基于协同过滤算法的推荐
云栖君导读:数据挖掘的一个经典案例就是尿布与啤酒的例子。尿布与啤酒看似毫不相关的两种产品,但是当超市将两种产品放到相邻货架销售的时候,会大大提高两者销量。很多时候看似不相关的两种产品,却会存在这某种神秘的隐含关系,获取这种关系将会对提高销售额起到推动作用,然而有时这种关联是很难通过经验分析得到的。这时候我们需要借助数据挖掘中的常见算法-协同过滤来实现。这种算法可以帮助我们挖掘人与人以及商品与商品的关联关系。
协同过滤算法是一种基于关联规则的算法,以购物行为为例。假设有甲和乙两名用户,有a、b、c三款产品。如果甲和乙都购买了a和b这两种产品,我们可以假定甲和乙有近似的购物品味。当甲购买了产品c而乙还没有购买c的时候,我们就可以把c也推荐给乙。这是一种典型的user-based情况,就是以user的特性做为一种关联。
(本实验选用数据为真实电商脱敏数据,仅用于学习,请勿商用)
一、业务场景描述
通过一份7月份前的用户购物行为数据,获取商品的关联关系,对用户7月份之后的购买形成推荐,并评估结果。比如用户甲某在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。
本次实验选用的是PAI-Studio作为实验平台,仅通过拖拽组件就可以快速实现一套基于协同过滤的推荐系统。本实验的数据和完整业务流程已经内置在了PAI首页模板,开箱即用:
二、数据集介绍
数据源:本数据源为天池大赛提供数据,数据按时间分为两份,分别是7月份之前的购买行为数据和7月份之后的。
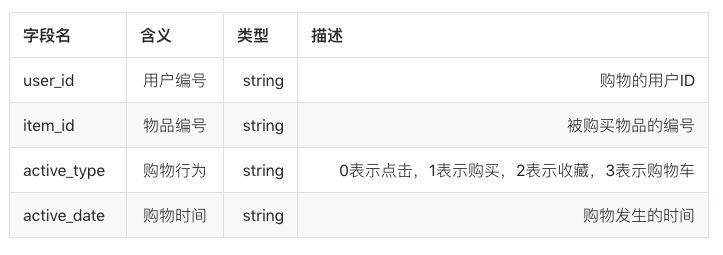
具体字段如下:
数据截图:
三、数据探索流程
本次实验选用的是PAI-Studio作为实验平台,仅通过拖拽组件就可以快速实现一套基于协同过滤的推荐系统。
实验流程图:
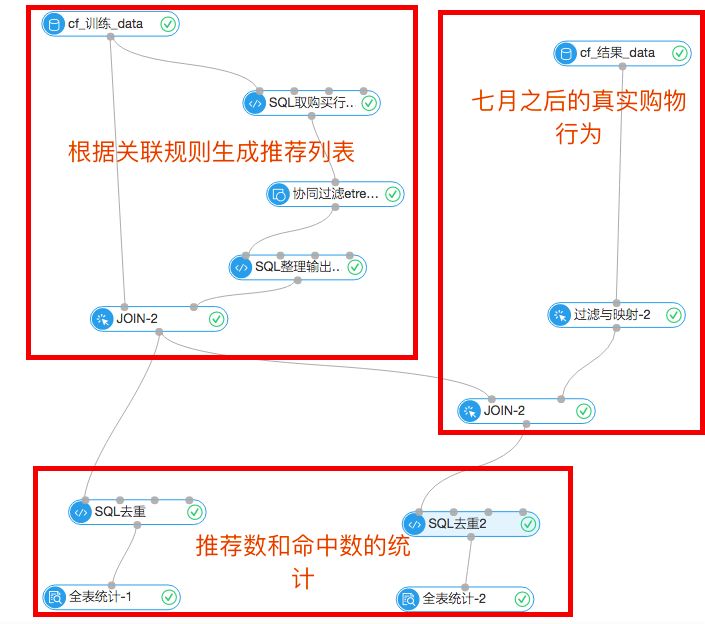
1.协同过滤推荐流程
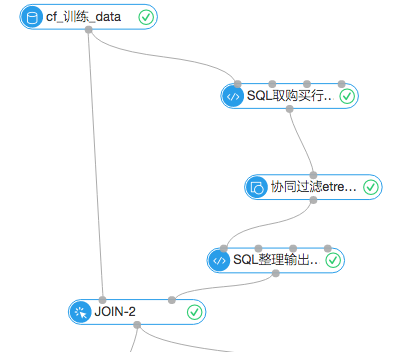
首先输入的数据源是7月份之前的购物行为数据,通过SQL脚本取出用户的购买行为数据,进入协同过滤组件,这么做的目的是简化流程,因为购买行为对这次实验分析是最有价值的。协同过滤的组件设置中把TopN设置成1,表示每个item返回最相近的item和它的权重。通过购买行为,分析出哪些商品被同一个user购买的可能性最大。设置图如下:

协同过滤结果,表示的是商品的关联性,itemid表示目标商品,similarity字段的冒号左侧表示与目标关联性高的商品,右边表示概率:
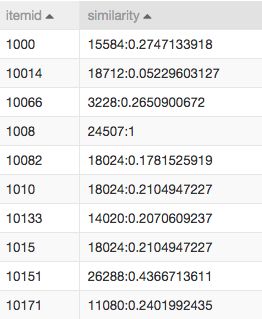
比如上图的第一条,itemid1000和item15584的相似度为0.2747133918,相似度越高表示两个物品被同时选择的概率越大。
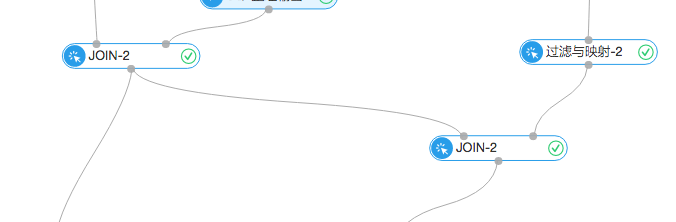
2.推荐
上述步骤介绍了如何生成强关联商品的对应列表,这里使用了比较简单的推荐规则,比如用户甲某在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。这个步骤是通过下图实现的:
3.结果统计
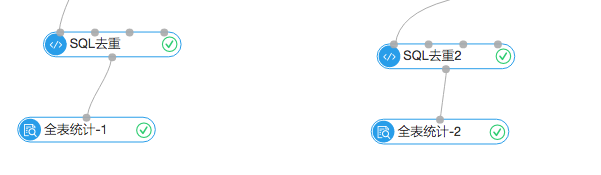
上面是统计模块,左边的全表统计展示的是根据7月份之前的购物行为生成的推荐列表,去重后一共18065条。右边的统计组件显示一共命中了90条,命中率0.4%左右。
根据上文的统计结果可以看出,本次试验的推荐效果比较一般,原因在如下几方面:
1)首先本文只是针对了业务场景大致介绍了协同过滤推荐的用法。很多针对于购物行为推荐的关键点都没有处理,比如说时间序列,购物行为一定要注意对于时效性的分析,跨度达到几个月的推荐不会有好的效果。其次没有注意推荐商品的属性,本文只考虑了商品的关联性,没有考虑商品是否为高频或者是低频商品,比如说用户A上个月买了个手机,A下个月就不大会继续购买手机,因为手机是低频消费品。
2)基于关联规则的推荐很多时候最好是作为最终推荐结果的补充或者是最基础的推荐系统,真正想提高准确率还是要依靠机器学习算法训练模型的方式,具体方法可以参考泛推荐系列的其它文章。






