搞定 Linux 命令之进程与数据流,不服来辩!| 原力计划


本文中,我们将一起来学习Linux进程和数据流的操作,比如过滤文本,统计文本、重定向、管道流、进程操作等,当然只是谈谈常用的命令以及参数,如果想详细看的话可以man command,利用Linux自带的命令手册去查看一下你想查的命令。文章比较有趣,相信大家看了以后会很有收获的!当然,如果说里面有什么问题的话,欢迎和博主华山论剑。

数据处理
1.grep:进行数据的过滤与筛选。我们平时处理文件时,肯定想查找或者过滤一下我们感兴趣的信息,那么我们就会用到这个东东了。
用法:
grep text file:这个就是在file文件中查找text文本内容了
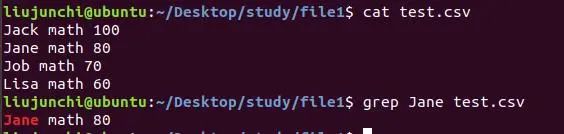
这个就是在test.csv文件里面查找Jane内容了,查找到了就会打印出来它所在的行,并且会给它点颜色看看。
当然,我们查找的文本如果没有空格可以直接输入,如果说有空格的话就要用双引号包起来。
grep -i text file:查找文本内容的时候忽略大小写,其中的i选项就是ignore的意思嘛,忽略大小写。

查找jane的时候忽略大小写,因此查到了Jane。
grep -n text file:n表示number的意思,查找文本内容的时候显示对应行号 :

这个就把查找内容对应的行号显示出来了。
grep -v text file:v表示invert,即颠倒的意思,查找与文本无关的内容。

这个说好了查找80,结果颠倒过来不听话给出来和80无关的行内容。
grep -r text file:r表示recursive,即递归的意思,在子目录,子文件当中查找文本内容,file一般为目录。如果你不知道你要查找的文本在哪个内容,就可以一气呵成干脆点,目录里面全盘搜索。
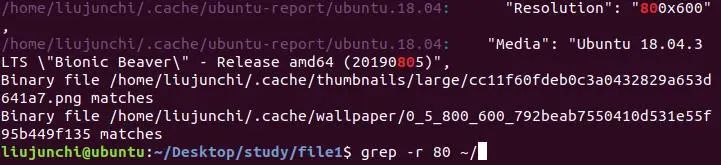
不小心在系统根目录里面查了个80,结果一堆和80有关的,看来是全局搜索没错了。
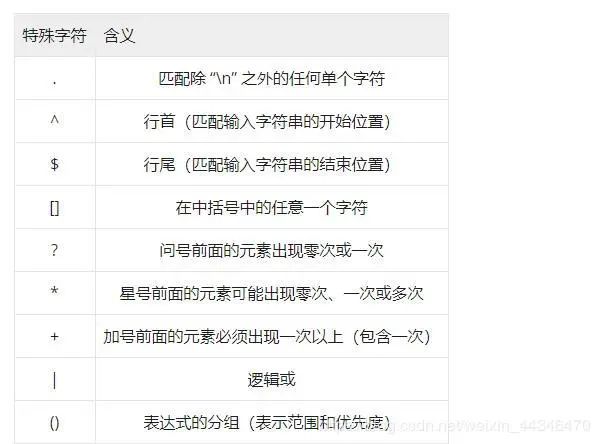
grep搭配正则表达式:接参数E。看看一些常用并且传统的正则表达式符号:
来试试:

这个就是利用符号^来查,就是查找开头为Jane的文本行内容,你看这不打印出来了嘛。对于其它的符号,大家都可以试试。
2.sort:对文本行内容进行排序。如果说你在操作文件的时候,感觉好杂乱无章,你想让它更好看一些,就可以排序一下。
用法:
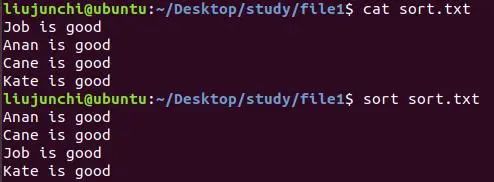
sort sort.txt:对文本行内容排序,默认的是对文本行的首字母进行升序排序:
sort -o new_file file:给file文件排序,将排序以后的结果存入到新文件中,如果说没有这个文件,那么就会创建。
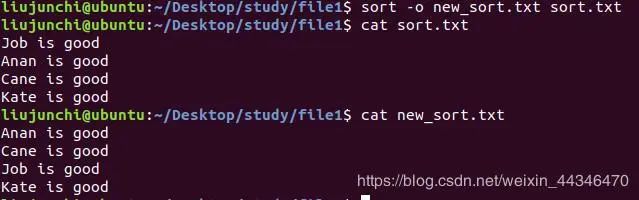
sort -r file:有人可能会问,咦,为什么只能升序排呢?不能倒序。我想说这个就是倒序了,r就是reverse的意思嘛,按照行内容首字母倒序排序。

sort -R file:随机排序,这个看心情吧,它想怎么排就怎么,很叛逆。
sort -n file:既然有根据首字母来排序的,那么遇到数字怎么办,那就用这个,n就是number,数字的意思,对数字排序
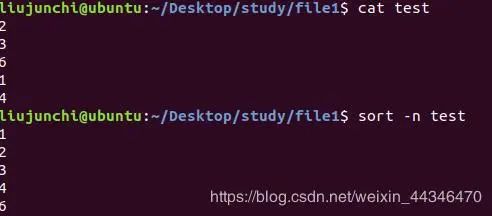
当然,以上所有的参数都可以搭配使用,比如说对数字倒序排序:sort -r -n file。灵活变通就行啦。
3.wc:这个可不是我们平时说的WC,用处可大了,可以统计我们文本当中的行数,单词数,字节数等等。
用法:
wc file:统计file文件的行数,单词数,字节数(从左至右显示列数)。
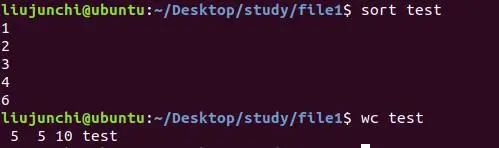
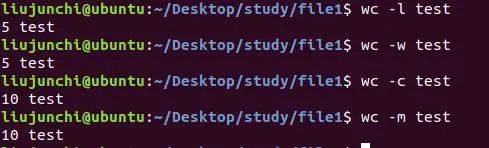
wc -l file:只统计行数,l就是line嘛。
wc -w file:只统计单词数,w就是word。
wc -c file:只统计字节数,c就是count嘛。
wc -m file:只统计字符数。
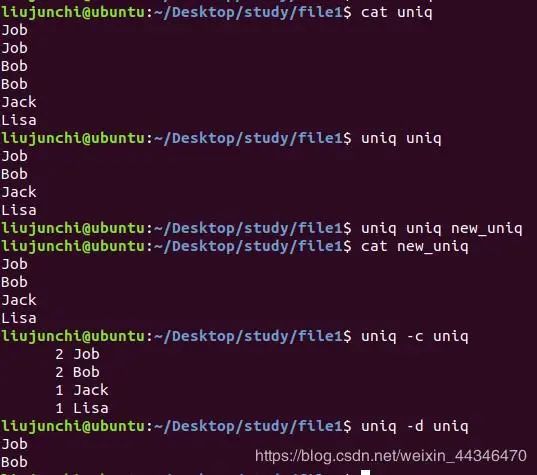
4.uniq:uniq一看就直到是unique,与众不同嘛,那么就允许重复的出现,这个就是为了删除文件中的重复内容。
uniq repeat.txt:删除该文件中的重复内容,打印出处理后的内容
uniq repeat.txt new.txt :把处理后的内容放到一个新文件中
uniq -c repeat :显示重复的行数,比如说1重复了3行,那么显示3 1
uniq -d repeat:d就是duplicated,即重复的,只显示重复的行的值
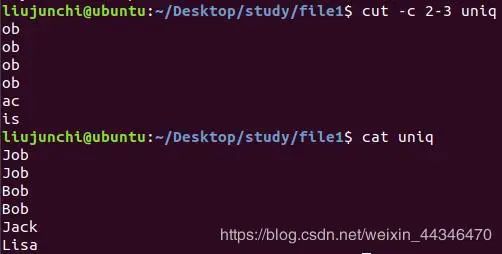
5.cut:剪切文件内容,可以做到提取部分我们想要的内容。
用法:
cut -c 2-4 file:每一行只保留第2到4个字符,-c就是根据字符剪切。

输出重定向
我们输入一个命令以后,它的结果一般有三个去处:
终端(打印在终端上)
文件(把结果放到文件中)
其它命令的输入(它的输出可以作为其它命令的输入)
我们之前看到的有终端,文件的,接下来博主会介绍一种新的,即去往其它命令的输入(管道的时候会说)。
1.>: 把输出内容重定向到一个文件中,并且如果这个文件已经存在并且有内容则会覆盖。
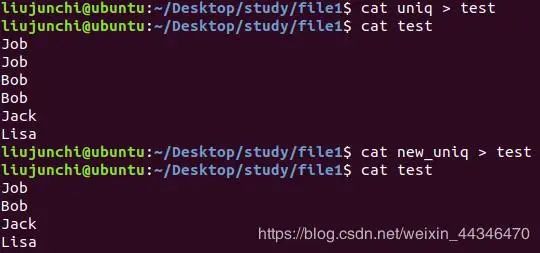
cat命令的结果最终重定向输出到test文件中去了,如果多次重定向到这个文件,那么就会覆盖之前的内容。
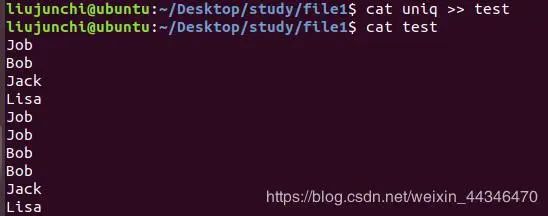
2.>>: 这个就和上面有点差别,虽然也是重定向输出到文件但是不会覆盖,只是会继续接到后面。
3. 2>:上面那几个都是标准输出的重定向,前提在于那些命令是对的,不会报错,但是这个命令就和上面不一样了,虽然用法一样,但是这个是标准错误输出的重定向,如果说命令错误了,那么错误信息就可以用这个来重定向输出。

4. 2>>: 这个也和上面介绍的>>差不多,只不过也是错误输出的重定向,不会覆盖。
5. 2>&1: 把错误和标准输出都重定向到文件中,一般放最后面,和>,>>一起搭配使用。
比如说:
cat not_exist_file.csv > results.txt 2>&1这个就是标准输出,错误输出都会重定向到results.txt文件中。

输入重定向
1.<: 文件输入,从文件中读取,以文件内容作为输入:
cat test.csv:就是以这个文件本身作为输入进行处理,也就是要先打开文件,再打印文件内容
而cat < test.csv:这个是将test.csv当中的内容作为输入进行打印
2.<<: 键盘输入,例:
cat << quit:就是打印键盘输入的内容,其中键盘输入以输入quit时截止
3.管道 | :把一个命令的输出重定向到一个命令的输入,命令与命令之间建立管道,可以多个。
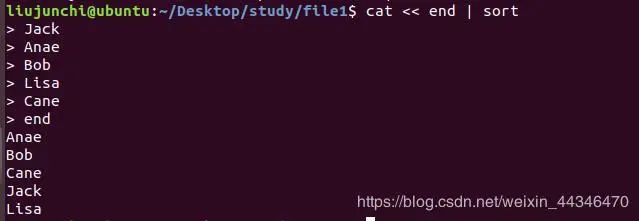
这个就是把键盘输入的内容,进行cat打印的输出,重定向到sort的输入,二者建立管道。
为什么用管道,管道能够更加简单,多个命令一起用嘛, 比如说du,就是深入遍历每一个目录:
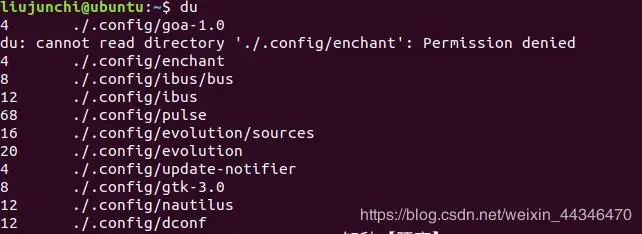
但是这样的话时间花那么久,而且列出来的杂乱无章,因此可以利用其它命令一起处理一下下:
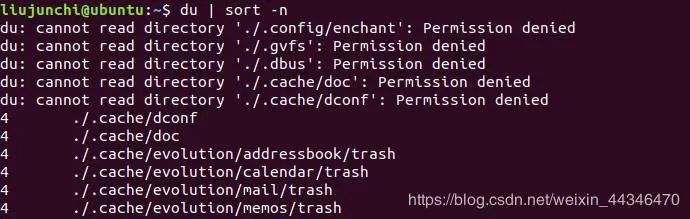
这样的话打印出来的文件目录就可以按照大小进行排序了,看起来就很舒服了。nice!!!

查看系统活动与进程
1.w:查看当前系统有哪些用户登录了以及用户的具体信息

从左到右看:
当前时间为01:25:36,运行正常(up表示正常),已经运行了两小时24分钟了,只有一个用户,之后的load average表示负载,三个数值分别表示:
1 分钟以内的平均负载(0.01)
5 分钟之内的平均负载(0.02)
15 分钟之内的平均负载(0.02)
之后两行就是登录的用户列表,分别为用户名,登录的终端名称,用户连接到的服务器的IP地址(由于这个是本机,因此是:0),刚开始登录的时间,用户多久没活跃了,该终端所有相关进程使用CPU的时间,当下进程使用CPU的时间以及当下运行的进程。
2.ps:列出运行的进程
对于ps命令:如果说不加任何参数,直接使用,就是列出当前用户在当前终端正在运行的进程(从左到右依次为进程ID,进程运行的终端,运行时间,产生这个进程的程序名):
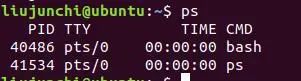
ps -ef:列出所有用户所有终端正在运行的进程

ps -efH:以乔木状列出所有进程
ps -u 用户名 :列出此用户运行的进程
ps -aux :通过CPU和内存使用来过滤进程
ps tree :以树形结构来显示进程,父子进程也有
列出的有:用户名 进程ID 父进程ID 产生进程的程序名等等。
但是ps命令有一个缺点,就是静态的,只能记录当下那一刻的进程,不会实时监控。
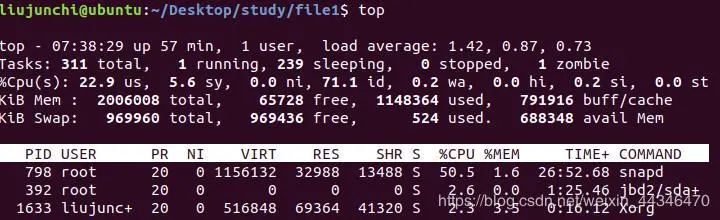
3.top:解决ps的缺点,可以动态查看,实时监控,但是至少显示前面几个最消耗处理器的进程,占满终端一页就行了。
当然,top还是可交互的,进入top后,还可以输入命令进行控制:
q:退出top
h:查看top内部命令
s:改变刷新时间,默认是3s
u:过滤进程,查看用户
k:杀掉某个进程,后面接ID
当然还有一些更好的,比如说:glances,htop这些查看进程的软件,需要的可以下载并且使用。

进程操作与系统重启
这个就比较简单了,就不做过多赘述了。
1.杀掉进程:
ctrl+C:快捷键可以终止终端中正在运行的程序
扩展:ctrl+shift+c可以复制,ctrl+shift+v可以粘贴
kill命令杀掉进程:
kill 7800:杀掉PID为7800的进程(当然可以同时加上多个进程PID,同时杀掉多个进程)
但是kill杀掉进程比较温和,有些进程不会马上结束。
如果需要马上杀掉,就输入:kill -9 7800
killall 程序名:杀掉多个进程,且程序名为find
2.系统方面:
halt:关闭系统
reboot:重启系统

前后台进程切换
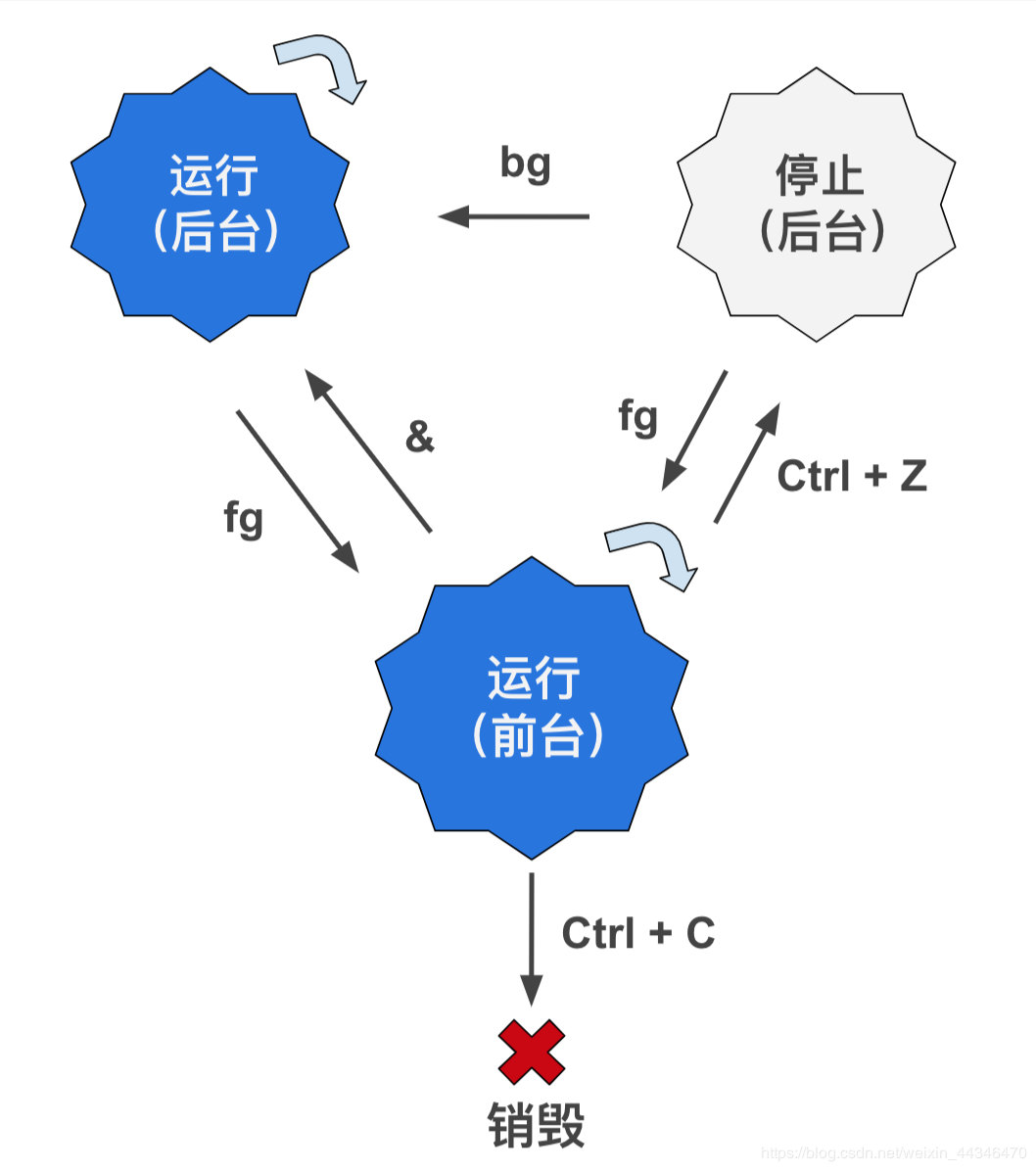
1.&:在后台运行进程,比如说:ls &:这个命令就可以在后台运行ls进程,我们不必要等他结束再输入下一个命令了。
但是这个和当前终端相关联,因此关闭终端以后,该后台进程也会结束。
但是nohup可以避免这个问题,让进程和终端分离:nohup command,放最前面。

这样ls就变成了后台进程,不需要等它列完,我们可以直接再输入命令。
2.ctrl+z:转到后台进程,并且暂停运行,也就是说这个进程还在,到后台去了:

之前运行了top命令,那么top就会占据整个终端,除非我们按q退出这个进程,否则不能继续输入其它命令(除了top内部的交互外),因此按下ctrl+z就可以把这个进程放到后台,然后暂停,我们就可以继续输入命令了(记住!!!进程没有退出,只是到后台!暂停了!)
3.bg:background的意思,背景后台嘛。转到后台进程运行,并不会暂停,如果说已经是后台,但是暂停,则会运行。
如果单独使用则针对最近的一个进程,一般是后面接进程标号
4.jobs:显示后台进程状态

这个就是我们之前的top后台进程了。从左到右依次为:后台进程标号 进程状态 命令。这个就代表着:top进程状态为Stopped,进程标号为1.
5.fg:既然可以转为后台进程,那么必然可以转为前台进程了,这个命令就是的,用法和bg一样。
来看看这几个命令之间的关系吧:

定时和延时执行
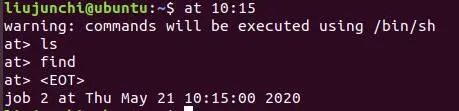
1.at:延时执行一个程序(sudo apt install at,要下载):
用法:
at 时刻,之后就会叫我们输入命令,我们输入的命令就会在我们设置的这个时刻执行,这个命令会叫你不断输入,直到你Ctrl + D 打住为止。
at now + 时间间隔:就是在现在开始的多少时间后执行
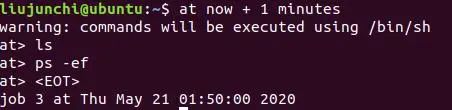
这个就是从现在开始的一分钟之后执行ls,ps -ef命令,并且定义为at任务3.
当然还有其它时间关键字,分别为:
minutes:表示“分钟”;
hours:表示“小时”;
days:表示“天”;
weeks:表示“星期”;
months:表示“月”;
years:表示“年”
2.atq和atrm:
atq:列出正在等待执行的at任务

正在等待执行的at任务是2号,在对应的时间执行。
atrm:删除正在等待执行的at任务,rm就是移除嘛!
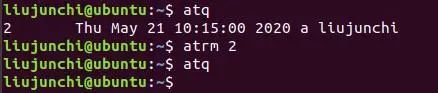
我的atrm移除了那个任务,因此atq之后没有at任务
3.sleep:休息一下再执行

这个就是先创建一个文件,暂停10秒后再删掉,暂停期间不能输入其它命令,和at不一样,at是过一段时间执行,但是输入完后,还是可以输入其它命令的。
后面接的数字默认为秒,但是还有其它的:
h:hour 的缩写,表示“小时”;
d:day 的缩写,表示“天”。
m:minute 的缩写,表示“分钟”;
比如说touch file.txt ; sleep 15m ; rm file.txt //这个就是暂停15分钟了
拓展:
上面的命令直接用分号分隔,其实就是命令的先后顺序,前面的执行完后,执行后面的,直接意义上,并没有关联性,不像管道那样。当然还有&&和||分隔符,看看它们和分号的区别:
&&:&& 号前的命令执行成功,才会执行后面的命令。
||:|| 号前的命令执行失败,才会执行后面的命令。
分号:不论分号前的命令执行成功与否,都执行分号后的命令。前后命令之间没有相关性。
以后你想一口气执行完你需要的命令就可以利用这些分隔符来。
4…crontab:定时执行程序
at是过一段时间执行一次命令,而这个是定时重复多次。
而crontab这个命令其实就是用来读取和修改名为crontab的文件,这个文件包含了我们要定时执行的程序列表,还有执行的时刻。
用法:
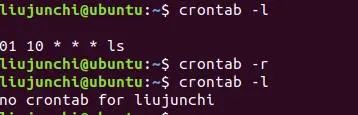
显示crontab文件:crontab -l

当然,刚开始是没有这些文件的,要我们自己去创建。
既然没有就去创建:
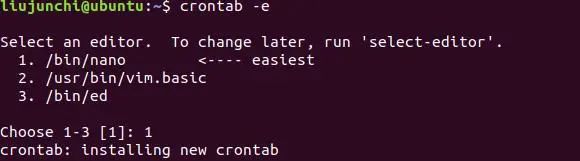
crontab -e:输入之后会进入一个编辑器界面(开始我们地选择什么编辑器,我选择了nano,就是1),这就是我们创建的crontab文件,我们只要输入我们要定时在什么时候执行我们的命令就行了。
格式:
定时时间 命令:定时时间分为五个区域,依次分别为分钟 小时 日 月份 星期几,如果说不想输入,就输入*代替就行了。

这就是我们编辑的定时命令:在每天的10点01分的时候执行ls命令。输入完以后保存就行了:
crontab -r:当然,如果我们不喜欢这个命令了就可以删除掉,这个就是来删除crontab文件的。
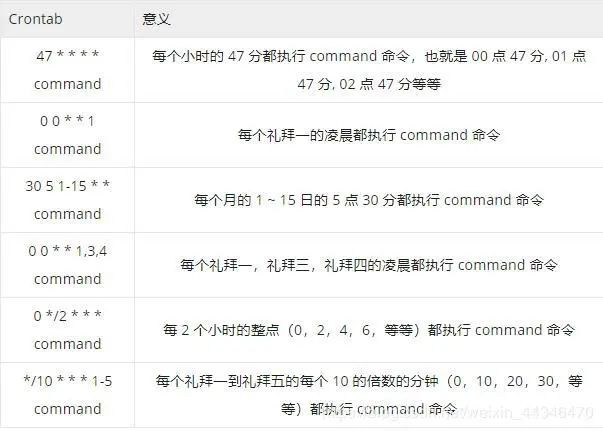
当然这里还有其它关于crontab文件里面的命令的相关举例:
版权声明:本文为CSDN博主「行者自远」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44346470/article/details/106263706
更多精彩推荐
☞Gary Marcus:因果熵理论的荒诞和认知科学带给AI的11个启示 | 文末赠书
☞好扑科技结合区块链行业发展趋势,重磅推出“好扑区块链合伙人”计划
![]()
你点的每个“在看”,我都认真当成了喜欢






