简单几步可视化Nature论文引用关系,百万量级数据全搞定

新智元推荐
新智元推荐
来源:爱思美谱(ID:acemap_)
指导老师:傅洛伊 王新兵;核心技术成员:李琦 亓杰星
整理编辑:三石
【新智元导读】目前已有的可视化技术可处理的节点规模上限在十万量级。当网络中节点数超过该上限时,布局算法的效率便急剧下降。上海交通大学Acemap团队便提出了一种突破百万量级壁垒的可视化绘图新方法。本文以Acemap数据库中收集的Nature杂志论文引用关系数据集为例,展现了超大规模学术网络可视化的破冰之旅!
数据可视化通俗来说就是使用图形来表达抽象数据的结构、变化、联系、或趋势。数据可视化的发展已经有几百年的历史,而上世纪五十年代计算机的发明使人类处理数据的能力有了质的提升。
与此同时,随着计算机技术的飞速发展,人类开始创造各式各样体型庞大的数据集。数据集的内容变得越来越抽象且复杂,简单的可视化方法已经无法满足人们的需求。
数据可视化用来创造一条快速认识数据集的捷径,图形化的数据表示方法能够将人类的注意力吸引到重要目标,搭建人类与数据进行沟通的桥梁。根据不同数据集的特点,对数据可视化方法进行研究,从而最终得到可视化结果的过程本身并不容易,因此大数据可视化本身就是一门艺术。

图1统计学家John Wilder Tukey:信息可视化理论的重要奠基者(1915—2000)
目前已有的网络可视化算法如Force Atlas,ForceAtlas2,Fruchterman Reingold,Yifan Hu等算法可处理的节点规模上限在十万量级。当网络中节点数超过该上限时,布局算法的效率便急剧下降。而学术网络中的节点数量通常在百万量级甚至更高,算法的性能瓶颈和实际需求间的巨大差异对于揭示实际学术大数据空间结构形态造成了巨大障碍,面临诸多严峻的技术挑战。
上海交通大学Acemap团队聚焦此项问题,另辟蹊径,提出了一种突破百万量级壁垒的可视化绘图新方法,为超大规模可视化的可实现性提供了新的突破口,开启了学术大数据空间可视化新纪元。接下来,本文将以acemap数据库中收集的Nature杂志论文引用关系数据集为例,向您展现超大规模学术网络可视化的破冰之旅!
超大规模学术网络——Nature杂志论文引用关系数据集
Nature杂志论文引用关系数据集来源于Acemap数据库,数据集包含了Nature杂志中的所有论文与这些论文引用的其他论文总共2053310篇。其中囊括了生物、物理、机械、化学、心理学等19个领域。从直观上来说,数据可视化完成后在整体上将会有明显的聚类效果,因为相同领域内的引用关系一定会比不同领域间的引用关系更加密切。除此之外,数据集中包含3426847条边,用来表示数据集中论文之间的引用关系。
破冰之斧——ForceAtlas2布局算法
ForceAtlas2布局算法是一种力引导算法。该算法整合了包括Barnes Hut近似,度决定性斥力,全局与局部迭代速度自适应调整等技术。相比于Force Atlas算法,ForceAtlas2运行速度更快,并且处理的图的规模更大。算法运行时,节点与节点之间将会相互排斥,存在连边的两个节点将会相互吸引。当算法稳定后,用户将得到一个稳定的布局。
斧之利刃——分割绘图法
当数据体量增长到一定程度后,以往的可视化方法无论从计算的准确性,还是可视化结果的可展示性都将遇到瓶颈,直接将所有数据放入布局算法中进行计算似乎是不可行的。于是我们提出使用分割绘图法对大规模学术网络进行可视化的方法。
分割绘图法的整体思路就是使用某种启发式算法,在数据进行可视化之前,检测数据的结构,并根据数据在结构上的联系将数据集分割为多个社区。分割后的单个数据集已经在布局算法可以处理的范围之内,这时我们需要将这些数据集进行分别布局,然后将布局完成的小图,以某种合理的方式进行拼接,最后再使用布局算法进行微调,即可得到最终的可视化。
破冰之旅——使用分割绘图法对学术网进行可视化
数据分割
我们使用启发式算法根据数据集节点在结构上的联系对其进行分割,分割的具体流程如下。

图2使用启发式算法实现数据集数据的结构分割流程图
图3为社区划分结果统计:
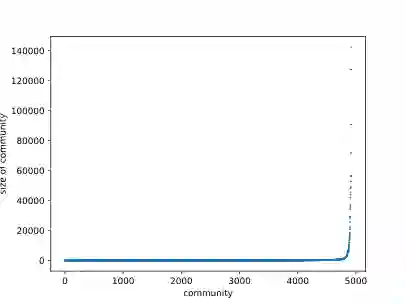
图3社区标号与社区中节点关系
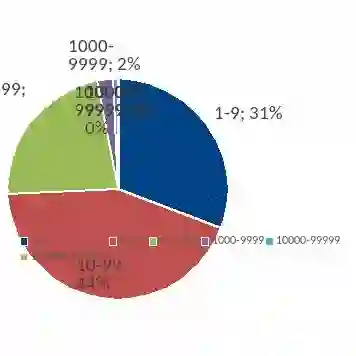
图4社区划分数量分布统计
图3显示了社区划分完成后4917个社区中节点数量的分布,图4显示不同社区节点数量级中社区数的分布。在社区数量分布来说,社区节点数量最多分布在1000以下,总共占总体的97%,社区中节点数量超过1000的占总体的3%,其中更是有两个社区节点的数量超过了12万,可见这些社区中核心节点的影响力之大。
根据社区划分的数量与最终的模块度可以看出:社区划分的效果较好,可知该数据集本身就具有非常强的结构性,且这种强结构性对后面图结构等效模型的提出有很好的启蒙作用。
等效结构的获取
为了解决社区的块间布局的计算,我们重新对基于引斥力模型的ForceAltlas2算法进行研究。在ForceAltlas2算法中,决定节点位置的最本质因素是一个节点所受的引力和斥力。同理,一个社区的最终位置也由该社区所受的引力和斥力决定,且社区内各个节点之间的力不会影响社区之间的引力和斥力。我们通过将社区中的所有节点等效为一个节点,进而得到数据集结构的等效模型。
图5为等效结构的Gephi渲染结果

图5 Nature杂志引用关系数据等效结构模型
该结构由社区节点数大于等于1000的149个社区进行等效,因为大图的总体社区结构应由节点数较多的社区决定,节点数较少的社区可能会对图的局部布局产生影响,但不会对整体结构形状造成影响,因此这些节点的作用可以暂时忽略。该图中的绿色节点表示社区的等效节点;绿色节点间的连边表示不同社区之间的等效连边,他们有不同的权重;绿色节点外的白色节点的作用是为了平衡不同社区之间的斥力。
子图的分别布局
我们使用ForceAtlas2算法对划分的结果进行分别布局,图6为ForceAtlas2算法收敛后选取的部分社区的可视化结果:
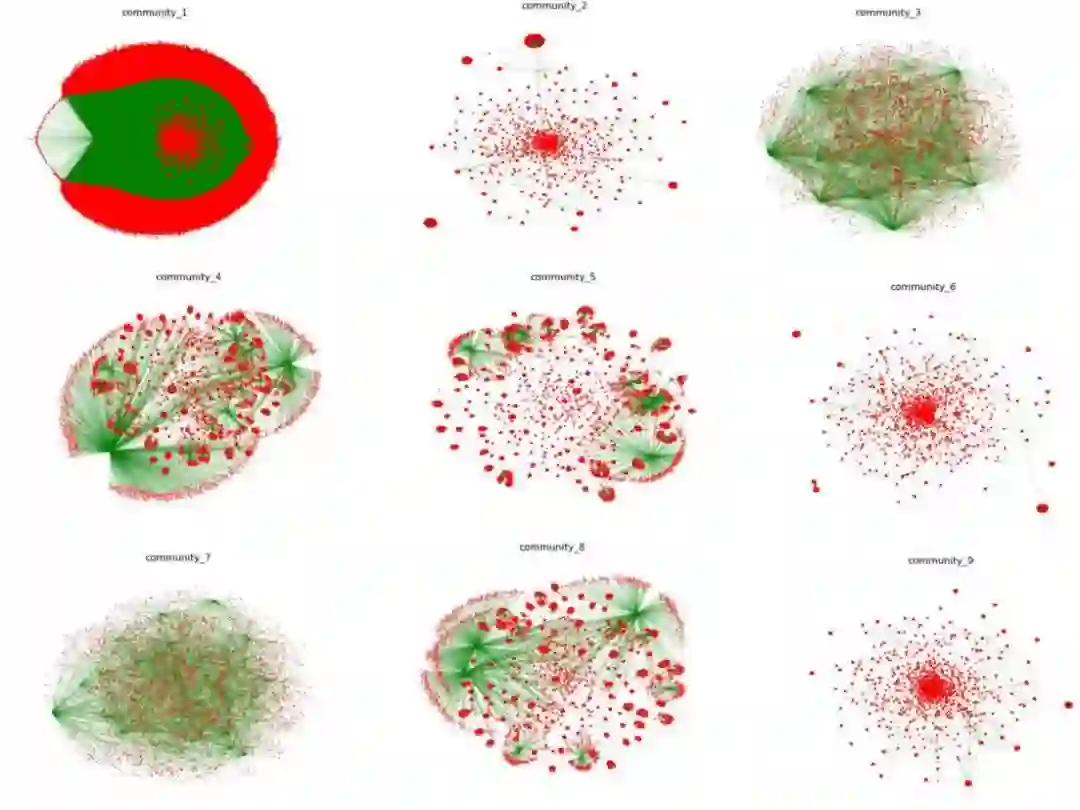
图6 ForceAtlas2算法对部分社区进行可视化的结果
在图6中社区以不同的结构形态聚集在一起,有些社区存在多个核心,比如community_4,community_5,community_8,这些社区所包含的领域中的论文可谓是“百花齐放”;有些社区只存在一个核心,比如说community_1,这些社区中核心论文可谓是“一枝独秀”。
子图的拼合
当我们得到Nature杂志引用关系数据的等效结构与每个社区在ForceAtlas2算法下的布局后,我们现在就可以进行社区的拼合工作。
首先,由于我们得到的结构是一个相对真实结构等比例缩放的结构,他不一定能够较好地容纳各个社区。因此,我们需要对得到的等效结构进行等比例缩放,以适用每个社区的大小,并且避免每个社区之间有过多的重叠或者社区之间的距离过大的问题。对结构进行缩放非常简单,只需要将结构中的每个中心节点的坐标乘上一个缩放因子即可,即:
由于拼合完成的图结构最终还需要进行微调,所以进行拼合时不需要将结构计算的非常精确,因此我们只需要手动调节参数λ到图结构合适即可。
当完成图结构大小的调节后,我们需要进行图的拼接。图的拼接同样很简单,假设等效结构中某社区的中心节点为,该社区的各个节点的坐标为
,则该社区中每个节点在大图中的位置为:
合并图的微调
在前面的操作当中,我们通过对社区进行分别布局,进而得到了Nature杂志论文引用关系数据布局的局部最优解,但通过上述的拼合方式得到的布局并不是全局的最优解,因此我们需要使用微调的方式来消除上述拼合过程中产生的误差。
为了保留数据的完整性,我们需要将先前忽略的数据补全。当完成数据补全后,我们可以开始图的微调工作了。微调完成后,我们已经得到所有节点的位置信息。到此时,节点布局的基本工作已经完成,这时我们需要将节点信息通过Gephi渲染,图7为Gephi最终渲染的结果:
图7 Nature杂志论文引用关系数据可视化结果(2053310个节点,3426847条边)

图8 图例
由图7可见,Nature杂志论文引用关系数据存在较强的结构性。图中最外层一圈细细的圆环是数据集中度为0的点,他们没有引力的作用,因此呈现在图的最外层;图中产生了超级大的红色节点,该点属于生物学领域,论文名称为“Cleavage of Structural Proteins during the Assembly of the Head of Bacteriophage T4”,据不完全统计,这篇文章已经达到了118282的引用量,引用数已经到达数据总量的1/20,达到了生物学领域数据量的1/10,可见这篇文章的影响力之大。图7能够显示出较好的聚类效果,红色区域表示生物学领域,生物学领域的文章的数量占据了Nature杂志一半还要多,在图中能够有较好的体现;然后物理学与机械领域分别占据了11.17%和9.11%;这些领域之间存在相互交叠的,交叠表示两个领域之间存在学科交叉。
理想彼岸终到达——可视化结果的呈现
完成数据的可视化后,我们还进行了节点的重叠去除,图的分层加载,由于篇幅限制,在此不再赘述。一下为可视化结果不同放大级别的展示。
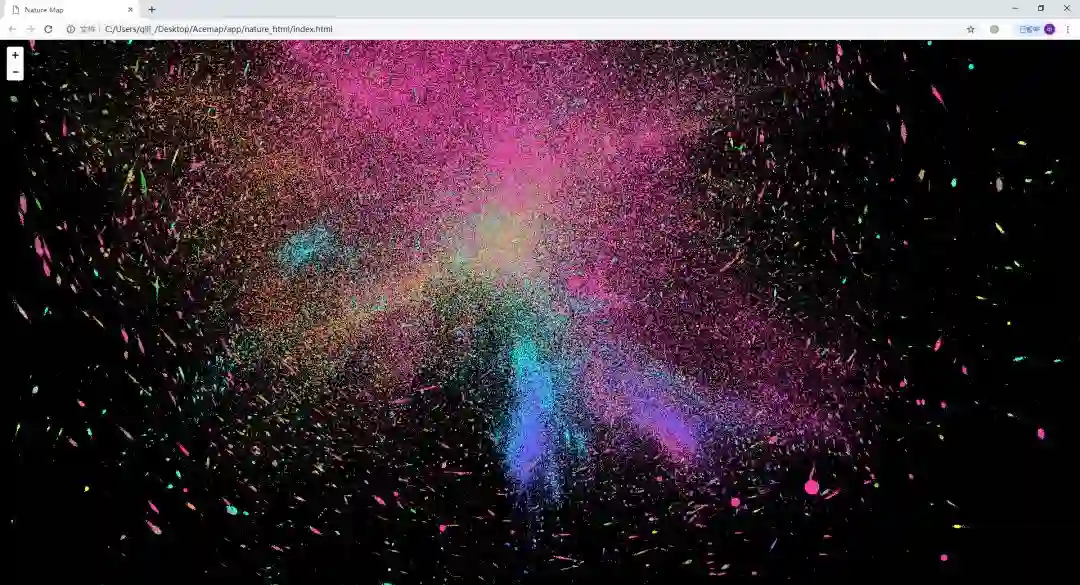
图9
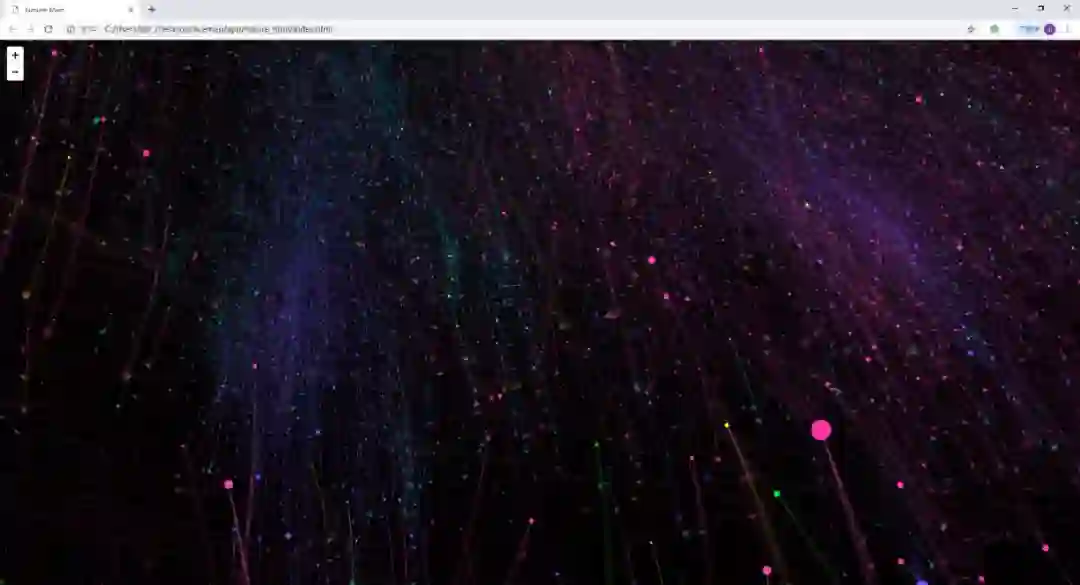
图10
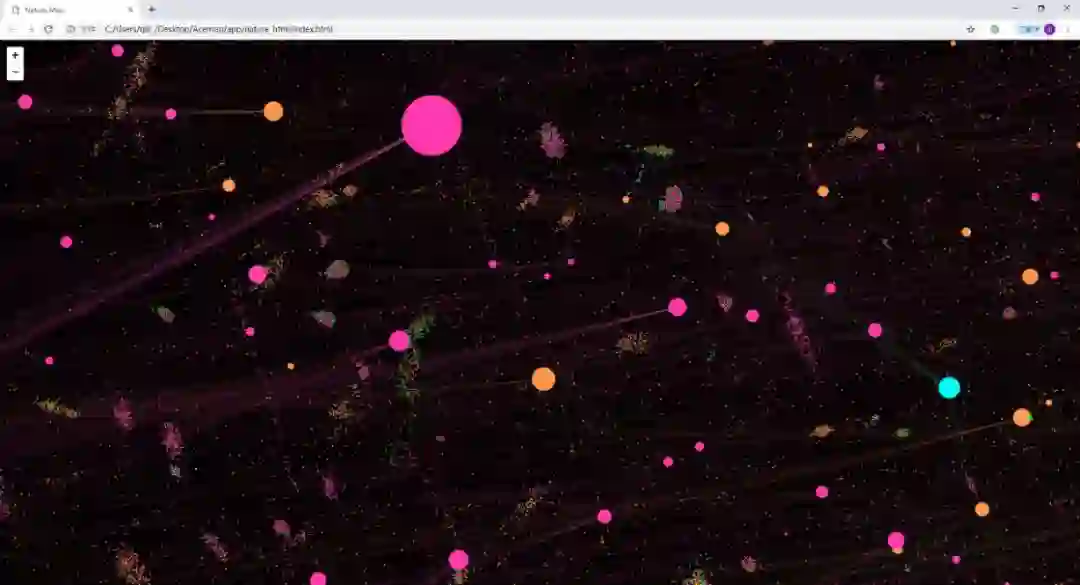
图11
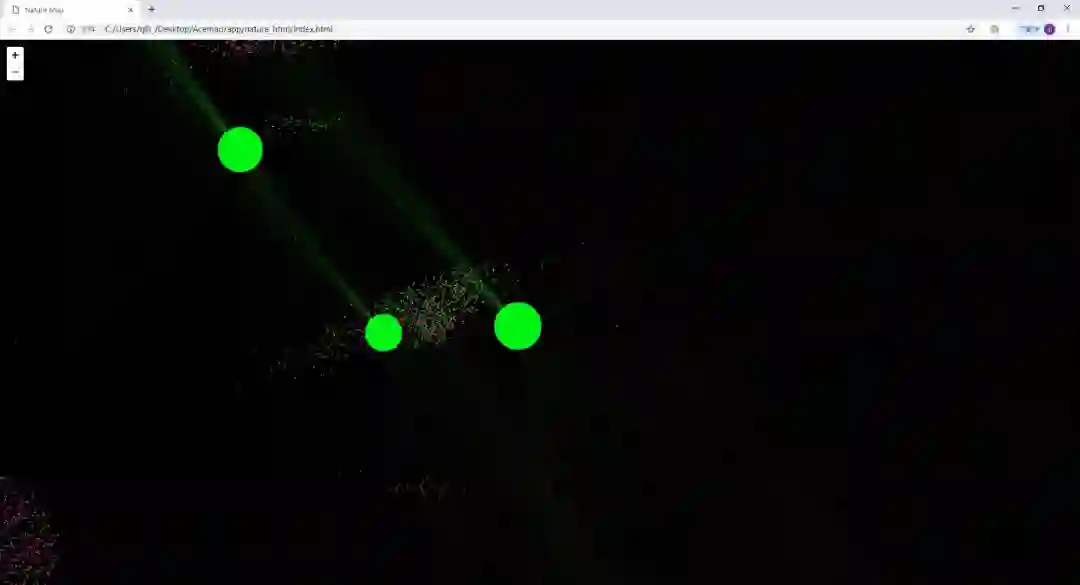
新纪元下的展望——分割绘图法的衍生应用
分割绘图法开创性地突破了网络大数据可视化百万量级的屏障,为超大规模作图带来了新鲜血液。该方法可将大部分学术网络一次性画出,从而有望揭示整个学术领域的全貌,以及世界范围内的精准学术定位,并对世界范围内的学术地图绘制提供重要思路。分割绘图法除了在超大规模学术网络可视化中发挥巨大作用外,该方法同样可以扩展到其他具有结构性的超大规模网络,例如大规模社交网络。
超大规模数据可视化领域仍有许多屏障需要我们去突破,这正是吾辈需要努力之处。总之,革命尚未成功,同志仍需努力!
本文经授权转载自微信公众号“爱思美谱”,ID:acemap_
新智元春季招聘开启,一起弄潮 AI 之巅!
岗位详情请戳:
.png")
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。



