明略科技首席科学家吴信东教授等人曾在ICDM 2019上举办了首届 IEEE ICDM/ICBK 知识图谱大赛,奖金一万美金。
本文内容对这次比赛做了详细总结。亮点包括:
探讨知识图谱的现状与挑战;
阐明数据图谱和知识图谱的差异;
赋予知识图谱较为完备的学术定义;
挖掘构建知识图谱的关键技术;
阐述 5 个获奖团队各自的模型;
介绍常用的构建知识图谱的工具包。
在今年即将举办的 ICDM 2020 上,第二届比赛将继续进行,奖金只多不少。
作为国际顶级数据挖掘会议之一,ICDM与KDD并称“国际数据挖掘两大顶级会议 ”(WSD
M 的势头也很猛,但偏WS),如何
更进一步,ICDM创始人吴信东教授(IEEE & AAAS Fellow,现任明略科技首席科学家)任重而道远。ICDM最为业界所知名的是其Regular Paper录用率历年来一直保持极低水平(10% 左右)。以 ICDM 2019 (北京)为例,共收到来自56个国家共1046篇投稿,而仅录用了 95 篇(录用率为9.1%)。
在本次会议中,由明略科学院和合肥工业大学联合主办以及澳大利亚麦考瑞大学协办,成功举行了首届 IEEE ICDM/ICBK 知识图谱大赛。这是一场奖金 10000 美元的比赛。
在这次比赛中,参赛团队需在至少两个不同领域的非结构化文本中自动构建知识图谱(即在无人工干预的情况下,从特定领域或多个领域的非结构化文本中构建知识图谱),并开发一个应用程序将其可视化。
针对这次比赛的内容,本文详细分析了知识图谱构建的现状与挑战,搭配具体的例子给有兴趣的同学提供通俗易懂的理解方式。此外也探索了知识图谱构建中的关键技术,主要侧重在Entity Recognition,Relation Extraction,Co-reference Resolution。
据了解,今年 ICDM 将于2020年11月17-20日在意大利南部城镇索伦托举行,而IEEE ICDM 知识图谱竞赛也将同期举办,比赛奖金相比去年会只多不少。敬请期待!
探讨了知识图谱的现状与挑战;
阐明了数据图谱和知识图谱的差异;
-
-
-
-
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8970862
Sharon Lu, Wuhan University of Technology, China
知识图谱(knowledge graph)普遍应用于Web搜索[1], 推荐[2]和知识问答[3]等领域。目前, 大多数高质量的知识图谱项目是由志愿者通过众包构建,例如Wikidata[4]。如果能够自动构建知识图谱系统,将极大改善当前知识图谱构建较繁琐的现状,以便于在更多商业场景中对知识进行结构化处理和管理。根据文本信息构建知识图谱一直以来都是极具挑战性的问题[5]。
信息冗余(information redundancy);
信息重叠 (information overlapping)。
信息丢失源于不完整的输出图谱。信息冗余指在输入文本中不存在但在背景知识中存在的额外概念和关系。
举个栗子: “Bob hit the nail into the wall with a hammer.” 对应的一个完整的知识图谱表达需包含:
-
entities (实体): Bob, nail, wall and hammer
-
relations(关系): (Bob, hit, nail), (nail, into, wall), and (Bob, with, hammer)
举个栗子:“John had a new fast 4-wheel car, and the car became a slow one 2 years later.” 这里有实体“汽车”在两年内从“快车”变成了“慢车”。
2019年10月在国家会议中心举行了第九期“认知图谱与推理”的主题辩论活动,国家“千人计划”特聘专家吴信东对知识图谱的认识问题做出了纠正。“ 知识图谱就是概念的关系连接”,这个说法是错误的,节点之间以边相连,这只是图谱,大部分人说的其实是数据图谱,还没有到知识层面。现在大部分知识图谱还停留在数据图谱上,是对个人了解以后生成的个性化推荐,知识图谱也可能有,也可能还没有认知这一层。(来自“大数据文摘”)
知识图谱在维基百科中定义为一种知识库,可以通过收集多种来源的信息来优化搜索引擎的结果。当前,很多公司正在构建知识图谱以支持多任务和功能。然而,
现有的99%的“知识图谱”实际上是没有知识的数据图谱 (data graph)。
举个栗子:“Bob and I were high-school classmates, and I will invite him for a dinner to celebrate our 25th year class reunion in 2020” 如果在图中不能识别出“他”是谁并且不能提供任何关于他们高中毕业的时间信息,这个图便仅是数据图谱。
知识图谱 (knowledge graph) 是一种语义图谱 (semantic graph),用于描述物理世界中的概念及其关系,它包含三个基本组成部分:
举个栗子: 概念可以是实体(如“人”)、属性(如“年龄”)或事实(如“有四扇门的红色汽车”),用节点表示。
2、关系 (relations)。关系是两个节点之间带有语义标签的连接。
举个栗子:“是一个”、“有一个”或动作(如“成为”)。
3、与概念和关系相关的背景知识 (background knowledge about concepts and relations)。概念可以具有不同的名称。
举个栗子: Professor X. Wu和Dr. Xindong Wu,以及可能具有的多个属性,如身高和职业。关系可以具有不同的表现,如“从前有”、“现在一个人有”和“现在多个人有”。以词典或本体存在的背景知识可以在语义上连接不同的名称、属性和表现。
数据图谱没有关于节点或关系的背景知识,是仅仅具有点和连线的图。
知识图谱的两个基本结构是“实体-关系-实体”(entity-relation -entity)三元组和“实体-属性”(entity-attribute)对。
在这两种结构中,实体通过它们之间的关系连接在一起,从而形成图结构的知识库。所以,知识图谱是关系的一种有效表达方法,它用图的形式描绘现实世界。
例如,下图便是展示了宫崎骏作品 “考虑了相关背景知识” 的知识图谱。
图2. 宫崎骏作品知识图谱 [来源于明略科技HAO图谱系统]
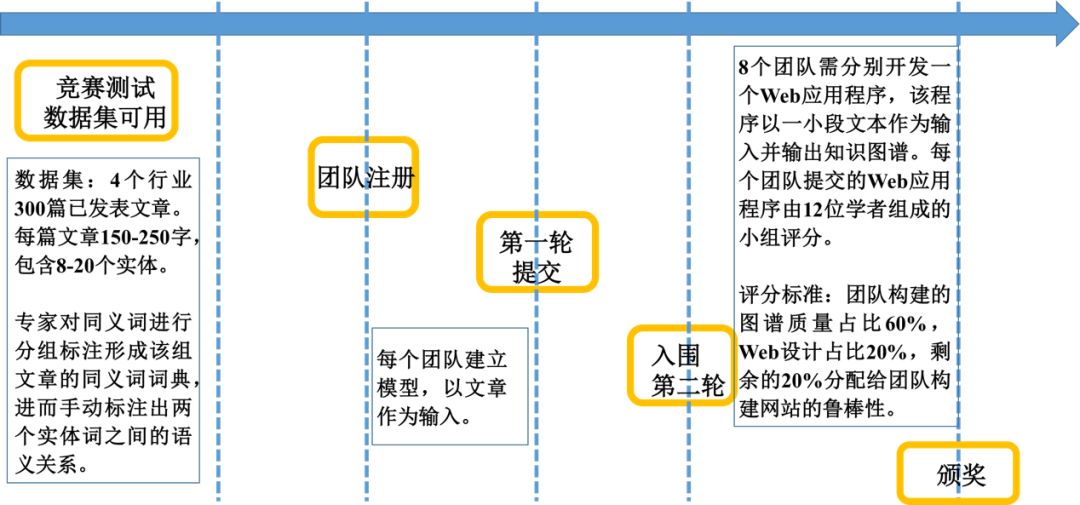
此次竞赛(首届 IEEE ICDM/ICBK 知识图谱竞赛)的目的是生成一种知识图谱,以模拟人类在阅读一段文字时的思维模式。
这里“人类”被假定为该段素材的人类阅读者。最终的比赛结果由专家评判。鉴于不同的专家不可避免地会关注文本的不同组成部分,其评判结果具有一定的主观性,为了确保竞赛结果的客观性,每一个竞赛作品均由两名专家进行评审。最终的入围名单由组委会在检查完每一个团队提交的所有打包材料之后决定。
每个参赛团队在竞赛组委会收集的同一个数据集上进行方法测试。该数据集包含300篇已经发表的新闻文章,这些文章分别涉及四个不同的行业:汽车工程、化妆品、公共安全和餐饮服务。每篇文章有150-250个字,包含8-20个实体。并且,每篇文章由该领域专家整体审核,确保了文章内容的多样性和深度并保证了每篇文章用词合理,使其既不会过于正式也不过于贫乏。来自上述四个领域的多位专家事先对300篇文章中的120篇进行人工标注。专家对同义词进行分组标注形成该组文章的同义词词典,进而手动标注出两个实体词之间的语义关系。
在线上评估阶段,首先,根据同义词词典,将提交的每个实体词替换为同义词集标签;然后,将每篇文章中提到的实体词标签与专家事先标注的标签进行对比。最后,每篇文章的容错标准由制定标签的行业专家确定。
每个团队需建立模型,以一篇文章作为输入并输出相应图谱。具体的规定如下:节点必须是文章中的实体词或短语;连接边必须是实体之间的关系词或短语;节点必须由原文中的单词或短语表示;合并单词的同义词。NLP相关会议在过去几年举行过类似的竞赛,这些竞赛是用开放文本构建知识图谱并事先给出了实体和/或关系的预定义架构,以便随后通过信息抽取模型提取信息。本次竞赛的新颖之处在于,没有预先为实体或关系设定任何类型的架构。
2、具体比赛流程及评分标准
在第一阶段,每个团队提交按行业划分的三元组,然后与专家标记的三元组进行比较 (数据集是300篇文章中的120篇)。每个团队的得分是通过计算所有行业得分的均值获得。具体而言,利用NetworkX[6]测算各个团队从文本中生成的图谱与两个行业专家标记的图谱之间的距离,距离越小的团队生成的图谱更接近实际。为了进一步增强比赛结果的客观性,各个团队提交文件中的实体词被行业专家标记的同义词词典中的单词替换。若提交内容与专家标记相同则获得“最高分”0,提交空文件的得分约为17.51。
在第二阶段,8个团队需分别开发一个Web应用程序,该程序以一小段文本作为输入并输出知识图谱。每个团队提交的Web应用程序由12位学者组成的小组评分。具体而言,根据评分标准,团队构建的图谱质量占比60%,Web设计占比20%,剩余的20%分配给团队构建网站的鲁棒性。
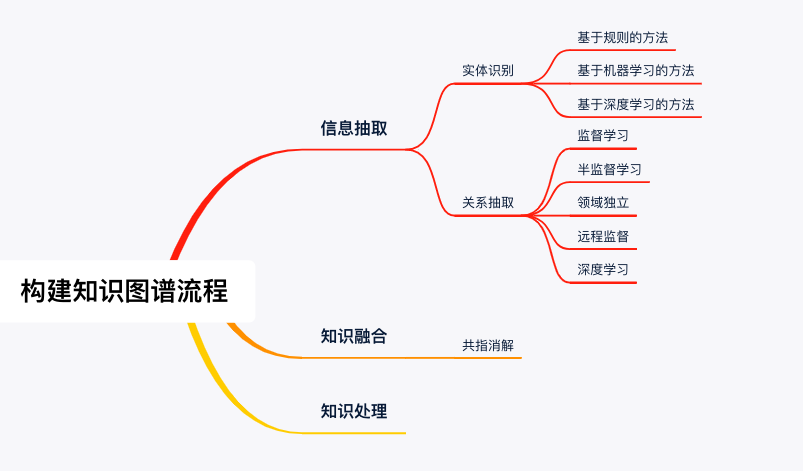
知识图谱构建的过程一般包含三个部分:信息抽取 (information extraction)、知识融合(knowledge fusion)和知识处理 (knowledge processing)。
本次竞赛只包括信息抽取和知识融合。信息抽取的目的是识别和分离数据源中的实体、实体的属性和实体间的关系。因此,信息抽取这一过程中并没有直接输出实际的“知识”。信息抽取涉及到的两项关键技术包括实体识别 (entity recognition)和关系抽取 (relation extraction)。此外,共指消解 (co-reference resolution) 会运用于知识融合中。
1、实体识别
实体抽取,又被称为命名实体识别 (Named Entity Recognition, NER),是指从数据 (尤指文本数据)中准确识别出命名实体的过程[7]。具体包含三个类别:实体类 (如人名、地名和机构名),时间类 (如日期和时间) 和数据类 (如货币和百分数)[8]。这些类别可以进行扩展以适应特定的应用领域。
NER技术已经从基于规则的方法 (rule-based method) 过渡到统计方法 (statistical approach),具体而言包含以下范例:
1)基于规则的方法:在早期的NER研究中,特别是在消息理解系列会议(Message Understanding Conference, MUC)中, 大多数主流的NER方法背后的基本思想是手动构建一组有限的规则,然后在文本中搜索与这些规则匹配的字符串。
2)基于机器学习的方法:基于机器学习的NER研究大致可以分为三个主题:模型和方法的选择,模型和方法的改进以及特征的选择。
3)基于深度学习的方法:深度学习技术在近年来已成为机器学习领域一个新的研究热点,与许多其他领域一样,深度学习技术已经成功的解决了一些NER问题。词向量表示 (word vector representation) 为解决NER序列化标记问题提供了支撑。Cherry 和Guo[9]提出了使用词向量表示特征的最简单且最高效的方法。Godin等[10]提出了带有NER的Twitter推文的分布式词表示。近期,Arora等[11]提出了一种神经-半马尔科夫结构支持向量机模型,该模型通过在训练过程中给loss-augmented inference 过程中不同类型的错误分配权重来保持精度和召回率之间的平衡。
Team UWA使用NLP工具SpaCy[12]对带有相同词性 (Part-Of-Speech, POS) 的标签以及根据预定义规则抽取的成块名词和动词短语进行分类。
名词块(noun chunk)被定义为描述名词的词。动词块 (verbal chunk) 是动词及其周围的介词和助词[13]。在可视化步骤中,名词组被分配到与被SpaCy识别出最相似实体相同的类别中,并且节点用颜色标记。
Team Tmail使用 Stanford OpenIE 工具包[14]、OpenIE 5.0[15]和SpaCy[12]提取命名实体并从OpenIE工具箱修改的数据中将这些实体改成原始词。
Team BUPT-IBL使用了自主开发的模型SC-LSTM[16],另外还使用了Stanford CoreNLP[14]和SpaCy[12]。
为了使用两个抽取模型以消除冗余实体,该团队设计了一个字符串匹配规则。
Team MIDAS-IIITD使用了NLTK[17]和SpaCy[12]进行预处理。
该团队也使用NLP工具包[18]将句子拆分为成块的短语并从中选择部分构建输出三元组。
Team Lab1105使用了SpaCy[12]。
另外,该团队在CoNLL 2003 NER数据集[19]中训练了BiLSTM + CRF模型,该模型包含四种类型的实体:人 (PER)、组织 (ORG)、位置 (LOC)和其他名称 (MISC)。
2、关系抽取
通过信息抽取获得图形中的实体 (节点) 后,下一步就是对构建连接边所需的关系进行抽取。
关系抽取与实体抽取方法类似,其早期主要工作都基于规则。基于规则方法的研究进展有限,但是自从将监督学习运用于关系抽取之后,该研究取得了较大进展。由于监督学习需要大量手工标记的样本,人工成本高,所以研究者们近期开发了半监督、无监督和自我监督的方法以减少对标签的需求。尽管这些方法已经在模型通用性方面取得了一些进展,但是自然语言非常复杂,关系抽取问题还远远没有被解决。下面是关系抽取的主要学习方法的概述[20]。
图6. 关系挖掘 (relationship extraction) 示例 [Source:网络]
1)监督学习 (supervised learning): 监督学习体现了对人类标注数据进行分类的思想。这些方法一旦经过训练就可以通过匹配和抽取特定关系进行识别实体。用于关系抽取的监督学习可以分为两大类:基于特征向量的方法 (feature vector-based methods) 和基于核的方法 (kernel-based methods)。
2)半监督学习 (semi-supervised learning): 大多数半监督学习与上述监督学习相比具有两个额外的步骤。首先是预设定一些关系类型。其次,将适当的实体对作为种子合并到训练集中。这些方法减轻了对大量标签的依赖。
3)领域独立 (domain-independent learning):领域独立放宽了对域规范的需求,这意味着这些方法易于扩展,可以应用于多个领域。一些研究人员已经合并了外部知识库,如Wikipedia,以补充各自的方法[21]。Bank[22]提出了公开信息抽取的框架和抽取模型TextRunner,并由Fader[23]和Schmitz[24]提高TextRunner的性能。这些方法假定每对实体具有已知关系,并使用上下文信息构造实体的特征表示。
4)远程监督 (distant-supervised methods):远程监督[25],[26]通过将非结构化文本与知识库匹配,从而自动生成大量的训练数据。Mintz等[27]尝试将远程监督纳入文本处理中,以通过语料和文本匹配来自动生成训练样本,从而提取特征训练分类器。Ji等[28]提出了句子级模型 (sentence-level model),该模型可以选择有效实例并充分利用知识库中的监督信息。
5)深度学习 (deep learning):深度学习在自然语言处理 (natural language processing, NLP)和图形识别方面已得到广泛应用,由此激发了研究者将此方法用于解决关系抽取问题。深度网络的架构有多种形式,如递归神经网络 (recurrent neural networks, RNNs)[29]、卷积神经网络(convolutional neural networks, CNNs)[30]、CNNs和RNNs组合[31],[32]以及长短期记忆 (long short-term memories, LSTMs)[33]。
Team UWA通过在句子中抽取诸如动词、介词和后置词之类的关系词,然后将每个关系短语与其左、右实体相结合以形成三元组,从而将实体映射成对。
图谱由每篇文章构建而成,用于查找分布在多个句子中的关系同时通过删除带有停用词 (stop words) 的实体来过滤三元组。该团队运用预先训练好的基于注意力 (attention-based) 的Bi-LSTM模型[33]显示关系名称,从而达到图形可视化的目的。
Team Tmail使用Stanford OpenIE工具包[14]和OpenIE[15]进行关系抽取。
由于该团队在命名实体识别和关系抽取中使用了多个模型,所以他们定义了一些手写规则以减少冗余的三元组数量,如删除实体短语中的停用词('an','the','it')、或使用SpaCy[12]定位名词块并合并具有相同名词块的实体。
Team BUPT-IBL主要使用Stanford OpenIE工具包[14]
,并基于语法树设计了一个模型来抽取更多的三元组,从而显著提高其模型的性能。
Team MIDAS-IIITD设计了手写规则
,以基于实体块的POS标签获得三元组。
Team Lab1105使用了SpaCy[12]
, 并设计了一系列基于主语、宾语、谓语和介词的手写规则以提取三元组。
3、共指消解
共指消解 (co-reference) 或实体解析 (entity resolution) 用于知识库中的一个实体链接到多个实体引用的情况中。例如,“President Trump”和“Donald John Trump”是同一个人,因此在这两个实体引用链接到知识库中的一个实体之前,应将其合并。
图7. 共指消解 (co-reference) 示例 [Source:网络]
实体解析的解决方案近年来大都基于最新的机器学习方法。McCarthy等[34],[35]将实体解析转换为分类问题,并使用决策树算法对其求解。Bilenko等[36-38]将实体解析转换为聚类问题,并训练分类器来识别重复对。术语相似度[39]和查询上下文相似度[40]能克服数据稀疏性并能在不同文本背景的实体之间建立关联。
本次竞赛的五个获胜团队中有四个 (UWA,BUPT-IBL,MIDAS-IIITD和Lab1105)使用NeuralCoref [41]进行实体解析。
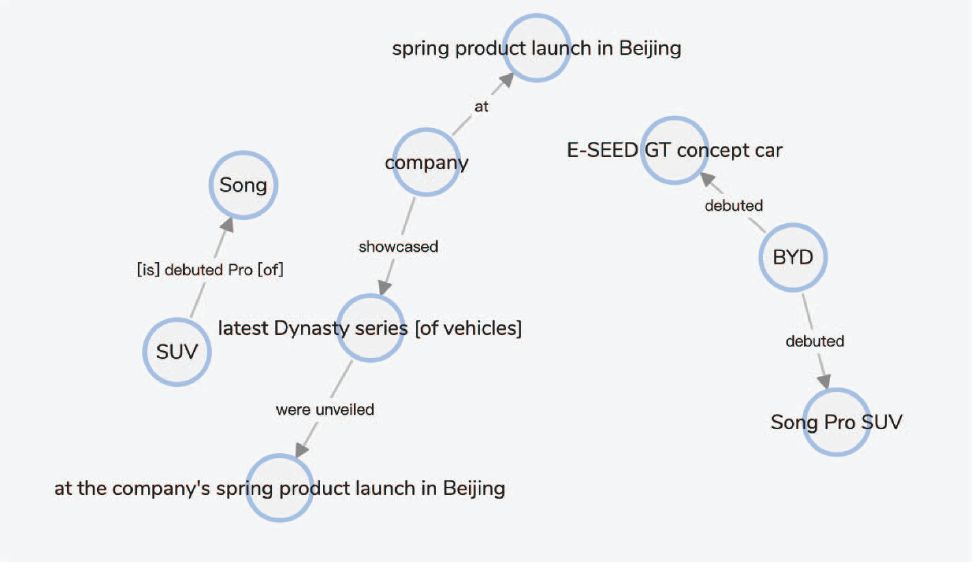
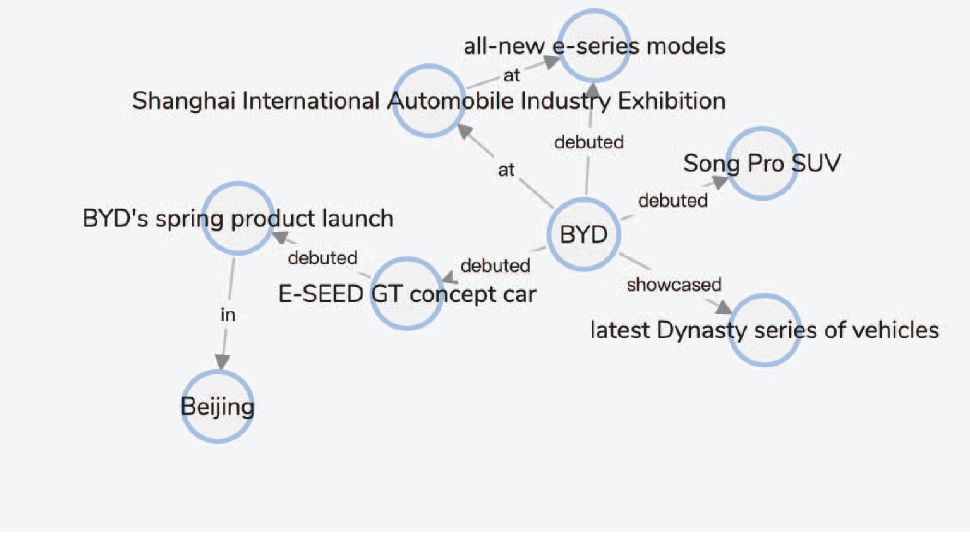
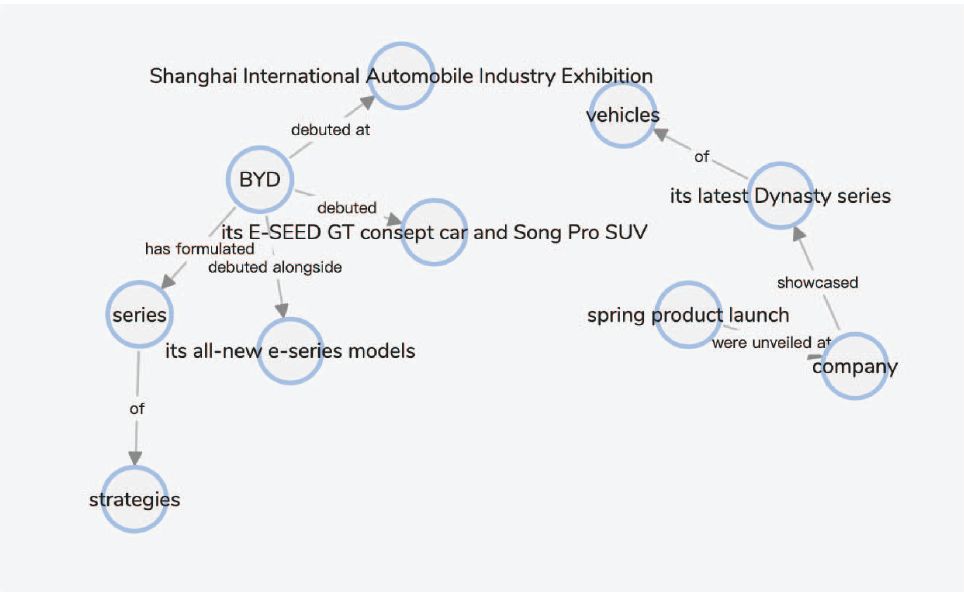
“BYD debuted its E-SEED GT concept car and Song Pro SUV alongside its all-new e-series models at the Shanghai International Automobile Industry Exhibition. The company also showcased its latest Dynasty series of vehicles, which were recently unveiled at the company’s spring product launch in Beijing.”
Team UWA 在其Web应用程序中对上述示例文本构建的知识图谱如下图所示。该团队的模型成功抽取了所有的实体和关系,并正确地将第二句中的第一个‘company’和第一句中的‘ BYD’识别为同一实体。但是它没有将第一个句子中的‘BYD’与第二句中的第二个‘company’链接为同一实体,这可能由两个短语之间的距离较大所致。
T
eam Tmail生成的图谱如下图所示。该团队已经成功识别大多数实体,并正确链接。然而,他们的模型中并未完全过滤重复的三元组(如,‘Song’和‘ Song Pro SUV’),也未识别出语义上属于同一实体的词组(如,‘ BYD’和‘company’)。
图9. Team Tmail 构建示例文本的知识图谱
Team BUPT-IBL的结果如下图所示。该团队识别出大多数实体,并在共指消解方面做得很好。但有些三元组的提取并未遵从原文的文意(如,E-SEED GT concept car, debuted, BYDs spring product launch)。
图10. Team BUPT-IBL 构建示例文本的知识图谱
Team MIDAS-IIITD产生的知识图谱如下图所示。该模型成功抽取了一些实体和关系,但未能将‘company’与‘BYD’关联起来。
图11. Team MIDAS-IIITD 构建示例文本的知识图谱
Team Lab1105生成的知识图谱如下图所示。该团队正确的抽取大多数实体并使其正确相互链接。然而,该团队在实体识别前后两次应用了共指消解,从而用实体术语代替了所有格代词,并为某些实体添加了多余的术语。此外,该团的模型也需得到进一步改进,以将‘BYD’ ‘the company’链接起来。
图12. Team Lab1105 构建示例文本的知识图谱
参考文献
[1] C. Xiong, R. Power, and J. Callan, “Explicit semantic ranking for academic search via knowledge graph embedding,” in Proc. WWW, 2017, pp. 1271–1279.
[2] Z. Sun, J. Yang, J. Zhang, A. Bozzon, L.-K. Huang, and C. Xu, “Recurrent knowledge graph embedding for effective recommendation,” in Proc. ACM RecSys, 2018, pp. 297–305.
[3] Y. Zhang, H. Dai, Z. Kozareva, A. J. Smola, and L. Song, “Variational reasoning for question answering with knowledge graph,” in Proc. AAAI, 2018.
[4] D. Vrandeˇci´c and M. Kr¨otzsch, “Wikidata: a free collaborative knowledge base,” Communications of the Acm, vol. 57, no. 10, pp. 78–85, 2014.
[5] Q. Liu, Y. Li, H. Duan, Y. Liu, and Z. Qin, “Knowledge graph construction techniques,” Journal of Computer Research and Development, vol. 53, no. 3, pp. 582–600, 2016.
[6] D. A. S. Aric A. Hagberg and P. J. Swart, “Exploring network structure, dynamics, and function using networkx,” in Proc. SciPy, 2008.
[7] D. Nadeau and S. Sekine, “A survey of named entity recognition and classification,” Lingvisticae Investigationes, vol. 30, no. 1, pp. 3–26, 2007.
[8] L. Liu and D. Wang, “A review on named entity recognition,” Journal of the China Society for Scientific and Technical Information, vol. 37, no. 3, p. 329, 2018.
[9] C. Cherry and H. Guo, “The unreasonable effectiveness of word representations for twitter named entity recognition,” in Proc. NAACL, 2015, pp. 735–745.
[10] F. Godin, B. Vandersmissen, W. De Neve, and R. Van de Walle, “Multimedia lab@ acl wnut ner shared task: Named entity recognition for twitter microposts using distributed word representations,” in Proc. EMNLP-WNUT, 2015, pp. 146–153.
[11] R. Arora, C. Tsai, K. Tsereteli, P. Kambadur, and Y. Yang, “A semimarkov structured support vector machine model for high-precision named entity recognition,” in Proc. ACL, 2019, pp. 5862–5866.
[12] M. Honnibal and I. Montani, “spacy 2: Natural language understanding with bloom embeddings,” 2017.
[13] M. Stewart, M. Enkhsaikhan, and W. Liu, “Icdm 2019 knowledge graph contest: Team uwa,” in Proc. ICDM, 2019.
[14] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, and D. McClosky, “The stanford corenlp natural language processing toolkit,” in Proc. ACL, 2014, pp. 55–60.
[15] S. Saha and M. Mausam, “Open information extraction from conjunctive sentences,” in Proc. COLING, 2018, pp. 2288–2299.
[16] P. Lu, T. Bai, and P. Langlais, “Sc-lstm: Learning task-specific representations in multi-task learning for sequence labeling,” in Proc. NAACL, 2019, pp. 2396–2406.
[17] S. Bird, E. Klein, and E. Loper, Natural language processing with Python: analyzing text with the natural language toolkit.” O’ReillyMedia, Inc.”, 2009.
[18] A. Akbik, D. Blythe, and R. Vollgraf, “Contextual string embeddings for sequence labeling,” in Proc. COLING, 2018, pp. 1638–1649.
[19] E. F. Tjong Kim Sang and F. De Meulder, “Introduction to the conll-2003 shared task: Language-independent named entity recognition,” in
Proc. CoNLL, 2003, pp. 142–147.
[20] D. Xie and Q. Chang, “Review of relation extraction,” Application Research of Computers, vol. 37, no. 7, pp. 1–5, 2019.
[21] F. Wu and D. S. Weld, “Open information extraction using wikipedia,” in Proc. ACL, 2010, pp. 118–127.
[22] M. Banko, M. J. Cafarella, S. Soderland, M. Broadhead, and O. Etzioni, “Open information extraction from the web,” in Proc. Ijcai, vol. 7, 2007, pp. 2670–2676.
[23] A. Fader, S. Soderland, and O. Etzioni, “Identifying relations for open information extraction,” in Proc. EMNLP, 2011, pp. 1535–1545.
[24] M. Schmitz, R. Bart, S. Soderland, O. Etzioni et al., “Open language learning for information extraction,” in Proc. EMNLP-CoNLL, 2012, pp. 523–534.
[25] M. Surdeanu, J. Tibshirani, R. Nallapati, and C. D. Manning, “Multi-instance multi-label learning for relation extraction,” in Proc. EMNLPCoNLL, 2012, pp. 455–465.
[26] C. Quirk and H. Poon, “Distant supervision for relation extraction beyond the sentence boundary,” arXiv preprint arXiv:1609.04873, 2016.
[27] M. Mintz, S. Bills, R. Snow, and D. Jurafsky, “Distant supervision for relation extraction without labeled data,” in Proc. ACL-IJCNLP, 2009, pp. 1003–1011.
[28] G. Ji, K. Liu, S. He, and J. Zhao, “Distant supervision for relation extraction with sentence-level attention and entity descriptions,” in Proc. AAAI, 2017.
[29] R. Socher, B. Huval, C. D. Manning, and A. Y. Ng, “Semantic compositionality through recursive matrix-vector spaces,” in Proc. EMNLPCoNLL, 2012, pp. 1201–1211.
[30] Y. Lin, S. Shen, Z. Liu, H. Luan, and M. Sun, “Neural relation extraction with selective attention over instances,” in Proc. ACL, 2016, pp. 2124–2133.
[31] X. Guo, H. Zhang, H. Yang, L. Xu, and Z. Ye, “A single attention-based combination of cnn and rnn for relation classification,” IEEE Access, vol. 7, pp. 12 467–12 475, 2019.
[32] V.-H. Tran, V.-T. Phi, H. Shindo, and Y. Matsumoto, “Relation classification using segment-level attention-based CNN and dependency-based RNN,” in Proc. NAACL, 2019, pp. 2793–2798.
[33] P. Zhou, W. Shi, J. Tian, Z. Qi, B. Li, H. Hao, and B. Xu, “Attentionbased bidirectional long short-term memory networks for relation classification,” in Proc. ACL, 2016.
[34] J. F. McCarthy and W. G. Lehnert, “Using decision trees for coreference resolution,” arXiv preprint cmp-lg/9505043, 1995.
[35] D. Bean and E. Riloff, “Unsupervised learning of contextual role knowledge for coreference resolution,” in Proc. HLT-NAACL, 2004, pp. 297–304.
[36] M. Bilenko and R. J. Mooney, “Adaptive duplicate detection using learnable string similarity measures,” in Proc. KDD, 2003, pp. 39–48.
[37] P. Christen, “Febrl: a freely available record linkage system with a graphical user interface,” in Proc. HDKM, 2008, pp. 17–25.
[38] T. Cheng, H.W. Lauw, and S. Paparizos, “Entity synonyms for structured web search,” IEEE Transactions on Knowledge and Data Engineering, vol. 24, no. 10, pp. 1862–1875, 2011.
[39] P. Pantel, E. Crestan, A. Borkovsky, A.-M. Popescu, and V. Vyas, “Webscale distributional similarity and entity set expansion,” in Proc. EMNLP, 2009, pp. 938–947.
[40] K. Chakrabarti, S. Chaudhuri, T. Cheng, and D. Xin, “A framework for robust discovery of entity synonyms,” in Proc. KDD, 2012, pp. 1384–1392.
[41] T. Wolf, “Neuralcoref 4.0: Coreference resolution in spacy with neural networks.” 2017.