带你读论文 | 端到端语音识别模型

编者按:过去十年,得益于人工智能与机器学习的突破、算法与硬/软件能力的进步,以及拥有既多样又大量的语音数据库,用以训练多参数的、大规模的语音识别与合成模型,使得语音处理技术获得飞跃性进展。
随着端到端神经网络在机器翻译、语音生成等方面的进展,端到端的语音识别也达到了和传统方法可比的性能。不同于传统方法将语音识别任务分解为多个子任务(词汇模型,声学模型和语言模型),端到端的语音识别模型基于梅尔语谱作为输入,能够直接产生对应的自然语言文本,大大简化了模型的训练过程,从而越来越受到学术界和产业界的关注。
本文将通过六篇论文,从建模方法、响应时间优化、数据增强等不同方面讲解端到端语音模型的发展,并探讨不同端到端语音识别模型的优缺点。

在讲述语音识别建模之前,首先明确端到端语音识别的输入和输出。
输入:目前端到端语音识别常用的输入特征为 fbank。fbank 特征的处理过程为对一段语音信号进行预加重、分帧、加窗、短时傅里叶变换(STFT)、mel 滤波、去均值等。一个 fbank 向量对应往往对应10ms的语音,而一段十秒的语音,即可得到大约1000个 fbank 的向量描述该语音。除了 fbank,MFCC 以及 raw waveform 在一些论文中也被当做输入特征,但主流的方法仍然采用 fbank。
输出:端到端的输出可以是字母、子词(subword)、词等等。目前以子词当做输出比较流行,和 NLP 类似,一般用 sentence piece 等工具将文本进行切分。
Seq2Seq
参考论文:Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition. ICASSP 2016(William Chan, Navdeep Jaitly, Quoc V. Le, Oriol Vinyals)
给定序列 X,输出 Y,最直白的一种办法就是延伸在机器翻译中所使用的 Seq2Seq 模型。Seq2Seq 模型由两部分组成:编码器和带有注意力机制的解码器。在解码每个词语的时候,注意力机制会动态计算每个输入隐状态的权重,并通过加权线性组合得到当前的注意力向量。在此处的语音识别任务中,Seq2Seq 模型与机器翻译中的 Seq2Seq 模型异曲同工,可以使用不同的模型作为编码器和解码器,例如 RNN、Transformer 模型等。
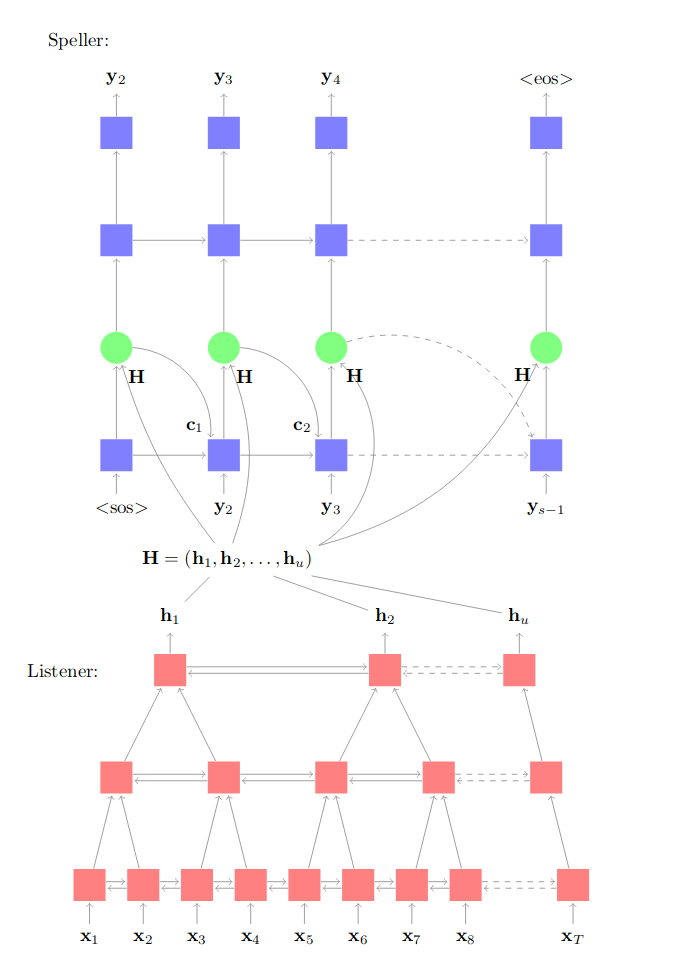
图1:Listen, attend and spell 模型结构图
为了训练更好的 Seq2Seq 语音识别模型,一些优化策略也被提出:
引入增强学习策略,将最小词错率(minimum word error rate)当作模型训练的奖励函数,更新模型参数。
由于语音的输入和输出有着单调性,并不存在机器翻译的调序问题,所以使用单调注意力策略,在一些实验中可以提升语音识别的性能。
引入覆盖(coverage)机制,缓解语音识别的漏词问题。
与 CTC 联合训练以及联合解码,可大幅提升 Seq2Seq 模型性能。
CTC
参考论文:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. ICML 2006(AlexGraves, SantiagoFernández,FaustinoGomez)
除了简单易懂的 Seq2Seq 模型之外,还需要关注另一个经典之作 CTC 模型。CTC 模型是端到端语音识别的开山始祖,提出时间远早于 Seq2Seq 模型,其建模思想也与 Seq2Seq 模型相去甚远。CTC 模型可以看作自动学习输入 X 与 Y 的对齐,由于 Y 的长度远小于 X,所以 CTC 引入空和 y_i 的重复来让 X 和 \{y}_hat 一一对应。
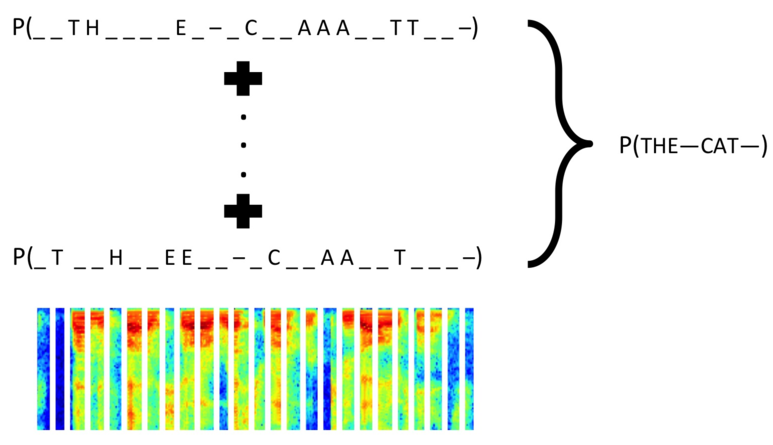
图2:CTC 输入音频与文本对应关系
例如,在图2中,CTC 引入空和重复使得句子 THE CAT (Y)和输入音频(X)做对齐。这种对齐方式有三个特征:
(1)X 与 Y 映射是单调的,即如果 X 向前移动一个时间片,Y 保持不动或者也向前移动一个时间片。
(2)X 与 Y 的对齐是多对一的。一个 X 可以有很多种方式和 Y 进行对应。
(3)X 的长度大于 Y 的长度。
为了求得该映射,需要最大化后验概率 P(Y|X)
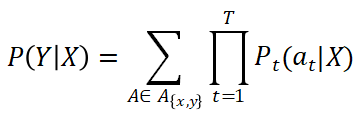
这里 A 是一条合法的 x 和 y 的对应路径,a_t 代表 t 时刻 X 所对应的输出。如有兴趣可参见 https://distill.pub/2017/ctc/ 了解更多的推导细节。
在训练中 CTC 与 Seq2Seq 模型相比,CTC 模型有如下不同:
CTC 在解码时,对于每一帧都可以生成一个对应的子词,因此 CTC 比 Seq2Seq 可以更好地支持流式语音识别。
CTC 的建模并没有直接建模 Y 中不同词语之间的依赖关系,所以生成的文本从语言模型的角度来看质量较差。为了解决这个问题,CTC 往往要和外部的语言模型一起进行解码才可以生成更好的结果。
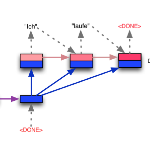
Transducer
参考论文:Sequence Transduction with Recurrent Neural Networks. arXiv 2012(Alex Graves)
由于 CTC 模型无法显示建模 Y 中词与词的依赖关系,Transducer 模型在2012年被提出。Transducer 可以被看作是 CTC 模型的延伸,由文本预测网络(text prediction network)来建模语言模型,弥补了 CTC 的缺点。之后语言模型的隐状态和语音编码器的隐状态传递给联合网络(joint network),以预测当前时刻的输出。
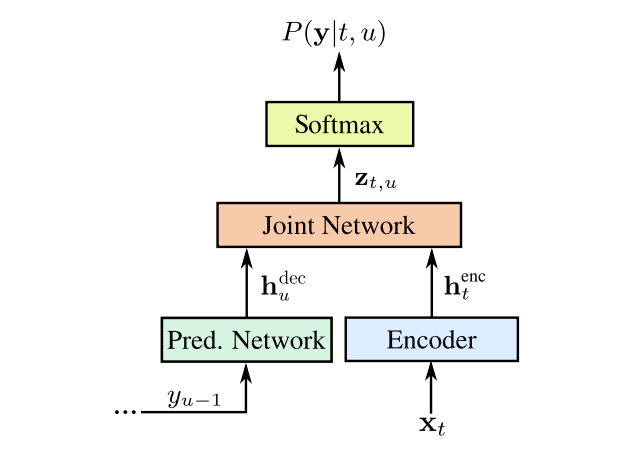
图3:Transducer 结构图
值得注意的是,Transducer 的状态转移矩阵和 CTC 稍有不同,在 CTC 中一个词连续出现两次会在后处理时被合并,而 Transducer 不支持这种表示,其主要原因为 Transducer 对语言模型进行了建模,每输出一个词它的 prediction network 的隐状态就会变化一次。并且 Transducer 支持同一帧对应多个输出单元,而 CTC 不支持。因为 CTC 和 Transducer 都是逐帧解码,语音结束解码过程结束,他们也被称作是帧同步(frame synchronized) 模型。与之相反的是 Seq2Seq 模型是逐词解码,直到出现 EOS 才结束,所以被称作词同步(word synchronized)模型。
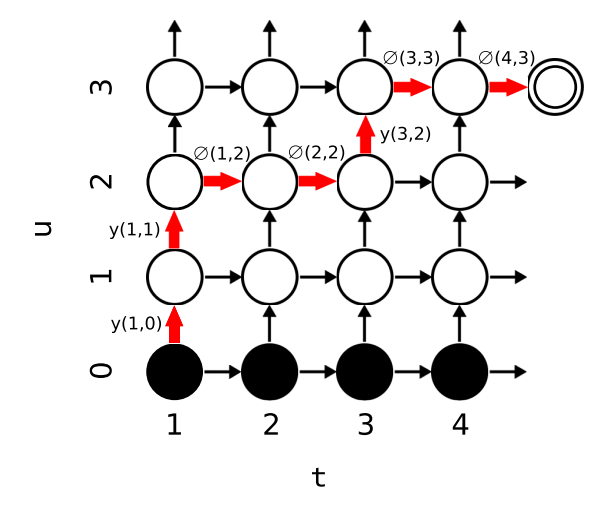
图4:Transducer 转移矩阵
有了大致的模型结构之后,科研人员们又从不同的方面对端到端模型进行了优化。
数据增强
参考论文:SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. INTERSPEECH 2019(Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, Quoc V. Le)
由于端到端模型需要大规模数据训练,而很多场景并没有那么多的数据,因此数据增强算法在端到端语音识别系统里最近被多次研究。其中最著名的数据增强算法为 Spec Augmentation。该方法简单实用,可以被看作是一种用于频谱的增强方法,来帮助神经网络学习有用的特征。为了使模型更加鲁棒,研究者采用了3种方法,对数据进行增强:
Time-warp: 可通俗理解为在梅尓谱中沿着时间轴把任意一帧向左或向右扭曲随机距离。
Frequency mask:添加在频率 f 的连续梅尔谱上,将 [f0, f0+f]mask。其中 f是一个统一的0到 F 的参数,f0 是选自 [0,v-f] 中的。v 则代表了梅尔频谱图的通道数量。
Time mask:添加在 t 的连续时间上,将谱图 [t0,t0+t] 全部掩盖掉。t 是一个0到 T 的均匀分布。
这其中 Time mask 和 Frequency mask 对模型鲁棒性的贡献最大。
延迟优化
参考论文:Towards Fast and Accurate Streaming End-to-End ASR. ICCASP 2019(Bo Li, Shuo-yiin Chang, Tara N. Sainath, Ruoming Pang, Yanzhang He, Trevor Strohman, Yonghui Wu)
端到端模型由于模型小,不需要额外的语言模型,所以很容易部署到移动设备之上。而在移动设备上的语音场景往往需要一个延时非常小的语音识别模型。例如,当用户说完“请为我查找歌曲晴天”时,系统应该尽可能快的进行响应,压缩延迟。迄今为止,有一系列工作对压缩 Transducer 的延迟展开了研究。其中比较著名的是 Google 所提出的 Endpointer 和其对应的关于延迟的惩罚。Endpointer 可以当做 Transducer 模型的句子结束符 EOS,研究员们希望这个 EOS 可以尽早出现,然而过早的出现可能导致删除错误,所以 Google 的研究员提出了 Early and Late Penalties 去建模 EOS 出现位置。
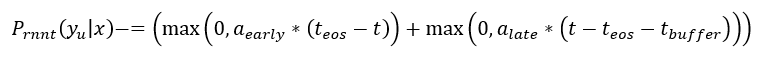
在公式中,首先需要知道 EOS 所出现的真实时刻,之后如果 EOS 早出现或者晚出现(允许晚 t_buffer)都要进行相应的惩罚。然而,此种方法往往会带来对精度的损失,在语音识别任务中,往往更好的延迟会以牺牲精度为代价。
参考论文:On the Comparison of Popular End-to-End Models for Large Scale Speech Recognition. InterSpeech 2020(Jinyu Li, Yu Wu, Yashesh Gaur, Chengyi Wang, Rui Zhao, Shujie Liu)
在今年的 InterSpeech 的论文中,微软亚洲研究院和微软 Azure Speech 团队的研究员们对比了主流的 E2E 模型,其中包括 Transformer 和 RNN 的结构对比,以及在流式场景下 Transducer 和流式 S2S 的框架对比,所有试验均在超大规模数据集上进行。实验的结论为,Transformer 模型比 RNN 模型效果稍好,而 Transducer 模型在流式场景下要好于流式的 S2S 模型。在此之后,研究员们在论文“Developing Real-time Streaming Transformer Transducer for Speech Recognition on Large-scale Dataset”中又探讨了 RNN 和 Transformer 模型在 Transducer 的优劣比较,实验结果表明,Transformer 在精度上要好于 RNN,在允许几百毫秒的延迟时从精度、速度上都要好于 RNN。然而 Transformer 模型在0延迟时计算代价要远远大于 LSTM,需要良好的计算设备才能支持实时运行。
你也许还想看: