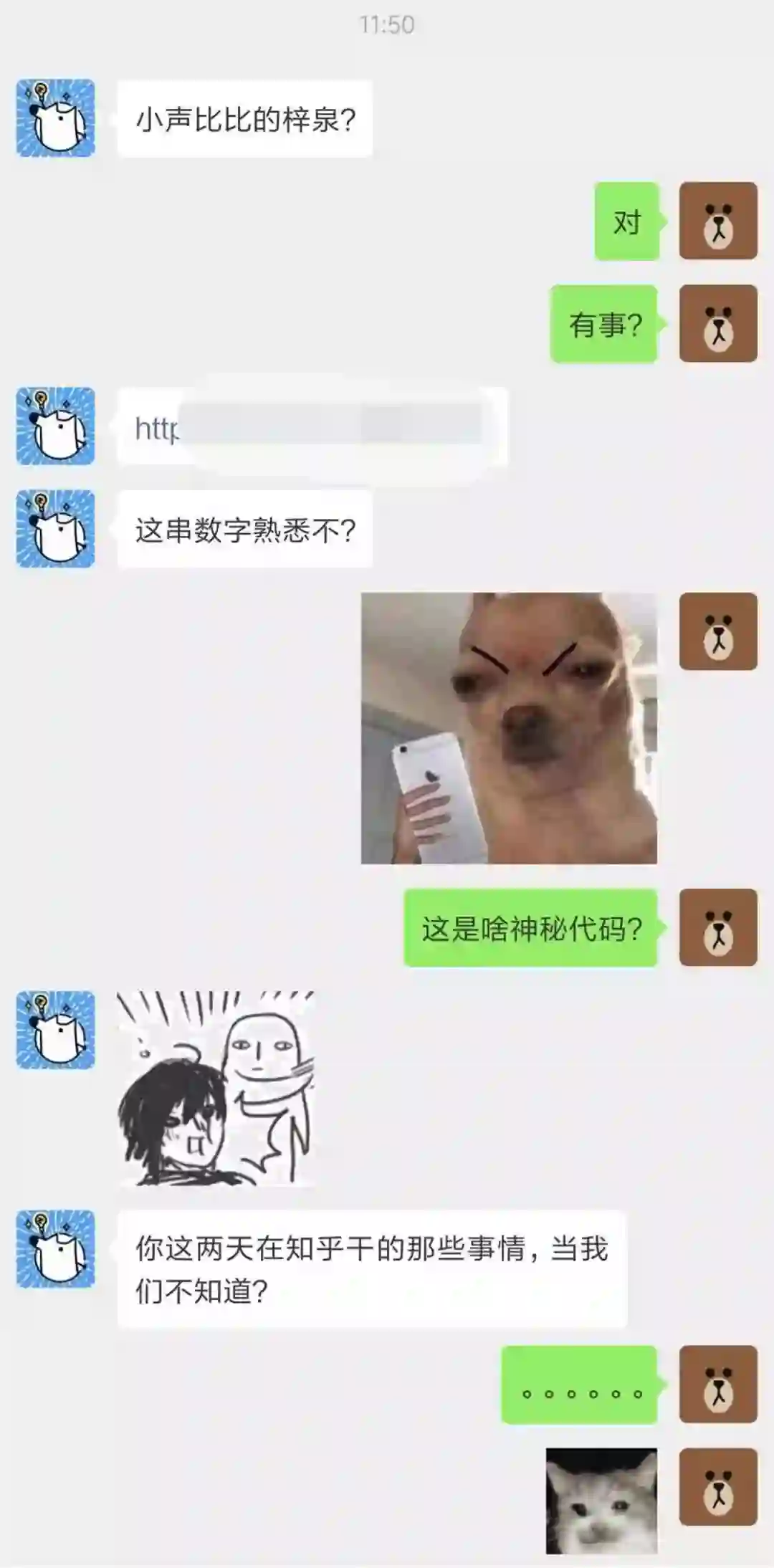
因为我在代码里找到的最后回答
仅仅只到网页显示的一丁点
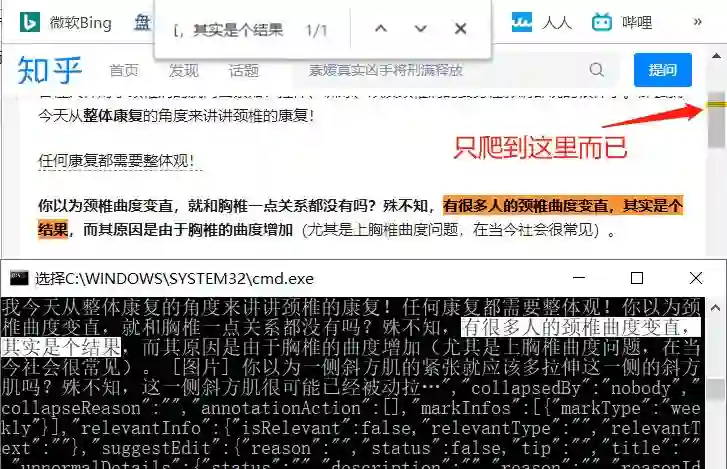
也就是说,我压根没爬全!

打开审查元素一看
罪魁祸首应该是这个batch
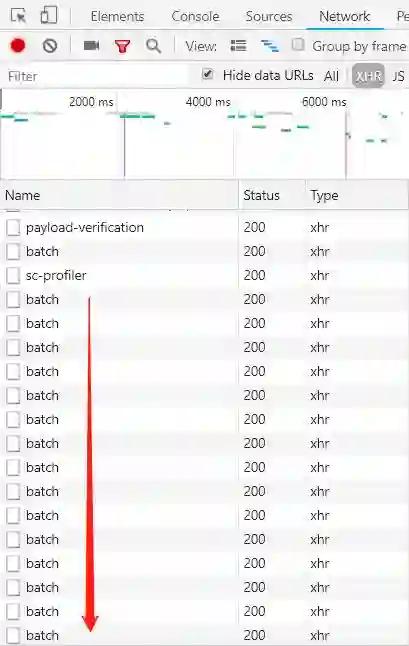
这应该是某种加密或隐藏的指令
其实我也不太懂
但对比豆瓣读书清晰易懂的结构
你知道知乎很坑就对了
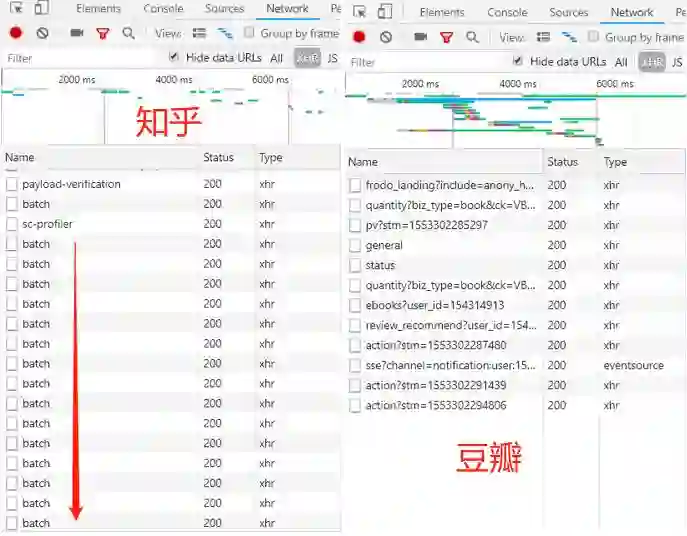
但此举也不是不能理解
知乎是一座知识博物馆的话
那答案就是里面的馆藏文物
所以怎么可能让你轻易搬走

不过,这岂能难倒我?
调用浏览器去爬取不就行了嘛!
这样既解决了衣服又解决了加密
只是浏览器的代码比较复杂
前面大段我也不懂,我搬网上的
反正只要把网址输入就能运行
之前爬优酷评论,用的就是它

不用费时去揣摩网页结构
直接暴力加载出数据
无脑爬取好帮手

不过这次还新增了一段代码

它的意思是把页面拉到最底
这样就不会出现数据遗漏的问题了
下面展示下爬知乎的效果
是不是很杰宝酷炫?
接下来我们再去看看数据
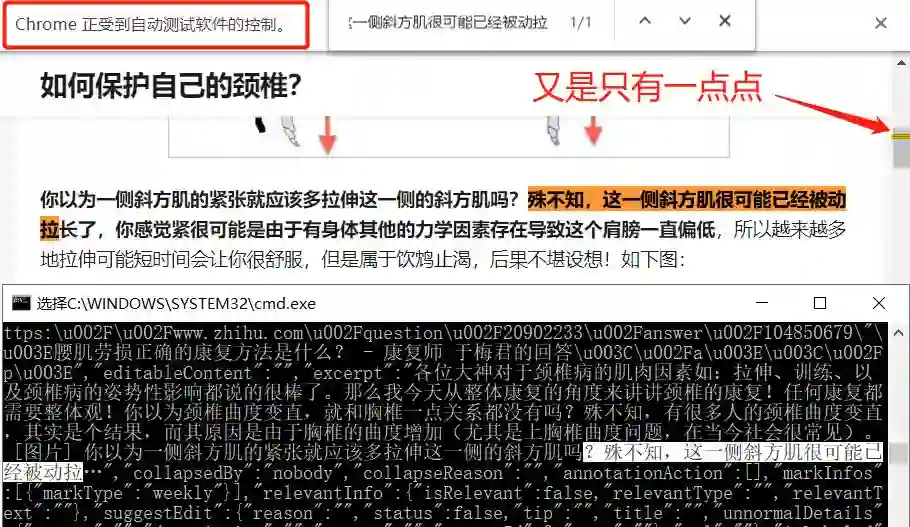
尼玛!为毛还那么少?
this is no science!
而且知乎还在代码里留下了嘲讽
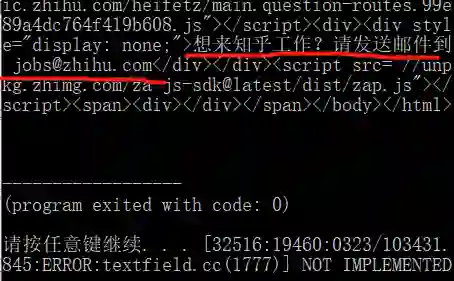

看来知乎的反爬措施并不简单
因为知乎虽说是个博物馆
但它不会一次性展示出全部精品
你想想,你一点进去一个问题
1200个回答同时完整加载
那电脑不得卡死?体验一定极差

因此知乎做了一个设置
只有当你走到特定位置
才会把文物从仓库里传送出来

换句话说,要想爬知乎
就必须找到这个仓库
找它也不难,浏览器直接按F12
下拉浏览器等待数据加载就能找到
复制后在浏览器打开是这个样子

可能有朋友会好奇:
既然你都知道可以这样弄
为啥一开始要绕那么大圈子?

唉,说到底主要还是
这个仓库地址复杂得让人脱发
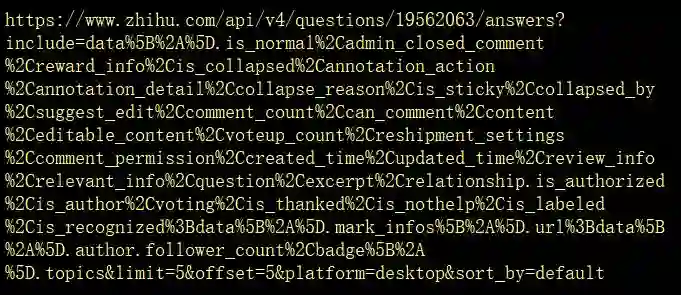

经过一番删删减减后
这地址精简成了这样...
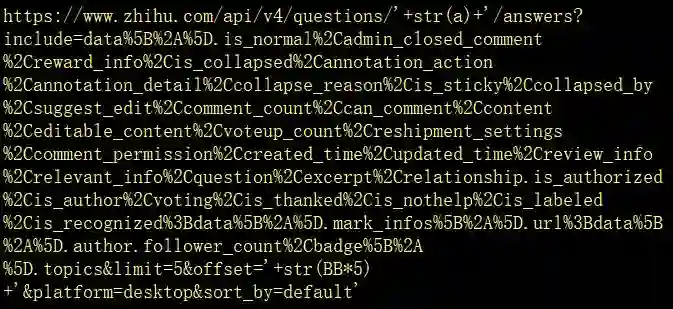

把它扔进request运行看看
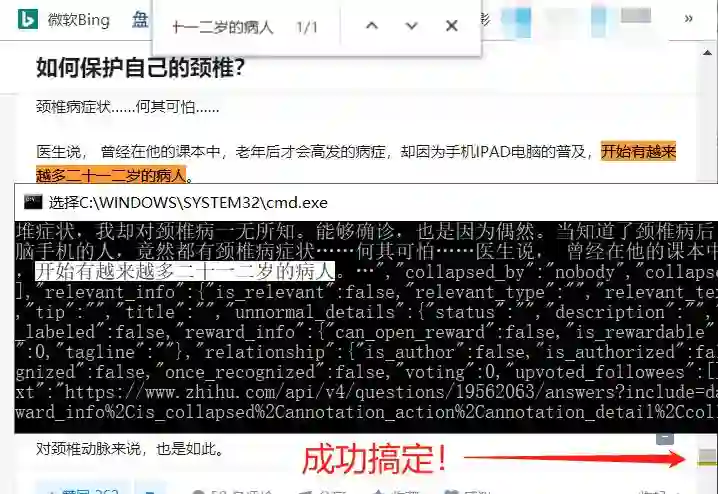
鹅妹子嘤!
现在,最难的问题已解决
剩下的工作就简单多了
▼
你只需要解析需要信息的位置
然后再嵌套一个爬问题的循环
并且还需搞个写入文件的函数
此外,为了效果能够酷炫一点
最好是在加入交互的体验过程
对了!点赞的筛选也不能忘记
还有就是要考虑一下模糊搜索
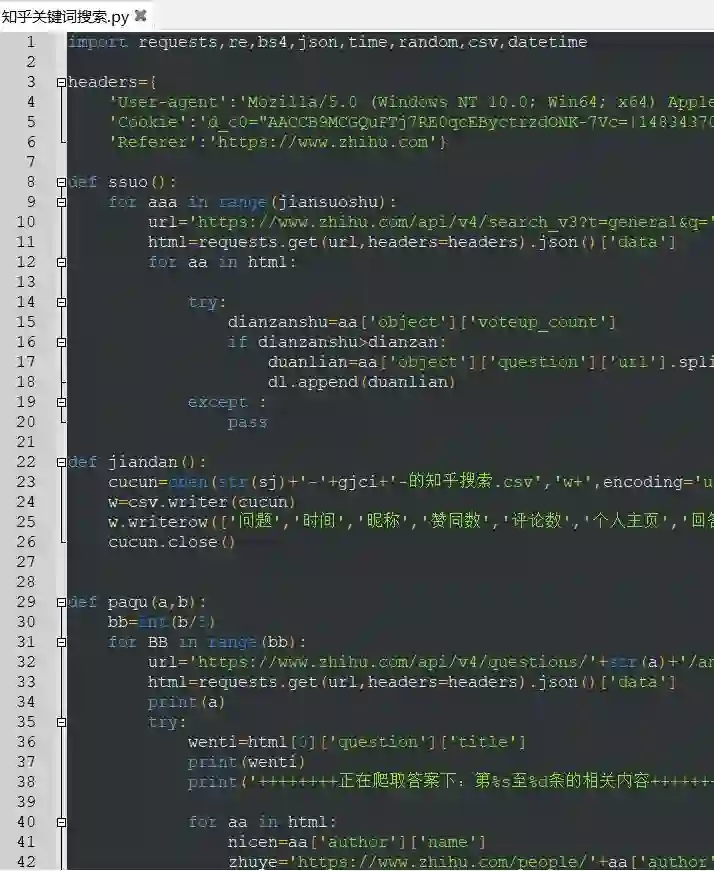
其实这些都不难
也就30分钟的工作量

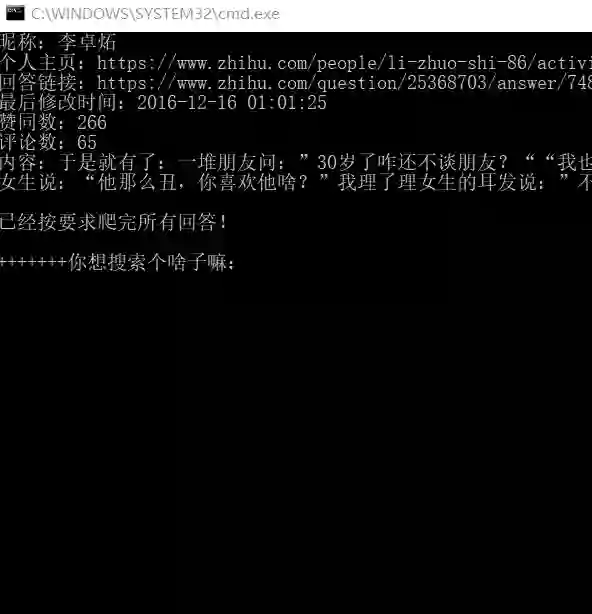
现在让我们来测试一下
比如,我这人有点闷
想学学幽默的沟通技巧

爬完关键词后
它还会问你要不要再爬
输入【结束】,就能停止程序
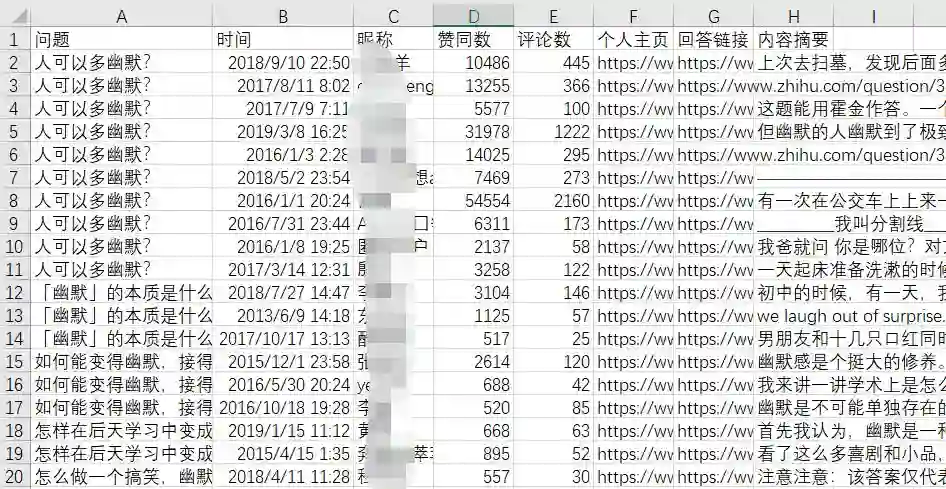
爬取的内容还会储存在表格中

自从捣鼓好这个爬虫后
我就犹如青春期的boy
拿到1024的邀请码
从此一发不可收拾


——————————————
往期精彩:




