个性化和情绪集成的注意力音乐推荐系统

论文:PEIA: Personality and Emotion Integrated Attentive Model for Music Recommendation on Social Media Platforms
地址:https://hcsi.cs.tsinghua.edu.cn/Paper/Paper20/AAAI20-SHENTIANCHENG.pdf
0.摘要
针对音乐推荐和社交媒体推荐设计的模型(PEIA),该模型利用用户长期行为(个性化)和短期行为(情绪)。它充分利用了面向个性的用户特征,面向情感的用户特征以及多面属性的音乐特征。提取用户表示时使用分层注意力机制。NDCG达到了0.5369。
1.问题
(1)由于社交媒体数据非常复杂,如何有效捕获有用信息以进行深入的用户建模?(2)由于问题涉及多方面的特征,如何对所有这些特征进行用户-音乐相关性建模,以及如何自适应地区分最重要的因素?
然后,作者深入研究了特征贡献,并探讨了用户特征与音乐偏好之间的相关性。进一步提出了一种人格和情感综合注意力模型(PEIA)来分别应对挑战。(1)除了简单的ID外,作者还通过提取个性化和情感化特征,涉及人口统计,文本和社会行为属性来全面分析每个用户。对于每个音乐曲目,还考虑其声学特征,元数据,歌词和情感。(2)我们采用深层次的框架来整合所有功能,并采用分层注意力来评估不同功能交互的重要性,以及用户长期口味(个性)和短期权重的权重偏好(情感)。
2.数据
采集2017.10到2018.4的171,254个用户和35,993首歌曲,共18,508,966次交互。(1)用户同一天听同一首歌多次只算一次。(2)每个用户至少10次记录。(3)每首歌至少有10个用户听过。
针对这些用户,还收集了相应的46,575,922条推文,120,322,771个社交互动,96,451,009条文章阅读记录等,以进行深入的用户建模。关于隐私问题,腾讯对数据进行匿名化和匿名化处理,无法找到特定的用户。
2.1用户个性特征:
使用提取的指标来获得面向个性的多维特征,以进行深度模型学习。
2.1.1受众特征
提取每个用户的性别,年龄和地理位置。由于在微信中实名认证是强制性的,因此此类人口统计特征相对可靠。
2.1.2文本特征
微信用户经常在Moments中发布推文,他们在此直接用附带的文本表达自己。使用结巴中文文本分割处理文本内容,并作为长期表示,使用Gensim提取100维Doc2Vec特征。
2.1.3社会行为特征
社交互动是微信中的一个核心问题,其中支持各种社交行为。提取联系人数量,推文数量和社交互动(例如评论和喜欢)的频率,以评估用户的社交参与度。由于隐私问题,未收集详细的社交关系和互动内容。还对发布的时间分布进行了研究,以反映日程安排。
2.1.4文章阅读特征
文章阅读行为是用户个人兴趣的重要指标,我们定义了23个主题(例如体育,互联网,美容和时尚),使用FastText训练文本分类器以计算文章主题,计算每个用户在23个主题维度中的阅读频率。
2.2情感用户特征
为了平衡情绪的及时性和数据的充分性,时间窗口设置为24小时。
2.2.1时间特征
分别以(早上,下午,晚上和午夜)和一周(工作日和周末)来对用户与音乐的交互进行统计。
2.2.2情绪向量
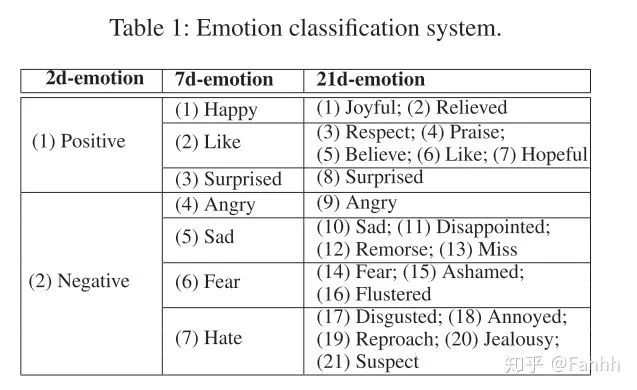
使用DUTIR中文情绪识别工具,针对用户推文的文本提取2维,7维和21维的向量拼接到一起组成30维用户情感向量。(2,7,21为DUTIR给定的维度),如果在对应时间窗口内没有推文(占17.8%)则使用整体情绪向量平均来填充。
2.3音乐特征
虽然每个音乐有其独特的id,但是这样表示太过模糊,因此用过分析声学特征,元数据,歌词和情感等全面分析某个曲目。
2.3.1 Metadata
该特征十分重要,对于每个音乐曲目,都会考虑其作者,流派,语言和发行年份。仅出现在一个曲目中的作者被合并为“其他”作者,并且最终涉及3721个独特的作者。
2.3.2 声学特征
在这项工作中,使用openSMILE,这是一种开源多媒体特征提取器,用于提取“ emobase”的988维声学特征集。具体来说,提取低级描述符(LLD,例如强度,响度,MFCC,音高),计算增量系数并应用几个函数(例如范围,均值,偏度,峰度)。
2.3.3 歌词特征
通过分析歌词来研究音乐曲目的语义信息。使用百度翻译器将所有歌词翻译成中文,使用jieba进行文本分割,并使用Gensim提取100维Doc2Vec特征。
2.3.4 情绪特征
使用与用户情绪特征相同的做法获取30维向量,对于缺失值训练线性回归模型获取缺失值向量。
3.模型
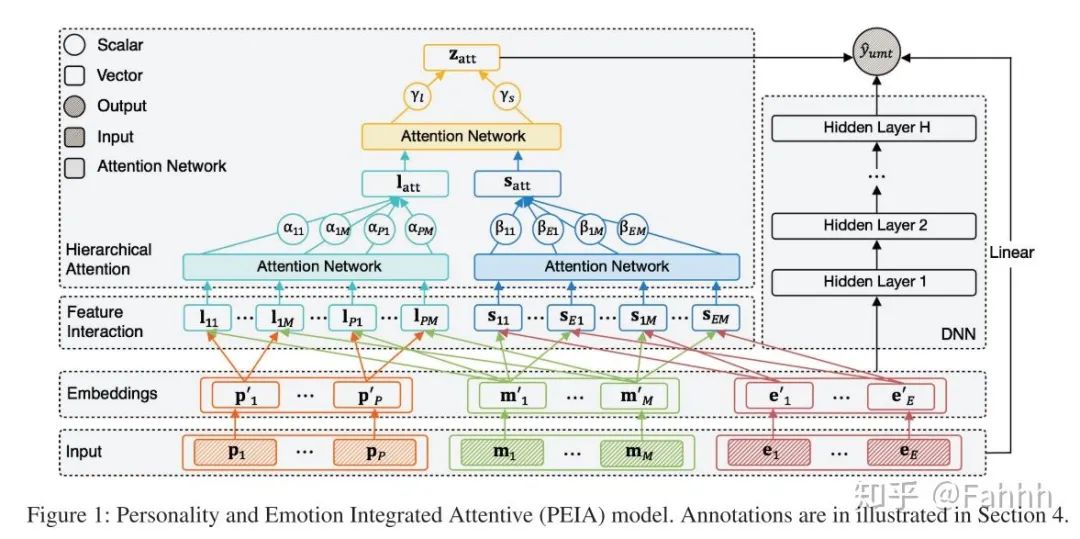
3.1 分层注意力特征提取
特征组包括P.E.M三个领域(个性特征,情绪特征,音乐特征)。每个领域特征包括ID类和Dense类特征:
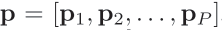
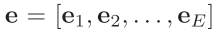
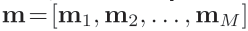
先将其映射到d-维。
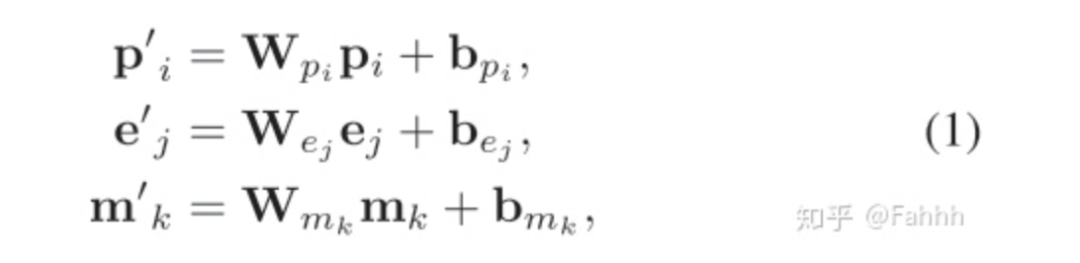
每个组之间的特征交叉使用hadamard积:
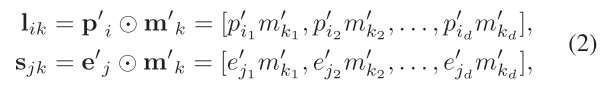
其中第一行是长期偏好,第二行是短期偏好。
注意力机制进行加权求和:

举个例子:
Pi = [a,b,c] Mk = [x,y,z]
Lik = [ax,by,cz]
对于L,S这两个矩阵,算注意力机制做weight sum。获得到长短期Latt和Satt的向量表示。再对Latt和Satt算weight sum得到Zatt
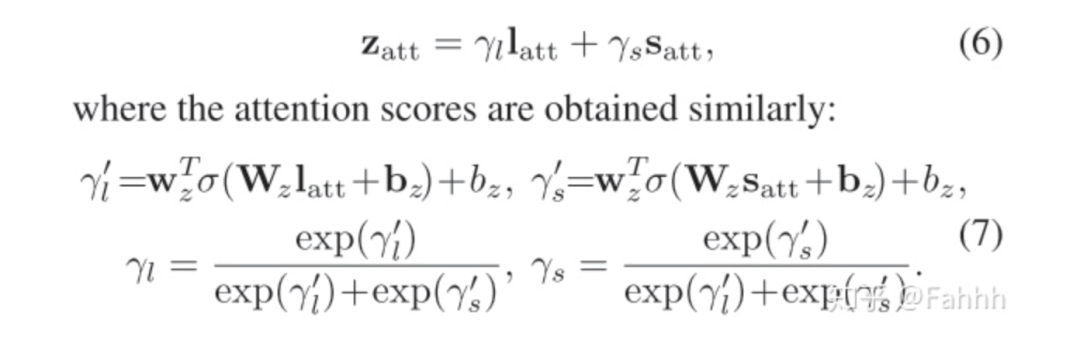
3.2 高阶交叉(深度模型)
将p`,e`,m`,拼接入DNN:
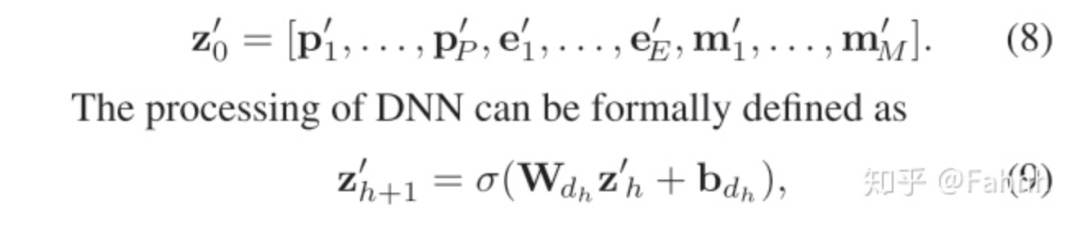
最终结果加上了LR输入,Zatt和DNN输出:

损失函数:交叉熵加L2正则。对于每个正样本,随机选取用户没听过的音乐作为负样本,训练时每个epoch正样本对应的负样本都不同。
4.实验结果
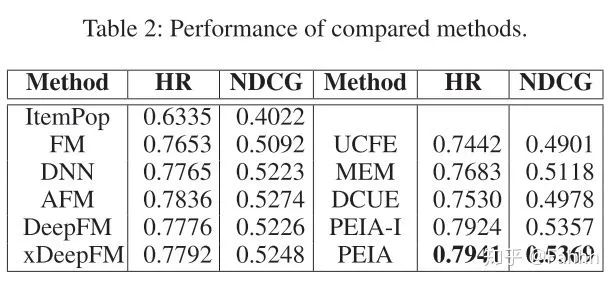
4.1对比实验
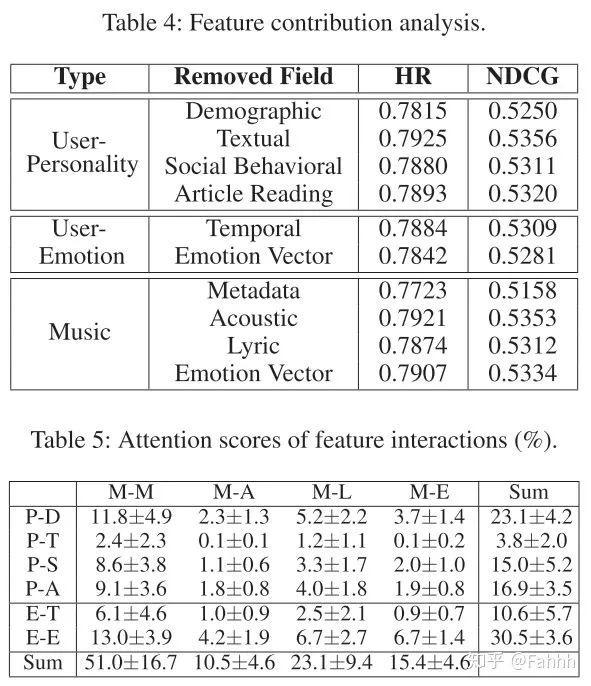
4.2分析特征重要性与注意力机制
4.3从统计角度和个人角度探讨用户特征与音乐偏好之间的相关性。
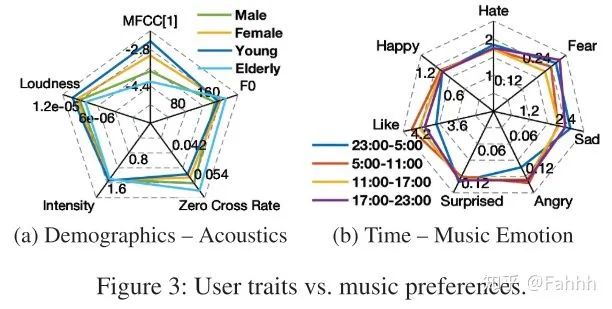
可以得出结论,与年轻人相比,老年人更喜欢高音调和有节奏的音轨,这些音轨的F0值较高且交叉率为零。性别差异在其他声学特征中没有预期的那么重要。