赛尔原创 | COLING 2018 基于目标依赖财经文档表示学习的累积超额收益预测
本⽂介绍哈尔滨⼯业⼤学社会计算与信息检索研究中⼼( SCIR)录⽤于COLING 2018的论⽂《 Learning Target-Specific Representations of Financial News Documents For Cumulative Abnormal Return Prediction》中的⼯作。本文提出了一种新的目标依赖的新闻文档表示模型。该模型使用目标敏感新闻摘要的表示来衡量新闻中句子的重要性,从而选择和组合最有意义的句子来进行建模。在累积超额收益上的预测结果表明,相比于摘要和标题,基于文档表示的方法更有效。同时,相对于句子级的方法,我们的模型能更好地组合来自多个文档源的信息。
论文作者:段俊文,张岳,丁效,Ching-Yun Chang,刘挺
1. 前言
研究表明,财经文本与股市波动存在相关性。自然语言处理(NLP)技术已被广泛应用于从公司文件、金融新闻文章和社会媒体文本中提取信息,以更好地理解金融市场的运行规律。早期基于统计的方法依赖于人工定义的特征来捕获词汇、情感和事件信息,这些信息容易受到特征稀疏性的影响。最近的工作已经考虑对新闻标题和摘要进行表示学习,通过模型自动习得对预测有用的特征。特别的,Ding et al. 表明,使用基于深度学习的事件表示方法相对于之前稀疏的事件表示的方法在预测效果上有很大的提升。
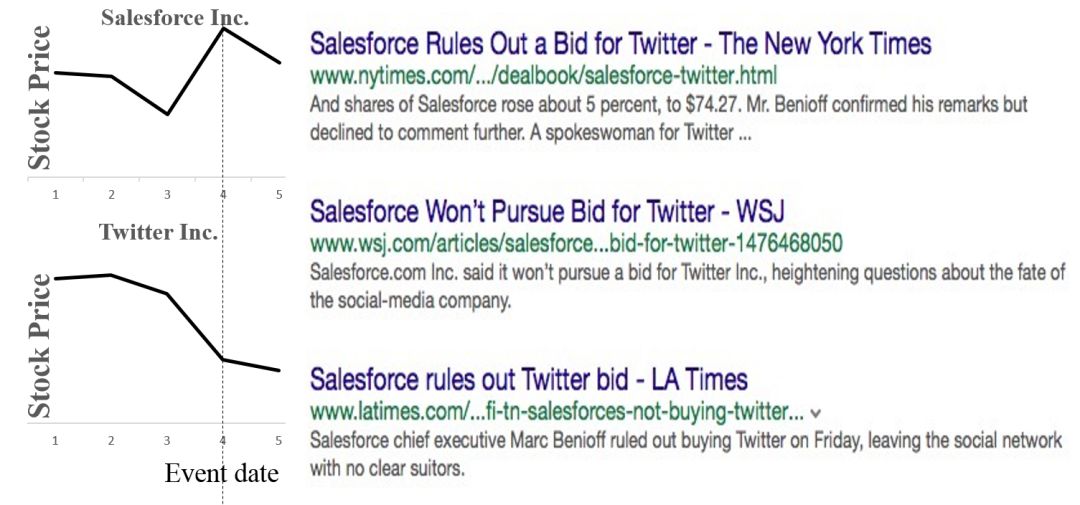
图1 相同的事件对于不同目标表现出不同的影响
然而前人工作的局限是,这些方法只对新闻标题或者摘要进行建模。新闻标题或摘要通常是单个句子,能够承载的信息有限,仅依靠标题或摘要往往很难作出准确的预测。例如针对新闻“Salesforce退出Twitter收购竞标”,仅仅通过阅读标题,我们很难理解为何Salesforce股票大涨而Twitter股票大跌。然而,在其正文中提到“Salesforce收购Twitter将同时接管Twitter的所有问题”。与新闻标题相比,完整的文档可以包含更多的潜在有用的信息,但也比事件和句子的有着更多噪声和不相关信息,因此建模难度更大。另外一个问题是,同样的事件对于参与其中的公司有着不同的影响,如图1所示,Salesforce从此事件中受益,而Twitter公司受损失。因此,在进行新闻建模时,我们需要对不同的目标进行区分,以更好地了解新闻事件对其的影响。
为了对与公司相关的多篇新闻文档进行建模,我们提出了一种新的目标依赖的新闻文档表示模型。该模型使用目标依赖的新闻摘要的表示来衡量新闻中句子的重要性,从而选择和组合最有意义的句子来进行建模。在累积超额收益上的预测结果表明,相比于摘要和标题,基于文档表示的方法更有效。同时,相对于句子级的方法,我们的模型能更好地组合来自多个文档源的信息。
2. 问题定义
2.1累计超额收益
形式上,公司j在交易日t的超额收益ARjt是指其实际收益Rjt相对于期望收益R̂jt的差,即ARjt = Rjt - R̂jt,其中期望收益R̂jt可以通过市场指数近似。而累积超额收益(Cumulative Abnormal Return)则是将在一段时间窗口内的超额收益相加。本文中我们选取窗口(-1,0,1),表示为CAR3,其中0表示事件发生的日期。
2.2 累计超额收益预测
我们将累积超额收益预测当成一个二分类问题,目标是建模新闻对目标公司股票波动的影响。给定一个新闻文档D和相关公司f,我们为D学习到一个依赖于f的向量表示df,之后我们将df作为习得的隐含特征表示送入分类器中进行分类,最终获得累积超额收益为正、负的概率。
3. 模型
学习目标敏感的文档表示的挑战是双重的。一方面,我们必须将企业特定的信息融入文档表示,以便使它们在目标之间有所不同。另一方面,我们必须忽略噪声,识别最重要的的句子。为了实现这个目标,我们首先为摘要学习目标特定的表示,然后利用摘要来指导关键句子的选择。我们提出的方法的体系结构在图2中示出,它由三个关键模块组成。在本节中,我们给出每个模块的详细信息。
3.1 目标依赖的摘要表示
作为第一步,我们通过将目标信息编码成新闻文档来提取目标相关的表示。我们使用双向长短记忆网络作为基本模型。为了允许目标公司的信息影响语义表示,我们使用条件编码(Conditional Encoding),使用关注对象et(c)的嵌入向量作为句子级双向LSTM的初始状态向量。我们对句子中每个词的隐藏状态进行平均,以获得目标相关的新闻摘要表示va。
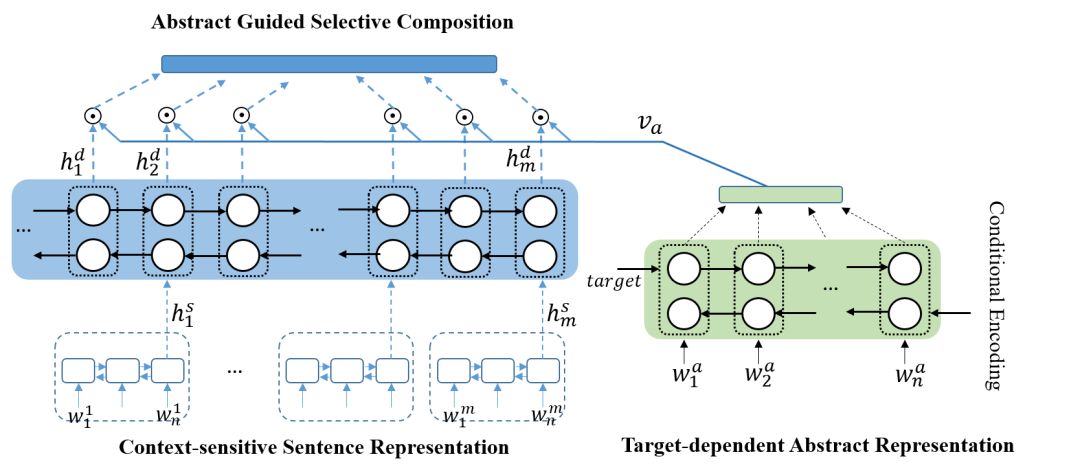
图2 本文提出的模型
3.2 上下文敏感的句子表示
为了保持文档的语义结构,并使句子的表示融合其上下文的信息,我们利用层次结构来编码文档中的句子。我们首先使用句子级LSTM将单词编码成固定维度的向量,然后将它们作为一个双向的LSTM的输入,对于每个句子si,前向和后向的隐含状态平均得到hdi,从而得到每个句子上下文敏感的表示。
3.3 摘要指导句子组合
前文中我们提到,一些句子可以提供支持决策的背景信息,但由于太冗长而不能包含在摘要中。为了解决重要句子选择的问题,我们使用目标依赖的摘要表示来指导句子的选择。这里我们使用注意机制也为正文中的句子赋权,使用注意机制的另一个好处是预测变得可解释。
给定目标依赖的摘要的表示va以及上下文敏感的句子表示{hd1, hd2, …, hdm}, 我们将va和hdi拼接,并送入公式1的神经网络中。通过公式2对句子的权重进行归一化处理,通过公式3对正文中的句子进行加权得到了文档的表示d。最终我们将va和d拼接作为文档的最终表示。
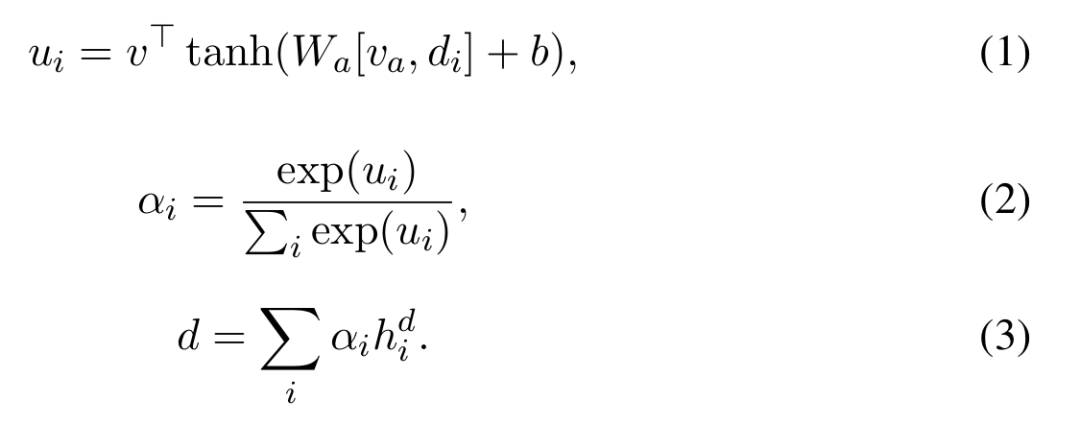
4. 实验
4.1 数据集
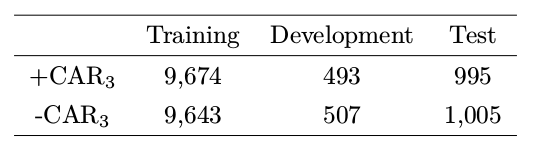
我们使用路透社2006年10月至2015年12月间的新闻文本,我们只保留在摘要中提及了具体公司的新闻。我们将数据集进一步划分为训练集,开发集和测试集。各个集合中的数据如表1所示。
表1 数据集中的正负例分布
4.2 评价指标
模型的性能由精确率-召回率曲线(AUC)下的面积来评价。准确度和召回率均在正类和负类上计算。该评价指标能够通过改变预测置信阈值时提供了精度和召回之间的平衡。跟随Chang et al. 的工作,我们还对具有|CAR3| > 2%的测试实例进行了评估,来确定模型在高超额收益股票上的表现。
4.3 实验结果
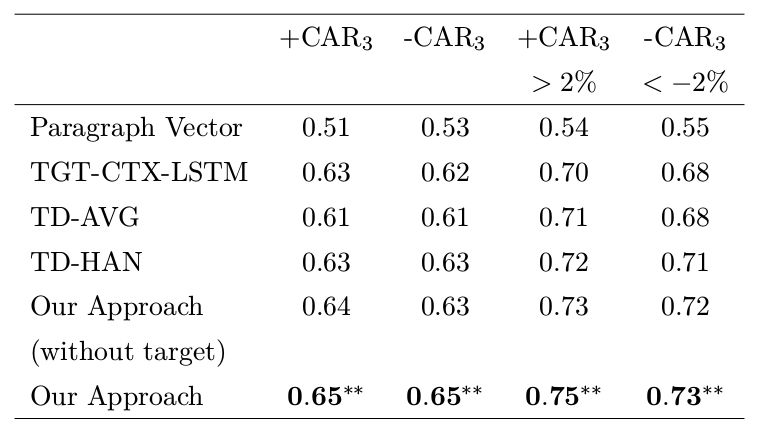
4.3.1 总体表现
表格2总结了不同模型在测试集合上的表现。我们的模型在测试数据集上正负类AUC均为0.65,超越所有的基线方法。跟随Chang et al.,我们还比较了在具有较高累积超额收益子集上的表现。我们的模型在正负类AUC分别为0.75和0.73。简单平均模式TD-AVG表现不及基于特定目标的摘要表示TGT-CTX-LSTM。这表明摘要在预测股票市场走势中的有效性。当我们将加权组合方法TD-HAN代替简单平均方法,模型取得了与TGT-CTX-LSTM相当的性能。这意味着,如果文档级别的背景信息能够得到有效建模,文档级模型能够超越基于标题或摘要的模型。
表2 在测试集上各个模型的表现
4.3.2 目标的影响
在表2中,我们还比较了有无目标信息的模型的性能。在没有目标信息时,我们的模型在正负类中AUC值分别达到0.64和0.63,这可以与最好的基线相媲美。将目标信息编码到文档表示中并没有给模型性能带来特别显著的改善。可能的原因是,我们的数据集中只有10.2%的新闻摘要提到一个以上的公司。
4.3.3 文档数量的影响
如前所述,在特定时间窗口中可能有多个与公司相关联的新闻文档。我们的数据集中超过25%的实例有多篇新闻。更多的新闻可以提供更丰富的背景信息,但也可能带来更多的噪声。图3(右)显示了我们的模型和基线方法TGT-CTX-LSTM相对于新闻文档数量的准确性。值得注意的是,我们的模型和TGT-CTX-LSTM使用相同的注意策略来组合来自多个文档的信息。随着文档的数量增加,我们的方法的性能提高,显示其能更好地利用非重叠信息源。我们的模型可以更好地捕获来自多个文档源的信息。
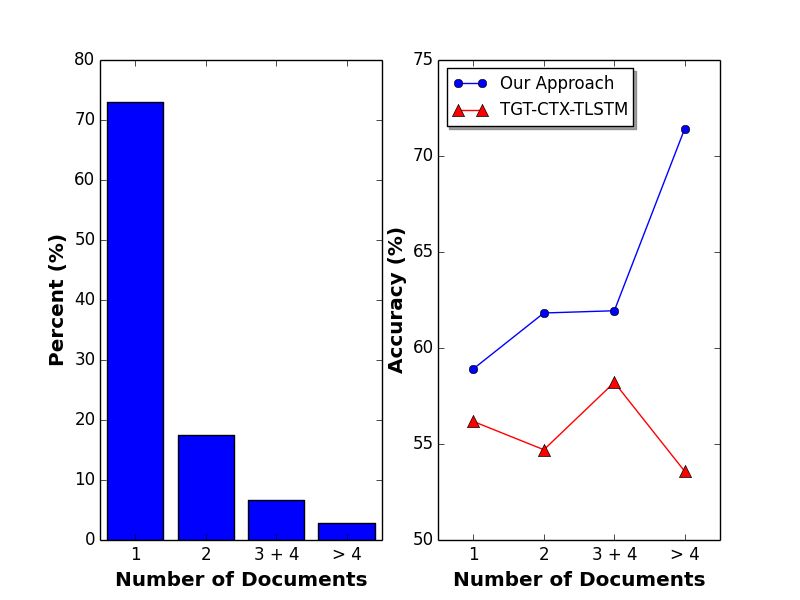
图3 新闻数量与预测准确率的关系
5. 结论
我们提出了一种新的目标依赖的新闻文档表示模型。该模型使用目标敏感新闻摘要的表示来衡量新闻中句子的重要性,从而选择和组合最有意义的句子来进行建模。在累积超额收益上的预测结果表明,相比于摘要和标题,基于文档表示的方法更有效。同时,相对于句子级的方法,我们的模型能更好地组合来自多个文档源的信息。
本期责任编辑:张伟男
本期编辑: 赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




