Deepmind AlphaStar 如何战胜人类职业玩家【中科院自动化所深度解析】

来源:德先生
作者:朱圆恒,唐振韬,李伟凡,赵冬斌
北京时间2019年1月25日2时,DeepMind在伦敦向世界展示了他们的最新成果——星际争霸2人工智能AlphaStar[1] 。

图1. DeepMind AlphaStar挑战星际人类职业玩家直播画面
比赛共11局,直播展示的是去年12月期间AlphaStar挑战Liquid team职业玩家TLO和MANA的部分比赛录像,分别有5局。最后一局为AlphaStar对战MaNa的现场直播。比赛采用固定天梯比赛地图、神族对抗神族的形式。
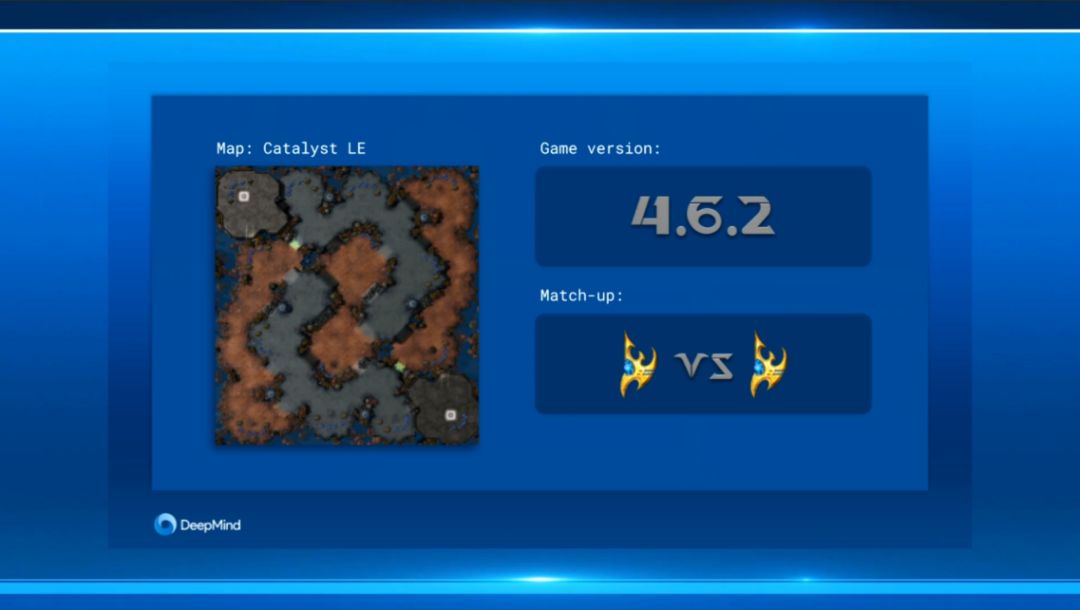
图2. 比赛地图、游戏版本、对战种族信息
结果自然是AlphaStar大比分碾压式胜利,在2018年12月10日以5:0击败TLO,12月19日以5:0击败MaNa。但是当天现场表演赛上AlphaStar却不敌MaNa。最终,AlphaStar取得了10-1的绝佳成绩,堪称世界上第一个击败星际争霸顶级职业玩家的人工智能。
星际争霸
星际争霸是由暴雪娱乐公司开发的一款经典即时战略游戏。与国际象棋、Atari游戏、围棋不同,星际争霸具有以下几个难点:
1、 博弈——星际争霸具有丰富的策略博弈过程,没有单一的最佳策略。因此,智能体需要不断的探索,并根据实际情况谨慎选择对局策略。
2、 非完全信息——战争迷雾和镜头限制使玩家不能实时掌握全场局面信息和迷雾中的对手策略。
3、 长期规划——与国际象棋和围棋等不同,星际争霸的因果关系并不是实时的,早期不起眼的失误可能会在关键时刻暴露。
4、 实时决策——星际争霸的玩家随着时间的推移不断的根据实时情况进行决策动作。
5、 巨大动作空间——必须实时控制不同区域下的数十个单元和建筑物,并且可以组成数百个不同的操作集合。因此由小决策形成的可能组合动作空间巨大。
6、 三种不同种族——不同的种族的宏机制对智能体的泛化能力提出挑战。
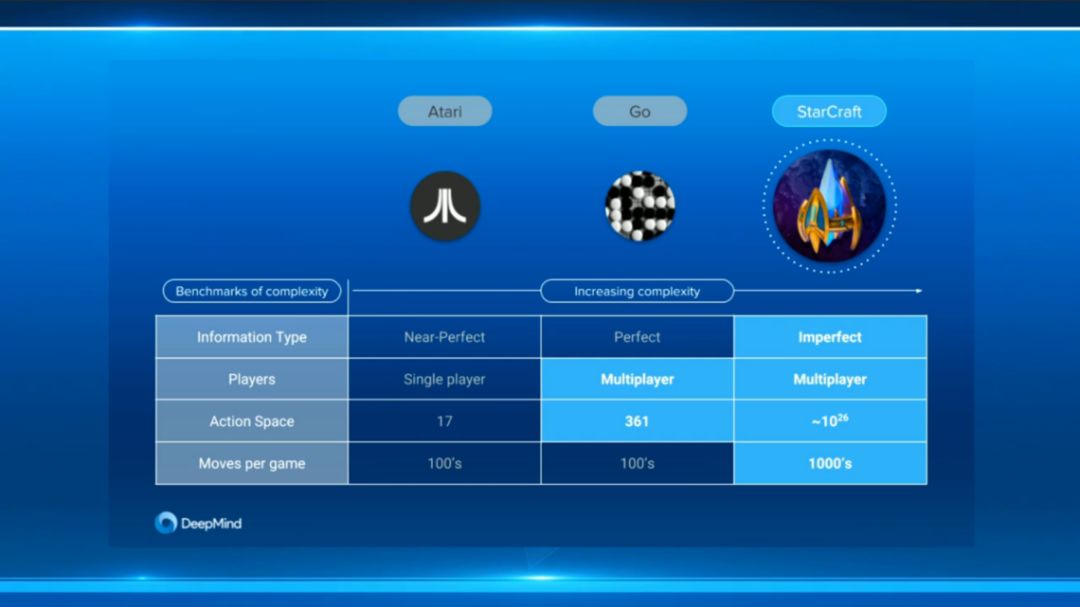
图3. 直播中组织者分析Atari,围棋,星际三者在信息获取程度、玩家数量、动作空间、动作次数的不同,难度呈现逐渐提升
正因为这些困难与未知因素,星际争霸不仅成为风靡世界的电子竞技,也同时是对人工智能巨大的挑战。
评估AlphaStar战力
星际争霸中包含神族、人族、虫族三种选择,不同种族有不同的作战单位、生产机制和科技机制,因而各个种族间存在战术制衡。为了降低任务训练所需时间,并避免不同种族间客观存在的不平衡性,AlphaStar以神族对阵神族为特定训练场景,固定使用天梯地图-CatalystLE为训练和对决地图。
面对虫族职业玩家TLO和排名更加靠前的神族职业玩家MaNa的轮番挑战,AlphaStar凭借近乎无解的追猎微观操作和凤凰技能单位的配合,能在绝大多数人类玩家都认为严重受到克制的兵种不朽下,在正面战场上反败为胜扭转战局,并最终兵不血刃的横扫人类职业玩家,取得了星际争霸AI当前最佳的表现水平,在实时战略游戏上取得了里程碑式的意义。

图4. 追猎者相互克制兵种关系
AlphaStar是如何训练的?
AlphaStar的行为是由一个深度神经网络产生。网络的输入来自游戏原始的接口数据,包括单位以及它们的属性,输出则是一组指令,这些指令构成了游戏的可行动作。网络的具体结构包括处理单位信息的变换器(transformer),深度LSTM核(deep LSTM core),基于指针网络(pointer network)的自动回归策略头(auto-regressive policy head),和一个集中式价值评估基准(centralised value baseline)。这些组成元件是目前最先进的人工智能方法之一。DeepMind将这些技术组合在一起,有信心为机器学习领域中普遍存在的一些问题,包括长期序列建模、大规模输出空间如翻译、语言建模、视觉表示等,提供一种通用的结构。
AlphaStar权重的训练同样是使用新型的多智能体学习算法。研究者首先是使用暴雪发布的人类匿名对战数据,对网络权重进行监督训练,通过模仿来学习星际天梯上人类玩家的微观、宏观策略。这种模拟人类玩家的方式让初始的智能体能够以95%的胜率打败星际内置电脑AI精英模式(相当于人类玩家黄金级别水平)。
在这初始化之后,DeepMind使用了一种全新的思路进一步提升智能体的水平。星际本身是一种不完全信息的博弈问题,策略空间非常巨大,几乎不可能像围棋那样通过树搜索的方式确定一种或几种胜率最大的下棋方式。一种星际策略总是会被别一种策略克制,关键是如何找到最接近纳什均衡的智能体。为此,DeepMind设计了一种智能体联盟(league)的概念,将初始化后每一代训练的智能体都放到这个联盟中。新一代的智能体需要要和整个联盟中的其它智能体相互对抗,通过强化学习训练新智能体的网络权重。这样智能体在训练过程中会持续不断地探索策略空间中各种可能的作战策略,同时也不会将过去已经学到的策略遗忘掉。
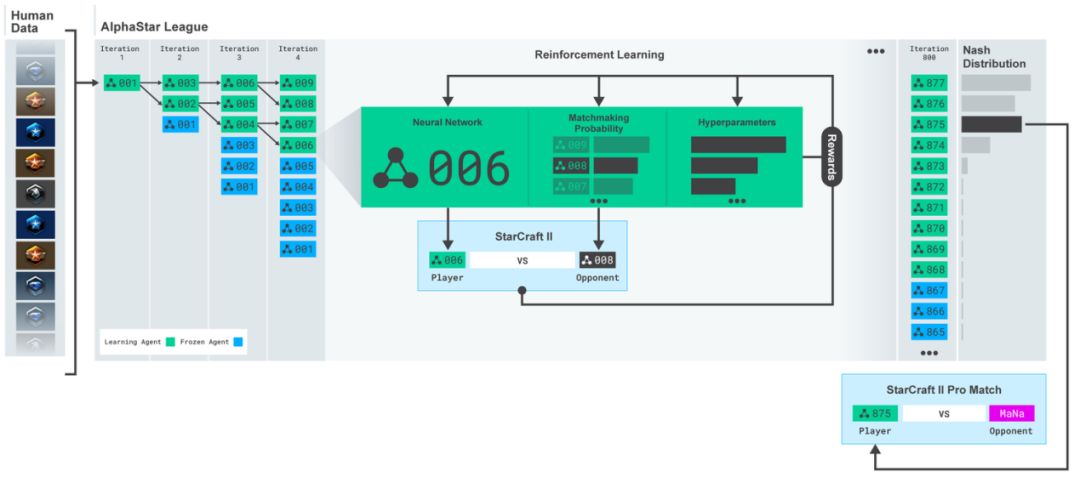
图5. 在使用人类数据初始化智能体后,DeepMind构建了一个智能体联盟,在每一代都将强化学习得到的智能体放入这个联盟中,每个智能体要和联盟中其它的智能体做对抗学习。最终从联盟中水平靠前的几个智能体中选取一个和MaNa对抗。
这种思路最早出现在DeepMind另一项工作——种群强化学习(population-based reinforcement learning)。这与AlphaGo明显的不同在于:AlphaGo让当前智能体与历史智能体对抗,然后只对当前智能体的权重做强化学习训练;而种群强化学习则是让整个种群内的智能体相互对抗,根据结果每个智能体都要进行学习,从而不只是最强的智能体得到了提升,它的所有可能的对手都有所提升,整个种群都变得更加智能。
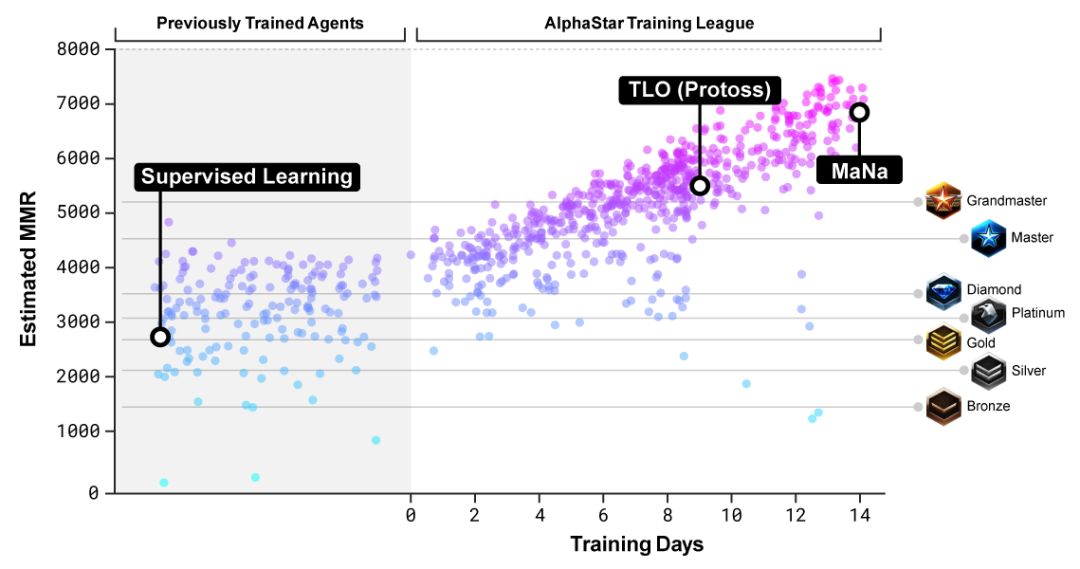
图6. 随着联盟中对智能体的训练,整个联盟的最强水平和整体水平都得到了提升,最终超过了人类玩家MaNa和TLO(神族)在MMR下的评分。图中纵坐标给出的是Match Making Rate (MMR),是一种对玩家水平的有效评估,图中横线对应暴雪对线上玩家水平的分级。
此外DeepMind还宣称,每个智能体不只是简单地和联盟其它智能体相互对抗学习,而是有针对性、有目的性的学习。例如通过内在激励的调整,有些智能体只考虑打败某种类型的竞争对手,而另一些智能体则是要尽可能地击败种群的大部分智能体。这就需要在整体训练过程中不断地调整每个智能体的目标。
权重的训练使用了新型的强化学习——离策略执行-评价(off-policy actor-critic)算法,结合了经验回放(experience replay)、自我模仿学习(self-imitation learning)、和策略蒸馏(policy distillation)。这些技术保证了训练的稳定性和有效性。

图7. 黑点代表了和MaNa对战所选择的智能体。大图给出了该智能体在训练过程中策略的变化情况。其它彩色点代表了不同策略对应的智能体,并显示出了不同时期不同策略被选中和MaNa智能体对抗的概率。尺寸越大,被选中概率越大。左下图给出了不同训练时期MaNa智能体出兵组成变化。
硬件部分
为了训练AlphaStar,DeepMind调动了Google的v3云TPU。构建了高度可拓展的分布式训练方式,支持数千个智能体群并行训练。整个AlphaStar智能体联盟训练了14天,每个智能体调用了16个TPU。在训练期间,每个智能体经历了相当于正常人类要玩200年的游戏时长。最终的AlphaStar智能体集成了联盟当中最有效策略的组合,并且可以在单块桌面级GPU上运行。
AlphaStar是如何玩游戏的?
在比赛时AlphaStar通过其界面直接与星际争霸游戏引擎交互,获得地图上可以观察的所有信息,也可称为全局信息。它并没有输入移动视角的视野图像。不过对比赛录像的分析表明AlphaStar隐式地学到了注意力集中机制。平均而言,AlphaStar的动作指令每分钟会在前线和运营之间切换30次,这与MANA和TLO等人类玩家的切屏行为非常相近。

图8. 与MaNa第二场比赛中AlphaStar的神经网络可视化。从智能体的角度显示了它对游戏的理解,左下角起为游戏的输入,神经网络的激活可视化,智能体的主要操作位置,局势评估,生产建造。
在12月份的比赛之后,DeepMind开发了第二版的AlphaStar。加入了移动视角机制,使其只能感知当前屏幕上的视野信息,并且动作位置仅限于当前区域。结果表明AlphaStar同样能在移动视角输入下迅速提升性能,紧紧追赶全局输入的性能,最终结果几乎一致。
DeepMind一共训练了两种智能体,一个使用原始全局输入,一个使用移动视角输入。它们都首先使用人类数据监督学习初始化,然后使用上述强化学习过程和第一版学好的智能体联盟对抗。使用使用视角输入的智能体几乎与全局输入的一样强大。在DeepMind的内部排行榜上超过7000MMR(远高于MaNa的MMR)。然而在直播比赛当中,MaNa战胜了移动视角的智能体。DeepMind分析认为该智能体只训练了七天的时间,还没有达到它的最高水平,希望在不久的将来会对收敛结果做进一步评测。
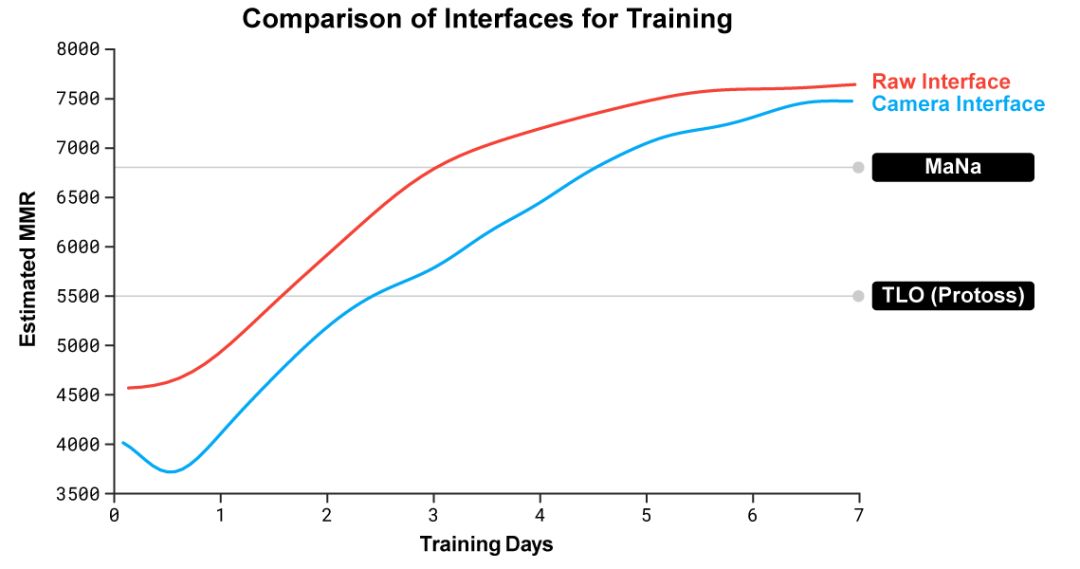
图9. 以整个地图信息为输入和以移动视角为输入两种智能体训练的提升效果比较。两者都是不完全信息,存在战争迷雾遮挡敌方单位的情况。只不过前者是将所有可视单位的信息放在全局地图上作为输入,后者是只将玩家局部视野内的单位信息作为输入。因此后者需要智能体在游戏过程中不断调整局部视野的范围,确保有用信息的输入。
众多观战者另一个关心的问题是AlphaStar的平均每分钟操作数(Actions Per Minute, APM)。计算机可以利用强大的计算能力,在短时间集中大量的操作,远超过人类的极限能力。就算是顶级职业玩家,APM也仅有数百,远远低于现有的对战机器人。如自动悍马2000,可以独立控制每个单元,APM维持在数万以上。
在TLO和MANA的比赛当中,AlphaStar的平均APM为280,尽管其操作更为精确,但APM明显低于大部分职业玩家。同时,AlphaStar从观察到行动之间存在350毫秒的延迟。
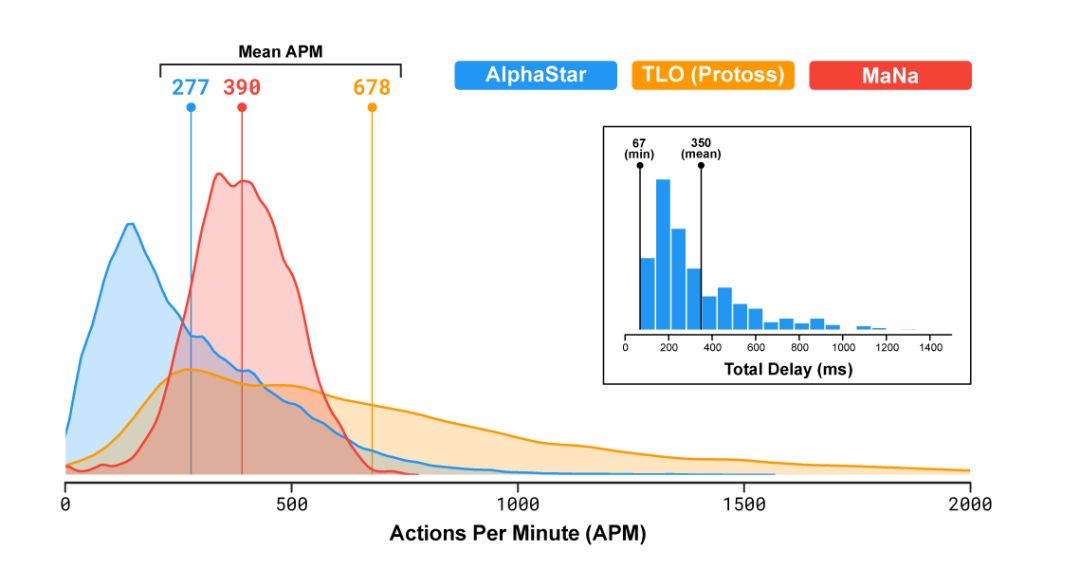
图10. 对战时AlphaStar,TLO(神族),MaNa三者的APM比较
综上,DeepMind认为AlphaStar对MaNa和TLO的胜利依靠的是卓越的宏观机制和微观战略决策,而不是单纯的靠闪烁追猎Blink。
AlphaStar优缺点分析
AlphaStar优势
1) 战胜职业玩家
AlphaStar的成功在星际争霸游戏乃至整个实时战略游戏具有里程碑式的意义,不仅在于第一次正式击败人类职业玩家,更在于这套深度强化学习框架在不完全依赖于规则脚本的基础上,通过监督学习、模仿训练、种群提升、和后期强化学习来提升智能体的作战能力。这套研究思路和方法一样适用于其他的实时战略游戏。
2) 微观操作卓越
即使在兵种对抗处于劣势的情况下,AlphaStar依靠精准的微操决策控制能力,仍然可以在形势不利的局面下反败为胜,化逆境为顺境。表现了实时战略游戏的一种虽然简单粗暴但较为直接的解决方式,证明了深度强化学习探索到较优可行解的能力。
3) 利用地形优势的感知能力
在战争局势不利的情况下,准确作出战略撤退,并分散撤退到具有较高地势的关口四周。利用峡口因素精确作出包夹的动作行为,形成对敌方的封锁及包抄,从而为局势逆转提供条件,具备较强的地形感知能力和利用性。
AlphaStar不足
1) 硬件资源需求高
单个智能体训练需要16个V3版本(最新版,运算次数为V2版本的8倍)的云TPU,以Alpha League训练完成的10类智能体作为保守估计,至少需要上百块TPU作为硬件计算支持,带来的硬件基础成本使普通开发者难以承受。
2) 鲁棒性仍不足
在最后一场直播中可见,由于AlphaStar无法根据敌人骚扰意图分散安排兵力部署防守本方基地,致使被人类玩家戏耍来回拉扯全军大部队,从而始终无法对人类玩家发起进攻,使人类玩家有足够时间生产大量的反追猎兵种(不朽),最终导致比赛的失利。
3) 地图场景较为简单
本次使用CatalstLE为两人小地图,没有多余的随机起始点,因而AlphaStar不需要派侦察部队侦察敌人确定位置,减小了环境的不确定性,简化了整体的不完全信息性。并且小地图使智能体偏向于使用RUSH类战术,使探索策略的复杂性显著降低。
4) 微操APM峰值过高
不同于普通人类玩家,AlphaStar的APM不具有冗余重复性,每次都为有效操作(EPM)。普通人类玩家的EPM平均大约只有80左右,只有在交战过程中短暂的20秒到30秒左右的时间达到EPM 200以上。但AlphaStar在使用近乎无解的闪烁追猎战术EPM估计能达到1000左右,显然对于人类玩家并不公平。
5) 后期表现未知
根据此次比赛公开的录像表现,AlphaStar大部分时刻采取追猎者攻击、骚扰或防御等动作,尚未观察到其他更为高级的兵种操作,并且没有出现满人口满科技树的情况,因而AlphaStar的后期表现能力存在较大疑问。
总评:从开放的11组视频对战资源分析,AlphaStar可以在局势不利的情况下,凭借卓越的微操控制能力、地形利用能力和多兵种整体协同配合能力,有效逆转战局,实现扭亏为盈。但是在最后一场现场直播中,AlphaStar出现了明显的作战缺陷,始终无法合理分配兵力保护基地,被人类玩家来回拉扯战场,错过了进攻的最佳时机,导致最终失利。纵观本次人机对抗,虽然在限制Bot的APM部分做的不太到位,只限制其APM的均值而没对峰值限制,但与2017年在韩国世宗大学举办的星际人机对抗(同样没对电脑APM作限制)以Bot的惨败相比较,本次的AlphaStar是真正意义上在全尺度地图上击败了星际争霸人类职业玩家,可谓进步显著。
星际争霸AI的研究进展简介
星际争霸是由暴雪娱乐公司于1998年公开发售,为实时战略游戏的典型代表,深受广大游戏玩家的欢迎并创造一列历史先河。与此同时,随着BWAPI,TorchCraft,SC2LE等开源API (Application Interface)的发布,众多研究者和工程师们纷纷对星际争霸展开了深入研究。

图11. 2017年星际人机对抗(脚本Bot)与2019年星际人机对抗(AI Bot)
早期的搜索型算法(如α-β搜索,MCTS树搜索)已经被广泛用于完成星际中动作攻击选择任务和建筑生产序列规划任务。并随着计算资源及性能的不断提升,演化计算、深度神经网络、深度强化学习(AlphaStar的主要采用方法)等方法正发挥着越来越显著的作用。图11表示了近些年人工智能算法在星际争霸的子任务中的具体应用。其中以强化学习为代表的计算智能算法在星际争霸领域取得了一系列显著的突破性进展。在特定场景的星际微操任务下,多智能体强化学习方法如阿里的Peng等提出的基于双向RNN的BicNet[3] ,牛津大学Foerster等提出的基于反事实机制的COMA[4] , 自动化所Shao等提出的基于SARSA(λ)和权重共享的PS-MAGDS[5] 等方法表现突出,能有效处理多智能体间信誉分配的问题。而在宏观序列生产预测任务,自动化所Tang等基于卷积神经网络的前向Q学习方法[6] 能帮助智能体找到最佳的生产序列,提升智能体的环境适应性,从而击败内置AI。分层强化学习方法可以在需要长期规划的任务问题上解决奖赏反馈稀疏的问题,以腾讯的TStarBot[7] 为代表的层级强化学习证明了该方法能在标准天梯地图中完整地完成AI的整套系统性学习任务。
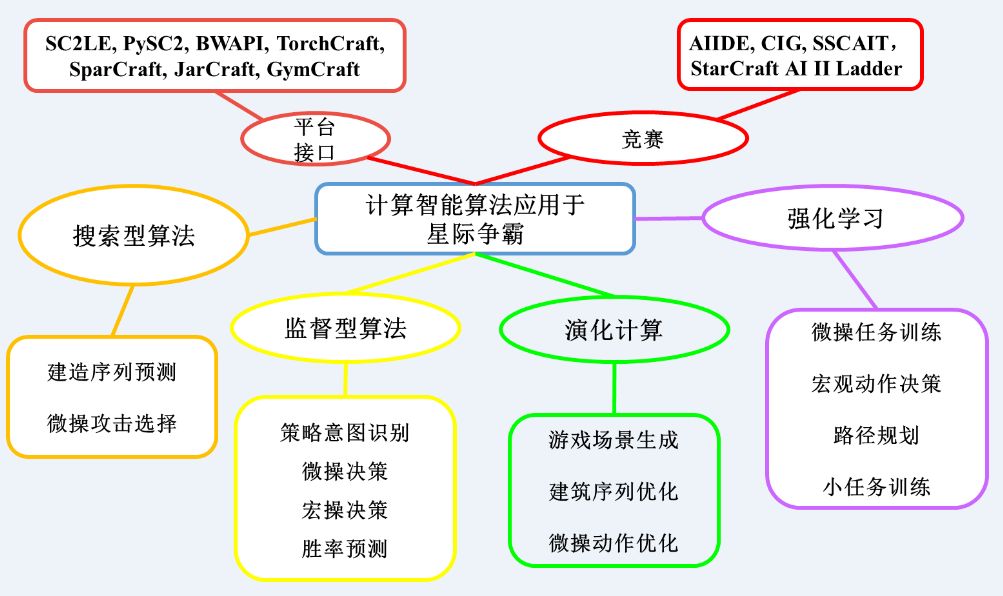
图12. 计算智能算法在星际争霸中的应用环境[2]
AlphaStar同样采用深度强化学习作为其核心训练方法,并与他的“哥哥”AlphaGo具有相似之处,都采用人类对战数据作预训练模仿学习。但为了满足实时性要求,AlphaStar舍弃了搜索模块,只让神经网络输出发挥作用,是一种更为纯粹的“深度强化学习”方法。
结束语
从AlphaStar的表现来看,人工智能半只脚已经踏上了实时对战游戏的顶峰。然而另外半只脚能否踏上去还要看能否解决现存的后期乏力、鲁棒性差的问题。近年来随着国际象棋、Atari游戏、围棋、德州扑克等一一被征服,人工智能在不断挑战人类智力领域的统治力。反之人类研究者也在不断推动和挖掘人工智能的极限。人工智能是否有极限?下一个将会被征服的领域会是什么?让我们拭目以待。
[1] AlphaStar: Mastering the Real-Time Strategy Game StarCraft II. DeepMind. https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
[2] Z. Tang, et al., “A Review of Computational Intelligence for StarCraft AI,” SSCI-18, 2018.
[3] P. Peng, et al., “Multiagent bidirectionally-coordinated nets for learning to play StarCraft combat games,” arXiv, 2017.
[4] J. Foerster, et al., “Counterfactual multi-agent policy gradients,” AAAI-18, 2018.
[5] K. Shao, et al., “StarCraft micromanagement with reinforcement learning and curriculum transfer learning,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2018.
[6] Z. Tang, et al., “Reinforcement learning for buildorder production in StarCraft II,” ICIST-18, 2018.
[7] P. Sun, et al. "Tstarbots: Defeating the cheating level builtin ai in starcraft ii in the full game." arXiv, 2018
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


