![]()
作者|小舟、蛋酱
来源|机器之心
GBDT 和 GNN 方法各有各的优势,现在,来自法国、俄罗斯两家机构的研究者将二者的优势结合起来,探索使用 GBDT 模型处理图结构数据。
![]()
论文地址:
https://openreview.net/pdf?id=ebS5NUfoMKL
图神经网络(GNN)已经在学习图结构方面取得了巨大成功,应用于分子设计、计算机视觉、组合优化、推荐系统等多个方面。该领域的进展依靠于规范的 GNN 架构的存在,该架构将原始输入数据有效地编码为表达型表征,从而在新的数据集和任务上获得高质量的结果。
最近的一些研究主要集中于具有稀疏数据的 GNN 上,这些数据代表同质节点嵌入(例如 one-hot 编码的图统计)或者词袋表征。但是在许多情况下,具有详细信息和丰富语义的表格数据更为自然,现实世界的人工智能也更丰富。例如在社交网络中,每个人都有社会人口统计学特征(例如年龄、性别、毕业日期),这些特征在数据类型、规模和缺失值上有很大差异。带有表格数据图形的 GNN 的研究是缺少的,梯度提升决策树(GBDT)在具有此类异构数据的应用程序中占主导地位。
GBDT 非常适用于表格数据,因为它们具有以下特性:
相反,GNN 的关键特征使它们同时考虑节点的邻域信息和节点特征来进行预测,这与 GBDT 不同,GBDT 需要额外的预处理分析才能为算法提供图摘要(例如通过无监督图嵌入)。此外,理论上已经证明,通过消息传递的 GNN 可以在其图输入上计算任何可由图灵机器计算的函数,即 GNN 是唯一在图上具有通用性的学习架构(近似化和可计算性)。
此外,与基于树的方法相比,基于梯度的神经网络学习具有多种优势:
GNN 中含有的关系归纳偏差减轻了手动设计捕获网络拓扑特征的需求;
训练神经网络的端到端属性允许在依赖于应用程序的解决方案中将 GNN 进行多阶段或多组件集成;
采用图网络的预训练表征丰富了迁移学习中的许多重要任务,例如无监督领域自适应、自监督学习和主动学习机制。
显然,GBDT 和 GNN 方法都有着明显的优势,可以将二者的优势结合起来吗?此前所有尝试将梯度提升和神经网络结合起来的方法在计算上都很繁琐,没有考虑图结构化数据,并且缺乏 GNN 架构中包含的关系偏向。
本研究是第一个探索使用 GBDT 模型处理图结构数据的研究。在这篇论文中,研究者提出了一种针对含表格数据的图的新型学习架构 BGNN,该架构将 GBDT 对表格节点特征的学习与 GNN 相结合,从而利用图的拓扑优化预测。这使 BGNN 可以继承梯度提升方法(异构学习和可解释性)和图网络(表征学习和端到端训练)的优势。
设计了一种新的通用体系架构,将 GBDT 和 GNN 组合为一个 pipeline;
通过迭代添加适合 GNN 梯度更新的新树,该研究克服了 GBDT 的端到端训练的挑战,使得错误信号可从网络拓扑反向传播到 GBDT;
研究者针对节点预测任务中的强基准对方法进行了广泛的评估,实验结果表明,在各种现实表格数据中,异构节点回归和节点分类任务的性能显著提高;
由于训练过程中的损失收敛速度更快,该方法比其他 GNN SOTA 模型更有效。此外,学习到的表征在潜在空间中展现出可辨别的结构,这进一步证明了该方法的表达能力。
GBDT 和 GNN 的优化遵循不同的方法:GNN 的参数通过梯度下降进行优化,而 GBDT 则是迭代构建的,并且决策树在构建之后仍然保持固定(决策树基于特征空间的硬拆分,因此不可微分)。
一种简单的方法是仅在节点特征上训练 GBDT 模型,然后将得到的 GBDT 预测与原始输入一起用作 GNN 的新节点特征。在这种情况下,将通过图神经网络进一步完善 GBDT 对图不敏感的预测。这种方法(被称为 Res-GNN)已经可以提高某些任务的 GNN 性能,但 GBDT 模型将完全忽略图的结构,并可能会丢失图的描述性特征,从而向 GNN 提供不准确的输入数据。
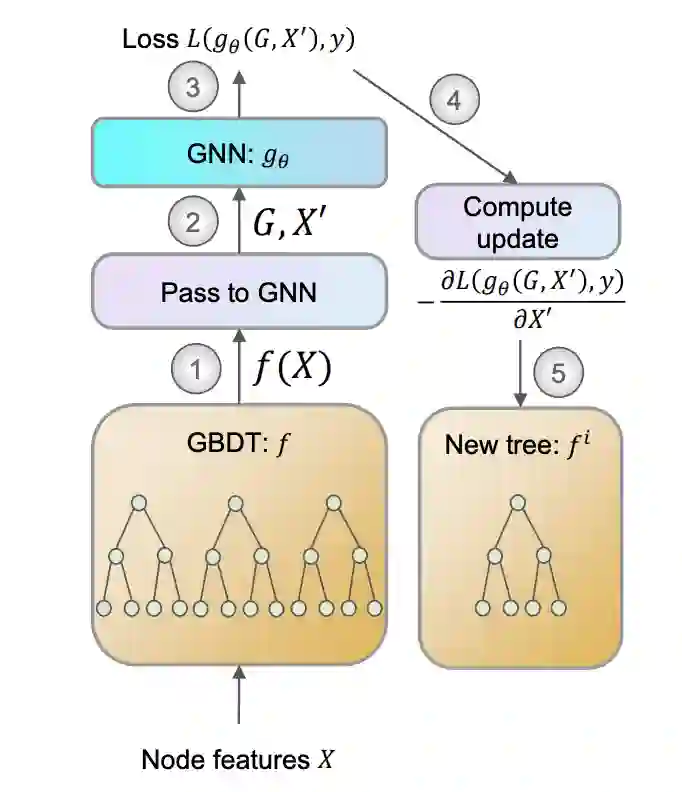
相反,该研究提出对 GBDT 和 GNN 进行端到端的训练,称为 BGNN(Boost-GNN)。该研究首先应用 GBDT,然后再应用 GNN。但考虑到最终预测的质量,该研究对它们进行了优化,BGNN 的训练如图 1 所示。已经构建好的决策树由于其离散的结构而无法正确调整,因此该研究通过添加新的树来迭代地更新 GBDT 模型,使其近似于 GNN 损失函数。
![]()
图 1:BGNN 的训练过程,计算每一个 epoch 的步数
下图算法 1 展示了 BGNN 模型的训练算法,它可用于半监督节点回归与分类这样的任意节点级别的预热问题。
![]()
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()