7 月 22 - 23 日,在中国科学技术协会、中国科学院的指导下,由中国人工智能学会、阿里巴巴集团 & 蚂蚁金服主办,CSDN、中国科学院自动化研究所承办的 2017 中国人工智能大会(CCAI 2017)在杭州国际会议中心盛大召开。
文/CSDN周翔
![]()
俄勒冈州立大学教授、AAAI 前主席
Thomas G. Dietterich
在本次大会上,
俄勒冈州立大学教授、AAAI 前主席
Thomas G. Dietterich
发表了主题为《
构建强健的人工智能:原因及方式
》的演讲。
在演讲中,Thomas G. Dietterich
综合考虑了“已知的未知”情况(对不确定情形有一个明确的模型)以及“未知的未知”情况(模型不完整或有错误),
介绍了 7 种用于保证 AI 系统安全可靠的方法。
以下是 Thomas G. Dietterich 的演讲全文,AI科技大本营略做修改:
感谢大会的邀请,非常高兴今天有机会在这边演讲
。
我今天的演讲
跟前面那些
可能有所不同
,
技术性
没那么强
。当然,我也会讲到
一些数学
知识,但更多
的内容还
是关于人工智能
所
面
临
的挑战,以及我们现在
所
用的一些安全的解决方法。
首先
,我
会讲一讲我们对于
强健
AI
(
robust artificial intelligence
)的需求、背后的目的何在。然后,我
要
谈一下
,
在模型不完整的时候
,我们的
AI
系统需
如何来
正常工作。
我们知道,现在世界上
还
有很多东西是人工智能不知道的,我们的目标就是
要
知道
,
有什么样的方法
能
让
AI
研究社区来
解决这些问题。
人工智能已经有 61 年的历史了,我们怎样才能应对
人工智能的不确定性,特别是
这些未知的未知(unknown unknowns)?
![]()
近年来,
人工智能
在技术上的长足
进展,让我们可以
考虑
一些
高风险领域
的进一步
应用,
比
如无人驾驶
、
自动
帮医生做手术
的外科手术机器人
,
还
有
在
金融
市场从事
自动化交易
的人工智能
,
另外
还有一些基础设施
相关的人工智能
,比如我的同事
正设法
用人工智能来提升电网的管理效率
。
当然,也有一些
极富
争议的
应用
,
例
如
,具备自主攻击能力
的武器
系统
。我认为这是一个
很糟的
主意,
世界各国应该就此协商,签署一份
限制
此类自主攻击武器研发的条约
。
所有这些系统都要去做出很多事关生死的重大决策,而人工智能和机器学习历经多年的坎坷挣扎,如今不过是勉强能用。我们并没有太多的时间来思考高风险应用上的强健性问题,但我们需要系统在面对错误时也能十分稳定地运行、不出故障。
这里的错误包括很多方面:
比如说
,
有时候会有人为的错误,还有一些
会
是网络攻击,或
是
设计者
和使用者
一开始就要求系统去做错误的事情
,
但我
今天要讲的两个重点
,则集中在
不正确的
模型
与无法
建模的
意外
现象
方面。
![]()
为什么我如此担心那些无法建模的现象呢?其实有两个原因,一是我们没有办法对世界上所有东西都建模,二是没有必要对所有东西都进行建模。
![]()
就人工智能的历史而言,我们所讨论的问题集中在两个方面:其一是先验条件问题(qualification problems),我们无法把某个行动所有的先决条件全都数字化。比如说一辆车要起步,那么燃料、电池、车钥匙就要考虑在内,但还有其他的条件我们可能就忘记了,此类我们所无法完整考虑的先决条件是无穷无尽的。另一个是分支问题(ramification problems),也就是说,我们无法把一个行动可能会产生所有的后果加以数字化。这里,我认为同样重要的一点是,不要把所有的东西都进行建模。
![]()
我们都知道,机器学习关于错误率的基本理论是,模型的出错率与其复杂程度成正比,与样本的大小成反比。如果数据量很小的话,我们就不能用特别复杂的模型,尤其是深度网络,因为它们相当复杂。其后果就是,在样本很小的情况下,我们的模型就必需非常简单。我们的模型要比现实世界简单,尽管这一点大家心知肚明,但我们还是要使用简单的模型。我们必须慎重地简化模型,因为这是优化预测准确度的方法。
![]()
一个 AI 系统,是需要在没有对整个世界完全建模的情况下有用的。当我们看一些安全至关重要的应用时,它会有什么结果呢?
接下来我会讲一讲达到强健的 AI 的一些方法,以及我们作为一个研究社区的一些想法。
![]()
首先从生物学来看,进化其实并不是优化,其实它只是选择在这个环境能够存活下来的有机物。我们可以说,生物学上的进化其实就是选择最强健的物种。因为,这个地球上现存的物种经历了各种挑战,比如说气候变化等等。
我们能够存活下来,是因为我们要跟很多其他的动物进行竞争,他们让我们更强壮。同时,我们还有很多不同的个体组成的群体。另外,我们每个人内部也有冗余,比如说每个基因都可以分为隐性和显性,这样我们可以把自身没用到基因传给未来的子孙后代,让我们得以保持基因的多样性。我相信,生物学给了我们很多关于强健的 AI 系统的启发。
![]()
这是我的演讲大纲。首先,我会讲“robustness to known unknowns”,我们的模型包含了反应外界重要因素的变量,但是我们对他们是不确定的。接下来,我会讲“robustness to unknown unknowns”,针对无法建模的现象。
1. 针对不确定性的决策
![]()
在上个世纪50年代的时候,我们第一个想法就是在不确定的情况下怎么进行决策。
我们来看一些标准的策略过程。首先,我们会观察
目标值
Y,然后要选择Action(行动) A,来让它的期望值达到最好的效果。我们把这样的决策进行建模:E[U|A, Y],希望把期望的效应达到最大化。
我们可以将该不确定性
模型
定义为
P[U| A, Y],这是你通常会看到的东西
:在
任意一本有关人工智能的书或者经济学的书
里,都可以看到
。
![]()
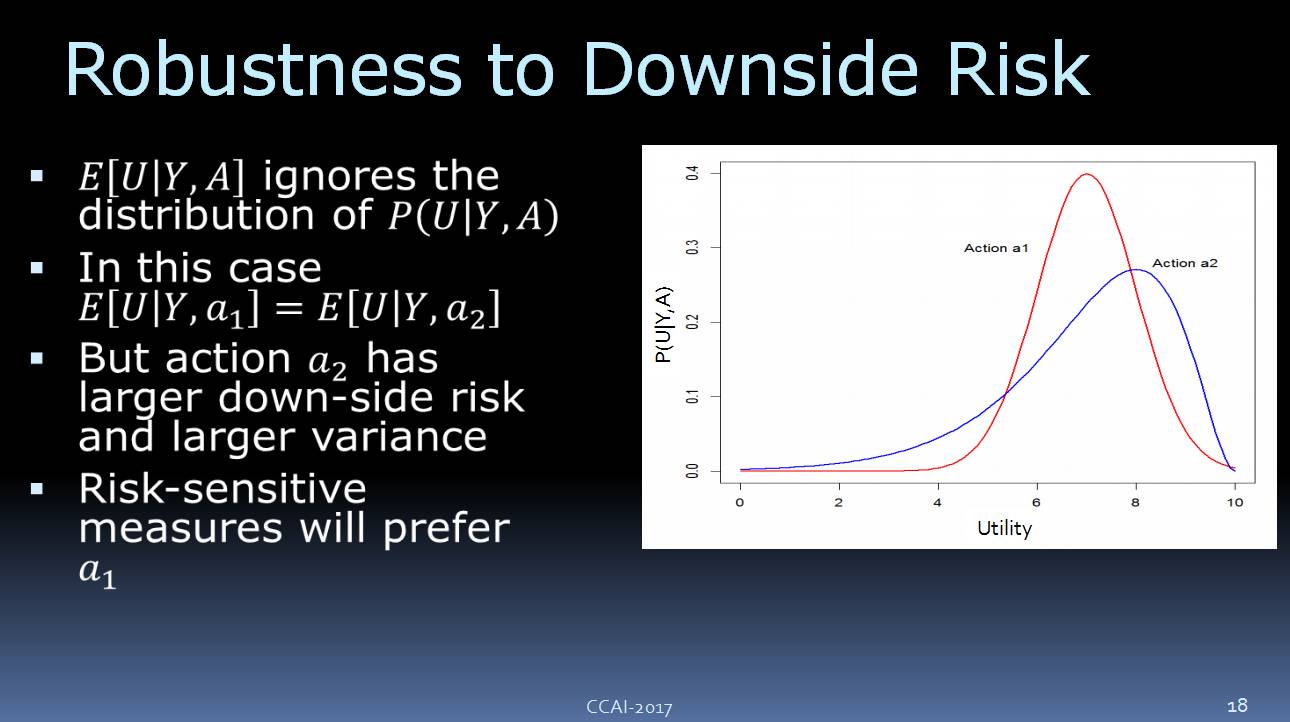
看看上面这个图,我们这边有两种不同的 Action:Action a1 和 Action a2。如果选择 a1,我们会得到如红线所示的结果,如果选择 a2,我们会得到如
蓝
线所示的结果。两者期望的效益是一样的,但是 a2 的
变化较大一些,有较高的上行风险和下行风险。
如果说对它们进行优化,其实两种都是非常好,但是很多人对 AI 系统里面的风险非常的敏感。如果说你对于风险敏感,那么
更多地可能会
选择 a1。
2. 强健的优化
![]()
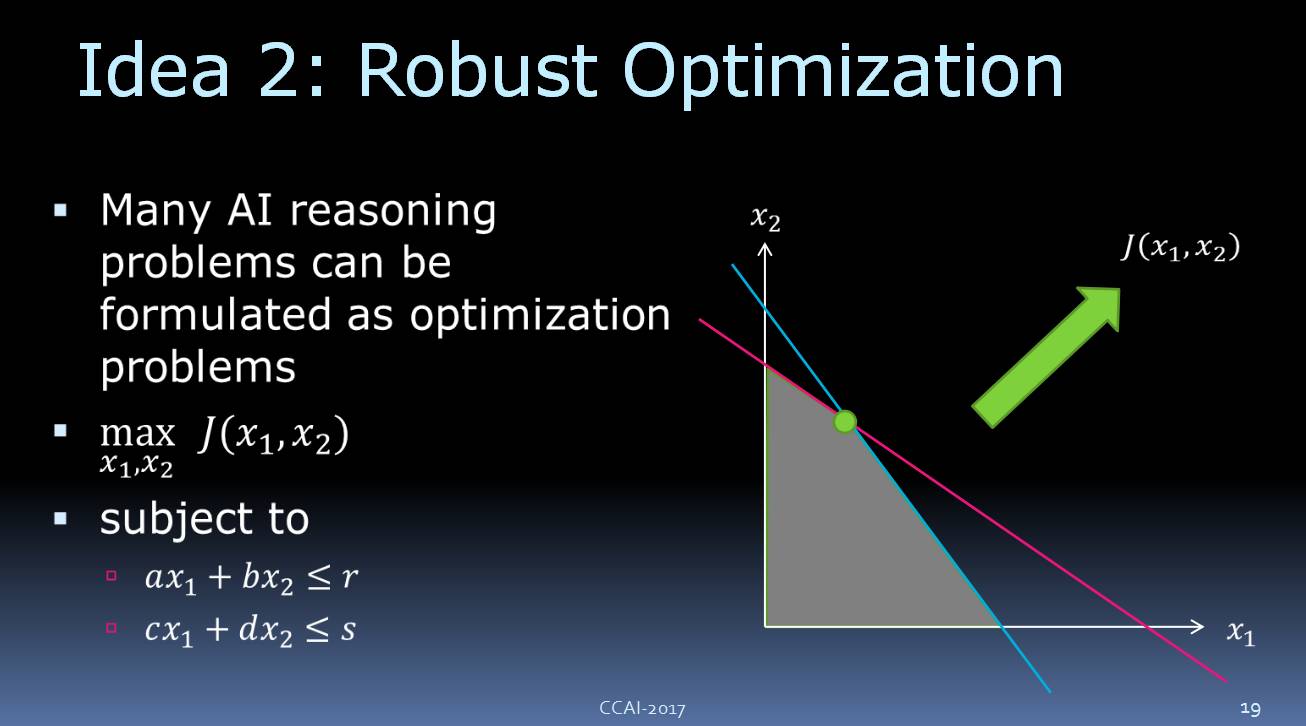
实际上,许多 AI 推理问题都可以
理解为
优化问题
。
我们来讲课本里的一个简单线性问题,如上图所示,这里面有两个变量,分别是 x1、x2,以及两个限制条件:(a*x1 + b*x2)小于等于 r,(c*x1 + d*x2)小于等于 s。
随着绿色箭头的方向,目标是在增长的
,
因此
我们可以在这个可行区域内
找到最佳优化
点。
![]()
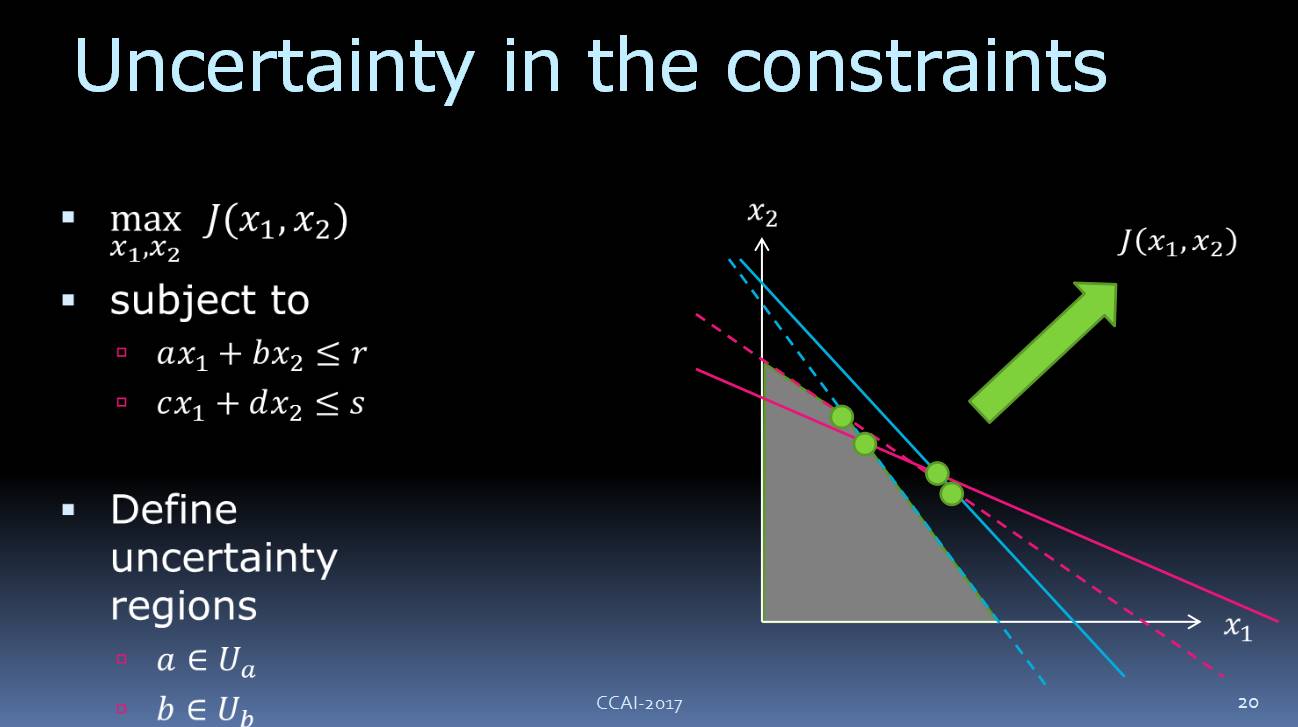
假设我们对这些限制不确定,
那么
我们
需要
使用不确定区间。这个的想法是
,
我们有常
数
a
、
b等等,我们不知道他们确切的值,但是我们知道他们属于一个不确定区间
。比如,
a
的不确定集合
是
U。这是对不确定性的另一种表达方式,但是更实用。
现在我们想最大化
目标值
,
那么
我们该如何
解决
这些不确定区间
带来的问题呢
?假设红线是我们这些常量的替代值,那么
这里的交叉点
就是最优解决方案
。
当然这在我们的问题中是不可能出现的,区域优化在对新问题来说是不
适用的
的。当
限制条件不确定时
,
规划的
解决方案可能不可行,
这将
导致非常严重的问题。
对此我们该怎么办?
![]()
其中一个方案是使用极
小化极大算法(一种找出失败的最大可能性中的最小值的算法)
来消除不确定性。我们有
adversary
,
并允许从
不确定集合中选择
a
、
b
等常量的值。
通过这种方案,我们
可以得到
稳健的
解决方案
,
然而这种方案太过保守。
![]()
根据 Bertsimas 在 MIT 的工作,这里其实有一个很重要的思想:给 adversary 加一个 budget。
现在我们可以分类讨论
bugdet
B。当设置
B
为
0
时,我们会得到
最初
的线性方程。如果
B
很大,那么这个我们
就有很大的可能性达不到目标
。所以我们可以通过
B
来预测结果到底如何。这是针对
“
budget on adversary
”
强优化的最新想法。
![]()
现在有一些非常有趣理论:现有一些 AI 算法是可以被看作稳健性优化。其中一个例子是支持向量机监督学习设置。我们给一些未知函数 y = f(x)训练样本,并且给出了一个损失函数 L(y(hat),y),当正确答案为 y 时,观察输出 y(hat)。
然后,我们找到能够将损失总和最小化的 h,公式如上图所示。
![]()
在Xu,Caramanis & Mannor
2009 年的
论文中(
如上图所示
),他们展示了这种正则化的方法相当于强优化。
3. 优化对风险敏感的目标
![]()
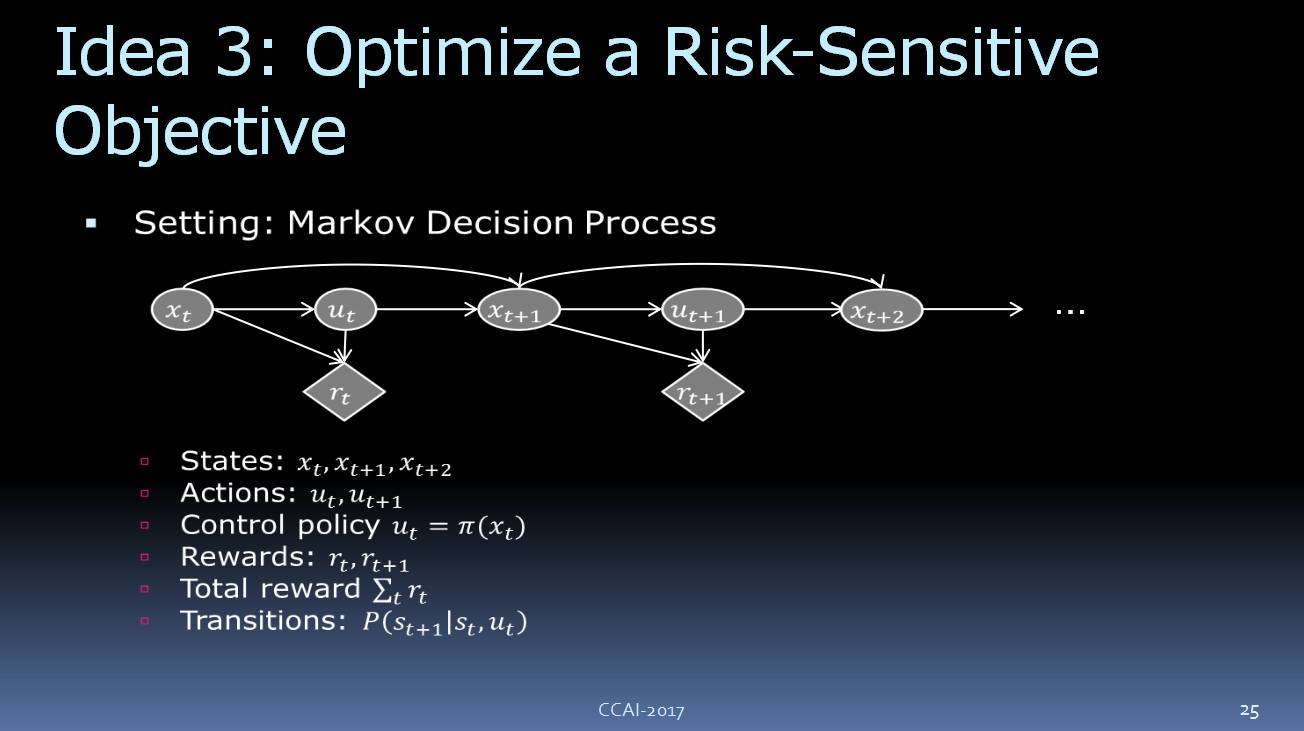
现在,让我们考虑一下,如何利用马尔科夫决策过程(Markov decision process)来对风险敏感的目标进行优化。用这种方法来决策流程的最大问题是,你必须先观察这世界找到策略设定回馈,你要设定最终的目标、反馈。
想象一下标准的马尔科夫决策问题过程,我们通过代理(
agent
)来观察这个世界的状态,这个代理会根据一些政策来采取行动,并收到回馈(reward)。比如,下围棋的时候一直到游戏结束才能得到 reward,但是在驾驶汽车时,每做一次正确决定就会得到一次 reward,或者至少免受惩罚。
![]()
![]()
![]()
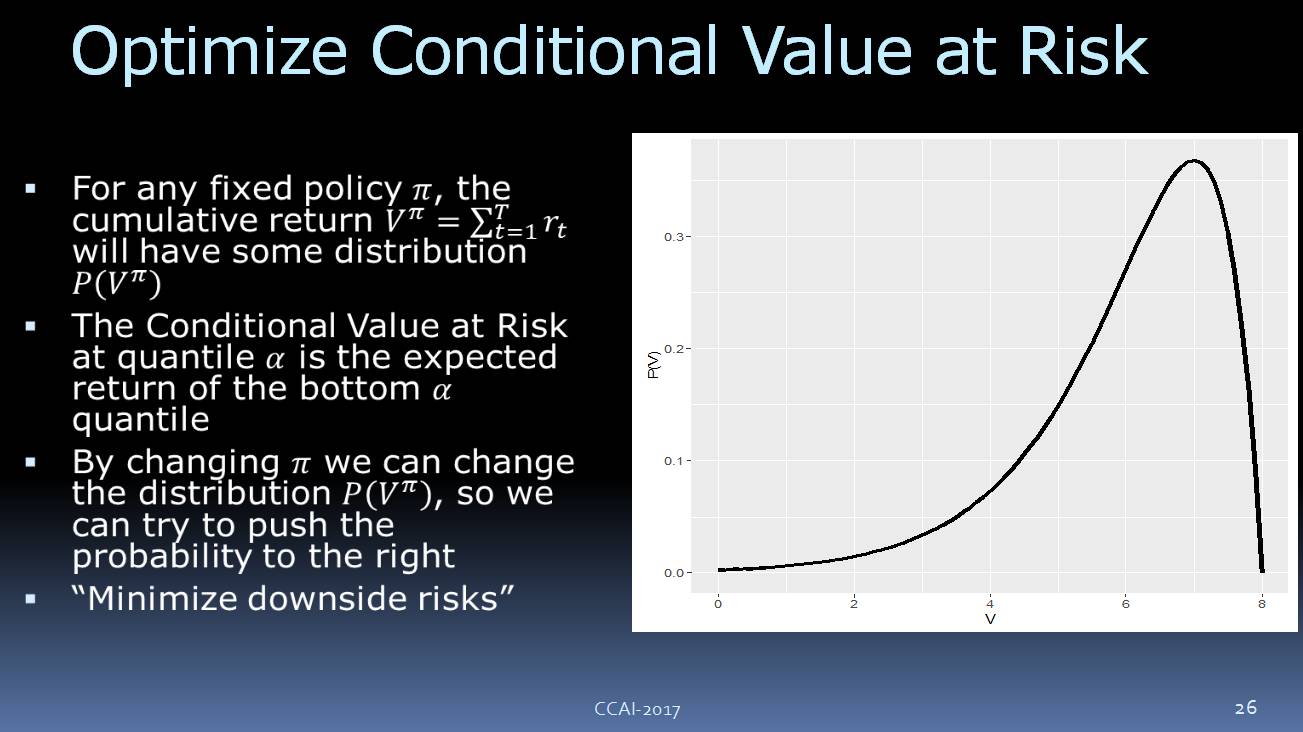
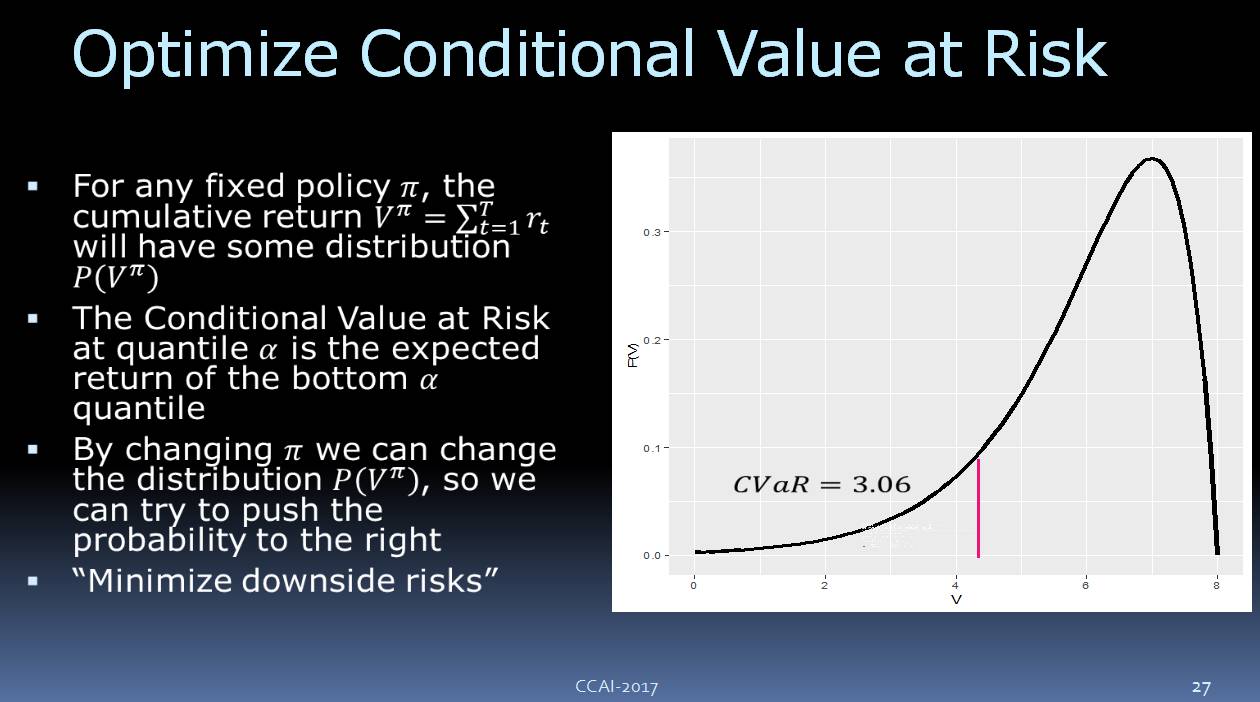
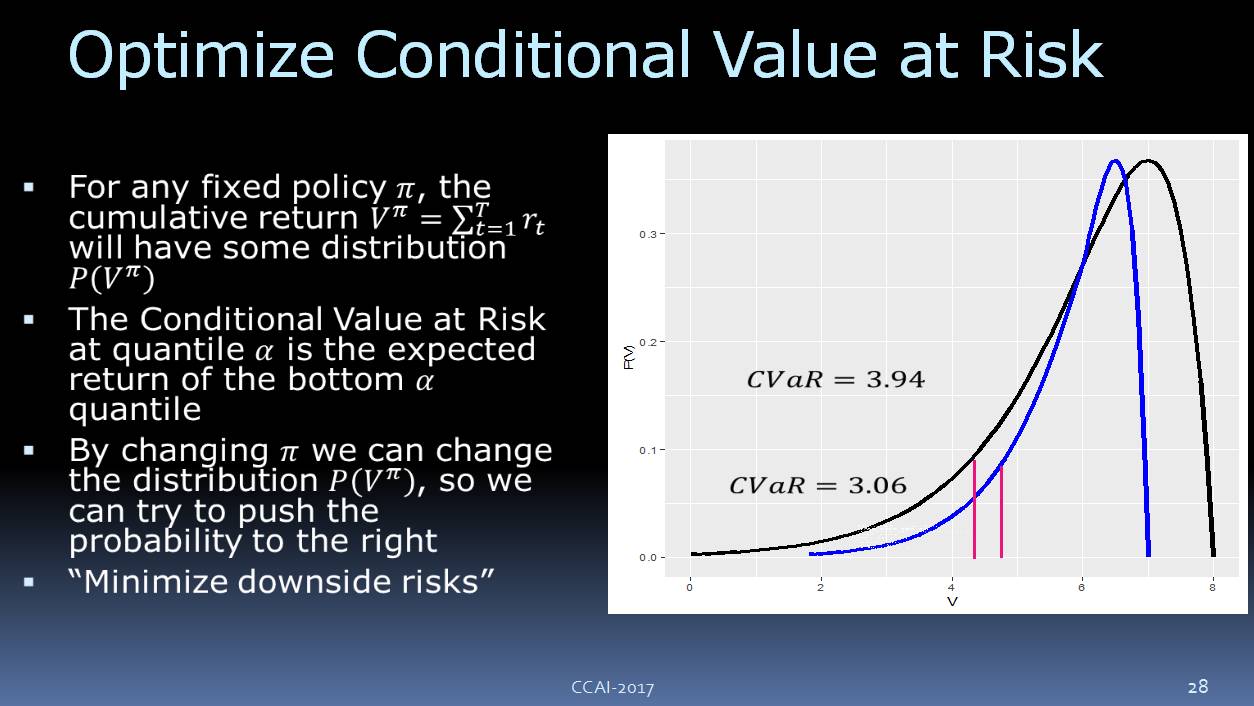
另外,我们还需要一个总回馈参数。我们来看一下,如果策略是固定的,我们要执行它,你可能要调整其他的一些参数,可以想像我们所收到的回馈参数会有这样的概率的分布,可以看到,它有一个下行的风险。我们要优化这个目标,让它尽可能避免下行的风险。我们现在使用的是 CVaR(Conditional Value at Risk) ,如上图所示。
![]()
这里可以得出一个结论:优化 CVaR,对模型的错误有更好的鲁棒性。
![]()
其实还有很多的例子,这边我就不谈了,因为时间的关系我们看下一部分。
4. 检测异常
![]()
首先,我们可以检测到模型里的缺陷。或许我们不能修正他们,但是至少我们可以检测出来。如果我们能检测到模型里的某个异常,那么我们就可以寻求用户的帮助,或者我们可以采取一些我们认为比机器学习到的更安全的措施。
![]()
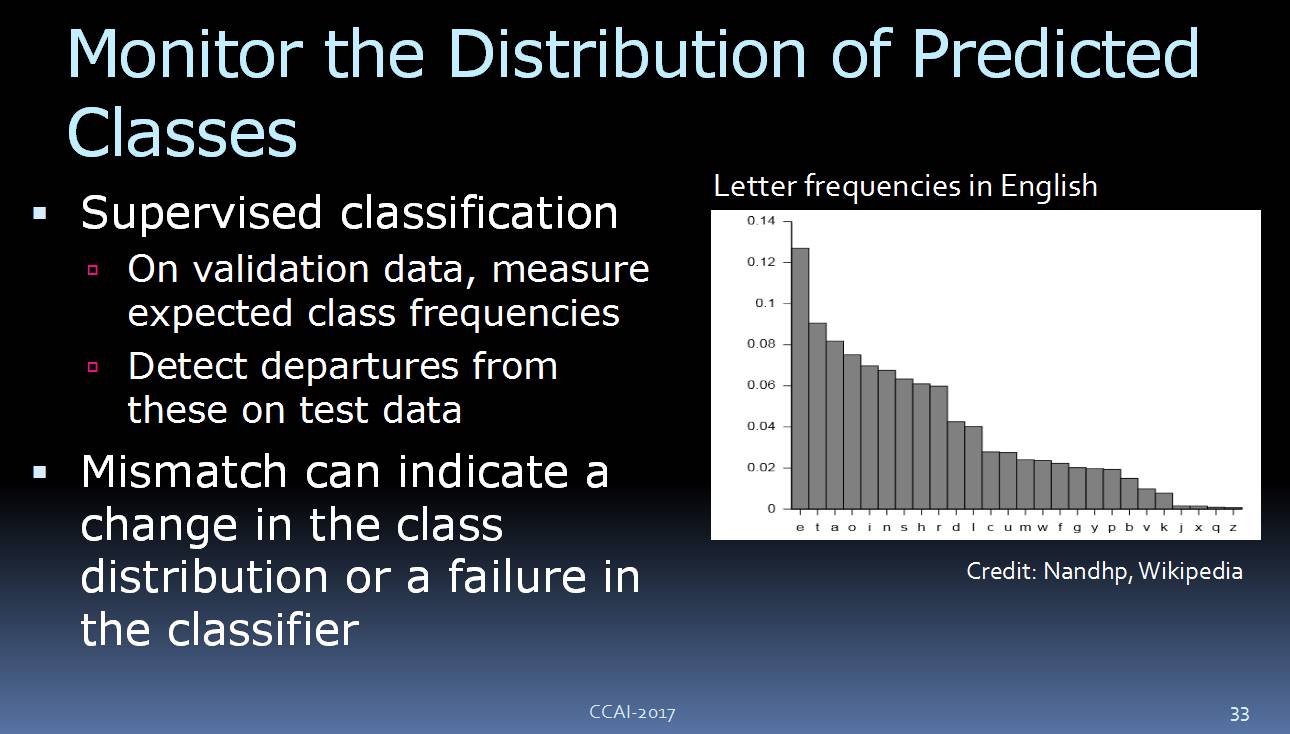
比如,我们可以监测预测类别的分布。试想一下,我们在做手写字符的识别系统,在英语里面,我们知道字符其实是有一定的分布频率的:最常见的英语字符是“E”,第二常见的是“T”等等。我们可以观察一下模型的分类器的结果,对比预测的分布,如果两者相差很大,那么很可能是出了问题。
![]()
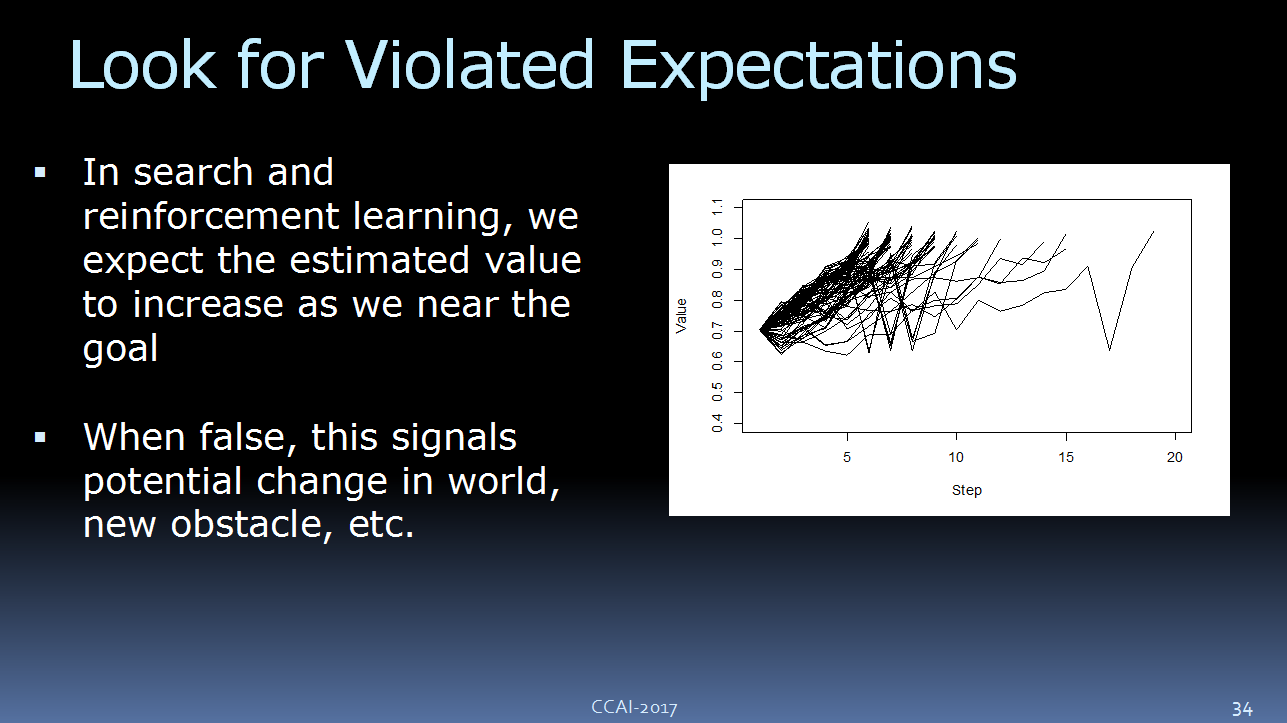
另一种方法是马尔科夫决策过程。举个例子,如果我们正在玩游戏,并希望达到某个目标,那么我们玩的时间越长,离达成目标的距离就越近。
比如,这是我们的预期价值函数,这是解决问题的步骤。通常情况下,我们在玩游戏或者按计划执行时,我们是在朝上走的,最大限度的让价值最大化。当然,当我们做的不好的时候,我们可以看到有些曲线的轨迹并不是朝上走的。看起来就像我们脱离了轨道,这或许意味着我们的模型存在一些问题。
![]()
另外一件可以做的事就是监测辅助规律。Hermansky 写过一篇很有意思的论文,是关于语音识别的里面的未知的未知。在做语音识别的时候,你可以为不同的频段,比如低频、中频、高频,训练单独的识别器。在自然语言中,你发出的两个音节之间是有时间间隔的,因此我们可以监控这些间隔时长。如果我们发现分类器给出的分布结果和我预期的差别很大,那么我们就可以探测哪个地方出了问题。
Hermansky 提出了一个解决方案:弄清楚哪些频段其实是噪音,因为在给定的环境中,有一些类型的噪音源其实是集中在某一个频段的。
![]()
另外一个例子要追溯到 1992 年的一个自动驾驶汽车项目。当时的这个系统很简单,只有一个车道保持系统和一个自动转向系统,当时是用神经网络做的。在这个神经网络里,有一个摄像头用来拍摄道路、树木等,然后这些信息会通过 4 个隐藏单元,用来预测转向指令。
此外,这 4 个隐藏单元对输入的图片进行重构,这样就可以比较原始图片和重构后图片之间的差异,如果两者之间的差异较大,那么这个转向命令就是不可信的。
在这一想法中,相同的隐藏层要完成两项任务,因此我们可以监测这些隐藏单元。如果重构后的图片差异很大,那么这些隐藏单元的这项任务完成的并不好,这也就意味着,在预测转向命令这一任务上,这些隐藏单元可能也做的很差。
![]()
我们可以做的另外一件事就是观察异常情况。如上图所示,我们的训练样本的分布是Ptrain,通过这些训练样本,我们训练处分类器。我们的测试样本的分布则是Ptest。如果训练样本的分布和测试样本的分布相同,那么我们系统的准确性就能得到保障。但是通常情况下,测试样本和训练样本的分布是不一样的,在这种情况下,我们应该怎样做呢?
![]()
当然,你肯定听说过领域适应(Domain Adoption)和迁移学习。我要讲的可能是稍微简单一点的问题,仅仅只需要检测测试数据是否与训练数据不同,这个例子是基于我在计算机视觉领域的一项研究工作。
此前,我曾参加过一个生态学的项目。当时我们想要衡量美国淡水河流的健康程度,于是环保部门派了一些人去收集这些河流里的昆虫标本,将昆虫的分布状态作为判断河流健康程度的标准。
![]()
我们要做的是建立一个计算机视觉系统,来对这些昆虫进行分类,而那些户外的工作人员收集了 29 种昆虫作为训练的数据集。后来,我们利用这些数据训练一个监督学习系统,而且运行结果也不错。
但是,很快我们发现,有的测试数据并不是这 29 类中的一种,有可能是其他的昆虫、或者小石头、叶片、垃圾等等。
我们要怎样做呢?
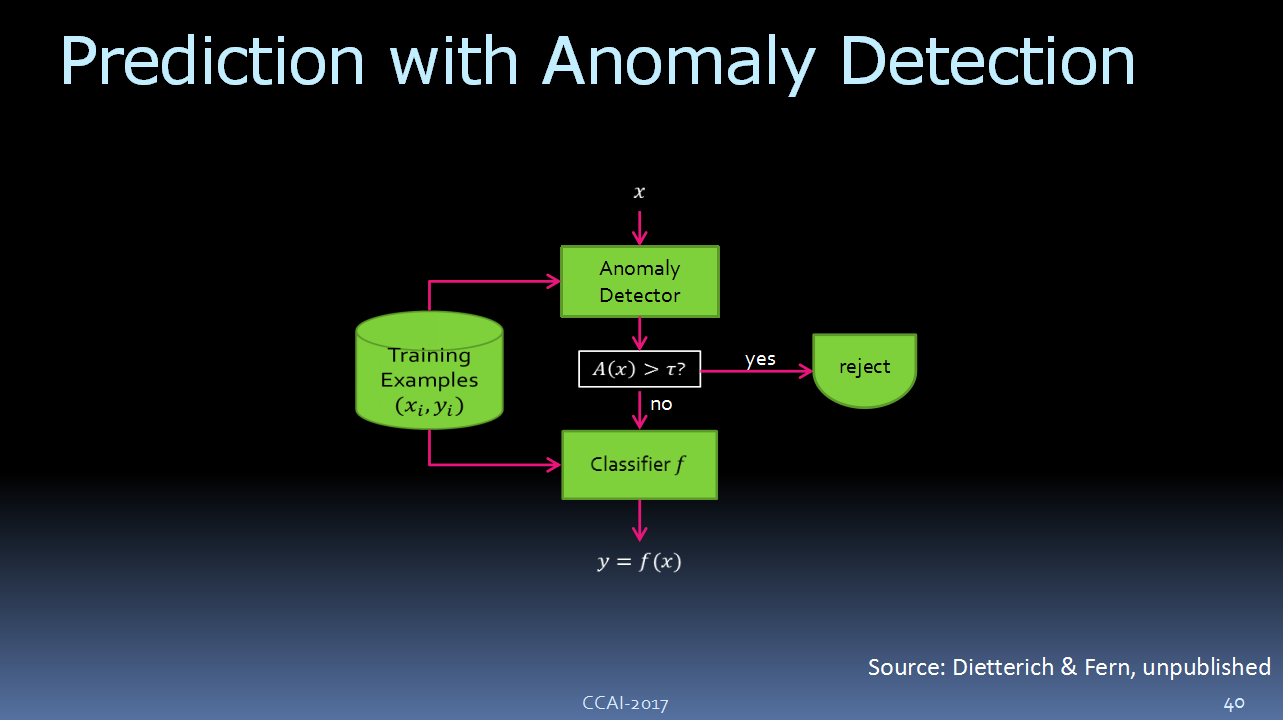
![]()
此前我们曾做过很多关于异常检测的工作,这里的方法很简单,就是在系统里加一个一场检测器,它主要用来负责检测新图片。如果这张图片与训练数据中的图片看起来很陌生,那么它就会给定一个“异常分数”,如果这个分数超过某个阈值,那么系统就会“拒绝”这张图片,如果低于这个阈值,那么就可以放行,进入到下一步——分类器。
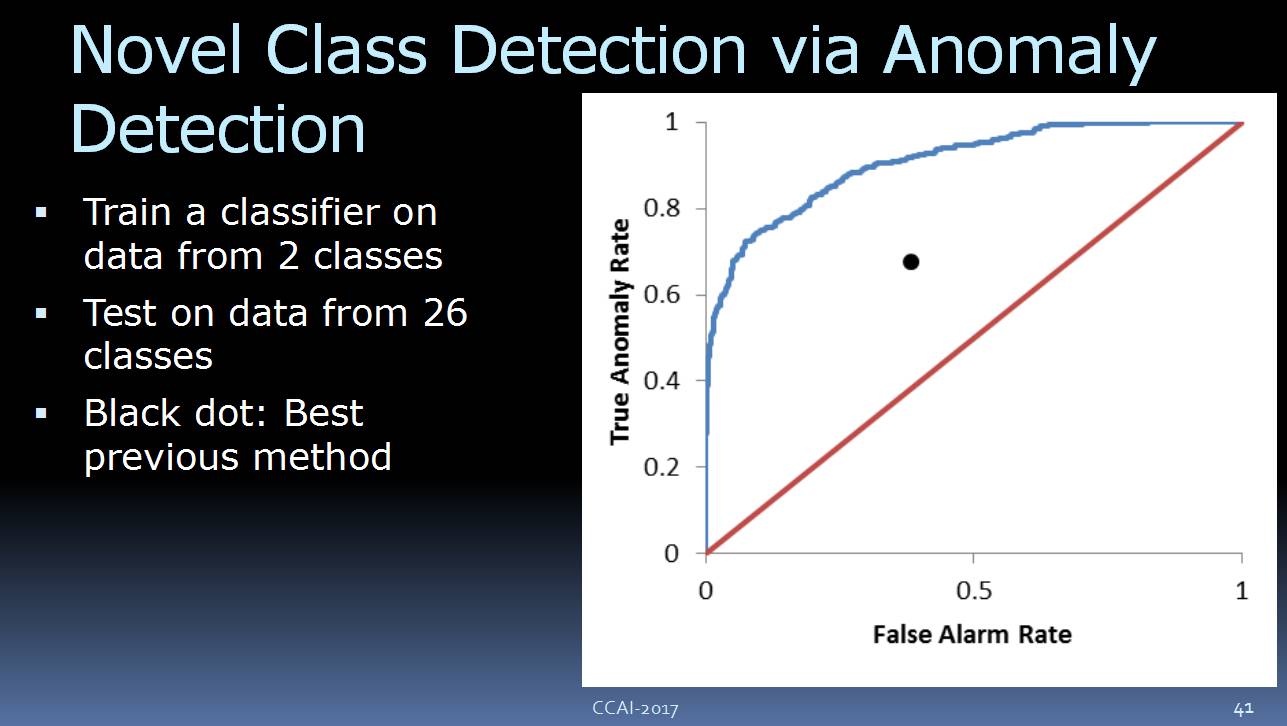
![]()
这里是一个初步的研究,我们训练的分类器时候只用了两个类别的数据,但是实际的测试数据包括 26 类。
![]()
实际上,还有很多其他的尝试,其中一些可能比我们现在的要好。比如Open Category Classification ,Change-Point Detection,Covariate Shift Correction,Domain Adaptation,这些都是和这些问题相关的。
5. 使用更大的模型
![]()
另外一种思路是直接增大模型。如果我们的模型缺少外界世界的信息,那么为什么我们不把模型做大一点,直接让模型具备更多的世界表征?而这就涉及到之前 Hans Uszkoreit(德国人工智能研究中心科技总监、北京人工智能技术中心总监兼首席科学家)所讲的:创建一个大型的知识库,特别是要从网络文档中抓取信息。
当然,这样做也存在一个通病。每当给一个模型增加一个新的组成部分,那么这个模型就会多一个出错的可能性。如果你在用这个模型做推理工作,那么很可能会出现错误。这实际上是另外一种过拟合的问题。
当我们想要避免额外的错误时,就需要让知识库保持简单。
6. 使用因果模型
![]()
还有一种思路是使用因果模型。 因果模型仅仅需要很少的训练数据,而且它们还以迁移到新的问题领域。
想象一下,采用因果模型,我们甚至可以对太阳和黑洞内部正在发生的事情做很好的预测。虽然不管以前还是现在,我们都没有与之相关数据,但是我们有能够信任的因果模型,可以派上用场。
7. 组合模型
![]()
AI 领域里另一个比较重要的思想是“组合(ensemble)”。每一个模型都可能会有不完整或者不正确的地方,但是将这些模型组合起来,我们可以做的更好。
在做的各位可能大多都知道 Kaggle 的竞赛,获胜者往往用的是“组合”的方法。
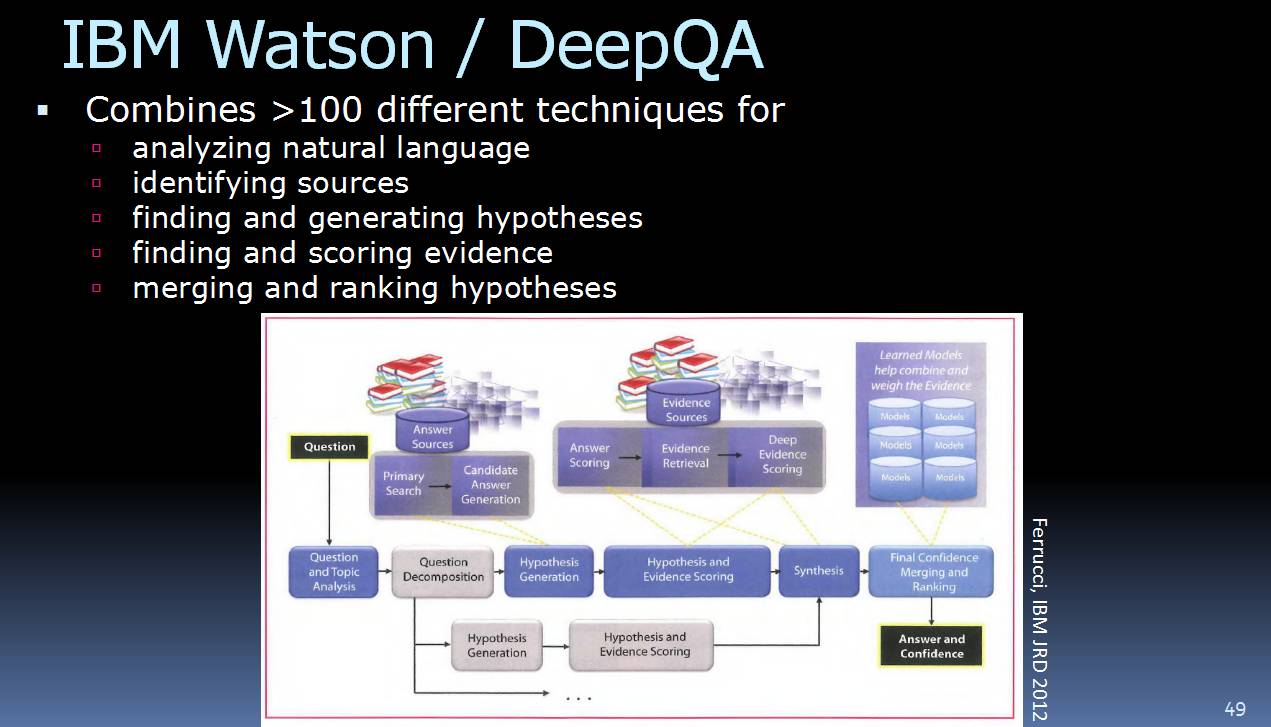
![]()
比如,IBM 的 Watson 实际上就是一个巨大的“组合”。它拥有超过 100 种技能来完成各种任务。此外,必应、百度、谷歌等也用到了很多技能的组合,比如,这些搜索引擎会综合排名、事实得分(evidence score)等方法来确定给用户呈现哪些搜索结果。
总结
![]()
上面这张图,列举了现有的可以帮助我们构建强健计算机系统和 AI 系统的各种方法。
首先,针对已知的未知,也就是当我们有一个模型,但是想要检测里面的错误时,要怎么办?正如我刚才所讲,我们可以在概率模型上使用“Risk Sensative Decision Making”的方法,或者我们可以利用对抗式的方法来进行优化。
接着,我谈到了“
robustness to unmodeled phenomena
”,这里针对的是未知的未知。刚刚我提到,我们有一系列的办法可以探测模型是否不完整,以及为什么有时会失效。但是,有的时候,我们能做的只有向人类寻求帮助。可以大胆猜测,大部分的 AI 模型都还太小、太简单。未来,我们需要比现在大得多的知识库,这样我们才能使用更大的模型。
此外,我还介绍了因果模型,这些模型类似于迁移学习,一个模型可以适用于不同的场景。最后,我提到了组合模型的方法。
今天,新一代的 AI 系统正被用于各种令人激动的领域,值得注意的是,其中很多应用都涉及到与人身安全相关的高风险决策,因此,我们需要构建强健的 AI 系统来解决这些问题。
AI 系统不可能对所有情况建模,因此这些系统需要在建模不完全或者包含某些错误情况时也能正常运行。
除了上述提到的这些思路,我们还需要更多的想法,希望未来在座的各位也能有所贡献。
谢谢大家!
CAAI原创 丨 作者Thomas Dietterich
未经授权严禁转载及翻译
如需转载合作请向学会或本人申请
转发请注明转自中国人工智能学会
CCAI 2017更多精彩内容,欢迎点击阅读原文,一次掌握“现场微信群”、“图文报道”、“视频直播”、“PPT下载”以及“大会期刊”所有入口!