英特尔首款AI芯片终于面世!10nm工艺,以色列团队设计细节曝光

新智元报道
【新智元导读】英特尔在Hot Chips大会上发布了首款AI处理器,专为大型计算中心设计。该芯片基于10纳米Ice Lake处理器,专为大型数据中心设计,可以用最少的能耗来处理高工作负载。本文带来这款芯片的详细设计细节。
近日在Hot Chips 2019大会上,英特尔发布了首款AI处理器,专为大型计算中心设计。

英特尔表示,该芯片由位于以色列海法的研发中心开发,名为Nervana NNP-I或Springhill,基于10纳米Ice Lake处理器,可以用最少的能耗来处理高工作负载。
英特尔表示,随着AI领域对复杂计算的需求日益增加,这款新的硬件芯片将有助于大型企业使用英特尔Xeon处理器。
在Hot Chips大会上,他们提供了这款AI芯片的更多设计细节。

英特尔正采取数项不同的举措,通过其“无处不在的AI”('AI everywhere)战略,扩大其在蓬勃发展的AI市场的影响力。该公司广泛的产品包括GPU,FPGA和定制ASIC,用于应对AI领域的不同挑战,其中一些解决方案专为计算密集型的训练任务而设计,用于为目标识别、语音翻译、语音合成等工作负载创建复杂的神经网络,将产生的训练模型作为轻量级代码运行的单独解决方案称为推理。
英特尔的Spring Hill Nervana神经网络推理处理器(NNP-I) 1000,我们在下文中简称为NNP-I,用于处理数据中心的轻量级推理工作负载。这款芯片足够小,可以安装在标准的M.2设备上,然后插入主板上的标准M.2端口,从而将Xeon服务器从推理密集型工作负载中解放出来,将更大的芯片释放出来用于一般计算任务。用于训练的神经网络处理器 (NPP-T) 作为英特尔的Nervana解决方案用于训练工作负载,但这两种设备的底层架构有很大的不同。
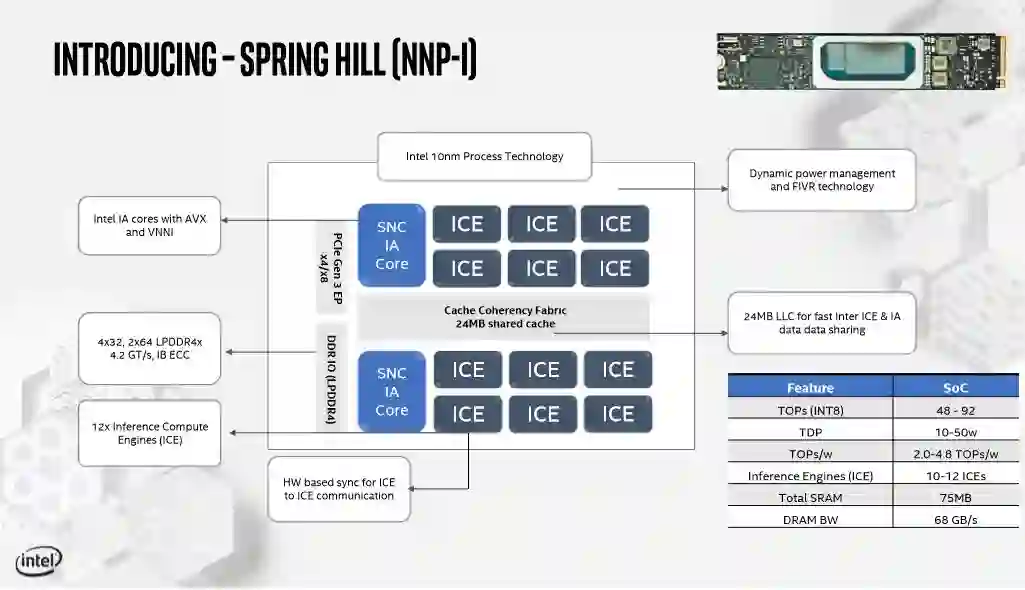
英特尔修改了10nm Ice Lake处理器,去掉了两个计算核心和图形引擎,以适应12个推理计算引擎(ICE)。ICE加速器具有基于硬件的单元间同步,与两个IA核共享一个连贯的结构和24MB的L3缓存,这两个IA核具有Sunny Cove微架构。
IA核心是标准的Ice Lake核心,支持AVX-512和VNNI指令,可加速卷积神经网络,而一个完全集成的电压调节模块(FIVR)动态地向组件供电,将更多的功率预算分配给最活跃的on-die单元。该芯片配备了两个LPDDR4X内存控制器,连接到封装内存,你可以将其视为M.2 PCB左下方的单个组件。控制器提供高达4.2 GT/s (68 GB/s)的吞吐量,并支持 in-band ECC。
英特尔尚未透露LPDDR4的容量,也没有透露有关M.2设备的其他细节。我们知道英特尔将这个软件包安装在不同形式的插入卡上,比如上面的M.2版本,它可以插入服务器主板上的标准M.2端口,或者插入标准的PCIe插槽的更大的附加卡。与谷歌的TPU等为人AI设计的定制芯片不同,这款设备基本上与所有现有的现代服务器硬件兼容。这种方法也是可扩展的:你可以根据需要向服务器添加尽可能多的NNP-I,特别是对于包含多个M.2端口的PCIe提升板。
该设备通过PCIe 3.0 x4或x8接口与主机通信,但不使用NVMe协议。相反,它作为一个标准的PCIe设备运行。英特尔将提供一种软件,可以将推理“作业”完全编排到加速器上,当工作完成时,该软件将通知Xeon CPU。卸载消除了Xeon与其他类型的加速器在PCIe总线上的来回通信,这对CPU来说是一种负担,因为它会生成中断并需要数据移动。相反,NNP-I是一个独立的系统,具有自己的I/O调节(PCH),允许它访问处理所需的数据。
该设备可以支持从10W到50W的不同功率范围,这对性能有影响。M.2接口的15W限制阻碍了插入标准M.2插座的设备的功率传输,但NNP-I在更大的外接卡中可以在最高TDP额定值下运行,这意味着它们提供了更好的性能。在INT8操作中,TOP/s的范围从48到92。根据配置的TDP,芯片的效率为每瓦特2~4.8 TOP/s,但该指标不包括总包功率。
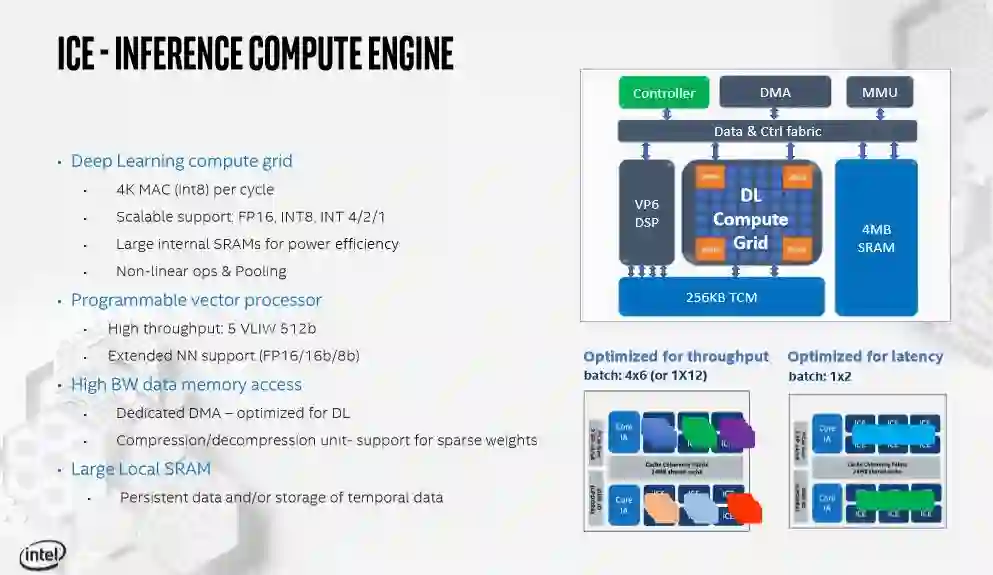
深入研究ICE引擎可以发现,每个ICE单元都有额外的4MB SRAM,有助于减少芯内数据移动,这在功耗和时间方面总是比实际的计算操作更昂贵。深度学习计算网格(DL Compute Grid)是一个张量引擎,通过数据和控制结构连接到SRAM和VP6 DSP。DSP引擎可以用于没有专门针对固定功能DL计算网格进行优化的算法。此外,其他代码可以在Ice Lake核心上使用VNNI运行,使多个模型可以同时在设备上运行,也为快速移动的AI空间提供了一些必需的前向兼容性。
DL Compute Grid支持FP16和INT8,但也支持INT4、2和1,以支持未来可能对AI算法进行的调整。令人惊讶的是,它不支持bfloat16。通过调整工作负载在ICE单元之间的分布方式,可以优化fabric的带宽或延迟,如下表所示。
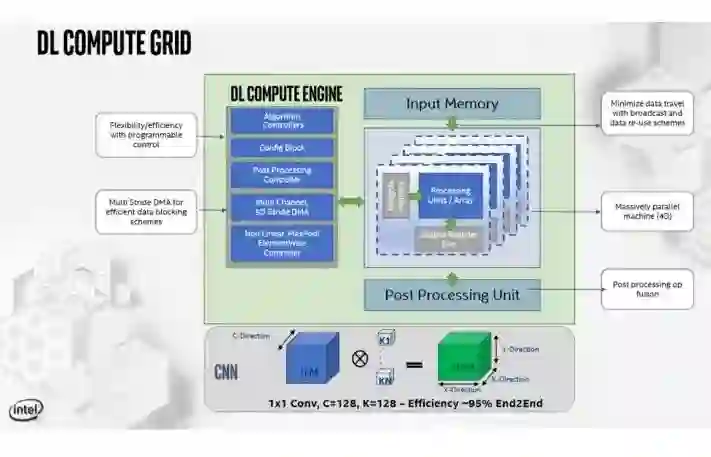
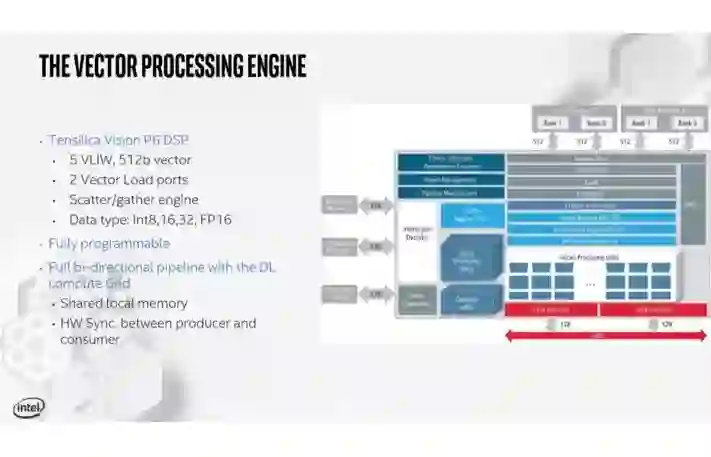
这里我们可以看到DL Compute Grid的特写视图,它被设计得很灵活,以最大化其4D并行计算能力,以及用于矢量处理的Tensilicon Vision P6 DSP。Tensilica DSP引擎是一个广泛的VLIW机器,支持INT8, 16, 32,和FP16。该引擎是完全可编程的,并具有一个双向管道和DL Compute Grid,可在两个硬件同步单元之间快速传输数据。。
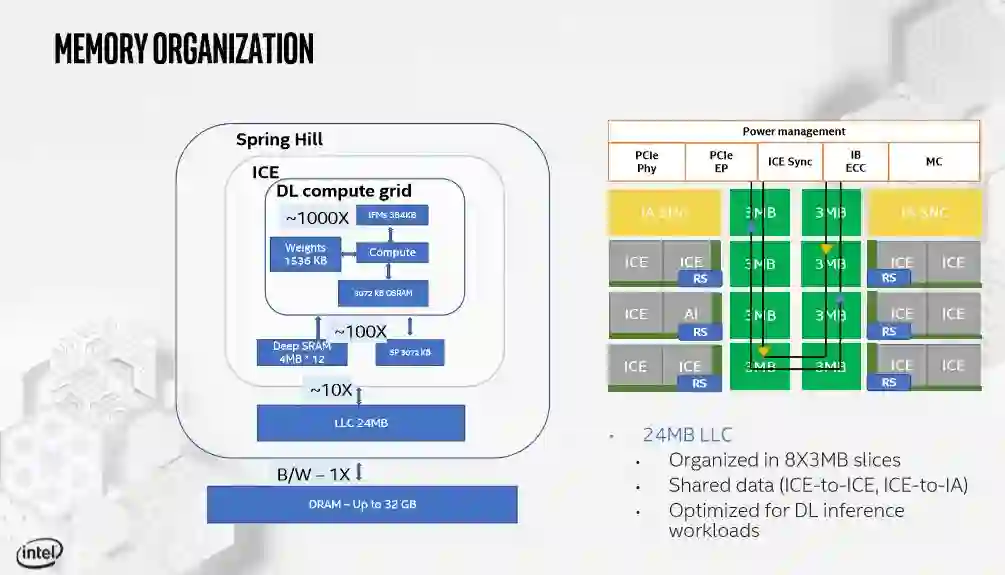
回到内存子系统,可以看到每个计算单元中所做的设计决策背后的许多合理化。这里我们可以看到硬件控制的L3缓存被分成8个3MB的片段,在AI核心和ICE单元之间共享。该设计经过优化,使数据尽可能接近计算引擎,并具有四个不同的层。
图表左侧的一系列blocks量化了通过内存结构的每一层移动数据的延迟。从DRAM到DLCompute Grid的数据传输被设置为基线,我们可以看到分层结构中的每一层将数据传输的engine的速度是多么快。从L3缓存访问比DRAM快10倍,而存储在DL Compute Grid中的数据比DRAM快1000倍。
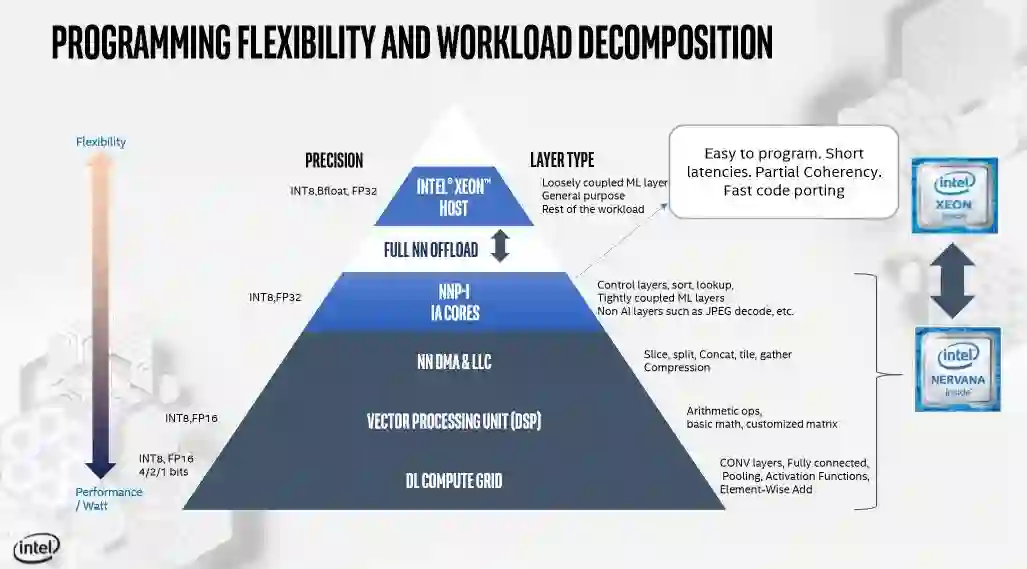
总之,分层设计允许Xeon向设备卸载几种不同类型的神经网络,每一层都支持一定的精度。请注意,上面的金字塔是根据每瓦特的性能排列的。

英特尔与ResNet50共享性能数据,运行速度为每秒3600 次推理,芯片设置为10W TDP。这相当于每瓦特4.8 TOP/s的效率测量,符合公司的设计目标。值得注意的是,芯片在较低的TDP范围内效率更高,因此在较高的性能设置下效率可能会有所不同。这些数字也只适用于ASIC,不包括整个M.2设备的功耗。英特尔表示,未来将分享更多的性能数据。
英特尔提供了一个编译器,可以为NNP-I的加速器定制代码,并正在与Facebook合作,以确保Glo编译器也支持NNP-I的加速器。Facebook是英特尔在开发期间的“定义”合作伙伴。该设备还支持所有标准框架,如PyTorch和TensorFlow等,几乎没有任何更改。英特尔坚持认为,任何能够使用Xeons进行推理的人都可以使用NNP-I。
在数据中心,推理应用远比训练普遍,价格合理的低功耗设备将集体销售给超大规模和云服务提供商(CSP),意思是这可以成为英特尔的一个利润丰厚的细分市场。该公司本身并没有打算将这些设备推向零售市场,但确实希望CSP在未来通过基于云的实例来公开它们。
英特尔已经研发了两代NNP-I。该公司将在今年年底前开始批量生产,NNP-I已经开始提供样品。
原文:
https://www.tomshardware.com/news/intel-10nm-ice-lake-neural-network-processor-ai-inference-m.2,40204.html





