如何使用 SQL Server FILESTREAM 存储非结构化数据?


在本文中,我将解释如何使用SQL Server FILESTREAM来存储非结构化数据。同时,还会介绍FILESTREAM的优缺点。
在SQL Server的早期版本中,非结构化数据的存储在维持结构化和非结构化数据间一致性、管理备份/还原过程、性能问题、可扩展性等方面提出了许多挑战。在SQL Server 2008之前的MSSQL早期版本中,存在各种用于存储非结构化数据的机制。这些信息通常被以文件的形式存储在共享文件夹中,其访问权限被授予了某些用户。
这些文件的UNC路径通常作为表(varchar (n))中的一列存储于数据库中,以便应用程序逻辑可以访问特定的文件。但文件的安全性、管理其访问权并对其进行维护方面存在一定问题。
后来的二进制大对象(Binary Large Objects,BLOB)概念在一定程度上有助于存储非结构化数据。这个概念的主要优点是数据库中的集成管理和事务一致性。在这种情况下,安全问题(以前的文件解决方案)得到了解决。但仍存在一些问题,即2GB的限制以及日志文件过载。
二进制数据作为单独的文件存储在数据库之外。
可以通过WIN32 API对这些单独的文件进行操作。
T-SQL语句适用。
通过FILESTREAM存储在文件系统中的对象已经取消了VARBINARY (MAX)列的2GB文件大小限制。
FILESTREAM还可以被用在压缩文件、磁盘、卷中。
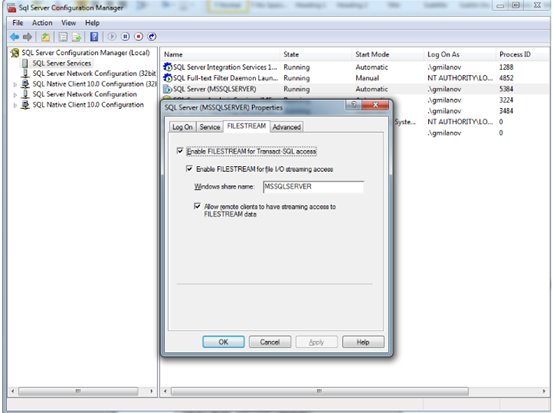 图1. 使用SQL Server 配置管理器在SQL Server级别启用FILESTREAM
图1. 使用SQL Server 配置管理器在SQL Server级别启用FILESTREAM
启用FILESTREAM的第二个级别是SQL Server Instance(实例)级别。通过执行脚本1中提供的T-SQL脚本来实现。
EXEC sp_configure filestream_access_level, 2
RECONFIGURE

表 1 列出了filestream_access_level的可能值。
值 |
描述 |
0 |
禁用FILESTREAM 对此实例的支持. |
1 |
启用FILESTREAM 进行Transact-SQL 访问. |
2 |
启用FILESTREAM 进行Transact-SQL 和Win32 流访问. |
表1. filestream_access_level的可能值
下一步是创建一个数据库,可以在其中创建将使用FILESTREAM的表。脚本2给出了一个T-SQL脚本示例,该脚本能够创建可以使用FILESTREAM的数据库。
CREATE DATABASE Test_FILESTREAM
ON
PRIMARY(
NAME=Test_FILESTREAM_Prmary,
FILENAME='d:\sqlbaza2019\mssql\data\FILESTREAM\Test_FILESTREAM.mdf'),
FILEGROUP FileStreamGroup CONTAINS FILESTREAM(
NAME=Test_FILESTREAM_FM,
FILENAME='d:\sqlbaza2019\mssql\data\FILESTREAM\Test_FILESTREAM_FM')
LOG ON (
NAME=Test_FILESTREAM_Log,
FILENAME='d:\sqlbaza2019\mssql\data\FILESTREAM\Test_FILESTREAM.log')

下一步要创建一个具有列VARBINARY (MAX)和FILESTREAM属性(脚本3)的表。
USE Test_FILESTREAM
CREATE TABLE [dbo].[Fajlovi]
(
ID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL PRIMARY KEY,
Fajl VARBINARY(MAX) FILESTREAM DEFAULT NULL
)

脚本3. 使用VARBINARY (MAX) FILESTREAM 列创建表
仍然需要将记录插入到新创建的表中(脚本4)。
INSERT INTO Fajlovi
VALUES (newid(), cast('My test FIESTREAM-a' as varbinary(max)))

用脚本4插入记录还将在文件系统上创建一个新文件夹。
可以通过执行脚本5从具有VARBINARY (MAX) FILESTREAM列的表中获取记录。
select * from [Test_FILESTREAM].[dbo].[Fajlovi]

脚本5. 使用VARBINARY (MAX) FILESTREAM 列从表中查看记录
执行脚本5的结果如图2所示。

图2. 具有VARBINARY (MAX) FILESTREAM列的表中的纪录
FILESTREAM列中的每个单元格都是一个与其关联的文件系统上的文件路径。要想读取路径的话,需要在T-SQL语句中使用varbinary (max)列的PathName属性。脚本6提供了如何读取varbinary (max)列文件路径的示例。
DECLARE @filePath varchar(max)
SELECT @filePath = Fajl.PathName()
FROM dbo.Fajlovi
WHERE ID = 'F9A149D0-F5F0-4FC5-9F59-1D27E4D10C1D'
PRINT @filepath

可以使用T-SQL处理FILESTREAM数据,但这是一个更自然的MS Visual Studio环境。通过System.Data.SqlTypes.SqlFileStream 类,可以在应用程序逻辑中使用FILESTREAM功能。为了保持数据的一致性,每个SQL FILESTREAM操作都必须是事务的一部分。MARS(多个活动结果集Multiple Active Result Sets)连接具有批处理事务的特殊规则,而T-SQL BEGIN TRANSACTION语句违反了这些规则。为了避免这个问题,应用程序客户端应该使用合适的事务管理API来表示类System.Data.SqlClient.SqlTransaction。
为了允许事务访问FILESTREAM数据文件系统,需要使用T-SQL函数GET FILESTREAM TRASACTION CONTEXT()来提供表示特定会话(C # code 1)中当前事务的令牌。
SqlConnection sqlConnection = new SqlConnection(
"Integrated Security=true;server=(local)");
SqlCommand sqlCommand = new SqlCommand();
sqlCommand.Connection = sqlConnection;
SqlTransaction transaction = sqlConnection.BeginTransaction("mainTranaction");
sqlCommand.Transaction = transaction;
sqlCommand.CommandText =
"SELECT GET_FILESTREAM_TRANSACTION_CONTEXT()";
Object obj = sqlCommand.ExecuteScalar();
byte[] txContext = (byte[])obj;
C # code 1. 使用 GET_FILESTREAM_TRASACTION_CONTEXT () 函数
这样一来,事务已启动,但还没有提交或回滚。使用FILESTREAM数据的多个操作可以在一个事务中执行。在C # code 2中给出了使用Win32 API的数据输入代码的示例,其中sqlFileStream对象最初是基于System.Data.SqlType类创建的。
SqlFileStream sqlFileStream = new SqlFileStream(filePath, txContext, FileAccess.ReadWrite);
byte[] buffer = new byte[512];
int numBytes = 0;
//Write string, "FILESTREAM test data" in FILESTREAM.
string someData = "FILESTREAM test data";
Encoding unicode = Encoding.GetEncoding(0);
sqlFileStream.Write(unicode.GetBytes(someData.ToCharArray()),0,someData.Length);
C # code 2. 在FILESTREAM中输入数据的示例代码
C # code 3中给出了使用Win32 API读取FILESTREAM数据的示例代码。这里使用的是在c# code 1示例开始时创建的同一个sqlFileStream对象。
sqlFileStream.Seek(0L, SeekOrigin.Begin);
numBytes = sqlFileStream.Read(buffer, 0, buffer.Length);
string readData = unicode.GetString(buffer);
if (numBytes != 0)
Console.WriteLine(readData);
C # code 3. 读取FILESTREAM数据的示例代码
在完成FILESTREAM注册事务(C # code 1)并读取FILESTREAM数据(C # code 2)之后,sqlFileStream对象(在C # code 1示例的开头基于System.Data.SqlTypes.SqlFileStream类创建的)必须关闭并提交事务(C # code 4)。sqlCommand对象是在示例C # code1的开头创建的。
sqlFileStream.Close();
sqlCommand.Transaction.Commit();
C # code 4. 关闭sqlFileStream对象并提交事务
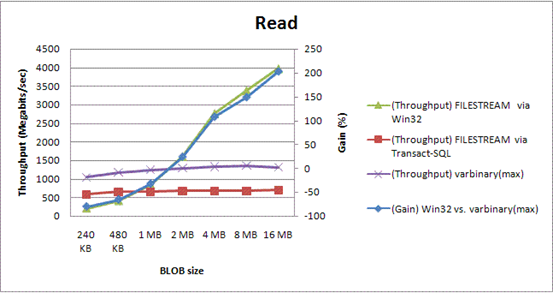
图3.不同大小的 BLOB的负载性能
还应该注意,FILESTREAM也被用于其他SQL Server技术中,例如FileTable和In-Memory OLTP。

最后
-
作为FILESTREAM的一部分创建的文件由SQL Server本身在其自己的文件组中进行管理,在这些文件组中可以与其他SQL Server数据一起进行备份和还原。 -
读写这些文件是数据库事务的一部分。 -
可以存储非常大的BLOB对象。
-
FILESTREAM数据只能被存储在本地磁盘卷中。 -
数据库快照中不支持。 -
数据库镜像不支持。 -
不支持透明数据加密。 -
不能与表值参数一起使用。
【End】

更多精彩推荐
☞50 岁程序员创业说:两个月提交 50 个 PR,三个月内融资 2000 万美元
☞平安科技王健宗:所有 AI 前沿技术,都可以在联邦学习中大展身手!
☞踢翻这碗狗粮:程序员花 7 个月敲出 eBay,只因女票喜欢糖果盒!
![]()
你点的每个“在看”,我都认真当成了喜欢