想知道Facebook怎样做推荐?FB开源深度学习推荐模型
选自Facebook博客
作者:Maxim Naumov等
机器之心编译
参与:路、一鸣
近日,Facebook 开源了深度学习推荐模型 DLRM。 DLRM 通过结合协同过滤算法和预测分析方法,提供了推荐系统当前最优效果。
随着深度学习的发展,基于神经网络的个性化和推荐模型成为在生产环境中构建推荐系统的重要工具。但是,这些模型与其他深度学习模型有显著区别,它们必须能够处理类别数据(categorical data),该数据类型用于描述高级属性。对于神经网络而言,高效处理这种稀疏数据很有难度,缺乏公开可用的代表性模型和数据集也拖慢了社区在这方面的研究进展。
为了促进该子领域的进步,Facebook 开源了当前最优的深度学习推荐模型 DLRM,该模型使用 PyTorch 和 Caffe2 平台实现。DLRM 通过结合协同过滤算法和预测分析方法,相比其他模型获得进一步的提升,从而能够高效处理生产级别数据,并提供当前最优结果。
Facebook 在官方博客中表示:开源 DLRM 模型以及公布相关论文,旨在帮助社区寻找新的方式,解决这类模型面临的独特挑战。Facebook 希望鼓励进一步的算法实验、建模、系统协同设计和基准测试。这将有助于新模型和更高效系统的诞生,从而为人们使用大量数字服务提供更具相关性的内容。
DLRM 开源地址:https://github.com/facebookresearch/dlrm
DLRM 论文:https://arxiv.org/abs/1906.00091
了解 DLRM 模型
DLRM 模型使用嵌入处理类别特征,使用下方的多层感知机(MLP)处理连续特征。然后显式地计算不同特征的二阶相互作用(second-order interaction)。最后,使用顶部的多层感知机处理结果,并输入 sigmoid 函数中,得出点击的概率。
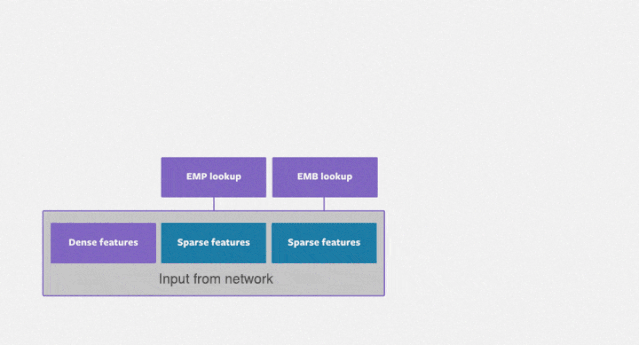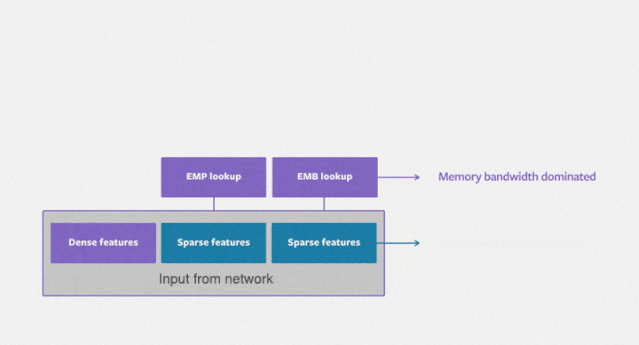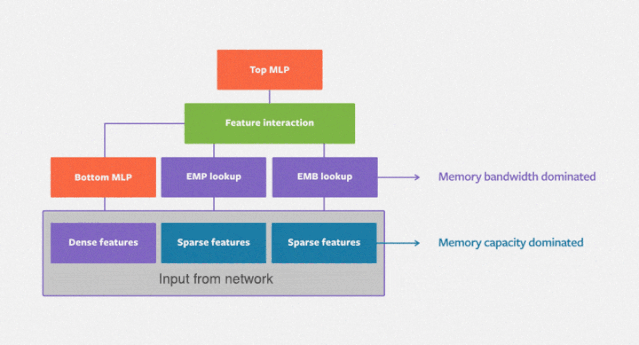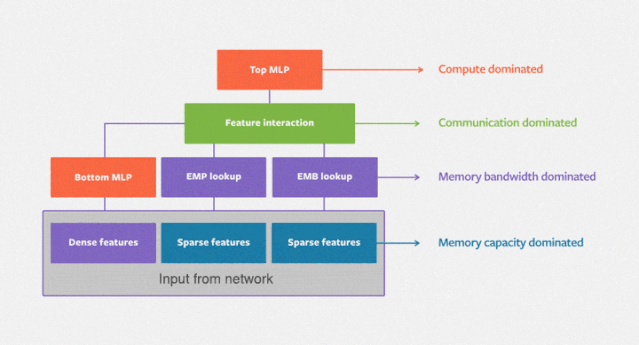
DLRM 模型处理描述用户和产品的连续(密集)特征和类别(稀疏)特征。该模型使用了大量硬件和软件组件,如内存容量和带宽,以及通信和计算资源。
基准和系统协同设计
DLRM 的开源实现可用作基准,去衡量:
模型(及其相关算子)的执行速度;
不同数值技术对模型准确率的影响。
这可以在不同的硬件平台上进行,比如 BigBasin AI 平台。
DLRM 基准提供两个版本的代码,分别使用 PyTorch 和 Caffe2。此外,DLRM 还有一个使用 Glow C++算子实现的变体。为了适应不同框架,各个版本的代码略有不同,但整体结构类似。
这些模型实现允许我们对比 Caffe2 框架和 PyTorch 框架,以及 Glow。或许最重要的一点是,未来我们可以从每个框架中选出最好的特征,然后组合成一个框架。
Big Basin 具备模块化、可扩展的架构。

DLRM 基准支持随机输入和合成输入的生成。基准模型同时也支持模型自定义生成类别特征对应的索引。这是因为多种原因:例如,如果某个应用使用了一个特定数据集,出于隐私原因我们无法共享数据,那么我们或许可以通过分布表示类别特征。此外,如果我们想要使用系统组件,如学习记忆行为,我们可能需要捕捉合成轨迹(synthetic trace)内原始轨迹的基本位置。
此外,Facebook 根据使用场景的不同,使用多种个性化推荐模型。例如,为了达到高性能,很多服务在单个机器上对输入执行批处理并分配多个模型,从而在不同平台上实现并行化推断。此外,Facebook 数据中心的大量服务器具备架构异构性,从不同的 SIMD 带宽到不同 cache hierarchy 的实现。架构异构性为软硬件协同设计和优化提供了机会。(对 Facebook 神经推荐系统架构的深入分析参见论文《The Architectural Implications of Facebook's DNN-based Personalized Recommendation》。)
并行计算
正如第一幅图所示,DLRM 基准模型由主要执行计算的多层感知机和受限于内存容量的嵌入构成。因此,它自然需要依赖数据并行计算提升多层感知机的表现,利用模型并行化解决嵌入对内存容量的需求。
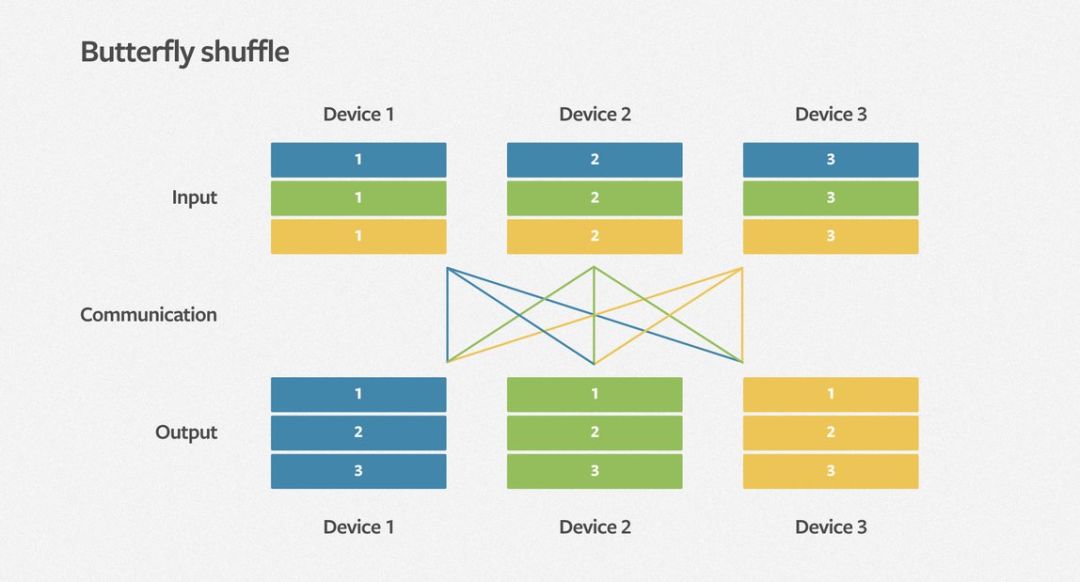
DLRM 基准模型提供了并行化的解决方案。它通过一种名为 butterfly shuffle 的机制,将每个设备上 minibatch 的嵌入矩阵分割成多个部分,并分配到所有设备上。如下图所示,每种颜色代表 minibatch 中的一个元素,每个数字代表一个设备及其分配到的嵌入矩阵。Facebook 研究团队计划优化这一系统,并在以后的博客中公开详细的性能细节。
建模和算法实验
DLRM 基准模型使用 Python 语言编写,支持灵活部署。模型的架构、数据集和其他参数都使用命令行定义。DLRM 可用于训练和推断。训练过程中,DLRM 增加了反向传播功能,使参数得到更新。
代码是完整的,且可以使用公开数据集,包括 Kaggle 展示广告挑战赛数据集(Kaggle Display Advertising Challenge Dataset)。该数据集包含 13 种连续特征和 26 种类别特征,定义了 MLP 输入层的大小,以及嵌入的数量,其他参数则可以使用命令行定义。例如,根据如下命令行运行 DLRM 模型,可以产生训练结果。结果如下图所示:
python dlrm_s_pytorch.py --arch-sparse-feature-size=16 --arch-mlp-bot="13-512-256-64-16" --arch-mlp-top="512-256-1" --data-generation=dataset --data-set=kaggle --processed-data-file=./input/kaggle_processed.npz --loss-function=bce --round-targets=True --learning-rate=0.1 --mini-batch-size=128 --print-freq=1024 --print-time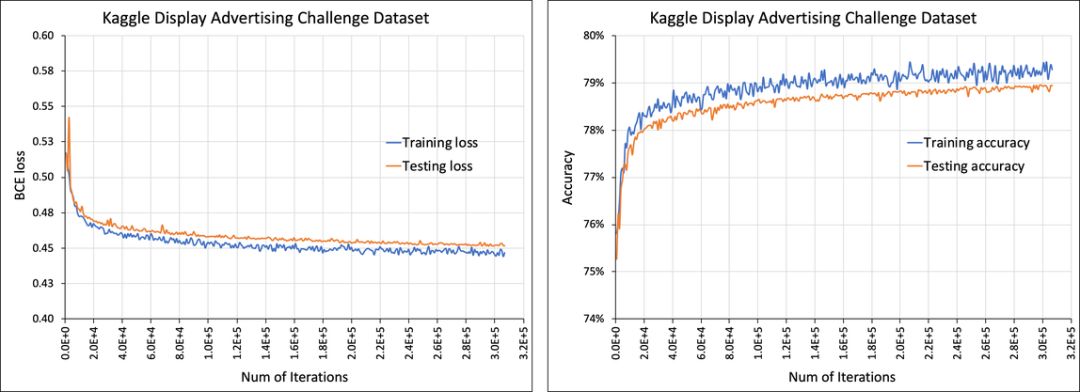
DLRM 模型可在真实数据集上运行,这可以帮助衡量模型的准确率,特别是使用不同的数值技术和模型进行对比实验时。Facebook 团队计划对量化和算法实验对 DLRM 模型的影响进行深入分析。
DLRM 模型开源代码
用户怎样使用模型呢?Facebook 官方在 GitHub 上开源了相关代码。目前,DLRM 模型主要有两个版本的实现:
DLRM PyTorch
DLRM Caffe2
通过使用 DLRM Data 相关的模块,我们可以快速生成或加载数据,也能使用对应的脚本进行测试。此外,如果希望试试基准模型,还能查看./bench 目录下的 DLRM 基准实现。
训练和测试
下图展示了如何训练一个较小模型:

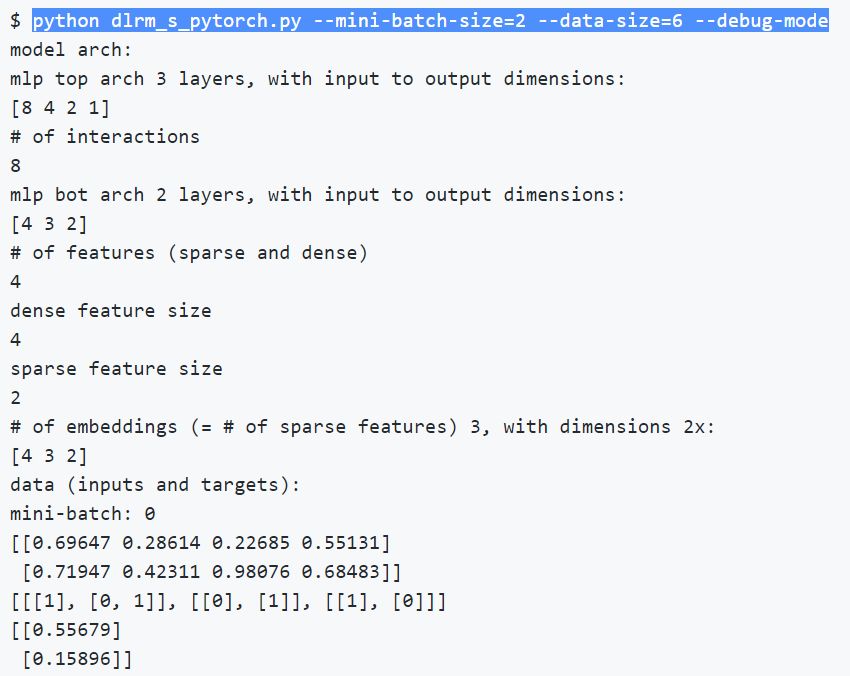
用户还可以使用 Debug 模式训练:
为了测试运行正常,可以使用如下的代码:

模型的保存和加载
训练时,模型可以使用 --save-model=保存。如果在测试时准确率提升,则模型会被保存。查看测试精确率的命令是: --test-freq intervals。
可以使用 --load-model=加载之前保存的模型。加载的模型可以继续用于训练,通过 checkpoint 文件保存。如果只要求用模型进行测试,则需要特别命令—inference-only。

原博客地址:https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



