基于Storm的实时计算应用实践
有赞使用 Storm 已经有将近 3 年时间,稳定支撑着实时统计、数据同步、对账、监控、风控等业务。订单实时统计是其中一个典型的业务,对数据准确性、性能等方面都有较高要求,也是上线时间最久的一个实时计算应用。通过订单实时统计,描述使用 Storm 时,遇到的准确性、性能、可靠性等方面的问题。
在使用 Storm 之前,显示实时统计数据一般有两种方案:
在数据库里执行 count、sum 等聚合查询,是简单快速的实现方案,但容易出现慢查询。
在业务代码里对统计指标做累加,可以满足指标的快速查询,但统计逻辑耦合到业务代码,维护不方便,而且错误数据定位和修正不方便。
既要解耦业务和统计,也要满足指标快速查询,基于 Storm 的实时计算方案可以满足这两点需求。
一个 Storm 应用的基本结构有三部分:数据源、Storm 应用、结果集。Storm 应用从数据源读取数据,经过计算后,把结果持久化或发送消息给其他应用。

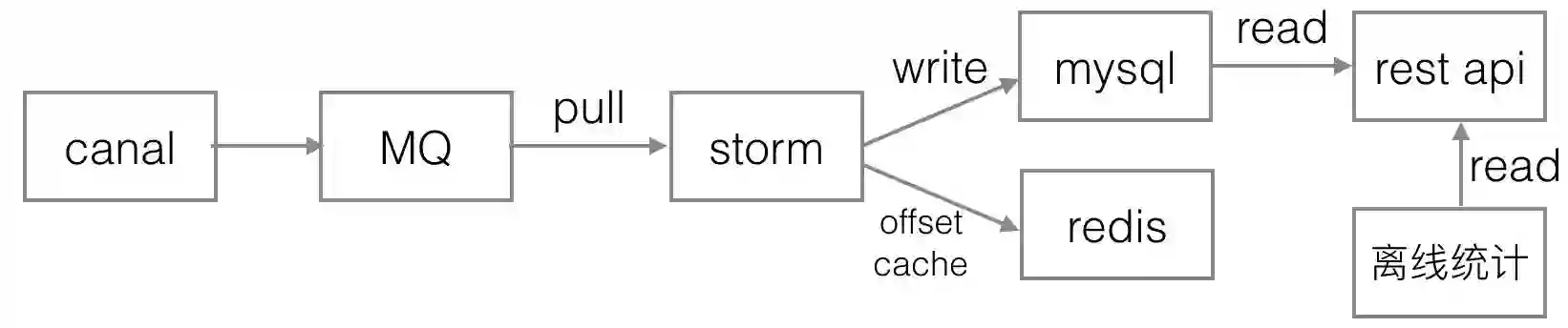
第一版的订单实时统计结构如下图。在数据源方面,最早尝试在业务代码里打日志的方式,但总有业务分支无法覆盖,采集的数据不全。我们的业务数据库是 mysql,随后尝试基于 mysql binlog 的数据源,采用了阿里开源的 canal,可以做到完整的收集业务数据变更。
在结果数据的处理上,我们把统计结果持久化到了 mysql,并通过另一个后台应用的 RESTful API 对外提供服务,一个 mysql 就可以满足数据的读写需求。

为了提升实时统计应用吞吐量,需要提升消息的并发度。spout 里设置了消息缓冲区,只要消息缓冲区不满,就会源源不断从消息源 canal 拉取数据,并把分发到多个 bolt 处理。
第一版的性能瓶颈在统计结果持久化上。为了确保数据的准确性,把所有的统计指标持久化放在一个数据库事务里。一笔订单状态更新后,会在一个事务里有两类操作:
订单的历史状态也在数据库里存着,要与历史状态对比决定统计逻辑,并把最新的状态持久化。Storm 的应用本身是无状态的,需要使用存储设备记录状态信息
当大家知道实时计算好用后,各产品都希望有实时数据,统计逻辑越来越复杂。店铺、商品、用户等多个指标的写操作都是在一个事务里 commit,这一简单粗暴的方式早期很好满足的统计需求,但是对于 update 操作持有锁时间过长,严重影响了并发能力。
为此做了数据库事务的瘦身:
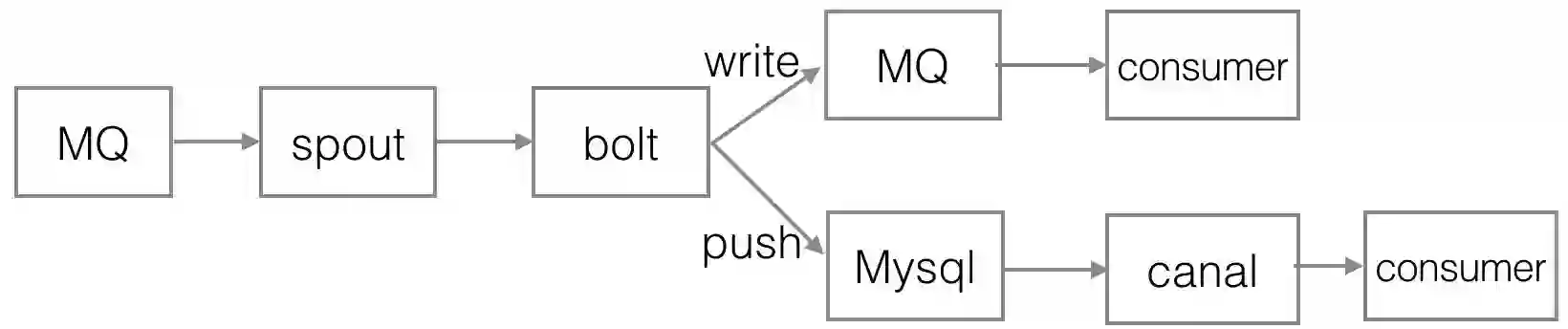
去除历史状态的 mysql 持久化,而是通过单条 binlog 消息的前后状态对比,决定统计逻辑,这样就做到了统计逻辑上的无状态。但又产生了新问题,如何保证消息有且只有处理一次,为此引入了一个 redis 用于保存最近 24 小时内已成功处理的消息 binlog 偏移量,而 Storm 的消息分发机制又可以保证相同消息总是能分配到一个 bolt,避免线程安全问题。
统计业务拆分,先是线上业务和公司内部业务分离,随后又把线上业务按不同产品拆分。这个不仅仅是 bolt 级别的拆分,而是在 spout 就完全分开。
随着统计应用拆分,在 canal 和 Storm 应用之间加上消息队列。canal 不支持多消费者,而实时统计业务也不用关系数据库底层迁移、主从切换等维护工作,加上消息队列能把底层数据的维护和性能优化交给更专业的团队来做。
热点数据在 mysql 里做了分桶。比如,通常一个店铺天级别的统计指标在 mysql 里是一行数据。如果这个店铺有突发的大量订单,会出现多个 bolt 同时去 update 这行数据,出现数据热点,mysql 里该行数据的锁竞争异常激烈。我们把这样的热点数据做了分桶,实验证明在特定场景下可以有一个数量级吞吐量提升。
最终,第二版的订单实时统计结构如下,主要变化在于引入了 MQ,并使用 redis 作为消息状态的存储。而且由最初的一个应用,被拆成了多个应用。

经过第二版的优化,实时统计的吞吐量已经不成问题,但还是遇到了做大数据最重要的准确性的问题:
统计口径是会变化的,同样是 GMV,一年前和现在的算法可能有变化。例如一笔货到付款订单,是买家下单算成交,还是卖家发货成交,在不同的时期可能使用不同的算法。
实时统计只能按照当时的算法来做计算。有可能出现一段时间周期内的 GMV,前一段是按旧算法来计算,后一段按新算法来计算,提供的数据就不准确了。
实时统计难免会出现 bug,有不准确的结果,修复错误数据是个难题。
为了解决这个问题,凡是涉及到两天以前数据的,一律由离线计算提供,最终展示给用户的数据,就是历史离线统计数据,并上今日昨日实时统计数据。为什么是今日昨日实时统计呢?因为离线统计有数据准备、建模、统计的过程,要花费几个小时,每天的凌晨很可能还得不到前一天的离线统计结果。
一旦统计口径有变化,只需要重跑离线统计任务就可修复历史数据,做到了冷热数据分离。
通过订单实时统计的案例,可以抽象出一些基于 Storm 实时计算的共性问题。
Storm 不提供消息状态管理,而且为了达到水平扩展,最好是消息之间无状态。对于大数据量、低精度的应用,需要做到无状态。而像订单实时统计这样数据量不算太大,但精度要求极高的场景,需要记录消息处理状态。而为了应付重启、分布式扩展的场景,往往需要额外的介质来存储状态。状态信息往往是 kv 形式的读写,我们在实际的应用中,使用过 redis、HBase 作为存储。
对于准确性要求高的场景,需要保证数据正确的只消费一次。Storm 的有三种消息处理模式:
at most once,若不实现 ack 和 fail 方法,无论后续处理结果如何,消息只会发送一次,必定不能满足高准确性;
at least once,若实现了 ack 和 fail 方法,只有调用了 ack 方法才会任务处理成功,否则会重试。可能会出现消息重复,在并发场景下重复又意味着可能出现乱序;
exactly once,trident 每个 micro batch 作为整体只成功处理一次,但也是无法保证消息真的只正确的处理一次,比如数据已经处理完毕并持久化,但向数据源 ack 时失败,就可能会有重试。
对于消息重复、乱序的场景,不是简单的消息幂等能解决,有以下的处理思路:
使用前面提到的状态管理的办法,识别出重复、乱序的数据;
业务逻辑中,兼容重复、乱序数据,比如维护一个业务状态机,把异常数据剔除。
对于时序判断,尽量不用使用时间戳,因为在分布式系统里,各服务器时间不一致是很常见的问题。
我们会尝试在运行过程中重启消息源、Storm 应用、存储 /MQ 等下游系统,或者制造网络丢包、延迟等异常,手工触发可能的消息丢失、重复、乱序场景,来验证我们的应用能否对应这些异常情况。
在 Storm 的文档里,有很多类似下图的复杂应用。
对于需要消息可靠处理的场景,是不适合这样复杂拓扑的,部分失败如何回滚,是否要全部 bolt 处理完毕才 ack,是需要面对的问题。过长的拓扑链路,里面的慢速逻辑会拖慢整体性能。
可以考虑使用更简化的拓扑,不同的逻辑之间尽量解耦,需要使用 bolt 的结果时,可以把数据持久化或者推送到 MQ。
生产环境少不了监控,除了服务器的基础监控,还加了不少 Storm 特有的监控:
消息延迟:消息在业务系统的时间戳与 Storm 应用的当前时间戳对比,大于一定阈值则告警,不同应用的阈值会不同;
消息处理时长、fail 数:这两个都可以由 Storm 的接口获取,数值偏大很可能是出了问题;
应用 TPS:记录应用的 emit、ack、fail 数的变化趋势,帮助分析应用的运行情况;
任务级监控:每台服务器的 worker、executor 数量,这也可以通过 Storm 接口获取。
除此之外,会有各类应用特有的监控,一般都是离线计算的结果与实时计算结果对比。对于数据同步类的应用,数据量比较大,可能会使用采样的方式做校验。
最近 spark streaming、Flink 等其他实时计算框架也很火,出于技术栈的维护成本的考虑,我们并没有过多使用新的技术,太多框架一起维护不是件容易的事。
基于 Storm 的实时计算应用开发有几个痛点:
消息重复、乱序的解决起来很麻烦,在分布式系统里很难有通用的办法,而类似 Flink 提供通用逻辑封装,是一种问题解决的思路;
不能统一实时和离线开发,spark 的统一不彻底,最新的 apache beam 则在 API 层做了统一封装,也不能根本解决这个问题;
高吞吐量场景,micro-batch 的模式,会比流式模式有优势,我们在一些日志处理场景下使用了 spark streaming。
后续我们会考虑将实时计算平台化,解决或减轻上述几个痛点,降低开发和维护成本。
本文系有赞技术团队原创文章,已经授权 InfoQ 垂直公众号转发传播。
今日荐文
点击下方图片即可阅读

千锤万凿出深山:且谈特征工程最佳实践
无论是想进入 Google、Facebook 等硅谷名企还是 BAT 这些国内一线互联网公司做研发工作,算法与数据结构都是面试官会重点考察的知识点。如何从刷题大军中脱颖而出,面对复杂的算法问题能快速找出解决思路,从而获得自己心仪的职位?本周六的 StuQ 免费公开课,我们邀请前 Facebook 工程师覃超,为大家分享“掌握终身受用的算法与数据结构思想及面试技巧”这个话题,为大家答疑解惑。欢迎添加下图中小助手二维码报名该课程。






